CV
1.Polarized Self-Attention
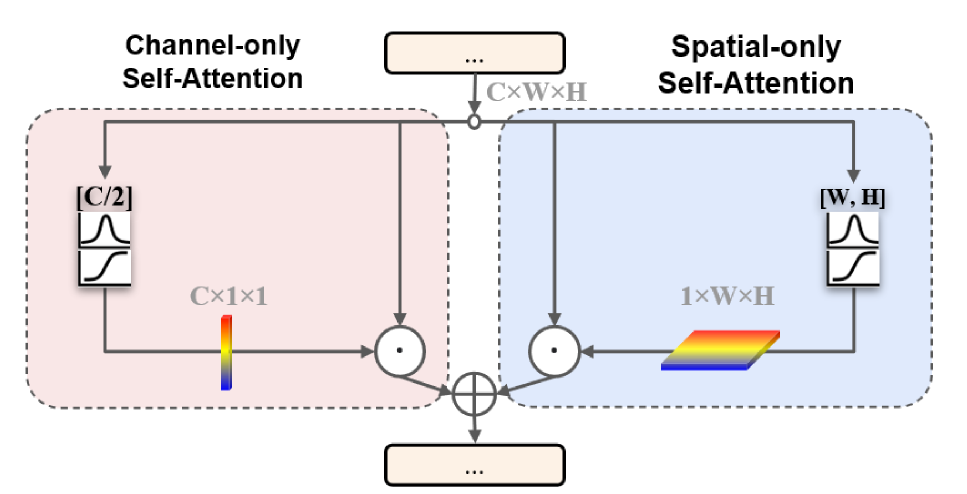
Abstract Pixel-Wise Regression은 keypoint heatmap을 추출하고 semantic mask를 생성하는 등 CV task에서 흔히 수행되는 작업이지만 낮은 computational overhead를 유지함과 동시에 고해상도의 input/
2021년 8월 15일
2.HRNet

semantic segmentation, human pose estimation과 같은 Position-Sensitive task에서는 High resolution representation을 보존하는 것이 중요하다. 하지만, 기존의 모델들에서는 input을 low
2021년 8월 20일
3.Do Vision Transformers See Like Convolutional Neural Networks
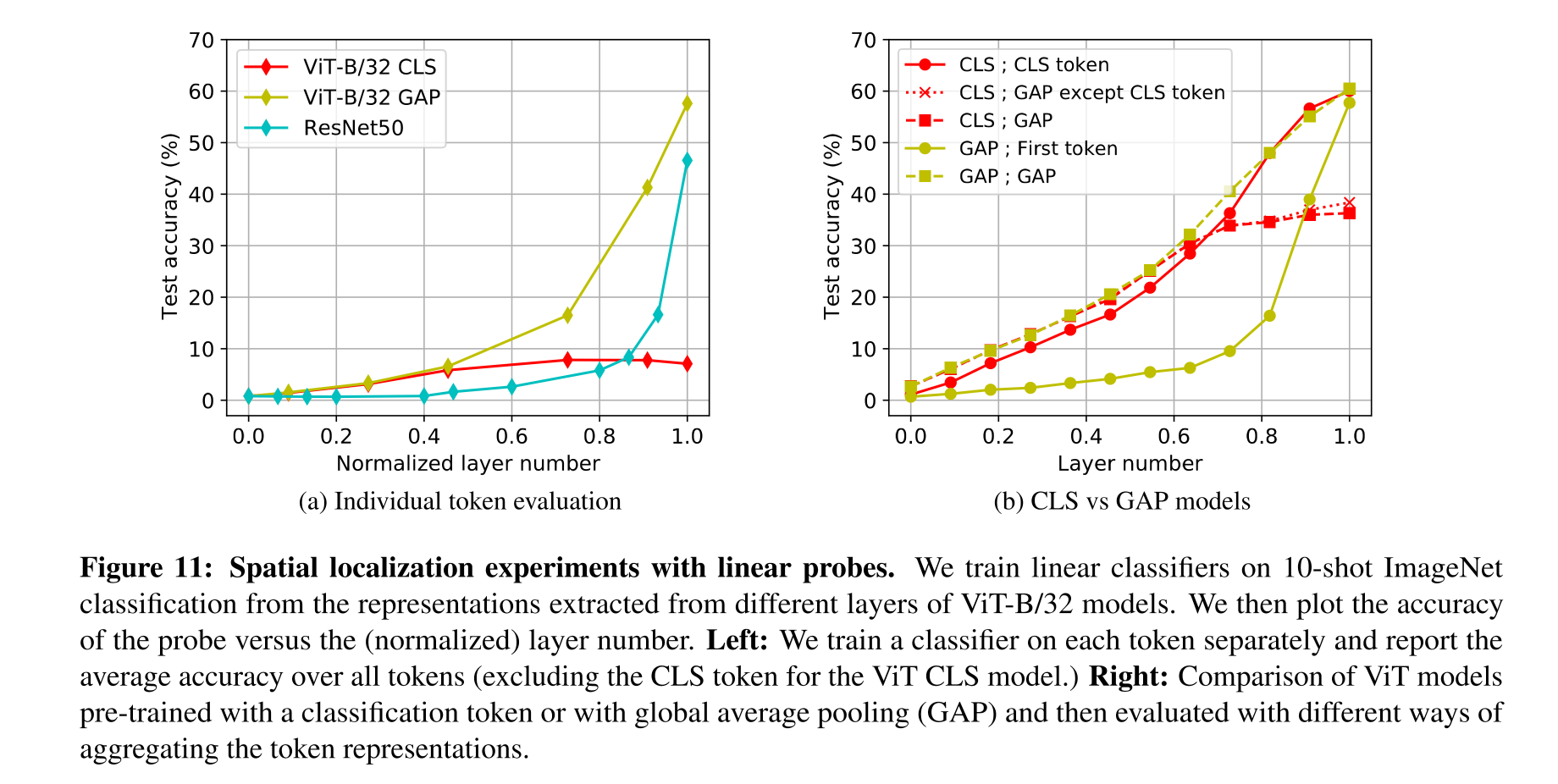
Paper link : CNN vs VIT 최근 Transformer 계열의 Vision 모델들이 쏟아져 나오면서 기존의 CNN 모델들과는 어떤 차이점이 있는지 궁금했는데, 드디어!! 이 둘을 비교하는 논문이 나왔다. 본 논문에서는 다음의 관점들에서 VIT와 대표적인
2021년 9월 4일