Paper : Style-Based Generator Architecture for Generative Adversarial Networks (Tero Karras, Samuli Laine, Timo Aila / CVPR 2019)
- Motivation : 워낙에 유명한 논문이기도 하고 예전부터 관심이 있었던 연구. StyleGAN은 Style-transfer 이론을 바탕으로 하는 새로운 이미지 generator architecture를 제시하여 face generation에서 놀라운 성능을 보여주었다. Image to image translation이 아닌 generation model은 많이 안다루어봐서 궁금한 분야이다.
Short Summary
- Progressively Growing GAN architecture를 baseline으로 style transfer의 개념을 도입하여 style-based generator architecture를 제안
- 해당 모델은 high-level attributes(pose, identity 등)와 stochastic variation(freckles, hair 등)을 잘 분리해내어 직관적이고 scale-specific한 이미지 synthesis control에 성공하였다.
- Interpolation quality와 disentanglement의 관점에 있어서 훌륭하게 이미지 생성에 성공하였다.
Introduction
GAN을 이용한 이미지 generation에서 resolution과 quality가 점점 발전하고 있지만, 아직까지도 generator가 이미지를 생성하는 과정은 black-box로 여겨지고 있고, latent space에 대한 이해나 stochastic feature에 대한 이해가 부족하다고 한다.
이 논문에서는 style transfer 연구(Arbitrary Style Transfer in Real time with Adaptive Instance Normalization)를 기반으로 이미지 생성 과정을 control할 수 있는 새로운 generator architecture를 제안한다. (discriminator나 loss function에 대한 연구는 아니다.)
Style-based generator는 이미지를 여러 style의 조합으로 만들어지는 것으로 보고, 학습된 constant input으로부터 시작하여 작은 resolution부터 시작하여 각 convolution layer마다 style을 조절하여 이미지를 생성한다. 추가적으로 network에 직접적으로 noise를 주입하여 high-level attribute와 stochastic variation을 잘 구분해내어 직관적인 scale-specific style mixing과 interpolation을 가능케 하였다.
Style-based generator는 기존의 generator와 다르게 input latent code를 intermediate latent space에 embedding하여 이를 style input으로 사용하는데, 이는 latent space의 disentanglement에 중요한 역할을 한다. 이러한 효과를 검증하기 위해 perceptual path length와 linear separability의 synthesis quality 평가 지표를 제시하고 해당 generator가 서로 다른 variation을 더 linear하고 disentangle하게 mapping한다는 것을 보여주었다.
Style-Based Generator
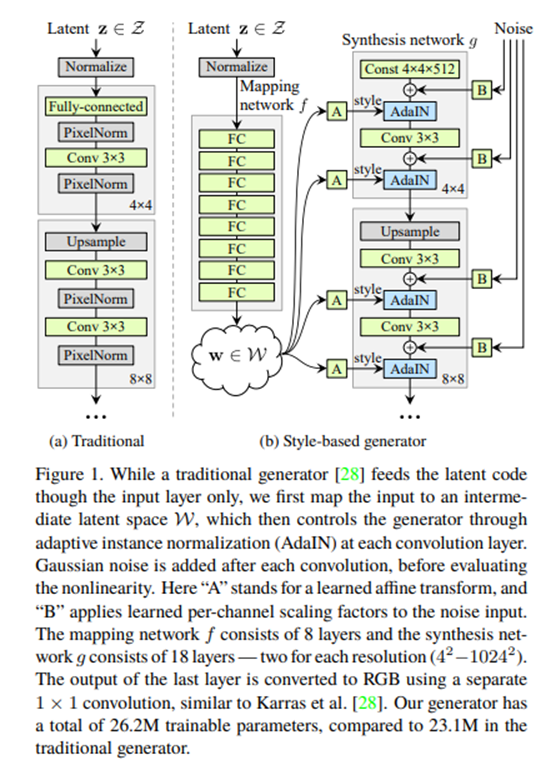
기존의 generator는 왼쪽과 같이 latent code가 generator의 input으로 직접 들어가서 이미지가 되는 방식이었지만, style-based generator에서는 오른쪽 그림과 같이 학습된 constant로부터 시작하고, constant tensor에 style을 단계별로 주입하며 이미지를 키워 나가는 방식이다.
Synthetsis network에서는 latent code 가 non-linear mapping network 를 거쳐 intermediate latent vector 로 변환된 후, 여러 layer를 거쳐 AdaIN을 수행하여 style을 주입해주는 식으로 이미지가 만들어진다.
AdaIN 논문과 다른 점은 어떤 example 이미지로부터 feature statistics를 뽑아서 이를 닮게 해주는 것이 아니고, vector 에서 spatially invariant style 를 계산하여 넣어준다고 생각할 수 있다. (MUNIT에서의 style을 구하는 방식과 유사)
마지막으로 synthesis network의 각 layer에 gaussian noise를 넣어주어 stochastic detail을 만들어주었고 이를 통해 더욱 사실적인 이미지를 생성할 수 있었다고 한다.
위의 설명과 같이 설계된 style-based generator는 엔비디아의 이전 논문인 Progressive GAN(Progressive Growing of GANs for Improved Quality, Stability and Variation)을 baseline으로 하고 있으며, architecture 변경 사안에 따라 이미지 생성 성능을 아래와 같이 끌어올릴 수 있었다고 한다.
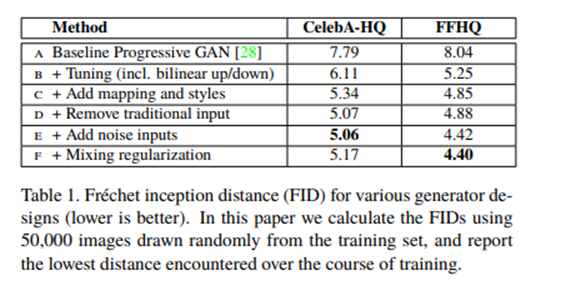
Properties of the style-based generator
이 논문에서는 style-based generator의 mapping network와 affine transformation을 학습된 distribution으로부터 각각 style에 대한 sample을 그리는 방법으로 해석하였고(특정 머리 스타일을 그리는 방법, 얼굴의 모양을 그리는 방법 등), synthesis network를 이 style들의 조합을 통해 새로운 이미지를 생성해내는 방법으로 해석하였다.(위의 여러 가지 스타일을 조합해 하나의 사람 얼굴을 만들어내는 방법)
Style-based generator의 가장 큰 장점은 각각의 style이 네트워크의 특정 부분에 localize되고, 각 layer에서 주입된 style이 이미지의 특정 부분에만 영향을 준다는 것이다.
한마디로, 이미지 생성 과정에 있어 내가 원하는 scale에서 원하는 style의 variation을 구현할 수 있다는 것이다.
Style generator에 사용되는 AdaIN 연산을 생각해보면, 매 layer마다 먼저 기존의 style을 normalize 시킨 후 intermediate vector 로부터 구한 style로 각 channel의 statistics간의 상대적 중요성을 변화시키기 때문에(channel별 다른 value로 affine transform), 각 style은 하나의 convolution만 영향을 끼치고, 다음 AdaIN 연산과는 관련이 없다는 것을 생각할 수 있다.
(아래 나오는 내용에 대한 demo는 여기에서 볼 수 있다. StyleGAN youtube demo)
Style Mixing
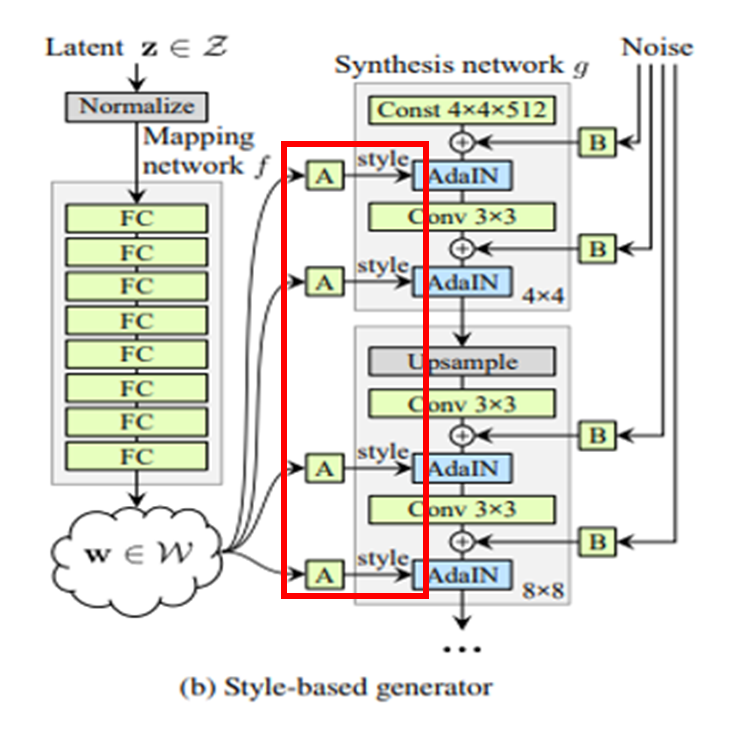
각 layer에서 제공되는 style이 담당하는 부분을 잘 맡을 수 있도록 mixing regularization 기법을 사용하였다.
Intermediate vector 는 위의 그림과 같이 이미지를 생성할 때 사용할 style의 집합을 모두 가지고 있는 vector인데, 이 vector 하나만으로 이미지를 생성하도록 학습하면 인접한 layer의 style이 correlate되도록 학습하는 문제가 발생할 수 있다. (예를 들어 눈, 코, 입을 그리기 위해 각 layer가 하나씩 그려주는 것이 이상적인데, 한 layer가 눈 조금 코 조금 그리고 다음 layer가 나머지 그리는 식이면 control이 어려움)
그래서 학습 시에 한 개의 latent code만을 사용하는 것이 아니고 두 개의 latent code를 사용하여 style을 mixing하는데, 정확하게는 두 개의 random vector 를 뽑아서 , 로 mapping하고, synthesis network의 특정 부분까지 을 쓰다가 그 뒤로 를 사용한다. 학습 시 Intermediate vector 를 바꾸어 주는 layer 위치를 계속 바꾸어 주었다.
이렇게 하면 network가 두 인접한 style에 대해 correlation을 가정하는 것을 막을 수 있었고 각 style이 각자 담당하는 의미 있는 high-level attribute를 배우도록 할 수 있다고 한다.

위의 표에서 첫 행과 첫 열은 각각의 latent code로 만들어진 source A 이미지와 source B 이미지이고, 표 내부의 이미지들은 source B의 스타일의 일부분과 source A style의 일부분을 함께 사용하여 만들어진 이미지들이다.
의 coarse spatial resolution에서 source B의 style을 사용하고 나머지는 source A를 사용하면, pose, general hair style, face shape, eye glass 등의 high-level aspect는 source B의 것을 따르고, 모든 color 관련된 것들이 source A를 따른다는 것을 볼 수 있다. 반대로 source B에서 의 fine spatial resolution을 가져다 쓰면 source B의 color와 microstructure style만을 가져온다는 것을 알 수 있었다.
- Coarse styles pose, hair, face shape
- Middle styles facial features, eyes
- Fine styles color scheme
Stochastic variation
사람 얼굴을 그릴 때에는 머리카락, 수염, 주근깨, 주름 등의 정확한 위치와 같이 stochastic하게 여겨지는 부분이 있고, 이런 것들은 정확한 distribution만 따른다면 사실 이미지에 대한 우리의 인식에 큰 영향을 주지 않고 randomize될 수 있다.
이전의 generator는 하나의 input이 input layer에 들어가서 직접 이미지가 되는 구조이기 때문에이러한 stochastic variation을 표현하기 위해 초기 layer부터 spatially variant한 어떤 random number를 만들어내는 방법을 배웠어야 했다. 이는 latent vector가 이미지의 중요한 정보 (high-level aspect)를 학습하는데 방해가 될 수 있기 때문에, 이 논문에서는 각 convolution layer 이후에 pixel별로 noise를 더해주는 방식을 통해 stochastic variation을 표현하고자 하였다. 실제 구현 시에는 single-channel의 noise 이미지를 만들고 학습된 scaling factor와 곱해서 이미지에 더해준다고 한다.

위의 그림을 보면 input noise는 오로지 stochastic한 부분에만 영향을 주고 대략적인 구성이나 중요한 부분에는 영향을 끼치지 않았다고 한다.

신기하게도, 어느 layer에 noise를 삽입하냐에 따라 stochastic variation이 생기는 방식이 다르다고 한다. Coarse noise(low-resolution에서 삽입)는 hair가 더 크게 꼬불거리고 fine noise(high-resolution)에서는 hair가 더 자글자글하게 꼬불거린다.
- Coarse Noise large-scale curling of hair
- Fine Noise finer details, texture
- No Noise featureless "painterly" look
Separation of global effects from stochasticity
정리하자면 style을 바꾸는 것은 pose를 바꾸거나 identity를 바꾸는 등 global한 영향을 주고, noise는 머리카락이나 수염 등 stochastic variation에만 영향을 주었다. 이러한 관찰은 spatially invariant statistics가 이미지의 style을 나타내고 spatially varying statistics가 특정 이미지 instance를 나타낸다라고 하는 기존의 style transfer 개념의 흐름과 일맥상통하다.
Style-based generator에서는 style이 feature map 자체를 scale하고 bias를 더하므로 spatially consistent하게 전체 이미지에 영향을 주게 되고, 반면에 noise는 각 픽셀에 independent하게 더해지므로 pose, lighting 이나 back ground style을 표현하기 보다는 spatially inconsistent한 stochastic variation을 표현하기에 딱 적합하다.
Disentanglement Studies
Disentanglement에는 여러 정의가 있겠지만, 보통은 latent space가 variation factor를 조정할 수 있는 linear subspace 로 이루어져 있을 때를 의미한다. 이전의 generator들은 fix된 distribution에서 를 sampling하였기 때문에, 가 training data의 distribution을 따르게 학습되면 필연적으로 latent space가 non-linear하게 mapping되고, latent vector를 이용해 이미지를 조절하는 것이 매우 어려워진다.
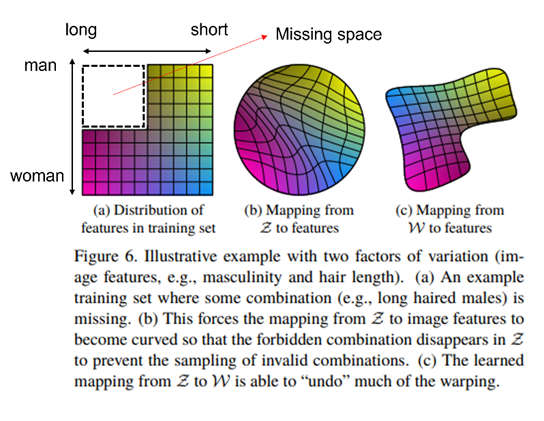
위와 같이 (a)와 같은 훈련 데이터셋이 구성되어 있다고 하자. (선형적으로 feature가 분포되어 있음) 이때 여기엔 머리가 긴 남자에 대한 데이터가 없다.
이때 기존의 fixed distribution에서 sampling한다면 는 훈련 데이터셋을 cover하기 위해, 또는 missing space의 combination을 가지는 데이터를 만들어내지 않기 위해 구부러진(warped) latent space를 만들어낼 것이다.
이런 상황에서는 각 visual attribute를 control하기 어려울 것이다. (예를 들어 머리카락 길이를 짧게 하는 것 만으로 남자처럼 이미지가 변한다던가.)
이와 다르게 intermediate latent space 로 mapping하는 경우, 고정된 distribtution을 따를 필요가 없기 때문에 variation factor가 더욱 linear해질 수 있다.
Perceptual path length
해당 논문에서는 latent space의 entangle 정도를 측정하기 위해서 latent space 내에서 이미지를 interpolation할 때, 이미지가 얼마나 급격하게 변하는지를 측정하려고 했다. 덜 구부러진 latent space에서 이미지의 transition이 더욱 부드러울 것이다.
Latent space 상의 두 점 , 를 spherical interpolation을 이용하여 아주 가까운 두 점으로 interpolation하고 이미지를 생성하여 두 이미지 사이의 거리를 측정한다. 이 값이 작을수록 latent space가 disentangle되었다고 볼 수 있다.
여기서 slerp은 spherical interpolation이고 d는 perceptual distance를 측정하는 VGG-16이다.
Intermediate latent space에서도 똑같이 average perceptual path length를 구할 수 있다.
Linear separability
만약 latent space가 충분히 disentangle된 상황이라면 각각의 variation factor에 해당하는 direction vector를 잘 찾을 수 있어야 한다. (어느 방향으로 변화시켜야 이미지 상 내가 원하는 변화를 만들어낼 수 있을지)
그래서 이 논문에서는 latent space내부 point들이 하나의 linear hyperplane으로부터 두 개의 구분되는 set으로 얼마나 잘 구분될 수 있을지를 측정하였다.
예를 들어 남자와 여자 얼굴을 구분할 수 있는 추가 classification 네트워크를 학습하고, 이미지 20만장을 생성하여 confidence score가 높은 10만장만 labelled latent-space vector로 사용한다. 그리고 이 10만개의 latent-space vector를 linear SVM으로 구분하여 하나의 plane으로 얼마나 잘 구분되는지를 확인하였다. (자세한 방법은 생략)
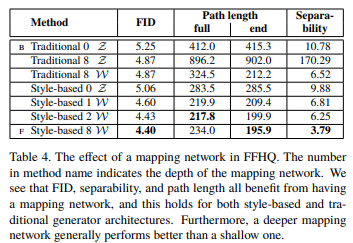
결과는 아래와 같으며, intermediate latent space를 사용할 때, 위에서 제시한 두 가지 지표에 대해 훨씬 latent space가 disentangle되어 있다는 것을 확인할 수 있었다.
Opinion
유명한 논문이고 내용도 매우 흥미롭다. 이미지 generator architecture로 오래 사용될 거 같고, STYLEGAN2, 3도 읽어야 할 것 같다.
Meaning of style
Style tranfer 연구에서는 대부분 이미지를 content와 style로 이루어진 것으로 보았고, 이미지의 style은 feature vector의 invariant statistics로 나타낼 수 있다고 생각하였다.
그리고 style을 이미지의 texture나 분위기 정도로, content를 underlying structure로 생각했기 때문에 feature vector를 content와 style로 분리하고, content vector를 바탕으로 style을 입히는 방식이 많았다.
style을 입힐 때에는 통계량으로는 보통 평균과 분산값을 사용하며, feature vector를 특정 style로 normalize하는 AdaIN 방식이 현재 가장 주로 사용된다.
반면에 이 논문에서는 이미지를 여러 style의 조합을 통해 구성되는 것으로 보고, stochastic variation이 특정 이미지 instance를 결정하는 요소로 생각하였다. noise가 없는 경우 style input만으로 이미지를 생성한다고 볼 수 있다.
Style이 의미하는 범주가 더 커진 느낌이다. invariant statistics로 구해지는 style은 이미지의 structure나 shape 등을 변화시키는 요소가 아니라고 생각했었는데, feature간의 relative importance를 재정비하는 adaIN의 연산이 생각보다 더 많은 역할을 수행하고 있는 것 같다.
Intermediate latent space
Latent space의 disentanglement 자체가 또 제일 중요하면서도 재밌는 주제인 것 같다.
Prior distribution을 training distribution에 맞춘다는 거는 예전부터 어색하게 느껴졌는데, intermediate latent space로 mapping해서 쓰는 것은 간단하면서도 합리적인 생각인 것 같고 다른 네트워크에도 쉽게 적용될 수 있을 것 같다.
MUNIT도 style vector를 gaussian에서 sampling하는데, 이것도 바꾸면 disentangle에 도움을 줄 수 있지 않을까?
