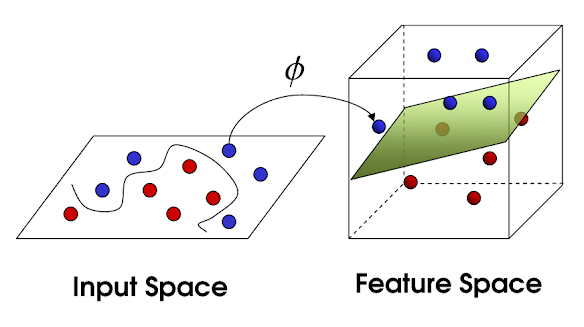
어떤 input space의 데이터 (xn,yn)의 classification 문제를 linear model로 풀고자 한다면 이는 어떤 적당한 hyperplane f(x)=wTx를 찾는 문제일 것이다. 하지만 위의 그림처럼 data가 linear하게 separable하지 않은 경우에는 non-linear function을 도입하여 해결할 수도 있겠다.
조금 다른 관점에서는, input domain space (x∈X)을 선형적인 특성을 가지는 또 다른 더 높은 차원의 space (ϕ(x)∈V)로 mapping시켜서 linear model을 통해 구분하는 방식을 생각해볼 수 있다.
여기서 사용하는 함수 ϕ가 basis function 혹은 feature map이다.
(예시) data point x를 polynomial kernel을 사용해 ϕ(x)로 옮긴 경우
그런데 실제로는 이 ϕ를 explicit하게 적용하는 것이 매우 복잡하기 때문에 (모든 data point에 preprocessing), kernel trick을 이용하여 어떤 kernel function을 통해 computationally cheap하게 연산을 수행하고자 한다.
여기서 SVM의 loss function을 한번 생각해보자.
L(w,α)=n∑αn−21n∑Nm∑Nαnαmynym(xnTxm)
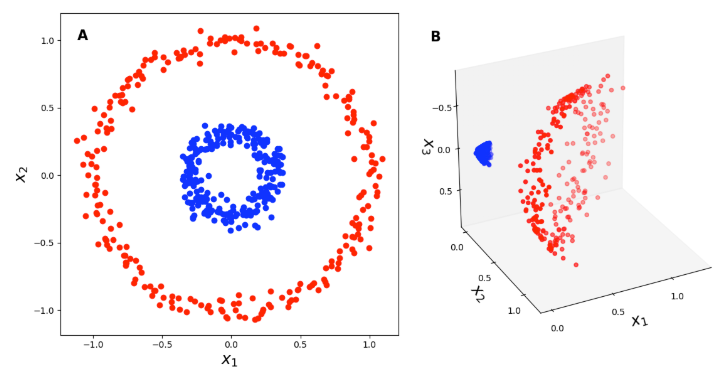
이 식이 어떻게 나왔는지는 따로 공부하는 것으로 하고, 결론적으로 SVM은 data point들의 내적 연산을 필요로 한다. 바로 위의 그림 A와 같은 data를 분류하려 한다면 똑같이 polynomial kernel로 데이터를 옮길 수 있다.
그럼 뒤의 내적 항은 아래와 같이 계산되고 모든 데이터 포인트에 대해서 이것을 계산하면 된다.
각 data point를 고차원으로 이동시킨 후 내적을 연산하지 않고, 내적을 계산하고 제곱을 취했다. 여기서는 문자를 써서 별로 연산에 차이가 많이 나보이지는 않지만 실제로는 내적 연산을 더 낮은 차원에서 한다는 것이 곱셈과 덧셈을 훨씬 덜 하고, 내적 후에는 그냥 scalar 제곱이기 때문에 훨씬 computational cost가 낮다.
즉, kernel trick은 더 높은 차원에서의 내적 연산과 같은 결과를 낼 수 있는 어떤 적당한 kernel function k(xn,xm)을 찾아 사용함으로써 더 높은 차원에서 expensive한 연산을 줄이는 방법이다. (방금전 예시에서는 k(xn,xm)=(xnTxm)2이고, 다양한 kernel function이 이미 많이 정의되어 있다.)
k(xn,ym)=ϕ(xn)Tϕ(xm)
Kernel trick에 대한 mathmatical basis는 Mercer’s theorem를 더 공부해보면 좋을 것 같다. (symetric function, positive semidefinite)
그런데 이런 Kernel trick도 N∗N의 covariance matrix K를 기반으로 연산되기 때문에, data point N이 너무 큰 경우 여전히 비효율적일 수 있다.
Random Fourier Feature (RFF)
Random Features for Large-Scale Kernel Machines에서는 이러한 내적값을 low dimensional random feature z를 이용하여 approxiamte하여 computational cost를 더 낮추고자 하였다.
k(xn,ym)=ϕ(xn)Tϕ(xm)∼z(xn)Tz(xm)
즉, 어떤 random projection z를 잘 찾아내서 data를 projection시키고, 이를 간단한 linear model로 분류하는 것이다.
Random D차원의 vector w∼ND(0,I)를 이용해 h:x→exp(iwTx)를 정의하면 아래와 같이 gaussian kernel을 approximate할 수 있다. (*는 켤레복소수)
어떤 non-negative measure p(w)의 fourier transform은 아래와 같은데,
k(Δ)=∫p(w)exp(iwΔ)dw
위의 observation과 Bochner's theorem을 바탕으로 fourier transform을 이용한 shift-invariant kernel의 approximation이 가능해진다.
Bochner’s theorem: A continuous kernel k(x,y)=k(x−y) on RD is positive definite if and only if k(Δ) is the Fourier transform of a non-negative measure.
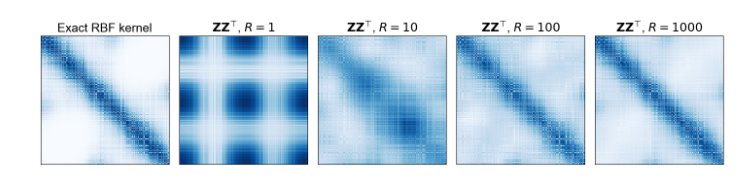
위 그림에서 볼 수 있다시피 sampling하는 fourier feature의 수 R이 커질수록 더욱 정확한 approximation을 해내는 것을 볼 수 있다.
Discussion
다른 논문을 읽다가 Random fourier feature라는 내용을 이해하고 싶어서 조금 공부해봤다. 결론적으로는 어떤 task를 잘 수행하기 위해서 data point를 더 높은 차원으로 mapping하고 싶은데, 이를 mapping하는 function을 찾기 위해 kernel trick을 사용할 수 있고, 이러한 kernel 자체를 더 간단히 estimation하기 위해 fourier base feature의 combination을 사용할 수 있다라는 내용이었다.