Paper link : CNN vs VIT
최근 Transformer 계열의 Vision 모델들이 쏟아져 나오면서 기존의 CNN 모델들과는 어떤 차이점이 있는지 궁금했는데, 드디어!! 이 둘을 비교하는 논문이 나왔다. 본 논문에서는 다음의 관점들에서 VIT와 대표적인 CNN이라 할 수 있는 ResNet을 비교한다.
- Lower Layer와 Higher Layer 사이의 유사도(Representation Structure)
- Local/Global Spatial Information이 어떻게 사용되는가
- Skip Connection의 영향력
- localization task에서의 VIT와 CNN의 차이
- 데이터셋 규모의 중요성
Representation Structure of VITs and CNNs

Layer 사이의 유사도를 Heatmap으로 봤을 때, VIT의 경우는 Higher Layer와 Lower Layer 사이의 유사도가 전체적으로 높게 나타난다. 즉, 낮은 층의 정보가 높은 층까지 원활하게 전달된다. 반면, ResNet의 경우는 특정 층을 기준으로 양분되어 있는 형태이다. 즉, 낮은 층의 정보가 높은 층으로 전달되다 어느 순간 끊어진다는 것이다.
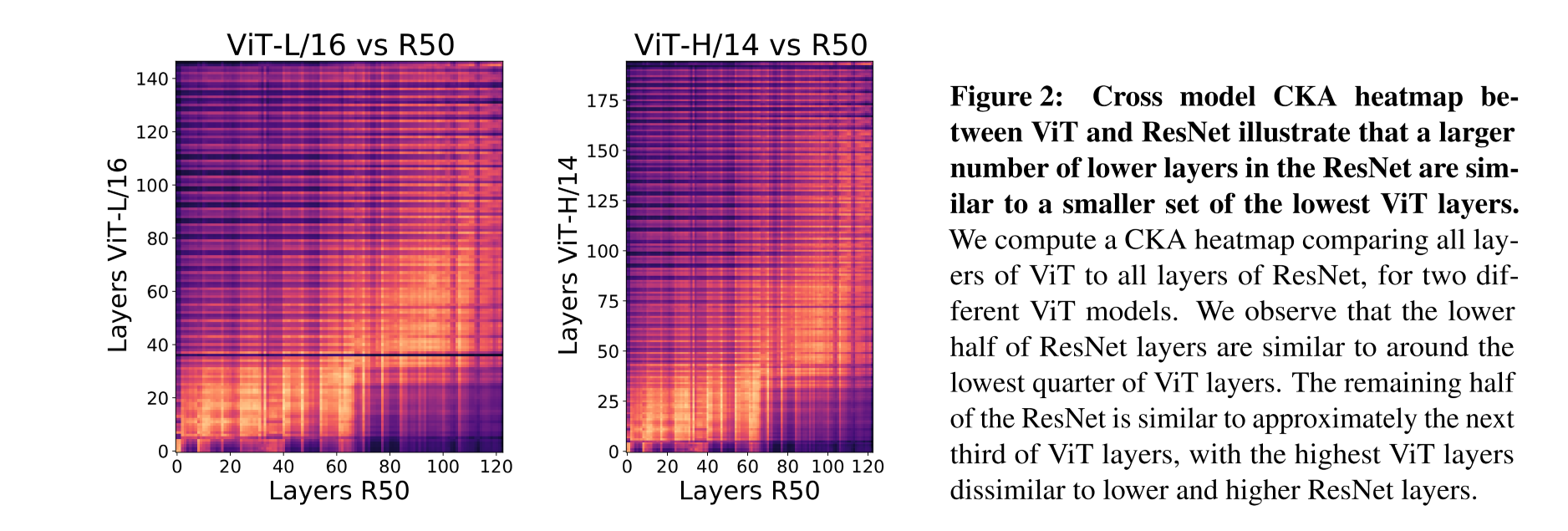
이외에도 VIT와 ResNet의 각 층에 대해서 cross-model comparison을 수행한 결과, ResNet의 하위 50%에 해당하는 층이 VIT의 하위 25%에 해당하는 층과 유사하다는 것을 확인할 수 있다. 또한, ResNet의 상위 50%에 해당하는 층은 VIT의 상위 25%까지의 층까지 유사하다는 것을 확인할 수 있다. VIT의 나머지 상위 25% ~ 0% 까지의 층은 ResNet과의 유사도가 상당히 떨어지는데, 이러한 현상이 발생하는 이유는 해당 구간에 포함되는 Layer들의 주된 역할이 CLS token representation을 다루는 것이기 때문이라고 추정하고 있다.
정리하자면,
- VIT의 Lower Layer는 ResNet의 그것과는 다른 방식으로 Representation을 계산한다. (대응되는 층의 수가 다른 것에서 낸 결론)
- VIT는 ResNet에 비해 Lower Layer에서 Higher Layer까지의 정보 전달이 원활하다
- VIT의 최상단 Layer는 ResNet과는 Representation에서 상당한 차이점을 보인다.
Local and Global Information in Layer Representations
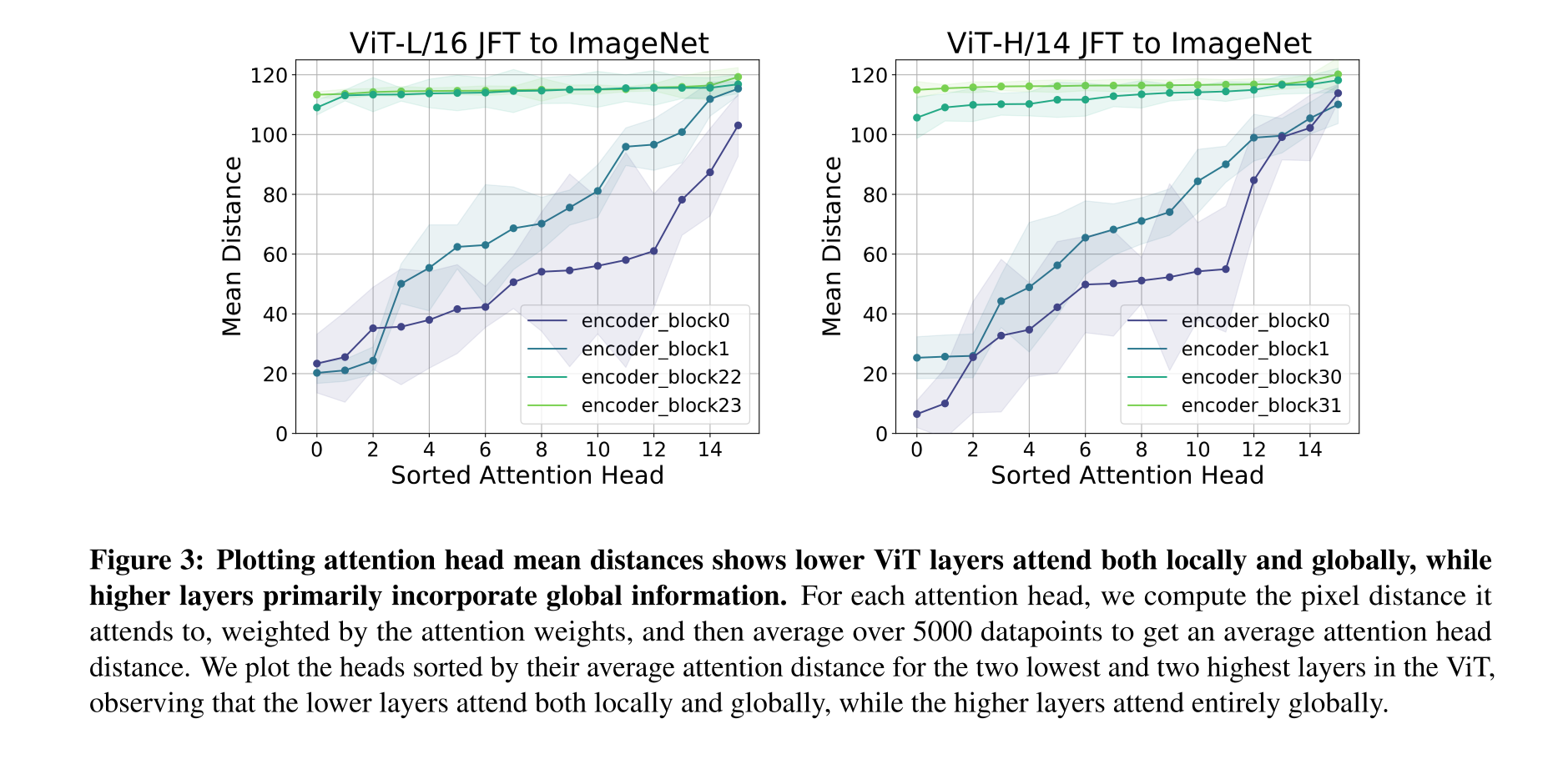
다음은 global information을 결합하는 관점에서의 두 모델의 차이이다.
즉, VIT 앞부분의 Self-Attention layer에서 얼마나 많은 양의 global information이 취합되는지, 그리고 그것이 고정된, local한 receptive field를 가지는 CNN과는 얼마나 큰 차이점이 있는지가 이번 섹션에서의 키포인트라고 할 수 있다. 그리고 저자들은 Scale과 Self-Attention distance 사이의 연관성을 밝혀낼 수 있었다.
각각의 Self-Attention Layer는 여러개의 Head들로 구성되어 있고, 각각의 Head들에 대해서 query patch의 position과 해당 patch가 참조하는 위치 사이의 거리를 구한 후, 이들에 대한 평균값을 계산함으로써 Self-Attention distance를 구하게 된다. 구체적으로, 각 Attention head에 대해서 참조하는 pixel distance를 attention weight로 weighting 해주는 프로세스를 약 5000개의 datapoint에 대해서 수행한 후 평균을 내주게 된다.
Analyzing Attention Distance
수행 결과, VIT의 가장 낮은 부분에 위치한 Layer에서도 Self-Attention layer에 local information을 처리하는 head와 global information을 처리하는 head가 혼재되어 있다는 사실을 알 수 있었다.(CNN의 경우 각각의 kernel이 한정된 위치만을 참조할 수 있기 때문에 당연히 저층부에서는 Local Information을 처리할 수 밖에 없다.) 그리고 최상단에 위치한 layer에서는 모든 Self-Attention head가 global information을 처리하고 있었다.
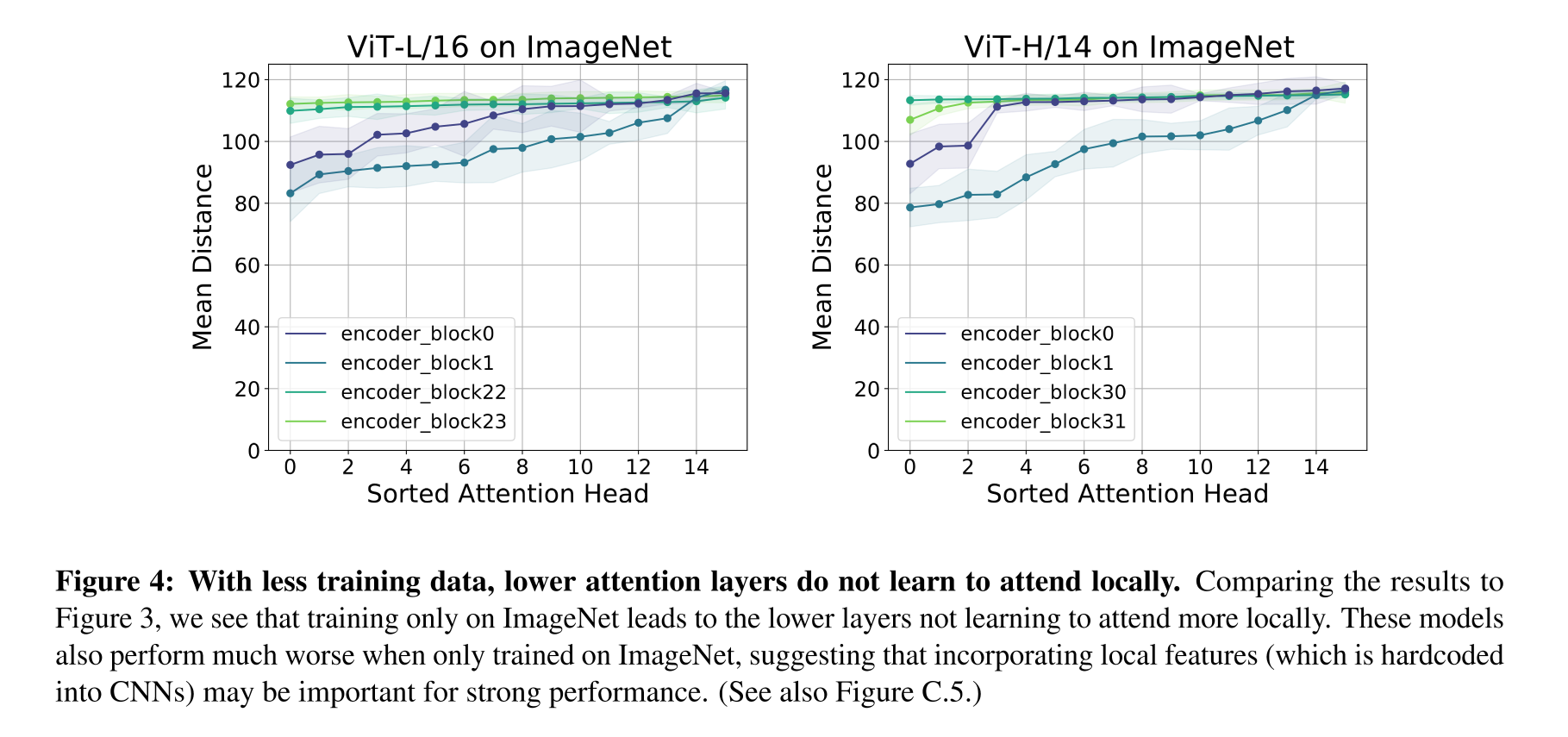
또한, 저자들은 Attention에서 Training dataset의 scale의 중요성을 알아보기 위해 ImageNet으로만 training한 모델을 이용하여 테스트를 진행하였다. 당연히 성능은 기존의 JFT dataset으로 pretraining한 VIT 모델들에 비해 더 낮았다. 중요한 것은 성능이 낮게 나오는 이유인데, 이러한 부분은 위의 Fig 3과 Fig 4를 비교해보면 캐치할 수 있다.(Fig 3 : Pretrained with JFT, Fig 4 : X)
VIT는 데이터가 충분하지 않을 경우 앞부분의 layer에서 local한 정보를 습득하지 못하며, 이러한 경우 성능이 큰 폭으로 떨어진다. 따라서, image task에서 좋은 성능을 내기 위해서는 모델의 저층부에서 local information을 활용하는 것이 중요하다는 결론을 내릴 수 있다.
Does access to global information result in different features?

lower layer에서 global information을 처리하게 되면 learned feature 역시 다를 것인지도 중요한 주제라고 할 수 있다. VIT의 첫 번째 encoder block에서 각각의 Head들의 참조 영역을 고려하여 subset을 추출한 후 ResNet의 lower layer Representation과 비교하는 interventional test를 수행하였다.
그 결과는 위의 Fig 5와 같다. mean attention distance가 증가할수록 둘 사이의 유사도는 이와 반대로 monotonic하게 감소하는 것을 확인할 수 있다. 즉, lower layer에서 global information을 참조하는 Self-Attention layer는 local한 정보만을 참조하는 Convolutional layer와 representation 측면에서도 다를 수 밖에 없다.
Effective Receptive Fields
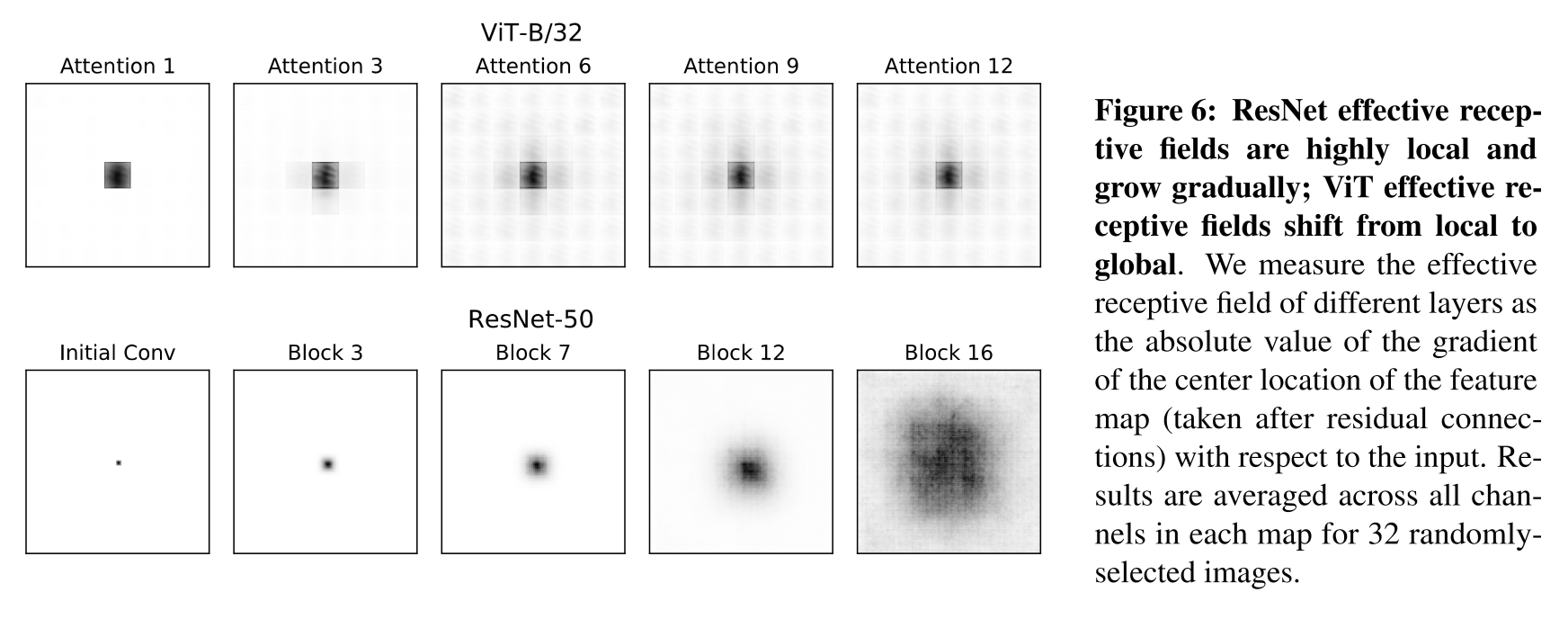
VIT의 lower level에서의 Effective Receptive Field가 ResNet에 비해 훨씬 더 넓다는 사실을 확인할 수 있었다.(Effective Receptive Field) 또한, ResNet의 ERF가 점진적으로 커지는 것에 비해, VIT는 네트워크 전반에 걸쳐서 global한 특성을 가진다는 사실을 확인할 수 있었다. 추가로, Fig 6 부분을 보면 VIT의 receptive field는 강력한 residual connection이라는 특성 덕분에 lower layer부터 higher layer까지 네트워크 전반에 걸쳐서 center patch 부분이 부각되는 것을 확인할 수 있을 것이다. (간단히 보면, ResNet의 경우는 점차 낮은 층의 정보가 높은 층에서 취합되면서 Receptive Field가 초반과는 전혀 다른 형태로 확대되지만, VIT의 경우는 낮은 층의 Receptive Field의 형태는 그대로 유지하면서 참조하는 영역이 확대되는 것을 확인할 수 있음)
Representation Propogation through Skip Connection
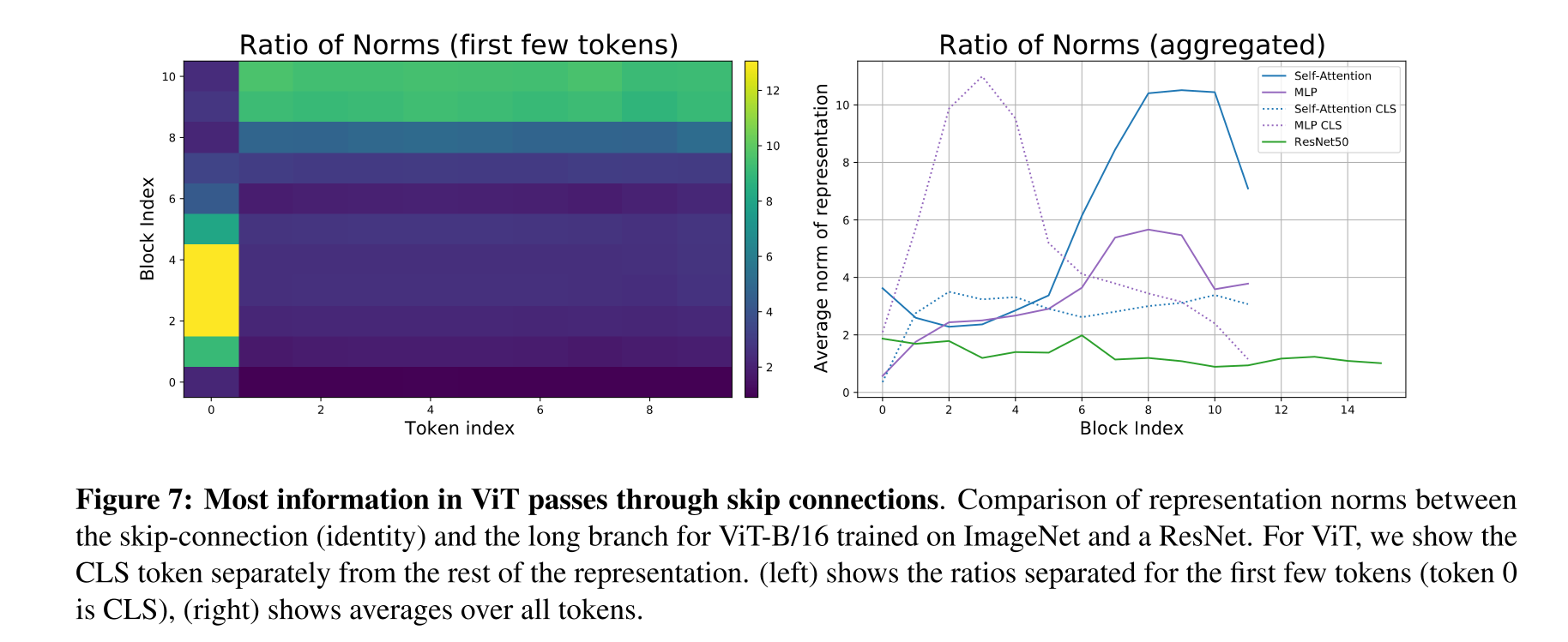
이전 장들에서는 lower layer에서의 global information의 유무 때문에 VIT와 ResNet의 Representation structure는 큰 차이를 보인다는 것을 설명하였다. 그리고, VIT representations의 uniform한 특성으로 미루어 봤을 때, lower representation이 higher layer로 상당히 원활하게 전달된다는 점을 추측할 수 있다.
본 섹션에서는 VIT에서의 skip connection의 영향력을 알아보기 위하여 norm ratio 를 측정한다.
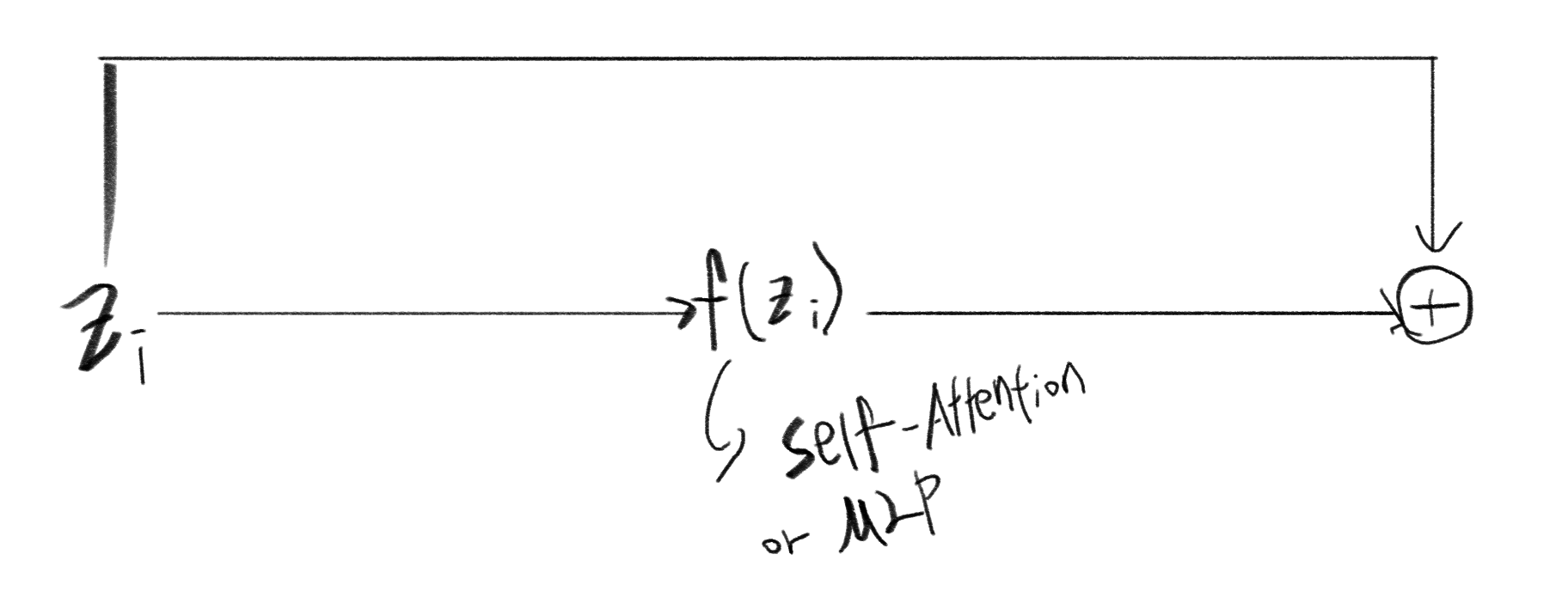
와 는 다음과 같이 그림으로 표현할 수 있다. 그리고 여기서 둘 사이의 비율인 가 높게 나타난다는 것은 skip connection을 통해 전달되는 정보의 양이 크다는 뜻이며 반대의 경우 skip connection의 영향이 보다 크지 않다는 의미로 해석할 수 있다.
실험의 결과는 위의 Fig 7을 통하여 확인할 수 있다.
좌측의 heatmap은 각각의 token representation들에 대한 norm ratio 값을 나타낸 것이다. 네트워크의 전반부에서는, CLS token(0번째 token) representation이 skip connection을 통하여 우선적으로 전파되었다.(norm ratio가 높았다) 반면, spatial token representation들의 경우는 norm ratio가 낮게 나왔다. 그리고 이러한 경향성은 네트워크의 후반부에서 반전되었다.
우측의 도표는 ResNet50, VIT의 CLS token, 그리고 VIT의 Spatial token의 norm ratio를 시각화한 것이다. 해당 도표를 통해서 위에서 언급한 경향성을 그대로 확인하는 동시에 한 가지 중요한 정보를 더 확인할 수 있다. VIT에서의 skip connection은 ResNet에 비해 훨씬 강한 영향력을 발휘한다.

또한 저자들은 특정 layer에서 skip connection을 제거하고 layer들 사이의 유사도를 측정하는 실험을 진행하였는데 결과가 상당히 쇼킹하다.
skip connection을 제거한 layer를 기준으로 위아래의 layer들이 별개의 feature를 학습하고 있는게 아닌가 싶을 정도로 유사도가 떨어지며, 퍼포먼스는 거의 4% 가량 떨어진다. 해당 실험 결과를 통해 첫 번째 섹션에서 설명한 VIT의 uniform representation structure에서 skip connection이 차지하는 지분이 상당히 크다는 부분을 유추할 수 있었다.
Spatial Information and Localization

위의 다른 섹션들에서 설명한 내용들로 미루어 봤을 때, VIT에서 input의 spatial information이 higher layer에서도 보존이 되는가 역시 중요한 주제라고 할 수 있다. 그리고 해당 주제에 대하여 ResNet과 비교하는 것 역시 필요한 부분이라고 할 수 있다.
저자들은 VIT와 ResNet의 higher layer들에서의 token representation들과 input patch들을 비교하는 방식으로 실험을 진행하였다. 이 때, VIT의 경우는 input으로 이미지를 잘라서 patch 형태로 만든 후 linear projection을 수행하고 token값을 붙여주기 때문에 큰 상관은 없지만 ResNet은 이러한 프로세스를 거치지 않기 때문에, 별도로 처리를 해주었다.
실험의 결과는 위의 Fig 9를 통하여 확인할 수 있다. 각각의 heatmap은 input patch와 final block의 output patch 사이의 유사도라고 보면 된다.
결과를 보면, VIT의 경우, 이미지의 edge 부분에 해당하는 token(CLS token)의 경우는 이미지의 edge 부분과 전체적으로 높은 유사도를 보이는 것을 확인할 수 있고, 이미지 내부에 해당하는 다른 token들은 해당하는 input과 output이 잘 매칭이 된 것을 확인할 수 있다.(사실, CLS token이 이미지의 Edge 부분의 patch에 해당한다는 사실이 잘 이해가 가지는 않는다.... 위의 heatmap만 봤을 때, 타겟의 전체적인 윤곽을 표현하는 patch라고 보는 것이 더 타당한 것 같다). 반면, ResNet의 경우는 그냥 구리다.
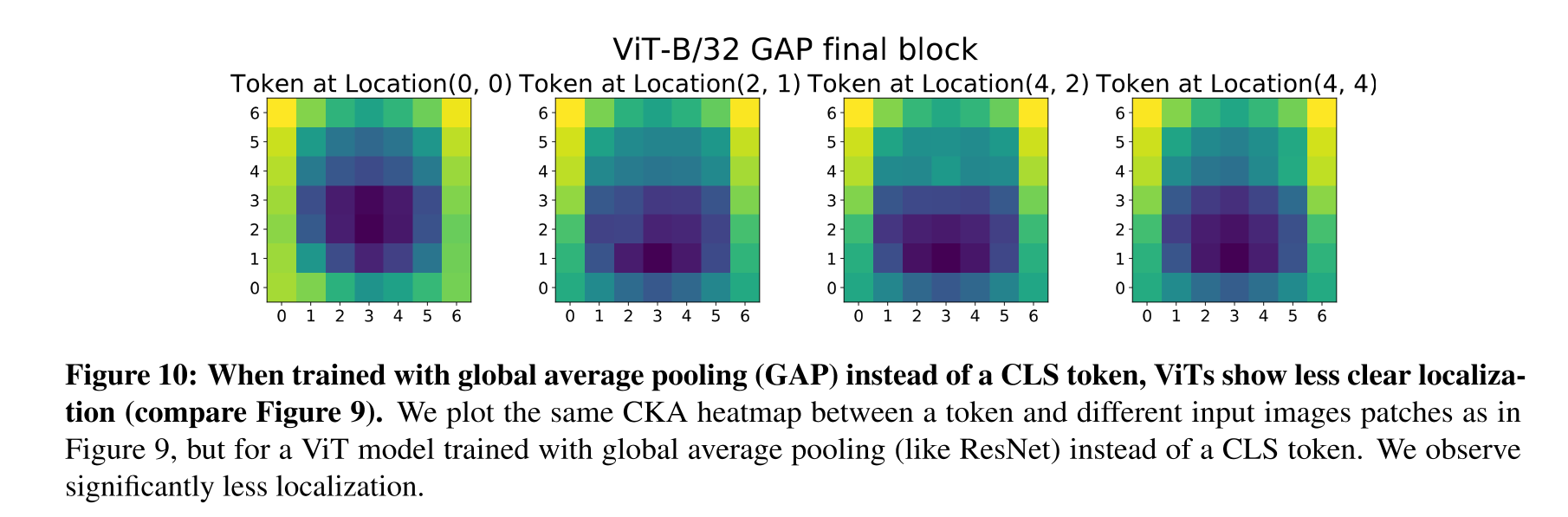
그런데, 이렇게 결과가 극명한 차이를 보이는 이유가 있다. 바로 Global Average Pooling 때문이다. VIT의 경우는 별도의 CLS token을 통해서 분류를 수행하지만, ResNet은 막바지에 GAP를 달아줘서 고차원의 Feature를 뭉게주는 과정을 수행하게 된다. 따라서, 저자들은 VIT에도 똑같이 GAP를 달아서 localizing을 수행하였는데, 결과는 위의 Fig 10과 같다. Fig 9의 ResNet과 마찬가지로 구리게 나왔다.
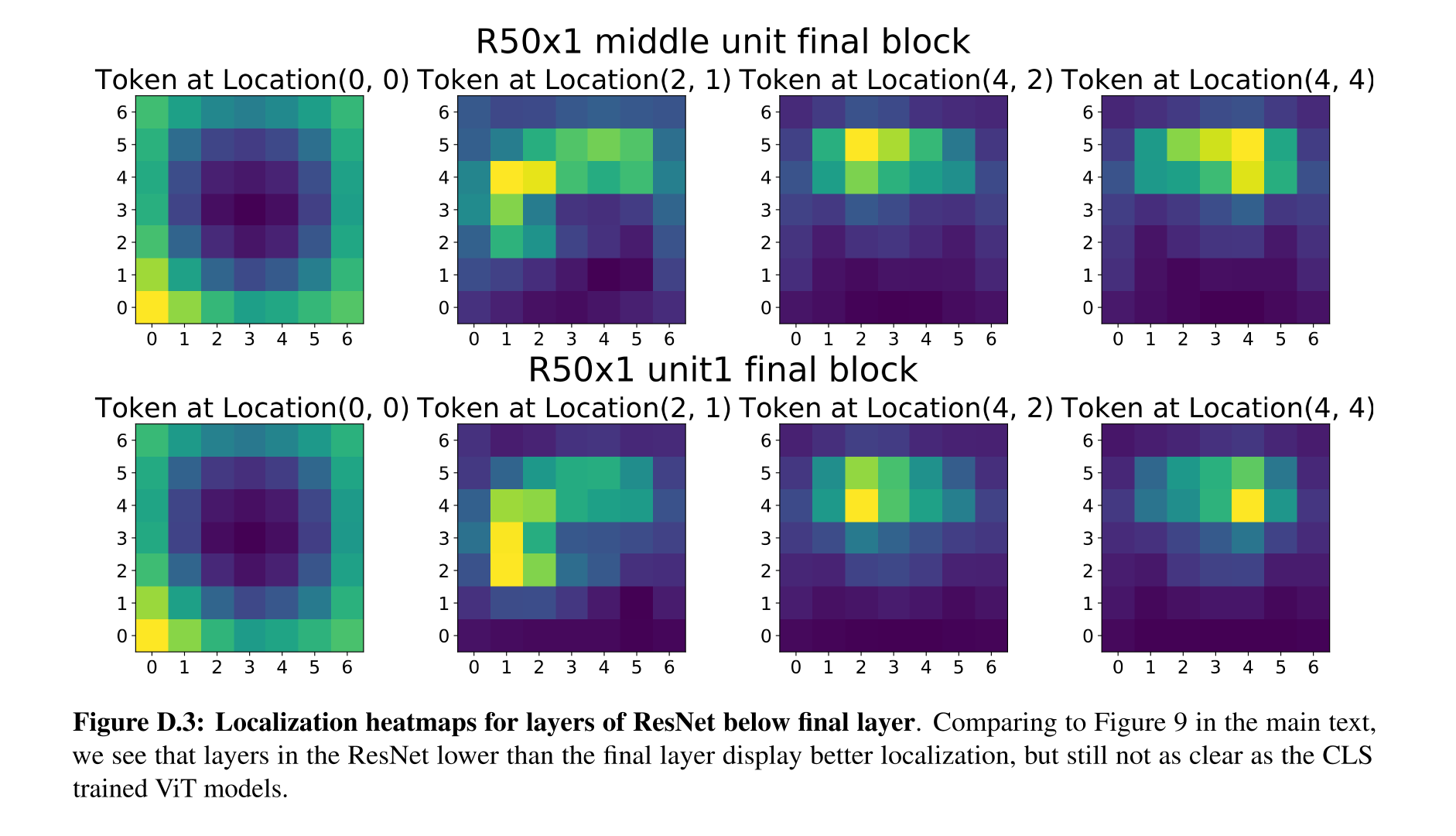
이러한 요인 때문에, Appendix에서는 final layer 바로 앞단의 layer를 통해 실험한 heatmap을 제시하였다. Fig 9의 첫 번째 줄과, Fig D.3의 두 번째 줄을 비교하면 된다. GAP를 제외하였을 경우 확실히 localizing이 잘 된 것 같지만 그래도 VIT에 비해 그 정밀함이 다소 떨어지는 것을 확인할 수 있다.
Localization and Linear Probe Classification
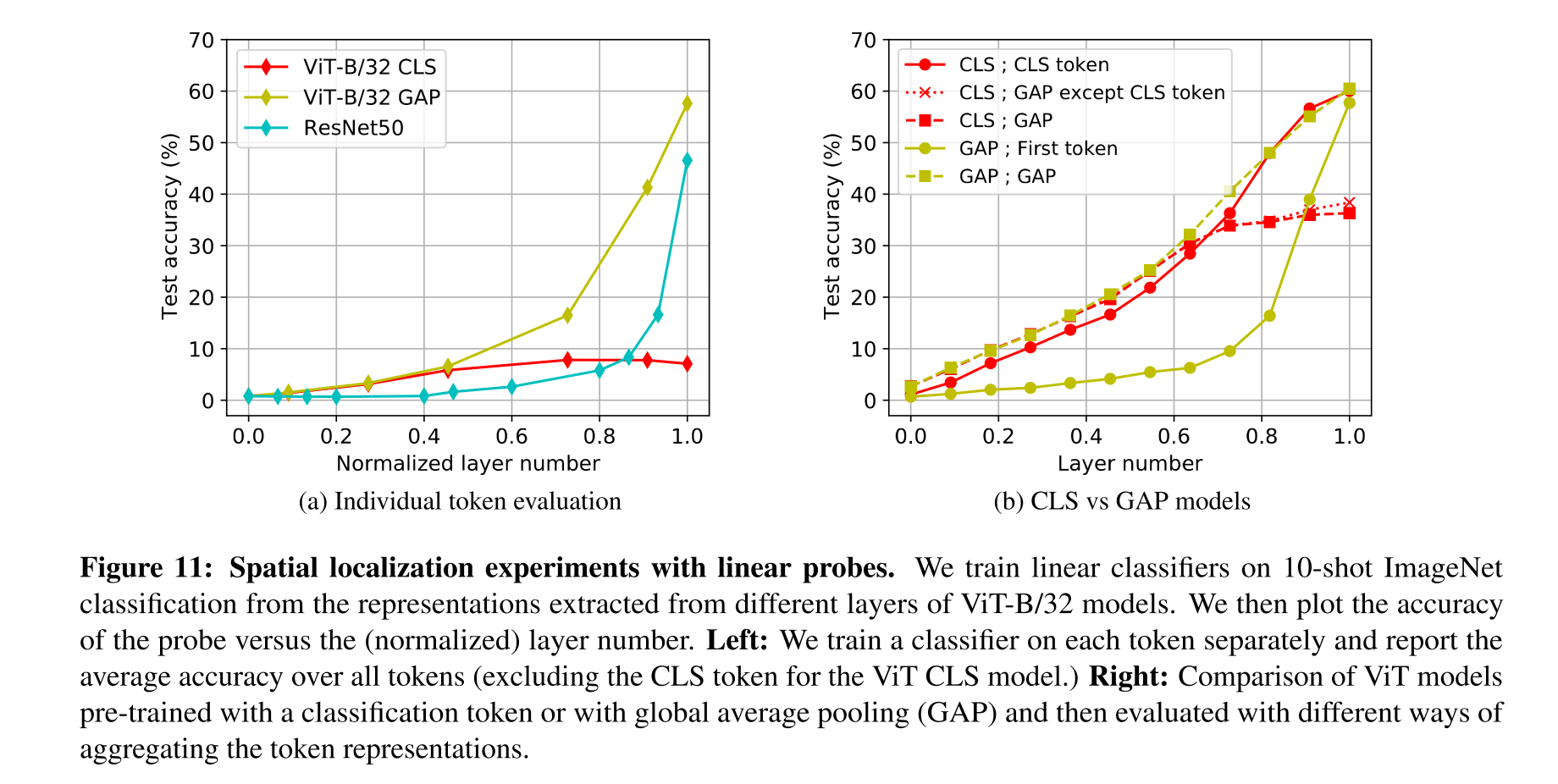
이 외에도, linear probe라는 기법을 이용하여(linear classifier probes), 각각의 token과 layer들에 대하여 classification task를 진행하였으며 결과는 위의 Fig 11에서 확인할 수 있다.
왼쪽의 그래프는 각각의 token에 대해서 학습한 classifier들의 평균 accuracy인데, GAP를 적용한 ResNet과 VIT가 higher layer에서 높은 성능을 보이는 것에 비해 CLS token으로 학습한 경우, spatial token들이 분류 작업에서 제 역할을 하지 못하는지 성능이 전체적으로 좋지 않다. 그리고 이러한 이유는 해당 token들의 representation이 higher layer에서도 spatially localized되어 있기 때문이라고 추정한다. 그리고, 이러한 추정에 대한 근거는 오른쪽 도표에서 찾을 수 있는데, VIT-GAP 모델에서 한 개의 token을 사용하였을 때나 모든 token에 대하여 GAP를 수행하였을 때나 higher layer에서의 성능이 엇비슷한 것을 확인할 수 있다.
정리하자면, GAP를 활용한 모델의 higher layer의 token들은 모두 비슷한 global representation을 학습한다고 볼 수 있다.
+뇌피셜을 더하자면, CLS token으로 classification task에 대하여 학습한 경우, cls token에 global한 정보들이 쏠리게 되고 나머지 token들은 큰 역할을 하지 않게 되는 것 같다. 당연히 이렇게 학습한 token들을 나중에 추론 과정에서 GAP 해봐야 쓸모 없는 spatial token들의 영향으로 평균 정확도가 낮게 나오게 되는 것이고.... 반면, GAP로 학습한 모델의 경우는 모든 token들에서 global한 represenation들을 학습하게 되는 것 같다.
Effects of Scale on Transfer Learning
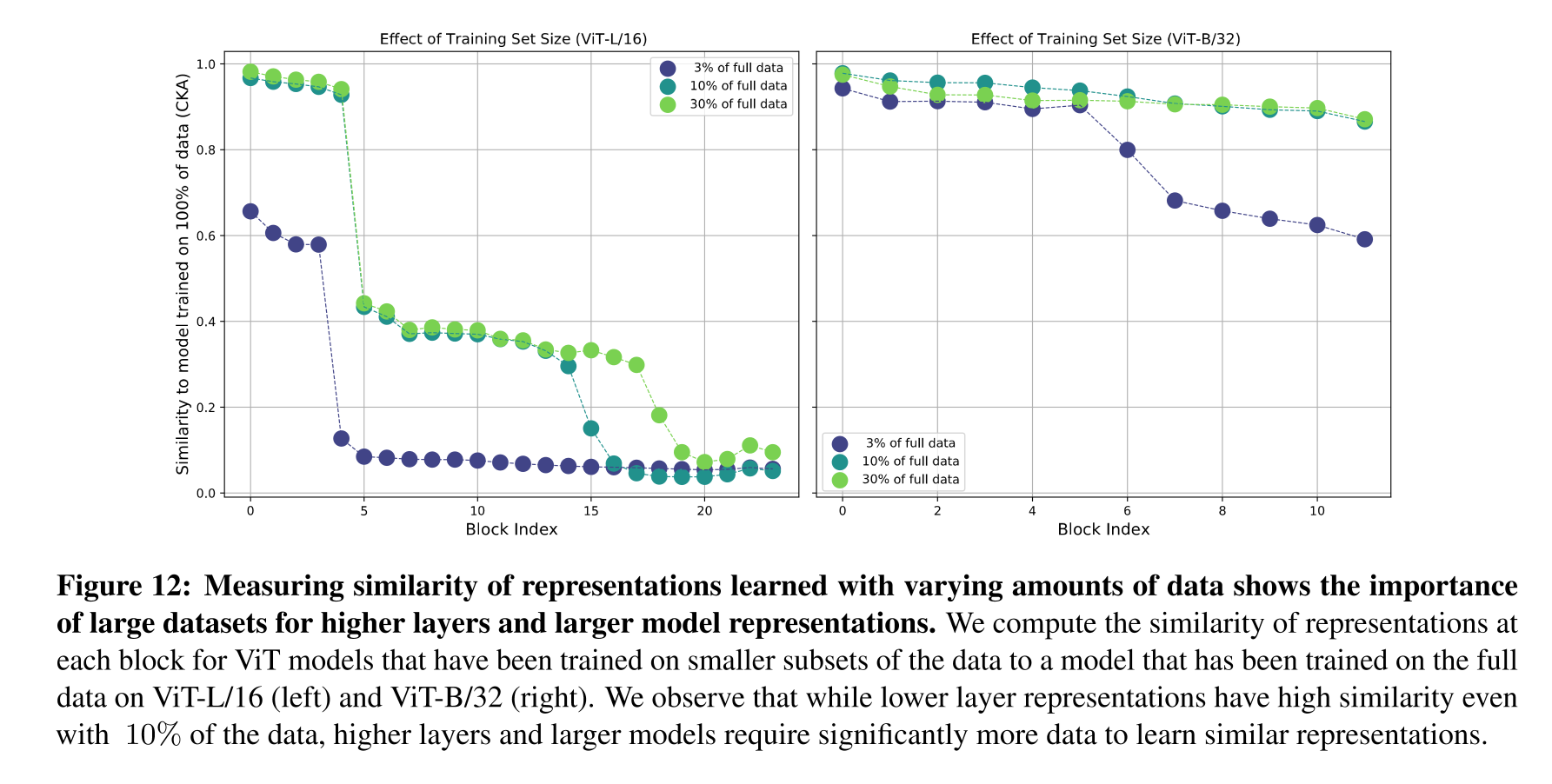
본 섹션에서는 transfer learning을 수행할 때, dataset의 크기가 representation에는 어떠한 영향을 끼치는지에 대해 알아보기 위한 실험을 수행하였다.
실험한 결과는 Fig 12와 같으며, 두 그래프는 VIT-L, VIT-H를 본래 크기의 데이터셋으로 pretraining한 것과, 일부만으로 pretraining한 것의 각각의 layer들에 대하여 유사도를 구한 것이라 생각하면 된다.
우선 standard VIT에서 pretraining한 JFT 데이터셋의 규모를 줄여서 실험을 진행하였다. 그 결과 전체 데이터셋의 3%만을 사용하더라도 lower layer representation은 본래의 것과 크게 다르지 않다는 사실을 알 수 있었다. 하지만, higher layer에서는 그 유사도가 크게 떨어지는 것으로 보아 동일한 수준의 representation을 학습하기 위해서는 보다 더 많은 데이터셋이 필요하다는 사실을 알 수 있었다. 그리고 이러한 경향은 모델의 사이즈가 클수록(VIT-L) 더 두드러졌다.

Fig 13의 왼쪽 도표는 비교적 큰 사이즈의 VIT-H, VIT-L을 JFT와 ImageNet으로 pretrain한 후 이전 섹션에서의 linear probe로 비교한 결과이다. 그 결과 JFT로 pretrain한 모델이 ImageNet에 비해 심지어 중간 layer의 representation에서도 월등히 높은 accuracy 를 보이는 것을 확인할 수 있다. 이러한 결과로 미루어 봤을 때, 대규모 모델에서 high quality intermediate represention을 학습하기 위해서는 큰 규모의 데이터셋이 필요하다는 사실을 유추할 수 있다. 그리고 이러한 결론은 오른쪽의 그래프를 통해서 어느 정도 뒷받침할 수 있다. 오른쪽의 도표는 VIT와 ResNet을 모두 JFT에 대하여 pretrain한 결과인데, 마찬가지로 대규모 데이터셋에 대하여 학습한 VIT가 ResNet에 비하여 훨씬 강력한 intermediate representation을 학습한다는 사실을 알 수 있다.(VIT가 ResNet에 비해 사이즈가 크기 때문에 이렇게 말한게 아닌가 싶다.)
