Paper : Progressive Growing of GANs for Improved Quality, Stability, and Variation (T Karras, T Aila, S Laine, J Lehtinen / ICLR 2018)
- Motivation : PGGAN은 NVIDIA의 StyleGAN의 baseline이 되는 GAN training methodology로, 이 방법론에 대한 이해가 필요했다. 고화질 이미지 생성 모델의 학습을 위해 실제로 사람이 그림을 그릴 때 아주 큰 structure부터 구도를 잡고 점점 작은 디테일을 그려나가는 것처럼 Generative model이 이미지를 생성할 수 있도록 하는 이 방법이 아주 기발하다고 생각되어 읽게 되었다.
Short Summary
-
이미지 생성 모델에서 GAN을 이용한 학습 방법은 현재까지 아주 좋은 성과를 내었으나, 몇 가지 불안정성과 한계를 가지고 있다.
-
PGGAN에서는 모델의 layer를 점진적으로 쌓아 low-resolution에서 시작하여 high-resolution까지 단계적으로 학습시켜 고화질 이미지 생성하는데 성공하였다.
-
추가적으로 생성되는 이미지의 variation을 향상시키고, 조금 더 안정적으로 GAN을 학습시킬 몇 가지 방법을 제시하였다.
Introduction
최근 연구에서 대부분 생성 모델은 Autoregressive model, VAE, GAN 접근법을 사용한다. 이 중 GAN은 sharp한 이미지를 만들어낼 수 있지만, 비교적으로 low-resolution에서만 잘 작동하고, 한정적인 variation이나 학습 시 불안정성 등의 문제점이 있다.
GAN에서, generator는 latent vector를 이용해 training distribution과 구분할 수 없도록 이미지를 만들어내도록 학습하고, discriminator는 이 이미지를 진짜인지 가짜인지 구분하도록 학습한다.
이러한 GAN의 formulation은 몇 가지 문제점이 있을 수 있다.
Problem of GAN
(1) 네트워크 학습의 불안정성
만약 training distribution과 generated distribution이 서로 멀리 떨어져있어 충분한 overlap이 없다면, 두 분포간의 거리를 측정할 때, gradient가 제대로된 방향을 가르키지 못할 것이다. (네트워크가 어떻게 학습을 해야할지 알 수 없다.) 이 문제를 해결하기 위해 least squares나 wasserstein distance 등이 제안되었지만, 해당 논문에서 다루고자하는 내용은 아니고, 둘 다 실험에 사용함
(2) high-resolution 이미지 생성의 어려움
high-resolution에서는 생성된 이미지가 training 이미지와 다르다고 판별하는 것이 더 쉽기 때문에 high-resolution 이미지를 생성하는 것이 어렵다. 또한 메모리 문제때문에 minibatch를 더 작게 사용해야하기 때문에, training stability가 떨어질 수 있다.
이 논문에서는 low-resolution부터 시작해서 high-resolution까지 새로운 layer를 하나씩 더해가면서 학습하는 방식을 도입하여 이 문제를 해결하였다.
(3) GAN formulation의 variation problem
GAN 공식을 보면 generative model이 training data distribution 전체를 표현할 필요가 없기 때문에, 훈련 데이터의 일부 distribution만을 표현하도록 학습되는 경우가 있다. 이러한 경우 생성되는 데이터의 variation을 보장할 수 없다. minibatch standard deviation을 통해 variation을 늘렸다.
(4) Mode Collapse
Generator는 discriminator를 잘 속이기 위해서 자신이 잘 만들 수 있는 데이터 일부 데이터를 계속해서 만들어내는 경우가 있다. 이러한 경우, discrimator가 취할 수 있는 방법은 그 똑같게 생성되는 데이터를 항상 가짜라고 하는 것이다. 그렇게 discriminator가 local minima에 빠져있는 동안, generator는 다시 discriminator를 쉽게 속일 example을 찾아낼 것이다. 이렇게 불필요한 경쟁은 보통 discriminator의 overshoot에서부터 시작되며 gradient가 과도하게 커짐에 따라 두 네트워크에서 신호 크기가 제어할 수 없게 된다.
이러한 문제를 해결하기 위해 network normalization 및 learning rate equalization 등 방법을 제시한다.
Progressive Growing of GANs
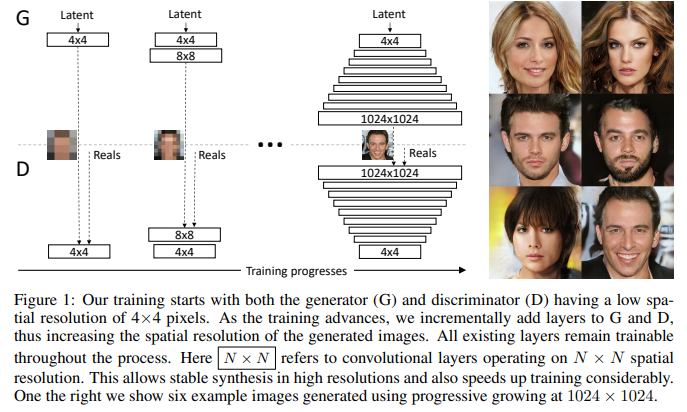
PGGAN은 위와 같이 이미지의 large scale structure(low-resolution, low-frequency)에서부터 시작해서 차근차근 finer scale detail(high-resoltion, high-frequency)의 정보를 학습하게 된다.
discriminator와 generator는 대칭적인 구조를 이루며, 함께 성장한다. 실제 학습에서는 4x4 resolution에서부터 학습을 시작해서 한 resolution의 layer에 대한 학습을 마치면 다음 resolution layer로 넘어가는 방식이며, 1024x1024 resolution까지 점차 커진다. (이전 layer의 parameter가 freeze되는 것은 아니다)
PGGAN의 progressive training은 몇 가지 장점을 가진다.
(1) 더 작은 class information과 더 적은 mode을 가지는 작은 이미지를 생성하는 것이 높은 resoltion의 이미지를 생성하는 것보다 더 안정적이다.
그러므로 resolution을 조금씩 늘려가는 것은 처음부터 latent vector로부터 높은 화질의 이미지를 생성할 때보다 네트워크에게 더 쉬운 task를 주는 효과가 있다.
실제로는 WGAN-GP loss나 LSGAN loss 등을 이용해 mega-pixel-scale 이미지의 학습을 안정화 시킨다고 하는데 나중에 확인해보자.
(2) training time 또한 감소된다. PGGAN에서는 대부분의 iteration이 기존의 이미지보다 작은 해상도에서 이루어지기 때문에 2배~6배까지 training 속도가 빨라진다고 한다.
지금까지 discriminator나 generator를 여러개 사용하여 high resolution 이미지를 생성하고자 하는 연구가 많았는데, 해당 논문에서는 하나의 GAN을 이용하여 latent vector로부터 여러 단계에 걸쳐 high-resolution 이미지로 mapping하는 네트워크를 제안했다.
Fade-in
점진적으로 layer를 붙여가면서 resolution을 높이며 학습을 진행할 때, 작은 resolution에서 잘 학습된 layer에 새로운 layer가 추가되면서 갑작스러운 변화로 인해 shock가 생겨 이전 layer까지 안좋은 영향을 줄 수 있으므로, 부드럽게 layer를 끼어맞춰주는 방법을 제시한다.
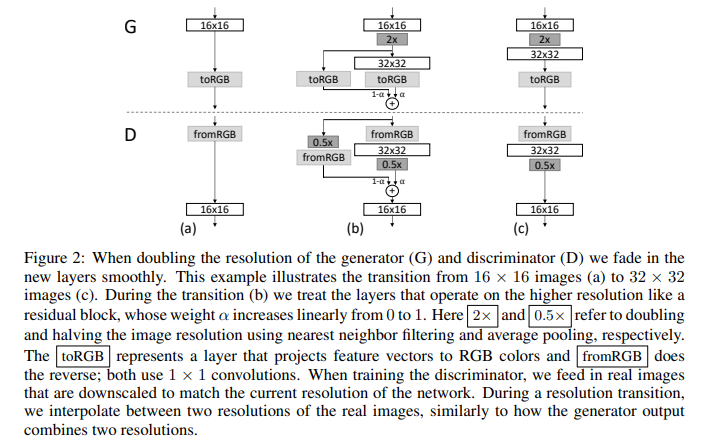
위 그림은 16x16 이미지에서 32x32 이미지로 해상도를 높이는 과정을 보여준다.
32x32 layer를 끼워넣을 때, 이를 residual block처럼 구성해서 16x16 layer로 만든 이미지를 2배(discriminator에서는 0.5배)로 키운 것과 interpolate한다. (어느정도 형태를 가지고 있는 이미지를 보여주어 low-resolution layer가 학습된 방향을 잘 유지하면서 새로운 layer 추가)
합쳐지는 두 이미지에는 와 가 곱해져 더해지며, 학습이 진행되면서 가 0에서부터 1까지 커지면서 이전 layer의 영향을 점차 줄여간다.
참고로 discriminator 학습 시, real 이미지는 실제로 1024x1024 이미지를 해당 layer의 resolution으로 resize해서 넣어준다.
fromRGB와 toRGB는 1x1 conv를 이용하여 feature channel을 RGB channel로 projection 시켜주는 부수적인 layer라고 보면 된다.
Increasing Variation Using Minibatch Standard Deviation
GAN은 학습 데이터의 일부분의 variation만을 학습하려는 경향이 있기 때문에, 이전 연구(Salimans et al. (2016))에서는 각각의 이미지 뿐만 아니라 mini-batch들의 feature statistics를 학습 데이터 mini-batch들의 feature statistics와 비슷하게 만들어줌으로써 variation을 늘려주는 minibatch discrimination 기법을 사용하였다.
discriminator의 마지막 layer에 mini-batch layer를 추가적으로 넣어 학습하는 기존의 방법과 다르게, 이 논문에서는 추가적인 parameter없이 discriminator에 이 정보를 넣어주려는 시도를 하였다.
먼저 mini-batch에서 각 feature와 각 spatial location에 대한 standard deviation을 구한다.() 그리고 모든 feature와 spatial location에 대해 구해진 값의 평균을 구한다.() 마지막으로 이 구해진 하나의 값을 mini-batch 내부 각 이미지 feature의 모든 spatial location에 대해 복제하여 feature map 마지막에 추가해준다. ()
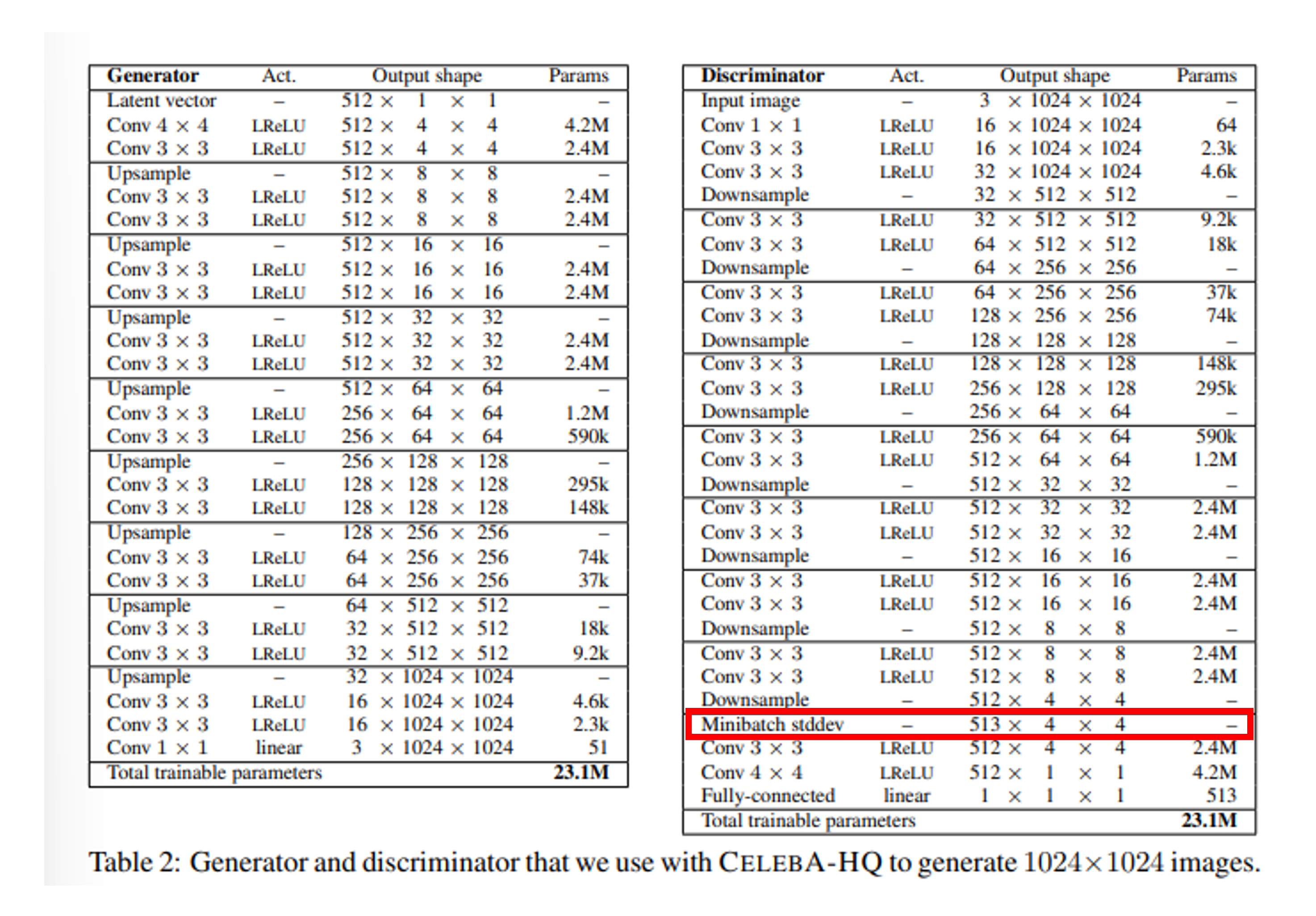
이 추가적인 feature map은 discriminator의 어느 layer에든 들어갈 수 있지만, 위의 그림처럼 마지막 layer에 추가되었을 때 가장 좋은 효과를 낸다고 한다.
GAN에서 variation을 높이기 위한 여러 연구가 존재하고, 더 좋은 성능을 낼 수도 있지만 해당 주제는 이 연구와 크게 상관없으므로 생략
Normalization in Generator and Discriminator
GAN은 discriminator와 generator의 불필요한 경쟁으로 인해 신호 강도가 매우 커지는 경우가 많다. 이전의 연구들은 이 문제를 batch-normalization 방식으로 해결하고자 했으나 batch-normalization은 원래 covariate shift 현상을 없애기 위해 고안된 것으로 이 문제가 잘 발생하지 않는 GAN의 해결방식으로는 적절하지 않다고 한다.
해당 논문에서는 GAN의 신호 강도와 경쟁 자체에 constraint를 주는 것이 해결 방식이 될 것이라고 생각했고, 아래의 두 방법을 이용하여 이 문제를 해결하였다.
Equalized Learning Rate
Batch의 크기가 작은 고해상도 이미지 생성 모델에서는 특히 weight initialize가 중요하다. 해당 논문에서는 로 initialize하고, 학습 시에는 각 layer마다 He’s initilizer로부터 구해지는 normalization constant()을 통해 동적으로 scaling한다.
이 방법은 estimated standard deviation을 이용해어 gradient update를 normalize하기 때문에dynamic range가 큰 parameter는 조정되는데 더 오랜 시간이 걸릴 것이다. 즉, 이는 모든 weight가 같은 learning speed를 갖도록 해주어 paramter의 scale에 영향을 받지 않고 training을 할 수 있게 해준다.
weight initialization에 대해서는 다음에 정리해서 포스팅을 쓰는 것으로 하자.
Pixelwise Feature Vector Normalization in Generator
두번째로 generator에서 매 conv layer 후에 feature vector를 각 픽셀별로 normalize해주어 값이 커지는 것을 막는다고 한다.
여기서 a는 이전 feature map, b는 이후 feature map
이러한 직접적인 constraint는 generator의 성능을 해치지 않고, 값이 너무 커지는 현상만 잘 막을 수 있었다고 한다.
Multi-Scale Statistical Similarity for Assessing GAN result
GAN으로 생성한 이미지의 성능을 비교하기 위해서 이전에는 MS-SSIM과 같은 방법을 사용하였지만, 이 수치는 훈련 데이터와의 유사성의 관점(variation)에서 이미지 quality를 평가하기엔 어려움이 있다.
잘 학습된 generator는 훈련 데이터셋 이미지와 모든 scale에서 local structure가 유사한 이미지를 만들어낼 수 잇어야하기 때문에, 두 이미지의 Laplacian pyramid representation으로부터 추출된 다양한 scale의 local patch의 통계적 유사성을 계산한다.
통계적 유사성을 계산하기 위해서는 Sliced Wasserstein distance(SWD)를 사용하는데, 이는 분산 거리를 예측하는 지표이다. 낮은 해상도에서 분산 거리는 대략적인 이미지 구성의 유사성을 의미하고, 높은 해상도에서 분산 거리는 픽셀 수준의 유사성을 의미한다고 한다.
직관적으로 작은 SWD 값은 학습 데이터와 생성된 데이터가 appearance와 variation 관점에서 유사하다라는 것을 의미한다.
GAN 결과를 다른 method와 비교하기 위한 수치가 이런 것이 있다라고만 알아두자.
Result
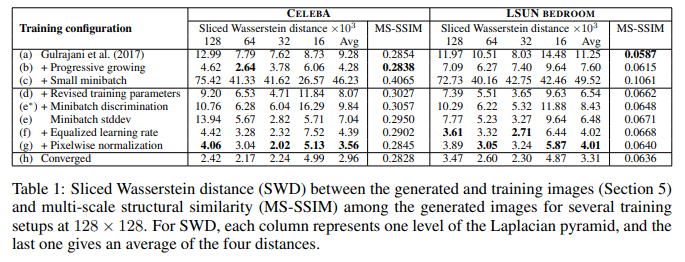
해당 논문에서 제안한 여러 가지 방법을 통해 훈련 데이터셋과 유사한 이미지를 생성해낼 수 있다고 한다.
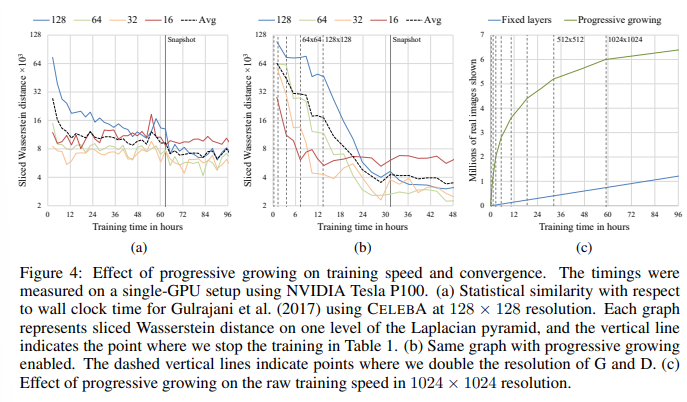
학습의 속도가 빨라지고 수렴성도 좋아졌다고 한다.

가장 중요하게도 고화질 이미지를 잘 생성할 수 있었다고 한다.
Opinion
실제로 GAN 학습을 해보면 high-resolution으로 갈수록 이미지 생성을 잘 못한다는 것을 많이 느꼈는데, 재밌는 내용인 것 같다.
고화질 이미지를 안정적으로 학습하는데는 성공하였으나 아직 micro-structure를 잘 파악하는데는 어려움이 있다. styleGAN으로 넘어가서 더 좋은 아이디어를 얻을 수 있을 것 같다.
아이디어는 참신하고 상당히 합리적인데, implementation detail이 조금 복잡한 것 같다. weight initialization이나 GAN에서 자주 사용되는 loss term은 자세히 설명되어있지 않다. 매번 보는 term인데, 나중에 한번 정리하면 좋을 것 같다.
