Abstract/Intro
semantic segmentation, human pose estimation과 같은 Position-Sensitive task에서는 High resolution representation을 보존하는 것이 중요하다. 하지만, 기존의 모델들에서는 input을 low resolution으로 압축한 후 이를 다시 high resolution representation으로 복원하는 방법을 사용해 왔다.
HRNet은 이들과는 다르게 모든 프로세스에서 high resolution representation을 보존한다. 또한, low resolution representation을 출력하는 branch 역시 병렬적으로 구성하였다. 번째 stage에서의 출력은 개의 high-low resolution representation으로 구성되어 있으며 각 stage가 끝날때 마다 feature를 fuse하는 부분 역시 존재한다. 이렇게 high resolution을 유지하면서 multi scale fusion을 수행한 HRNet은 semantic한 관점에서 더 강건하며 spatial한 관점에서 역시 마찬가지로 보다 더 정밀하다.
HRNet에는 크게 세 가지 버전이 있다.
- HRNetV1: 개의 branch 중에서 가장 해상도가 높은 결과물만을 output으로 내보내며 Keypoint Detection task에 활용한다.
- HRNetV2: high resolution부터 low resolution까지 모든 representation을 결합하여 내보내며 Semantic Segmentation task에 활용된다.
- HRNetV2p: multi-level representation으로, HRNetV2의 high resolution representation output을 Faster R-CNN, Mask R-CNN과 같은 SOTA detection/instance segmentation framework에 적용한다.
Detail
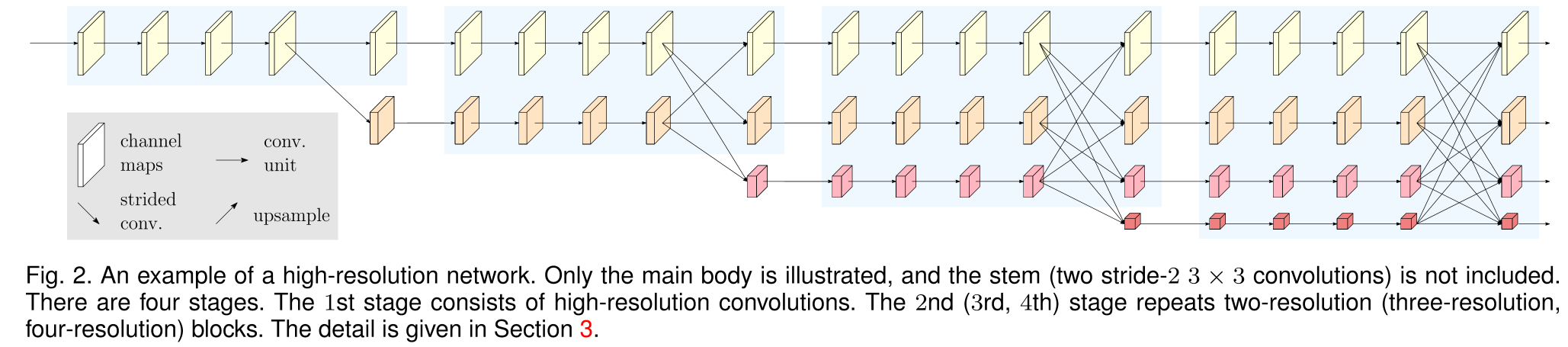
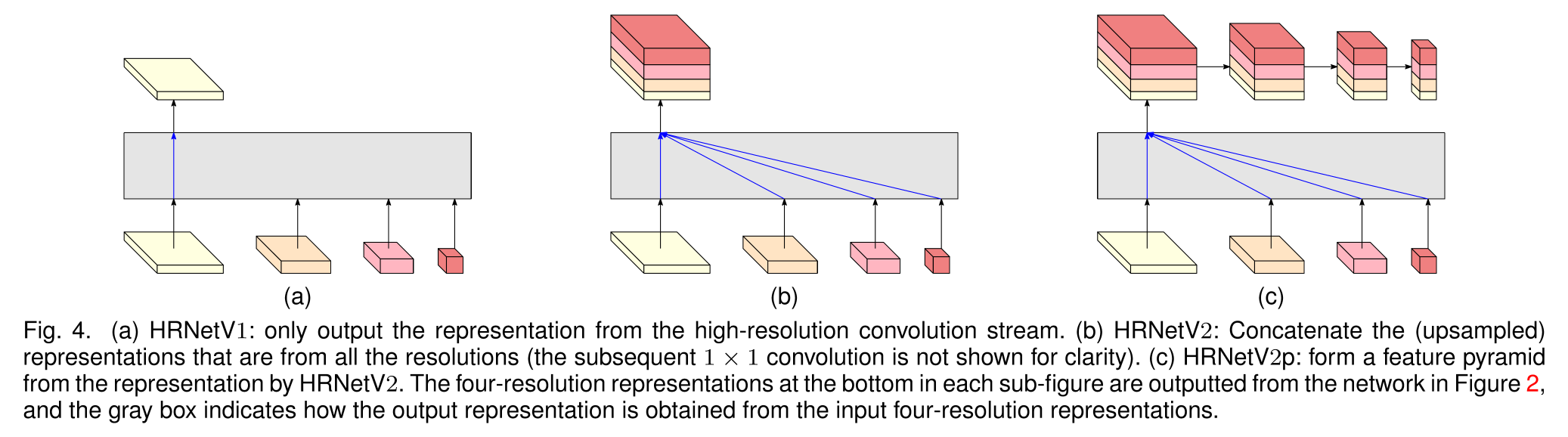
네트워크의 전체적인 레이아웃과 모델 버전별 output은 위와 같다.
HRNet은 high-resolution convolution stream으로부터 시작하고 스테이지를 하나씩 넘어가면서 low resolution branch가 하나씩 확장되는 구조라고 할 수 있다. 즉, 다음과 같이 표현할 수 있다.
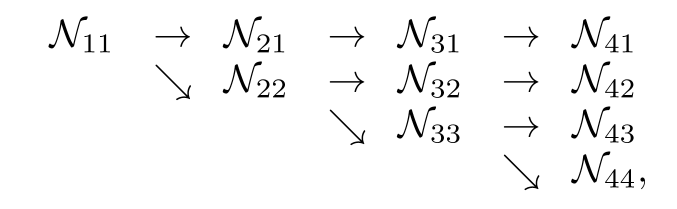
에서 와 은 각각 stage와 resolution의 index를 의미하며 번째 인덱스의 resolution은 로 나타낼 수 있다.
또한 각 Stage가 끝나는 부분에서 이러한 multi-resolution representation들을 fuse하며 정보 교환이 이루어진다. 3개의 branch로 이루어진 resolution representation들을 fuse한다고 가정해보자.
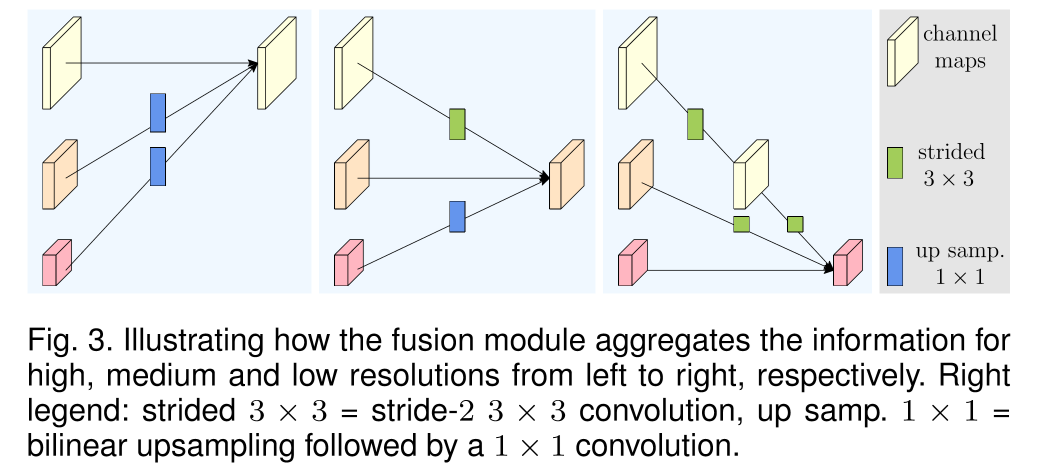
의 input을 가정하면 이에 대응되는 output은 로 표현할 수 있다.
여기서, 각각의 output representation은 3개의 input representation들을 변환한 후 sum한 것이라 볼 수 있다. 즉, 로 표현할 수 있다. 이 때, stage 3에서 4로의 fusion을 고려하면 와 같은 추가적인 output이 있다고 볼 수 있다.
transform function 의 경우 input resolution index 와 output resolution index 에 따라서 달라진다. 인 경우에는 인 identity mapping이고 인 경우, 즉, input으로 요구하는 resolution에 비해 이전 stage의 output resolution이 큰 경우는 개의 stride-2 3x3 convolution을 통하여 downsampling을 수행한다. 이와 반대의 경우는 bilinear upsampling과 1x1 convolution을 통하여 resolution과 channel을 조절한다.
리뷰를 마치며
앞서 리뷰했던 Polarized Self-Attention과 마찬가지로 HRNet AnimalDatathon에서 사용한 모델이다. 물론 Paperswithcode에 HRNet+PSA가 SOTA를 찍었기 때문이기도 했지만, 이미지에서 키포인트들이 굉장히 가깝게 붙어있는 케이스들이 보였기 때문이기도 했다. 이런 경우, 기존의 Encoder로 resolution을 뭉게고 Decoder에서 복원하는 모델을 사용하기보다는 input resolution을 그대로 보존하는 방식의 HRNet이 훨씬 나은 성능을 보일 것이라 판단하였다. 그리고 해당 대회에서 최종 리더보드 2위를 달성하게 됨으로써 이러한 판단이 어느정도 맞아떨어졌다고 생각한다.
