Regression task를 해결하기 위한 대부분의 DCNN 모델은 encoder-decoder 구조로 이루어져 있다. 이러한 구조는 대부분 endcoder 구조에서 순차적으로 spatial resolution을 줄이는 동시에 channel resolution을 늘려나가고, decoder에서 이를 원래대로 복원하는 방식으로 이루어진다. 그리고 대게 encoder와 decoder를 연결하는 tensor는 input image tensor와 output tensor 크기에 비해 작다. 이러한 방식으로 정보를 압축하는 것은 계산이나 메모리의 효율성 측면과 stochastic optimization을 수행하는 데 있어서 필수적이지만, 타겟의 pixel appearances나 patch shape는 nonlinear한 특성이 있기 때문에 축소된 크기의 feature로 encoding하는 것은 성능에 악영향을 끼칠 가능성이 높다.
Model design의 관점에서, pixel-wise regression 문제의 당면 과제는 다음과 같다.
- 합리적인 계산 비용 하에서 높은 internal resolution을 유지하는 것.
- keypoint heatmap이나, segmentation mask 같은 output distribution을 fitting 시키는 것.
본 논문에서는 현존하는 네트워크들을 개선할 수 있도록 plug-and-play solution, 즉, attention 블록을 삽입하는 방식에 주목하였다.
CBAM, SE block과 같은 기존의 attention module들은 pixel wise regression task를 상정한 모듈이 아니기 때문에 데이터의 non linearity가 제대로 반영되지 않는 문제점이 있다.
또한, 앞서 말한 바와 같이 이미지가 backbone network를 통과하며 low resolution feature로 변환된다는 점 역시 pixel wise regression task에서 문제가 된다. backbone에 self-attention block을 삽입함으로써 attention 연산 과정에서 high-resolution semantics를 보존하는 것이 필요하지만 현존하는 attention block들은 오히려 lower internal resolution에서 잘 동작하고 있다. 따라서, pixel wise regression task에서의 성능을 높이기 위해서는 attention 연산 과정에서 higher resolution information을 활용하여 non-linearity를 보다 더 정밀하게 계산하는 방법을 찾아야 한다.
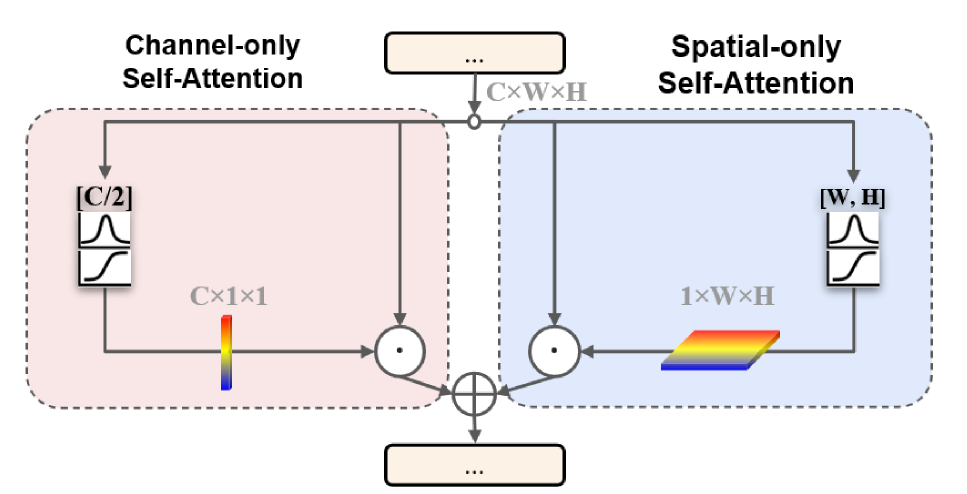
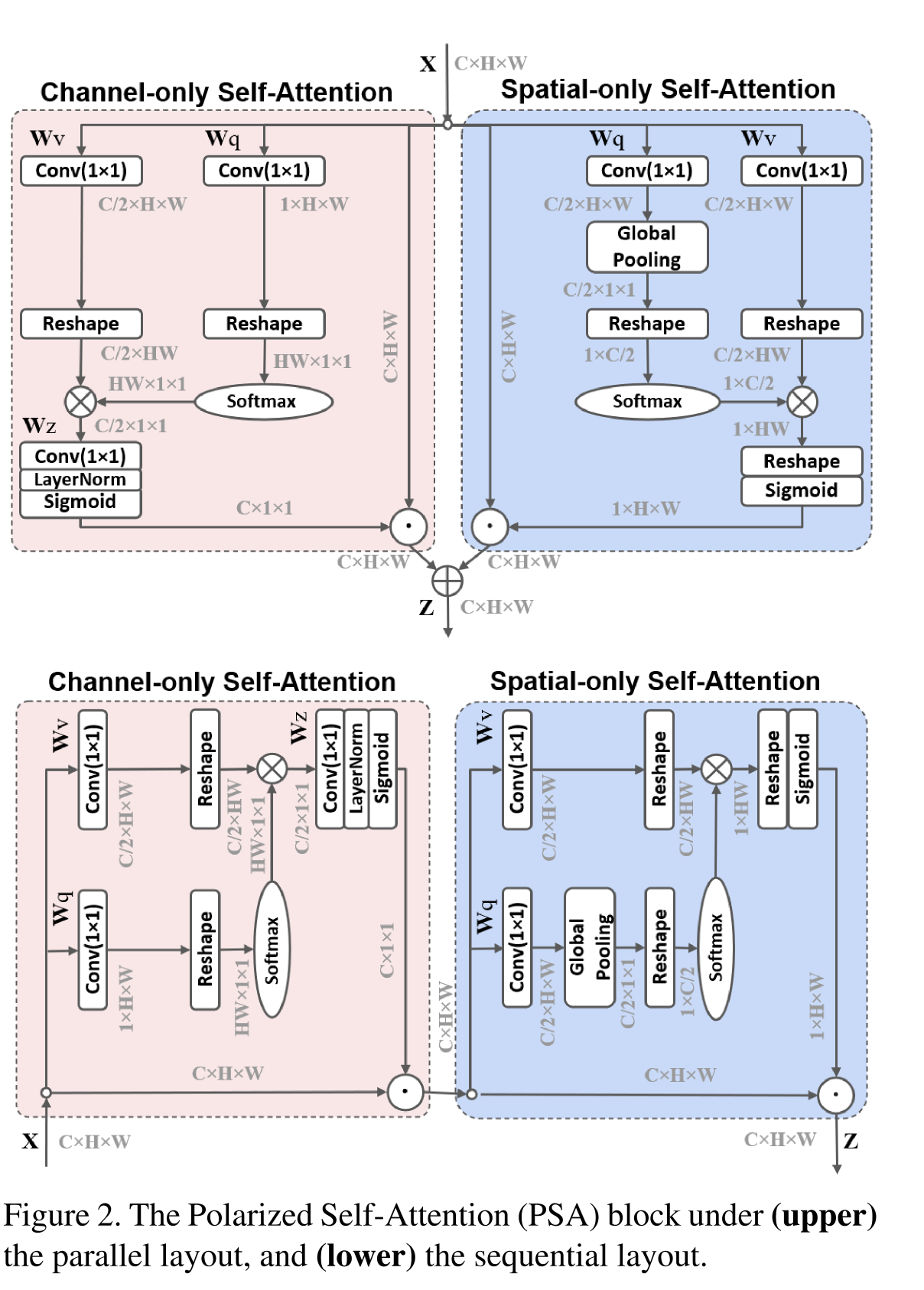
이러한 문제점을 해결하기 위하여 PSA에서는 attention 연산에 polarized filtering이라는 기법을 응용하여 적용한다. polarized filtering은 사진학에서 모티브를 얻어 고안한 메커니즘으로 한 방향의 feature(channel or spatial)은 collapse하고 이와 orthogonal한 방향의 feature(즉, collapse 한 feature가 channel 방향의 feature라면 나머지 spatial 방향의 feature가 해당)은 보존하는 기법이다.
Polarized Self-Attention에는 이 외에도 HDR 기법 또한 포함된다. HDR은 bottleneck tensor(attention block에서 가장 작은 크기의 feature tensor)에 softmax normalization을 적용함으로써 attention의 dynamic range를 늘리고 바로 뒤에 sigmoid function을 통하여 tone-mapping을 적용하는 기법을 의미한다.
즉 정리하자면 PSA에서 활용하는 기법은 다음과 같다.
-
Polarized Filtering : Attention 연산에서 Channel과 Spatial feature 중 하나만 collapse한다.
-
HDR : Softmax로 normalize한 후 sigmoid function을 통하여 tone mapping을 적용

위의 시각화한 이미지를 보면 가려지거나 겹쳐 있는 keypoint들 역시 잘 맞추는 걸 볼 수 있다. hybrid한 방식이기는 하지만 그래도 전체적인 맥락을 파악하는 self-attention 메커니즘이니 당연한 결과라고 할 수 있다.
최근 소 이미지의 keypoint를 예측하는 AnimalDatathon이라는 대회에 참가하며 HRNet에 본 모듈을 추가하여 사용해 보았는데 occlusion이 심한 이미지에서도 타겟 키포인트를 잘 맞추는 것을 확인할 수 있었다.
