Paper : YOLOv4: Optimal Speed and Accuracy of Object Detection (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao / arxiv 2020)
Yolo의 네번째 버전.
CNN의 성능을 향상시키기 위한 수 많은 방법들 중 특정 상황에서만 잘 작동하는 feature들을 지적하면서, 어떠한 상황에서도 잘 작동하고 이론적으로도 어느정도 증명이 된 universal한 feature들을 가져다 차용함으로써 더욱 강력한 YOLO 모델을 만들었다.
Highlights
- 1080 Ti나 2080 Ti와 같은 일반적인 GPU에서도 쉽게 학습할 수 있는 효율적이고 강력한 object detection 모델 제안
- 학습 시, Bag-of-Freebies와 Bag-of-Specials 방법을 사용하며 이의 효용성 입증
- CBN, PAN, SAM과 같은 최신 기법들을 single GPU training에 적합하게끔 수정
Introduction
대다수의 CNN 기반 OD 모델들은 특정 상황에서만 잘 작동하는 경우가 많고, 가장 정확한 현대의 모델들은 real-time에서 작동하지 않으며, 학습시 large mini-batch size와 많은 GPU를 요구한다.
이번 연구는 그러한 문제를 해결하여, 일반적인 GPU로 real-time operation이 가능하며, 심지어 하나의 GPU로 학습이 쉽게 가능한 모델을 제안한다.
Related work
여러 가지 SOTA feature들을 가져다 사용한 연구인 만큼 related work가 잘 정리되어 있다.
Object detection models
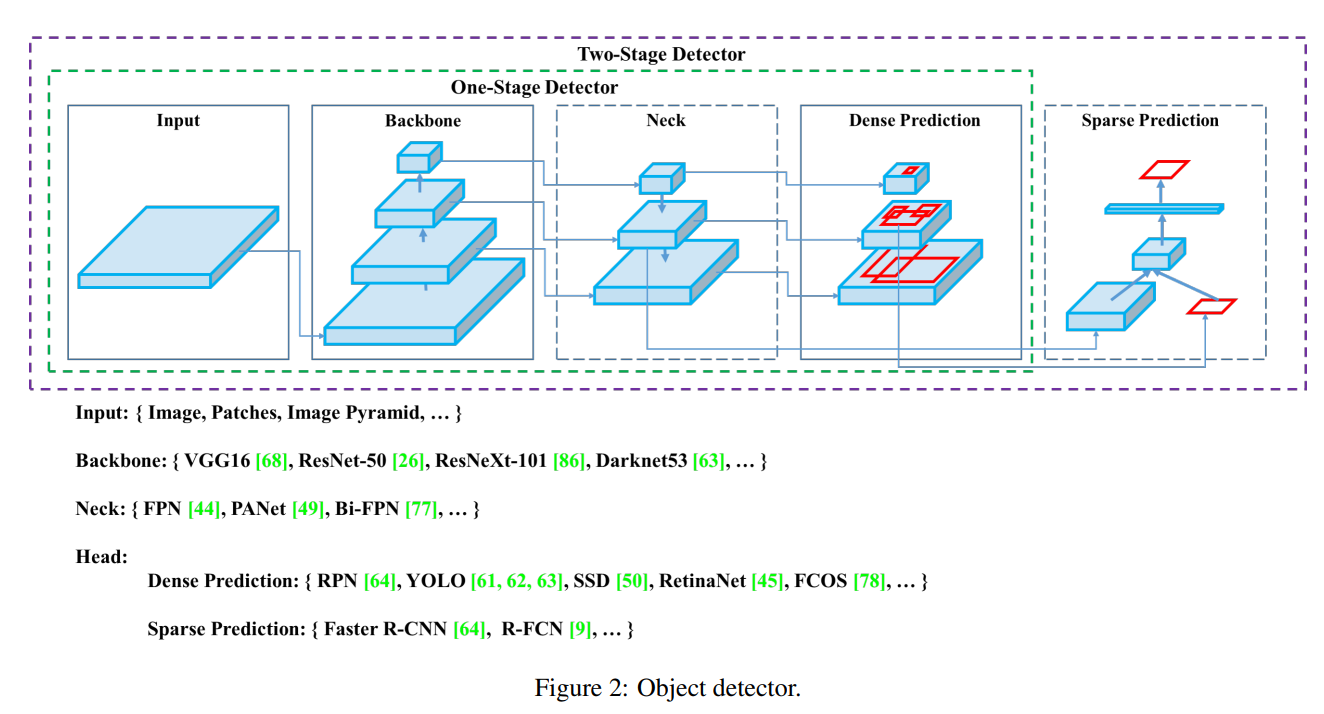
현대의 detector는 보통 backbone과 head로 이루어져있다.
먼저 backbone은 image에서 feature를 추출하기 위한 network로 보통 imageNet으로 pretrain하여 사용한다.
-
GPU에서 작동하는 detector들의 backbone
VGG, ResNet, ResNeXt, DenseNet 등 -
CPU에서 작동하는 detector들의 backbone
SqueezeNet, MobileNet, ShuffleNet
Head part의 경우 이 구조가 크게 두 종류로 나뉘는데, 하나가 one-stage object detector이고, 다른 하나가 two-stage object detector이다. 추가적으로, 1 or 2 stage detector들은 anchor 사용 여부로도 나눌 수 있다.
-
Two-stage object detector (Sparse Prediction)
- Anchor based : R-CNN 계열 모델들 (fast R-CNN, faster R-CNN, R-FCN 등)
- Anchor free : RepPoints -
One-stage object detector
- Anchor based : YOLO 계열 모델들, SSD, RetinaNet (Dense Prediction)
- Anchor free : CenterNet, CornetNet, FCOS
최근의 detector들은 backbone과 head 사이에 몇 개의 layer를 삽입하여, 서로 다른 stage (resolution)의 feature map을 collect하고 aggregate하여 성능을 올리려는 시도가 많은데, 이를 object detector의 neck이라고 하자.
Neck layer는 주로 몇 개의 bottom-up path나 top-down path로 이루어져 있으며, 이러한 mechanism을 사용한 network로는 FPN, PAN, BiFPN, NAS-FPN 등이 있다.
Bag of freebies
Inference cost를 늘리지 않으면서 detector의 성능을 올릴 수 있는 일련의 training method들을 bag of freebies라고 한다. Bag of freebies는 training 시에 약간의 cost를 증가시키지만, inference에는 전혀 영향을 미치지 않기 때문에 간단하고 효율적이다.
이 논문에서 소개한 Bag of freebies의 대표적인 예시는 아래와 같다.
- Data augmentation
- Solving problem of semantic distribution bias
- Label smoothing
- Object function of bounding box regression
1) Data augmentation
Data augmentation은 입력 이미지의 다양성을 늘려줌으로써 모델이 더 robust하게 학습되도록 하는 기법으로, 대표적으로 object detction모델을 학습할 때 주로 사용되는 예로는 photometric distortion과 geometric distortion이 있다.
이 논문에서는 Photometric distortion으로는 brightness, contrast, hue, saturation, noise 조정 등을 고려하였고, geometric distortion으로는 random scaling, cropping, flipping, rotating 등을 고려했다.
위의 예시와 같이 pixel-wise로 이미지를 조작하는 방법 말고도, object occlusion issue를 해결하고자 적용하는 방법 (Random erase, CutOut 등)들이 있는데, 이러한 방법들은 일부로 이미지 일부를 지워서 학습함으로써, 모델이 object가 겹친 상황을 잘 대처할 수 있게해준다.
이러한 개념을 feature map에 적용한 것이 바로 DropOut, DropConnect, DropBlock과 같은 방법이 된다.
추가적으로는 서로 다른 이미지를 겹치거나 (MixUp), 오려 붙힘으로써 (CutMix) data augmentation을 수행하는 방법들이 많이 연구가 되었고, style transfer GAN 등을 사용하여 data augmentation을 수행하는 방법들도 많이 연구가 되었다.

개인적으로 내가 가진 데이터의 특성을 잘 파악하고 이에 맞는 data augmentation을 사용하는 것이 매우 중요하다고 생각한다.
2) Solving semantic distribution bias
Object detection 모델을 학습할 때에는 보통 negative example의 갯수 (background 혹은 다른 class object)가 positive example (target object)의 갯수보다 훨씬 많기 때문에, data imbalance를 해결하는 것이 아주 중요한 문제가 된다.
이러한 문제를 해결하기 위해서는 Focal Loss가 주로 사용되며, 이는 output logit에 따라 loss에 weight를 줌으로써 easy example의 영향을 suppress하는 방법이다.
3) Label smoothing
Object detection 모델을 학습할때, one-hot hard representation으로는 서로 다른 class간의 관계를 표현하기가 어렵다. 이러한 문제를 해결하기 위해 labelling 단계에서 hard label을 soft label로 바꾸어 학습하는 방법을 사용하여 모델을 조금 더 robust하게 학습하곤 한다.
Soft label을 더 잘 만들기 위하여, knowledge distillation 방법이 사용되기도 한다.
4) Object function of Bounding Box regression
보통 object detector들은 bounding box regression을 위해 MSE loss를 많이 사용한다. 즉 prediction 좌표와 ground truth 좌표 사이의 MSE loss로 네트워크를 학습한다.
하지만 이 방법은 bounding box의 각 coordinate value를 독립 변수로 가정한 것으로, bounding box 자체와의 관계를 고려하지 않는다.
이를 해결하기 위해 IOU Loss가 제안되었으며, 이는 pred, gt bbox 영역 자체를 고려하여 계산된다. 또한 IOU는 scale invariant representation이므로, scale에 따라서 값이 증가하는 l1, l2 loss보다 안정적이다.
최근에는 IOU loss를 발전시키기 위하여 object의 shape과 orientation을 고려한 GIoU loss가 제안되었으며, object center의 거리를 고려한 DIoU loss 등도 제안되었다.
Bag of specials
Bag of freebies와 다르게, inference cost를 조금 증가시키는 대신에 object detection의 정확도를 크게 높여주는 plugin module이나 post-processing 방법들을 Bag of specials라고 한다.
이 논문에서 소개한 Bag of specials의 대표적인 예시는 아래와 같다.
- Enlarging receptive field
- Attention mechanism
- Feature integration
- Activation function
- Post-processing
1) Enlarging receptive field
모델의 receptive field 크기를 키우는 module에는 대표적으로 SPP (spatial pyramid pooling), ASPP, RFB 등이 있다. SPP는 backbone으로부터 얻어진 feature를 서로 다른 크기의 grid로 나누고, 각 크기의 grid에서 pooling하여 얻어진 vector들을 모두 연결함으로써, 효율적으로 receptive field를 키워준다. (ASPP도 비슷한 접근)
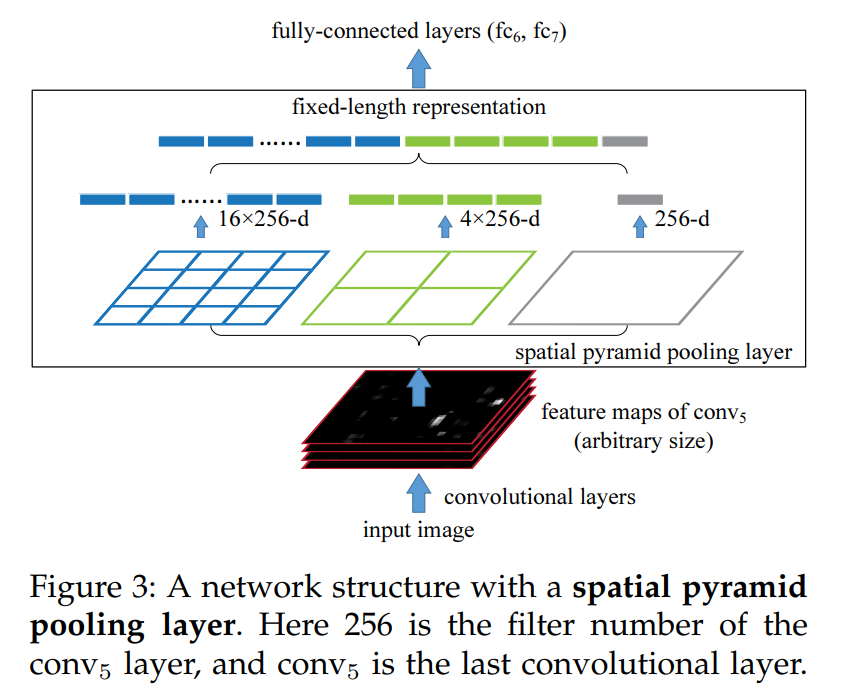
2) Attention mechanism
Object detection에서 사용되는 attention module은 크게 channel-wise attention (Squeeze-and-Excitation)과 point-wise attention (Spatial Attention Module)으로 나뉜다.
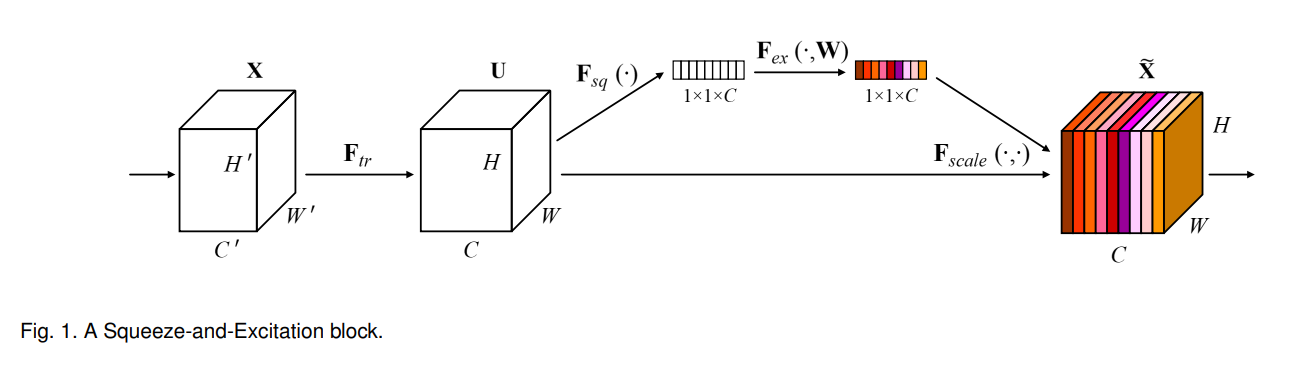
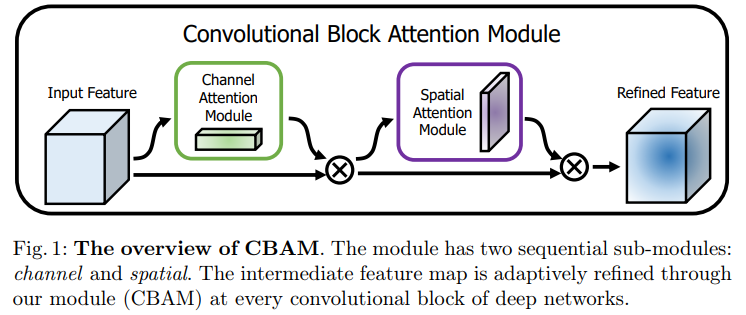
Channel attention 모듈은 feature map의 각 channel 별 중요도를 구해서 이를 고려해주고, point-wise attention은 feature map의 HW dimension에서 중요도를 구해서 고려해준다. 위 그림에서 CBAM 방법은 이를 둘 다 고려해준 연구이다.
3) Feature Integration
초기 feature integration 방법들은 low-level physical feature를 high-level semantic feature와 결합하기 위해 skip connection이나 hyper-column 등의 방법을 사용하였다.
이후 FPN (feature pyramid network)와 같은 multi-scale prediction method가 발전하면서, BiFPN, SFAM, ASFF와 같은 더 가벼운 feature pyramid integration 방법들이 제안되었다.
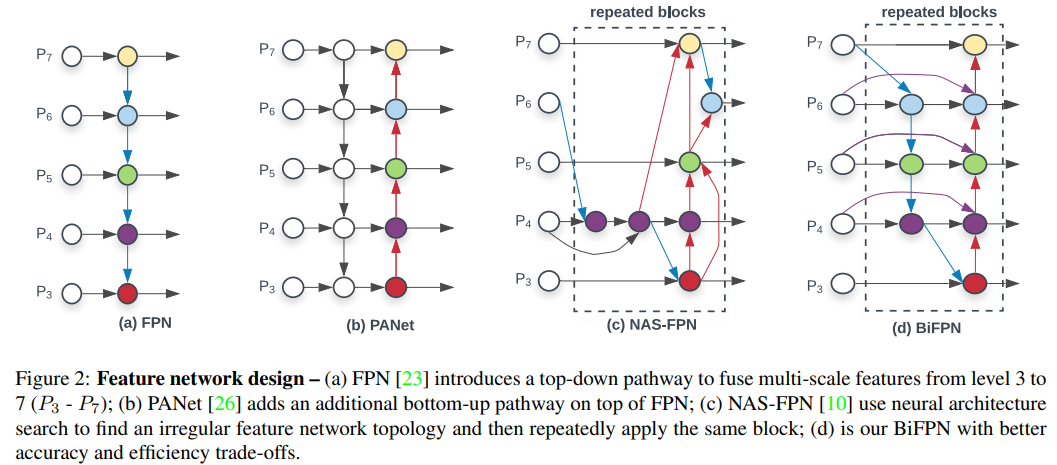
BiFPN은 이전에 efficientDet 논문 리뷰에서 공부.
4) Activation function
Activation function을 잘 설정하여 gradient가 잘 전파되도록 할 수 있는 동시에 computational cost를 줄일 수 있다. ReLU는 가장 대표적인 활성화 함수로 tanh나 sigmoid에서 발생하는 gradient vanishing 문제를 해결할 수 있다. 이어서 LReLU, PReLU, Swish, Mish 등 다양한 활성화 함수가 제안되었다.
5) Post processing
Object detection 모델에서 가장 흔히 사용되는 후처리 방법은 Non-Maximum suppression으로, 같은 object를 detect한 중복되는 여러 bounding box들 중에서, 가장 높은 confidence를 가지는 bounding box만 남기고, 나머지를 제거하는 방법이다.
이후 Soft NMS나 DIoU NMS와 같은 방법도 제안되었다.
Methodology
Selection of architecture
Architecture 선택 과정에서의 목적은 크게 아래의 두 가지로 생각할 수 있다.
-
Input network resolution, conv layer의 수, parameter 수 ()와 layer output의 수 사이의 최적의 balance를 찾는 것
-
서로 다른 backbone level에서의 feature를 aggregate하는 method와 receptive field를 증가시킬 수 있는 추가적인 block을 선택하는 것
Classification network와 다르게 object detection network에서는 조금 더 많은 요구사항이 있다.
-
Higher input network size (resolution) : 여러 개의 작은 object를 탐지하기 위함
-
More layers : input network의 size의 증가에 대응하기 위한 더 큰 receptive field를 확보하기 위함
-
More parameters : 한 이미지 내부에 존재하는 서로 다른 크기의 object들을 잘 검출하기 위해 더 큰 capacity 요구
이론적으로는 더 큰 receptive field size와 더 많은 parameter를 가진 모델이 backbone으로 선택해야 한다고 가정할 수 있다.
Receptive field size의 영향은 다음과 같다.
- Object size의 receptive field size: 네트워크가 object 전체를 볼 수 있다.
- Network size의 receptive field size: 네트워크가 object 주변의 내용을 볼 수 있다.
- Network size 이상의 receptive field size: image point와 최종 activation사이의 연결점을 늘린다.
즉, receptive field size가 늘어남에 따라 이미지 내부의 한 point에 대해 더 많은 neuron이 관여하게 되고, 그 point가 최종 output feature map에서 더 많은 point와 연결된다는 것이다. 그렇게 되면 network가 그 이미지에 대해 더욱 complex하고 abstact한 representation을 학습할 수 있다.
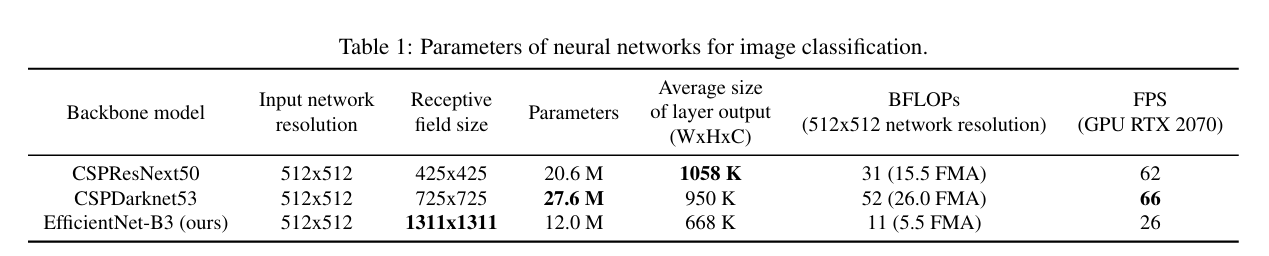
최종적으로 YOLO v4는 CSPDarknet53을 backbone으로 설정하였고, 이에 SPP block을 추가하여 receptive field를 증가시켰다. Feature aggregator로는 YOLO v3의 FPN 대신 PANet을 선택하였고, head는 YOLO v3와 같은 anchor-based head를 사용하였다.
YOLOv4
YOLOv4의 전체 architecture는 backbone이 바뀌고 SPP와 PANet이 Neck으로 사용되었다는 것 말고는 YOLOv3와 크게 다르지 않다.
그림 출처: https://wikidocs.net/167833
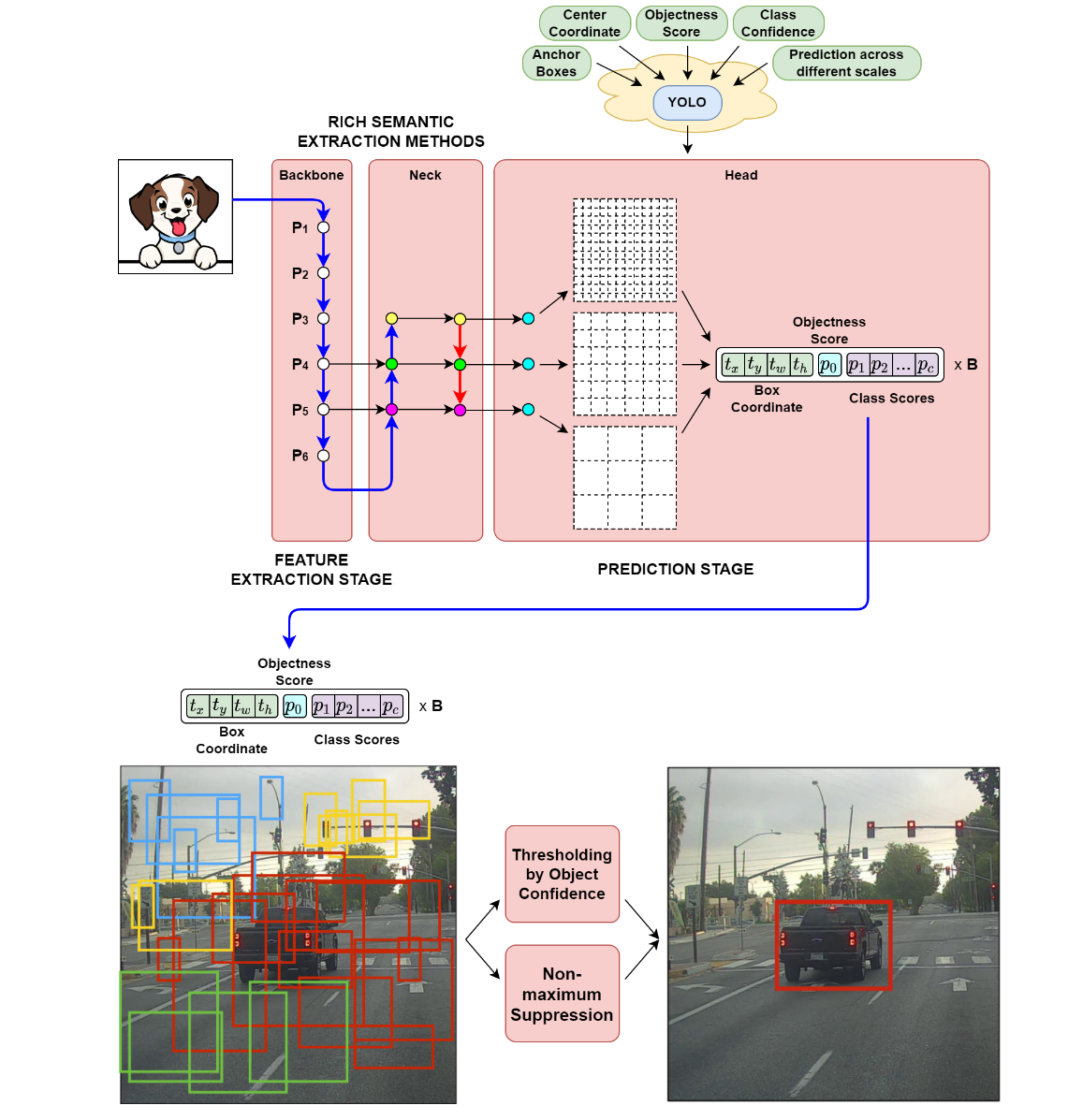
Object detection training 시에 사용되는 여러 가지 BoF나 BoS를 실험적으로 실험적으로 선택하였고, YOLOv4의 최종 feature는 아래와 같다.
- YOLOv4 consists of
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: YOLOv3
- YOLO v4 uses
- Bag of Freebies for backbone: CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
- Bag of Specials (BoS) for backbone: Mish activation, Cross-stage partial connections (CSP), Multi input weighted residual connections (MiWRC)
- Bag of Freebies (BoF) for detector: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler, Optimal hyperparameters, Random training shapes
- Bag of Specials (BoS) for detector: Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
엄청 디테일하게 model architecture 및 training strategy를 설계하였다.
Additional improvements
YOLOv4를 하나의 GPU에서 학습 가능케하기 위해 추가적인 design을 몇 가지 제안하였다.
1) Data augmentation Mosaic
CutMix에서 2개의 image를 섞어 data augmentation을 하는 것처럼 Mosaic은 4개의 training image를 섞어서 학습한다. 이를 통해 네트워크가 일반적인 맥락 밖에서 object를 탐지하도록 한다.

2) Batch normalization
Batch normalization이 각 layer 당 4개의 다른 이미지에 대한 activation statistic을 통해 수행되게 하여 mini-batch size에 덜 의존하도록 하였다.
3) Self-Adversarial Training (SAT)
SAT는 두번의 forward, backward stage를 통해 수행되는 data augmentation 기법으로, 첫번째 stage에서는 neural network가 cost function을 줄이기위해 network weight 대신에 original image를 변형시킨다. 이렇게 되면 그 이미지 내부에 desired object가 없는 것처럼 속이도록 이미지를 변형시키게 되는데, 2번째 stage에서는 이 변형된 이미지를 통해 일반적인 방법으로 학습을 시킴으로써 neural network가 스스로 adversarial attack을 가하도록 하는 것이다.
4) CmBN (Cross mini-batch normalization)
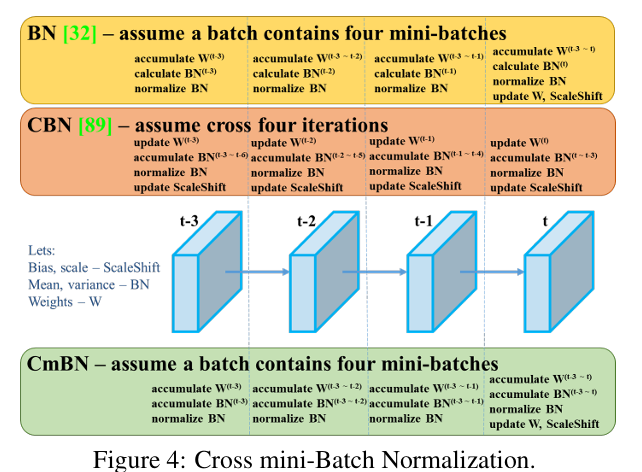
Neural network 학습시에는 gradient에 의한 parameter update에 의해 activation function에 들어가는 입력 값의 분포가 계속 바뀌게 되므로 이 함수의 분포 자체가 불안정하게 되는데, 이는 gradient-vanishing 문제를 불러일으키게 된다.
** Batch는 한번의 iteration (한번의 update)에 사용되는 데이터의 set, mini-batch는 batch 사이즈가 너무 클 때, 이를 더 세분화한 subset (weight update를 accumulate)
Batch normalization (BN)은 mini-batch 안에 존재하는 sample들의 statistic을 계산하여 이로 데이터를 normalize하고, 학습된 임의의 값으로 scale & shift하여 gradient-vanishing 문제를 해결한다.
하지만 BN은 각 batch의 statistic이 전체 training dataset의 statistic에 근사한다고 가정하기 때문에, 작은 batch에 대해서는 그 효과가 유효하지 않다고 볼 수 있다.
Cross-Iteration Batch Normalization (CBN)은 이러한 문제를 해결하기 위해 이전 iteration에서 활용한 sample의 statistic을 활용한다. 특히 매 iteration에서 network weight가 변화하게 되므로, Taylor series를 사용하여 이전 statistic과 현재 statistic을 보간하여 사용한다.
Cross mini-Batch Normalization (CBN) CBN의 변형 버전으로, 하나의 batch안에 있는 mini-batch들 사이에서만 statistic을 구하게 된다.
4) Modified SAM and PAN
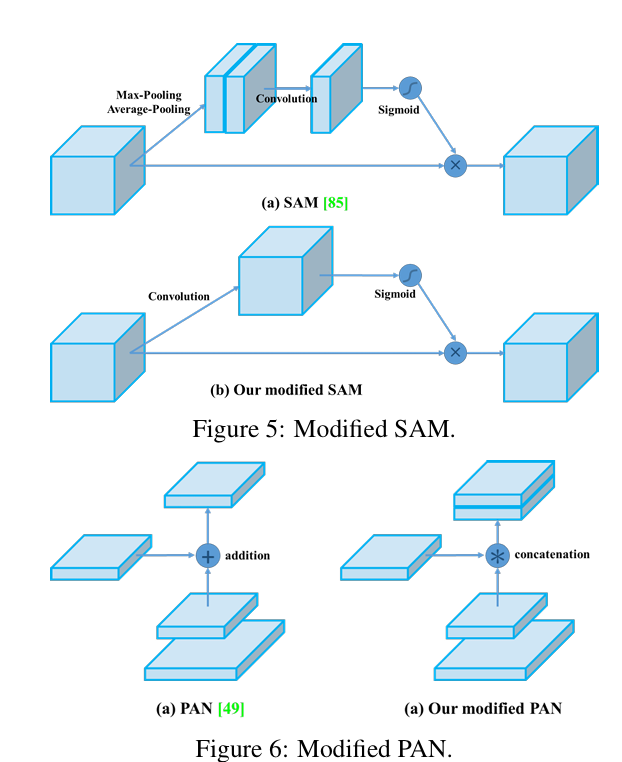
SAM을 spatial-wise attention으로부터 point wise attention으로 변형시키고, PAN에서 shortcut connection을 concatenation으로 대체하였다.
Influence of different features
위에서 언급한 많은 전략들을 바탕으로 최적의 성능을 도달하기 위해 다양한 feature에 대한 실험을 진행하였다.
1) Influence of different features on Classifier training

먼저 ImageNet image classification 실험을 통해 data augmentation / label smoothing regularization / activation function에 대한 영향을 조사했다.
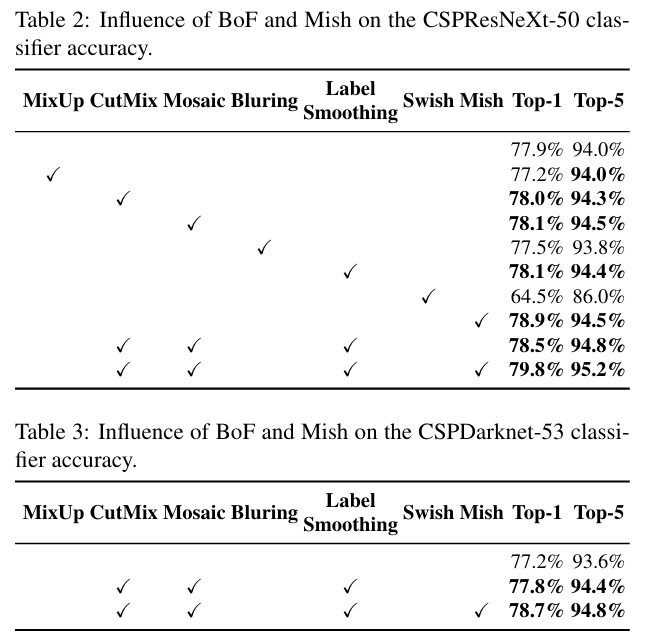
CutMix, Mosaic data augmentation과 Class label smoothing, Mish activation function을 적용하였을 때 최상의 성능을 보여주었다.
2) Influence of different features on Detector training
이어서 MS COCO object detection 실험을 통해 다양한 BoF, BoS에 대한 영향을 조사하였다.
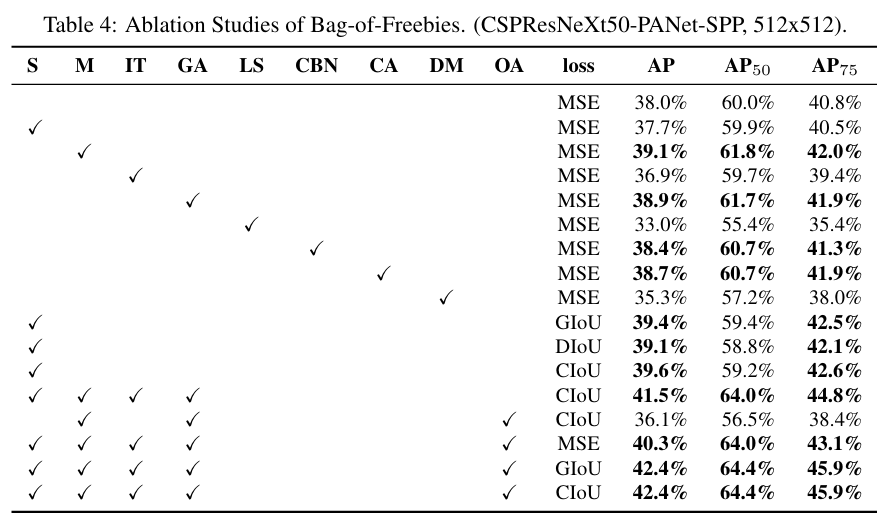
BoF는 아래의 경우 최적이다.
- grid sensitivity를 제거하였을 때
- Mosaic data augmentation을 적용하였을 때
- IoU threshold를 적용하였을 때
- Genetic algorithm으로 optimal hyperparameter를 찾았을 때
- GIoU, CIoU loss를 사용하였을 때
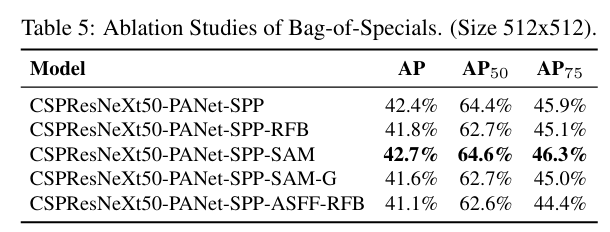
BoS는 아래의 경우 SPP, PAN, 그리고 SAM을 사용하였을 때 최적이다.
이외에도 3) Influence of different backbones and pretrained weightings on Detector training과 4) Influence of different mini-batch size on Detector training에 대해 조사하였는데, 이는 생략하는 것으로 한다.
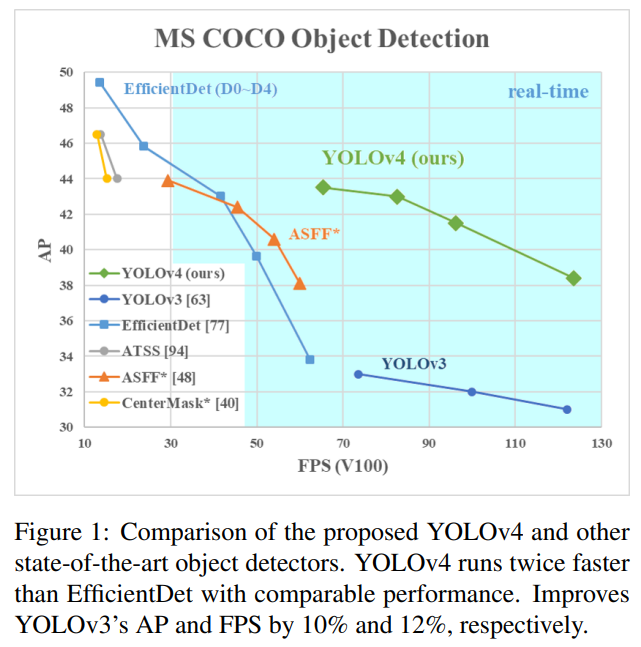
Results
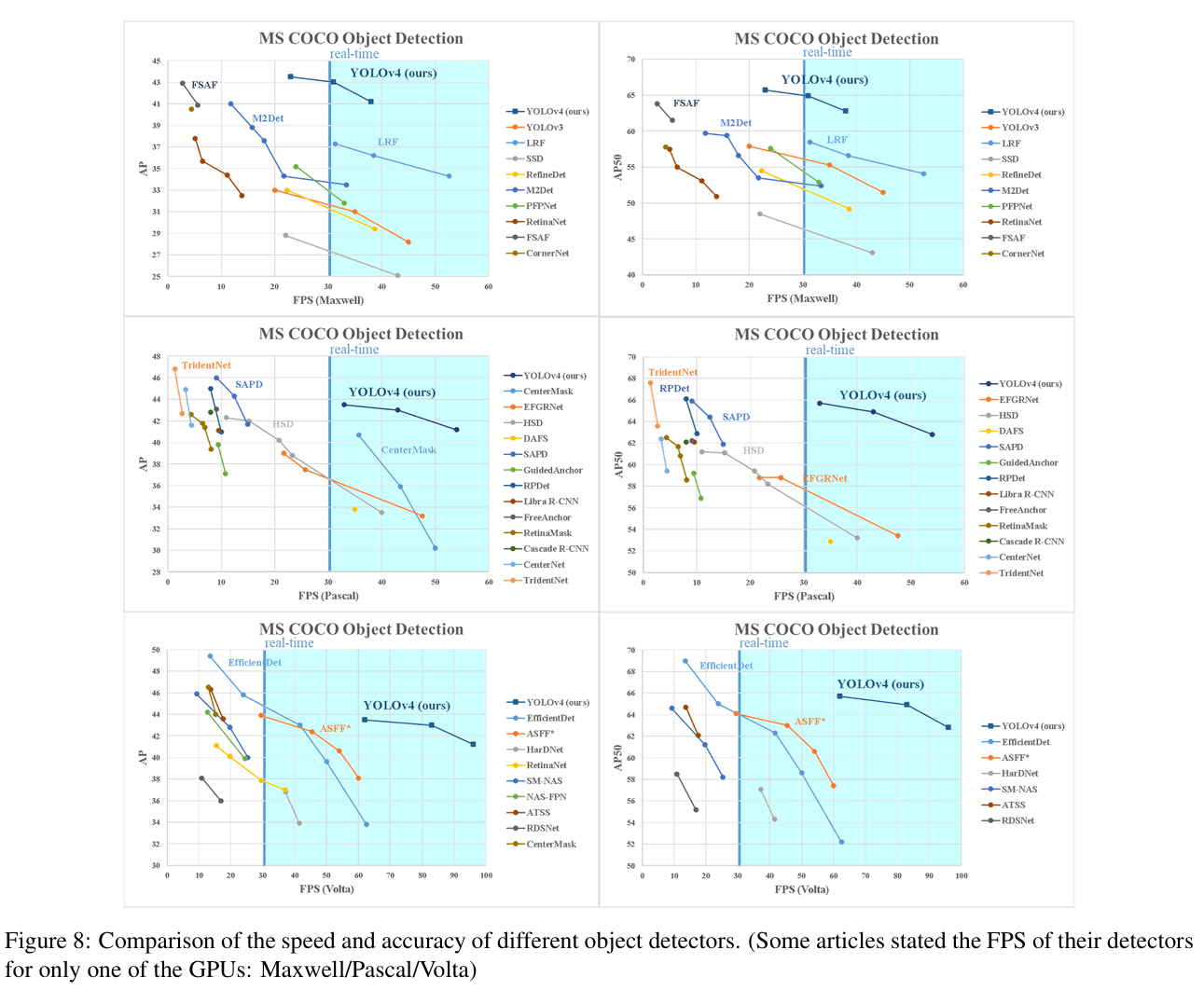
YOLOv4는 당시 speed와 accuracy 측면에서 다른 SOTA 모델들에 비해서 우세한 성능을 보여주었다.
Discussion
개인적으로 굉장히 유용한 페이퍼라고 생각한다. 현실적으로 최적의 OD 모델을 찾아나가는 과정을 자세하게 살펴볼 수 있어서 좋았고, OD 모델들의 발전사를 공부하기에 매우 적합했다고 생각한다.
이 논문 안에서도 아직 공부할게 너무나도 많고, refer가 100개가 넘어가서 이것만 다 읽어볼 수 있다면 이 분야 연구에 대해 어느정도 흐름을 이해할 수 있을 정도이다.
YOLO는 계속 현실적인 문제를 풀고있고 진화하고 있다. ultralytics라는 그룹이 이를 연구/개발해서 수 많은 application에 적용할 수 있도록 도움을 주고 있다.
다음에는 YOLOv5,6에서 어떠한 변화가 더 있었는지 리뷰해보려고 한다. (논문은 나오지 않았다.)
