파이썬 TIPs
소수점 적용
- round(data, n)
round(3.14159, 2)- format 함수 (f'{ }'.format( ))
print("{:.2f}".format(3.14159))- format 함수 (format(data, '.nf'))
format(.314159, ".2f"))- % 서식 문자 ('%nf'%data)
print("%0.2f"%3.14159)- f-string (f'{data:.nf}')
print(f"{3.14159:.2f}")리스트, 배열 전체 소수점 적용
- 리스트
np.round(list_data, n)- 배열
array.round(n)matplotlib subplot axes legend
- 각 ax는 따로따로 legend 생성해줘야 함
for ax in axes:
ax.legend()pandas get_dummies
- one hot encoding (pandas)
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("국민건강보험공단_건강검진정보_20211229.xls", encoding='cp949')
plt.rc('font', family='Malgun Gothic') #한글 폰트 지정
df_dummies = pd.get_dummies(df[['성별코드', '시도코드']], drop_first=True)
print(df_dummies.head(1))
print('=============================')
df = pd.get_dummies(df, columns=['시도코드', '성별코드'])
print(df.head(1))
#
#결과
성별코드 시도코드
0 1 36
=============================
기준년도 가입자 일련번호 연령대 코드(5세단위) 신장(5Cm단위) ... 시도코드_48 시도코드_49 성별코드_1 성별코드_2
0 2020 1 9 165 ... 0 0 1 0Deep learning model 만들기 예시
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
X_train.shape
model = Sequential()
model.add(Dense(128, activation = 'relu', input_shape=(X_train.shape[1],)))
model.add(Dropout(0.5))
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(32, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
mc = ModelCheckpoint(filepath='best.h5', verbose=1, monitor='val_loss', mode='auto', save_best_only=True)
es = EarlyStopping(monitor='val_loss', mode='auto', verbose=1, patience=5)
history= model.fit(X_train,y_train, epochs=50,
validation_data=(X_test,y_test),
# validation_split=0.1,
verbose=1,
callbacks=[es,mc]
)
plt.figure(figsize=(10,5))
plt.plot(history.history['acc'], 'red', label="acc")
plt.plot(history.history['val_acc'], 'blue', label='val_acc')
plt.title("title")
plt.xlabel('학습회수')
plt.ylabel('정확도')
plt.rc('font', family='Malgun Gothic') #한글 폰트 지정
plt.show()한글 폰트 적용 (plt)
plt.rc('font', family='Malgun Gothic') 간단한 플롯 그리기 (확인용?)
import seaborn as sns
import matplotlib.pyplot as plt
iris = sns.load_dataset('iris')
iris['species'].value_counts().plot(kind='bar')
plt.show()딥러닝 모델 개요보기(summary)
model.summary()
원하는 위치에 column 추가하기 (pandas)
df.insert(loc, column, value, allow_duplicates=False)
# ex
df.insert(1, 'month', df['Datetime'].dt.month)
df.head()
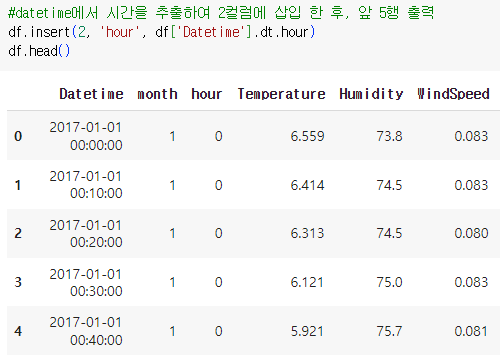
df.insert(2, 'hour', df['Datetime'].dt.hour)
df.head()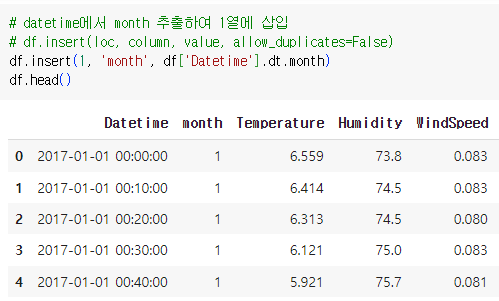
DataFrame데이터프레임에서 문자열 찾기
# 문자열을 포함하는 열 찾기
df[df['Country name'].str.contains('K')]
# 문자열로 시작하는 열 찾기
df[df['Country name'].str.startswith('S')]Random color 랜덤 색상 지정
import random
#hexadecimal 형식으로 랜덤 색 선택
def rand_color(num=1):
col = list()
for _ in range(num):
col.append("#" + "".join([random.choice('0123456789ABCDEF') for _ in range(6)]))
return col필요한 수만큼 리스트로 반환
📕 kde 그래프에 색상을 랜덤으로 주기
import random #hexadecimal 형식으로 랜덤 색 선택 def rand_color(num=1): col = list() for _ in range(num): col.append("#" + "".join([random.choice('0123456789ABCDEF') for _ in range(6)])) return col fig, ax = plt.subplots(figsize=(15,8)) ax = sns.kdeplot(data=df, x='Ladder score', hue='Regional indicator', alpha=0.3, fill=True, palette=rand_color(len(df['Regional indicator'].unique())), # 항목 수만큼의 색을 지정해야 함 lw=2, edgecolor='w', shade=True) plt.title('Ladder Score by region') plt.axvline(df['Ladder score'].mean(), c='black', ls='--', lw=.5) plt.show()

pyplot(plt), Seaborn Subplot ax 지정
# pyplot(plt)
ax[idx].scatter(data=df_t, x=cols[idx], y='CO2 Emissions(g/km)')
#seaborn
sns.scatterplot(data=df_t, x=cols[idx], y='CO2 Emissions(g/km)', ax=ax[idx])sns.barplot은 평균값을 표현함
#barplot
plt.figure(figsize=(25,7))
sns.barplot(data=df, x="Make",y='CO2 Emissions(g/km)',ci=None)
plt.xticks(rotation= 35)
plt.show()데이터 스케일링
- 수치형 데이터의 정규화/표준화를 의미
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X=scaler.fit_transform(X)
plt.hist(X)pandas dataframe 컬럼 split
- pandas.DataFrame.str.split('구분자', expand=True or False)
df[["High_pressure", "Low_pressure"]] = df['Blood Pressure'].str.split('/', 1, expand=True)- DataFrame[column].apply(lambda x: pd.Series(str(x).split(",")))
df["High_pressure"] = df['Blood Pressure'].apply(lambda x : x.split('/')[0])
df["Low_pressure"] = df['Blood Pressure'].apply(lambda x : x.split('/')[1])histogram Hue 옵션
- seaborn.histplot, hue 및 multiple
fig, ax = plt.subplots()
ax = sns.histplot(data=df, x='Sleep Disorder', hue='Gender', multiple="dodge", shrink=.8)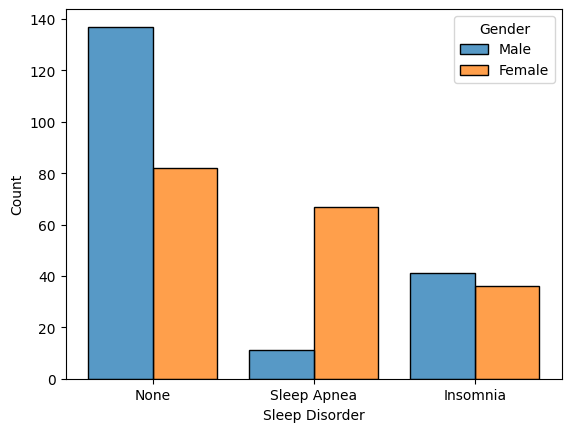
- plotly.histogram, color 및 barmode
fig = px.histogram(x=df['Sleep Disorder'], color=df['Gender'], barmode='group')
#barmode: relative, gruopm overlay 옵션이 있음
fig.show()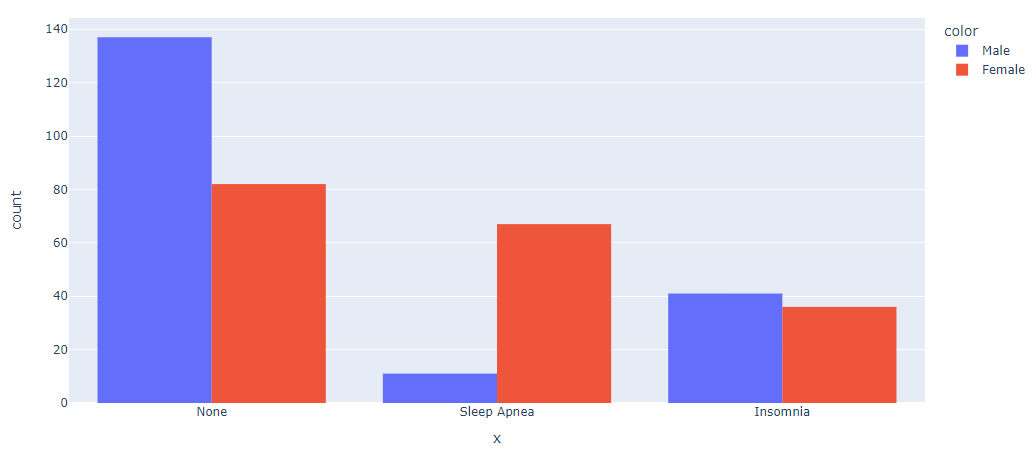
pandas 컬럼명 변경
- 전체 열 이름 입력하기
df.columns = ['col', 'col', 'col']- 선택하여 열 이름 변경하기
df.rename(columns={'Before':'After'})pandas 컬럼을 인덱스로
- set_index
DataFrame.set_index(keys=column, inplace=True)add_subplot 예시
fig = plt.figure(figsize=(15,6))
for idx, col in enumerate(['Age','Income','Spending']):
ax = fig.add_subplot(1, 3, idx+1)
sns.distplot(mall[col], ax = ax)
ax.set_title(col)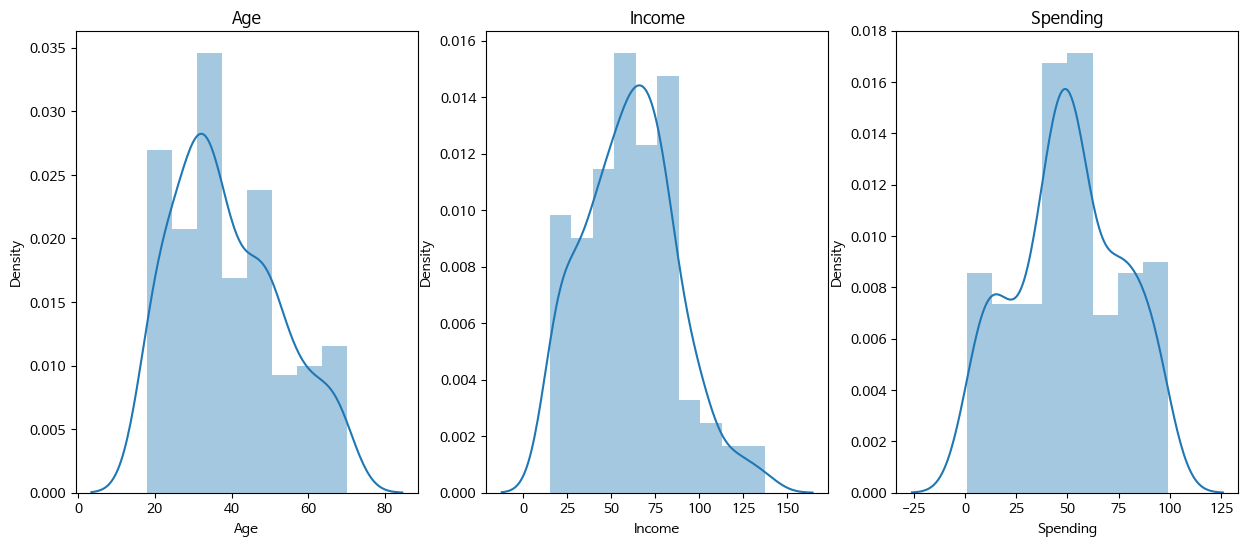
한 컬럼의 value_counts 값으로 barplot 그리기
mall['Age_Range'].value_counts()
#
# 결과
25-34 54
35-44 42
45-54 39
18-24 35
55+ 30
Name: Age_Range, dtype: int64plt.figure(figsize = (15,6))
sns.barplot(mall, x=mall['Age_Range'].value_counts().index, y=mall['Age_Range'].value_counts().values)
plt.title("나이별 고객수")
plt.xlabel("나이")
plt.ylabel("고객수")
plt.show()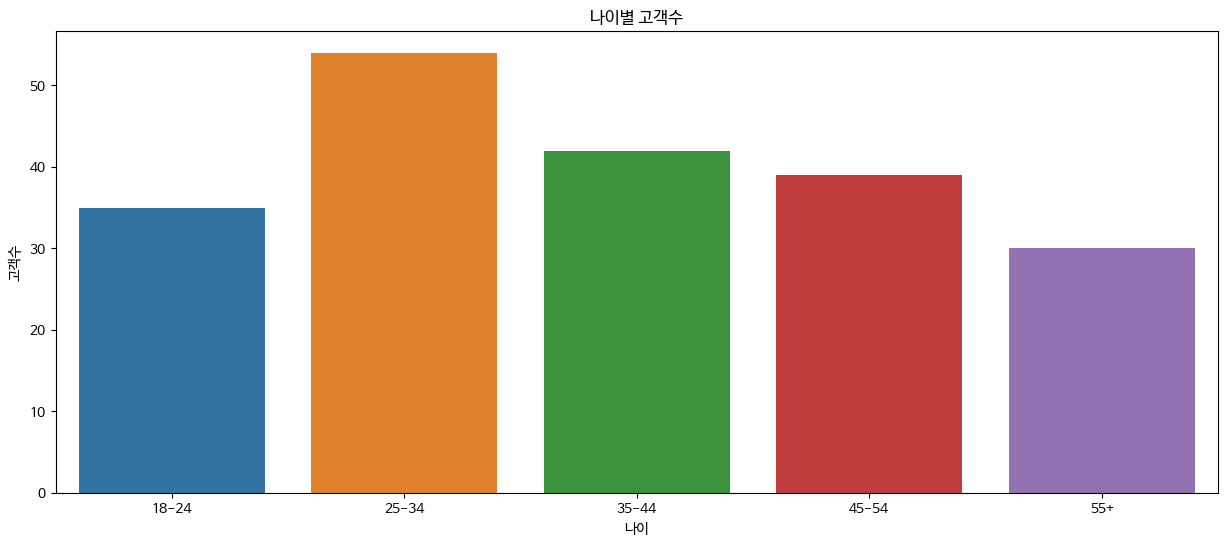
value_counts한 값의 index와 values를 가져옴!!
연산 시간 체크하기 timeit
- timeit: 코드 일부분의 실행 시간을 측정할 때 사용하는 모듈 https://docs.python.org/ko/3/library/timeit.html
import timeit
# concant
def test1():
l = []
for i in range(1000):
l = l + [i]
# append
def test2():
l = []
for i in range(1000):
l.append(i)
# list conrehension
def test3():
l = [i for i in range(1000)]
# list, range
def test4():
l = list(range(1000))
# extend
def test5():
l = []
l.extend(range(1000))
print("concat: ", timeit.timeit("test1()","from __main__ import test1" , number= 1000),"ms")
print("append: ", timeit.timeit("test2()","from __main__ import test2" , number= 1000),"ms")
print("l_c: ", timeit.timeit("test3()","from __main__ import test3" , number= 1000),"ms")
print("list_range: ", timeit.timeit("test4()","from __main__ import test4" , number= 1000),"ms")
print("extend: ", timeit.timeit("test5()","from __main__ import test5" , number= 1000),"ms")
#
# 결과
concat: 1.7168940530009422 ms
append: 0.0696691520006425 ms
l_c: 0.036703269001009176 ms
list_range: 0.015264612000464695 ms
extend: 0.015725848999863956 ms_method 랑 __method 차이?
__method는 직접 호출 불가
ex) student1.grade() : 가능
student1.__grade() : 불가능
- 다시 알아보기..
클래스 타입 확인 isinstance
- isinstance() ; 기반 클래스 정보를 체크
#지정한 객체가 지정한 클래스타입인지 체크
print(f'{isinstance(Kim, Student) = }')
#
# 결과
isinstance(Kim, Student) = True- 사용 예
class Student:
def study(self):
print('studing')
class Teacher:
def teach(self):
print('teaching')
classroom = [Student(), Student(), Teacher(), Student() ]
for person in classroom:
if isinstance(person, Student):
person.study()
elif isinstance(person, Teacher):
person.teach()
#
# 결과
studing
studing
teaching
studingif name=='main': 의 의미
- 프로그램이 이 파일에서 시작했을 경우 라는 뜻
파이썬에서 'is'와 '=='의 차이
- is
- 앞 뒤 변수가 같은 '객체 Object'를 가리킬때 True
- 값이 같아도 다른 객체이면 False
- ==
- 앞 뒤 변수가 같은 '값 Value'을 가질때 True
f string의 활용 예
https://note.nkmk.me/en/python-f-strings/
성능테스트 모듈 dis
import dis
dis.dis(테스트 하려는 작업)클래스 중첩
class ArtificialNeuron:
def __init__(self, X, w, b):
self.X = X
self.af = self.AffineFunction(w, b)
self.sg = self.Sigmoid()
def cal_y(self):
self.z = self.af.forward(self.X)
self.y = self.sg.forword(self.z)
return self.y
class AffineFunction:
def __init__(self, w, b):
self.w = w
self.b = b
def forward(self, x):
z = np.matmul(self.w, x) + self.b
return z
class Sigmoid:
def forword(self, z):
return 1 / (1 + np.exp(-z))위 코드는 수정해야 할 코드인데 클래스 중첩을 적용해봐서 기록으로 남겨둠

:D