신경망 기계 번역
이전편에서 예고한 대로 Watson의 번역 성능에 대해 어떤 방식으로 구동되어지는 지를 알아보고자 Watson Language Translation을 소개하는 페이지를 방문하였고 아래와 같은 정보가 있었다.

여기서 Neural Machine Translation(신경망 기계 번역)을 딥러닝을 사용하여 속도와 정확성을 높였다라고 소개하고 있다. 그래서 이 NMT에 대해 알아보게 되었다.
신경망 vs 통계
신경망과 통계라는 비교는 생각보다 쉽게 상상이되지 않는다. 하지만, 신경망이 모사하고자 하는 인간의 뇌를 생각하면 상상하기 쉬워진다. 인간의 뇌와 통계의 가장 큰 차이점은 이해력이라고 생각한다.
통계적 번역(Stastical Machine Translation)는 주어진 문장을 단어나 구로 분할하고 확률적 결과에 따라 대체하는 식으로 이루어진다.
한글: 나는 내일 학교에 간다
영어: I go to school tomorrow.
위와 같은 경우는 무리 없이 번역이 된다. 하지만 아래와 같은 경우에는 문제가 발생한다.
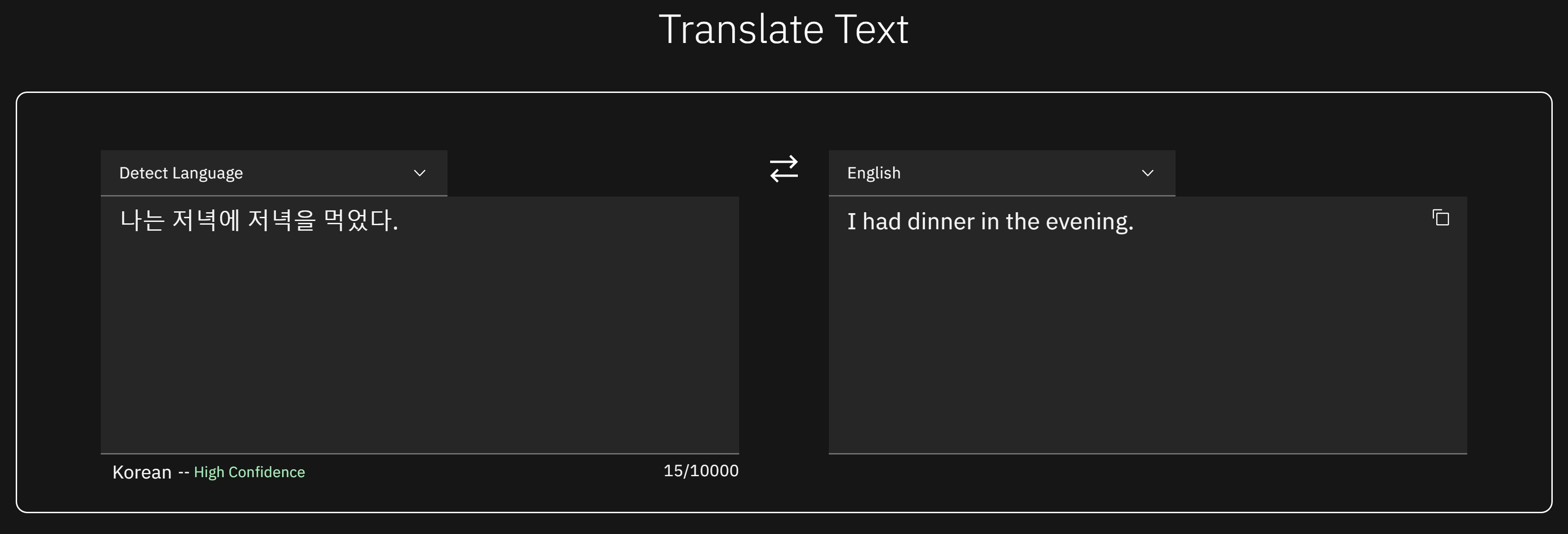
한글: 나는 저녁에 저녁을 먹었다.
영어: I had a night at night.
우리가 말하는 '저녁'은 두가지 의미가 있다. 시간적 개념으로 사용되는 '저녁'과 저녁시간에 먹는 '식사'가 있다. 하지만, 일 '저녁'이란 단어가 내포하는 의미는 일반적으로 시간적 개념으로 사용된다. 그래서 결과는 우리가 의도한 문장의 의미와는 다르게 번역되어질 수 있다.
하지만, 신경망을 모사한 NMT의 경우는 위와 다른 결과를 보여준다.
한글: 나는 저녁에 저녁을 먹었다.
영어: I had dinner in the evening.
이 결과가 보여주는 것은 문장 속에 동일하게 사용된 '저녁'이란 단어를 다르게 해석하였다는 것이고 이는 문장의 의미를 이해했다는 것과 동일하다.이는 Watson Language Translator를 통해 확인할 수 있다.
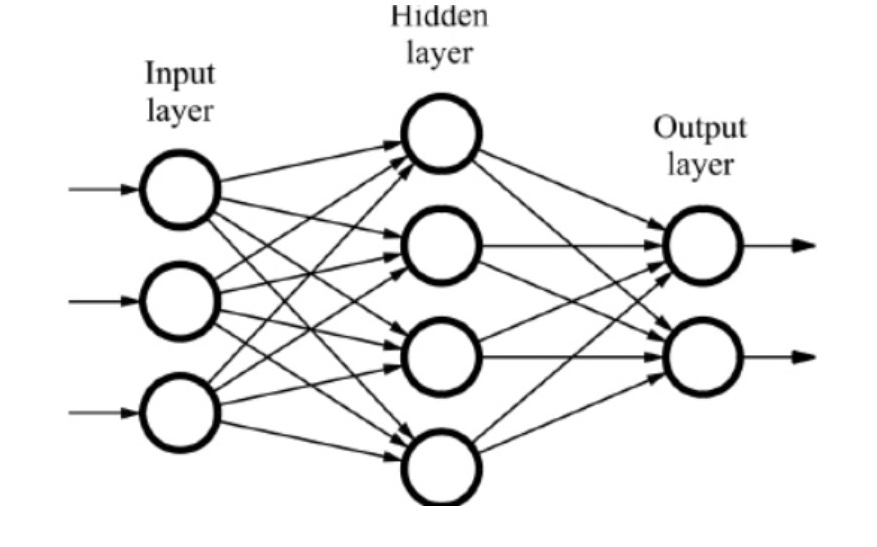
Neural Net & 번역기
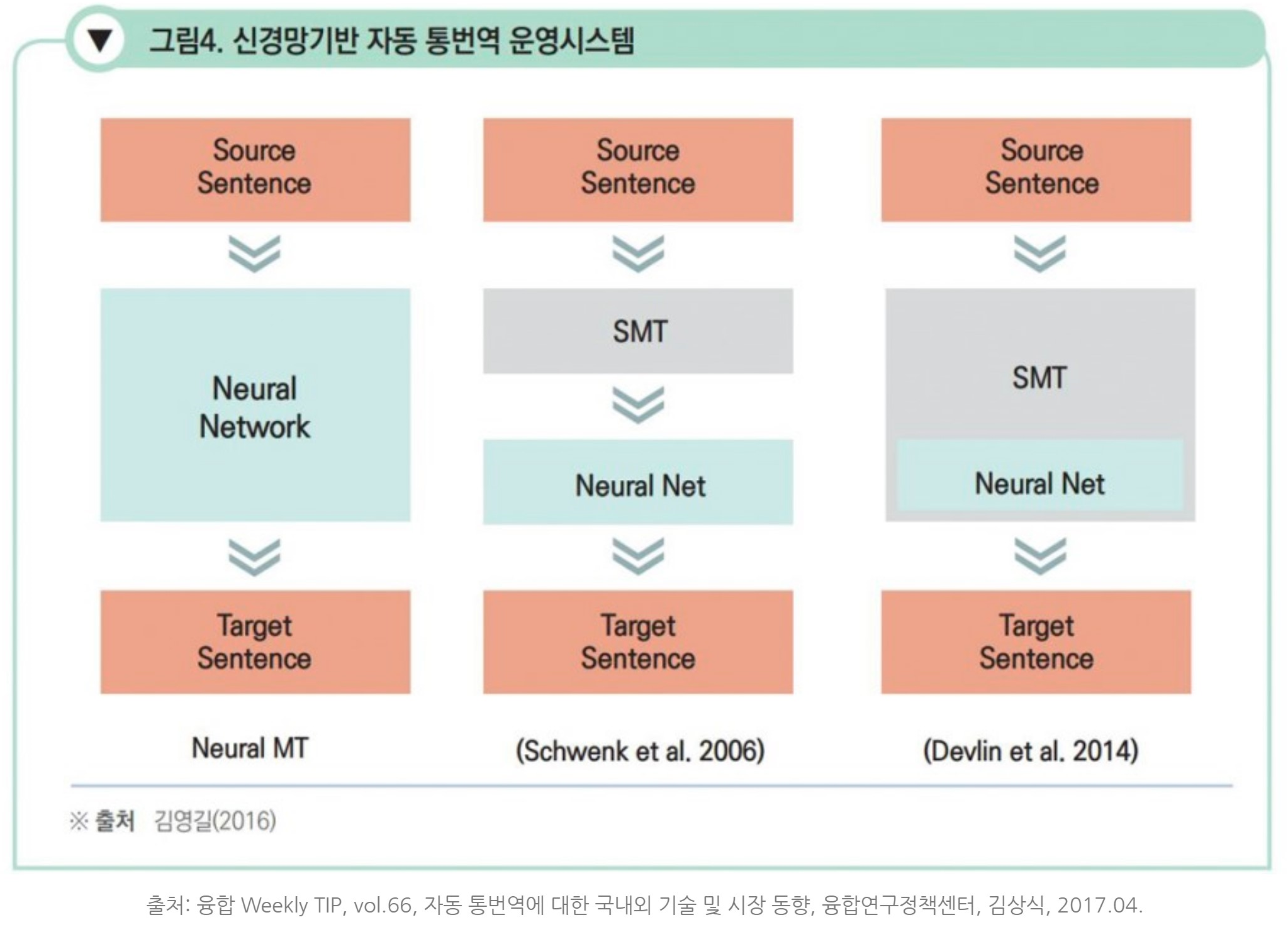
신경망 기계 번역을 사용한 번역기들은 위와 같은 구조로 Neural Net, SMT + NN, SMT(NN) 으로 이루어져 있다.
그리고 우리가 사용해본 IBM Watson과 비교군이었던 Naver Papago, Google Translate 모두 Neural Net 기반 번역기이다. 여기서 말하는 Neural Net이 바로 신경망 기계 번역을 수행하는 딥러닝 모델이다.
정리
Watson Language Translator가 신경망 기계 번역을 통해 번역을 한다는 것을 알 수 있었다. 그리고 신경망 기계 번역은 문장의 번역할때 통계적 기계 번역과 같이 문장을 단어나 구로 분할한 뒤 확률적 계산에 의한 결과 도출이 아닌 문장을 그대로 번역하는 모습을 보여주면 이는 마치 인간의 뇌가 문장을 '이해'한 것과 유사한 형태를 보여준다는 것을 알게 되었다.
다음편
다음편에서는 이 신경망 기계 번역이 이루어지는 Neural Net에 대해 알아볼 것이다.