
Chain-of-Thought Reasoning without Prompting
논문원본: https://arxiv.org/pdf/2402.10200
Introduction
Background
- LLM Reasoning 능력을 높이기 위한 기존 방법
i) few-shot prompt
ii) zero-shot with cot prompt
iii) instruction tuning - prompting 방법의 단점 (i, ii)
- task-specific 프롬프트 엔지니어링을 해야하는 문제
- 사람의 지식이 포함됨 -> LLM의 고유한 평가가 어려움
- fine-tuning 방법의 단점 (iii)
- 많은 양의 supervised data가 필요
Problem Definition
- Can LLMs reason effectively without prompting?
- 해당 논문은 위 질문에 답변하기 위한 1. 실험 + 2. 적용 방법 을 제시
Method
1. Can Reasoning without prompting
- 추가 prompt 없이 "Q: {question}\nA:" 형태 사용
- 1번째 decoding step에서 top-k개의 토큰을 뽑고 각각에 대해 greedy decoding 수행
- Figure1은 위 실험의 예시
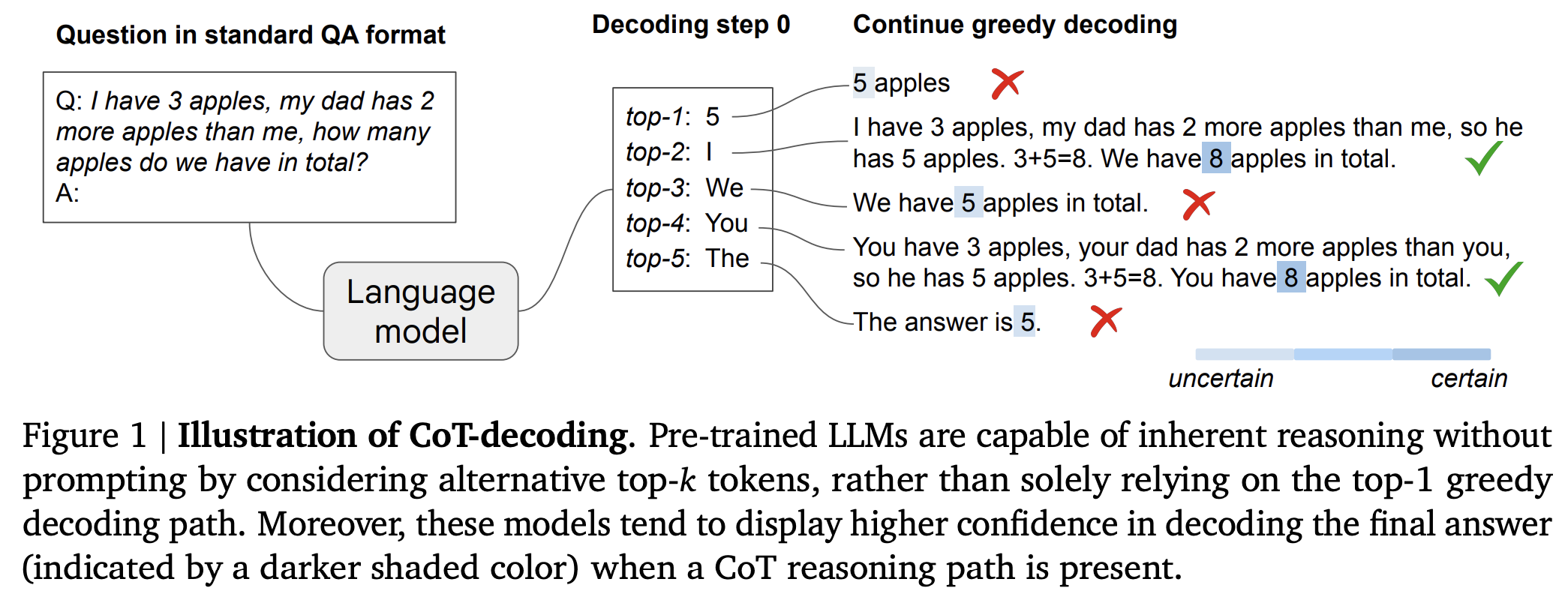
실험 해석
- Greedy decoding path만 고려하면 LLM의 reasoning 결과를 얻을 수 없다.
- figure1에서 top1 token에 대한 path(5 apples)를 보면 reasoning을 안함 -> 답도 틀림
- LLM에 사용된 학습데이터의 분포가 간단한 문제에 편향됨
=> LLM은 reasoning 없이 바로 해결할려는 경향이 부각됨
- 다른 decoding path를 고려하면 LLM의 reasoning 결과를 얻을 수 있다.
- figure1에서 top2 token이나 top4 token에 대한 path를 보면 reasoning을 함
- pre-training 단계에서 LLM은 reasoning 능력을 갖고 있음
2. CoT-Decoding
-
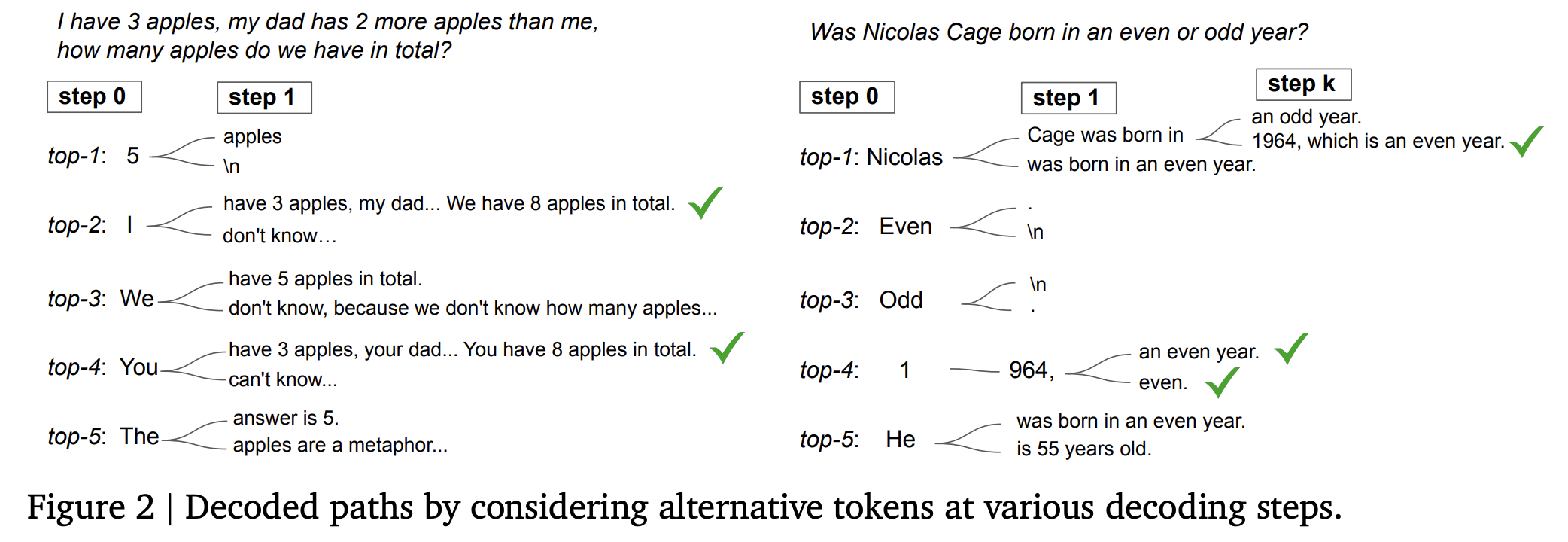
위 실험을 통해 top 1이 아닌 다른 path에 reasoning path가 있다는 것을 알게 됨
-
어떻게 reasoning path를 찾을 수 있을지에 대한 방법 제시
-
과정
- 첫번째 decoding step에서 logit 값이 가장 큰 top k개 token 선택
- top k개 token 각각에 대해 greedy decoding 수행
- 각 decoding path에 대해 confidence 계산
- 각 decoding step에서 softmax를 거친 top1, top2의 확률의 차이를 계산하고 decoding path에서 평균을 계산 = confidence
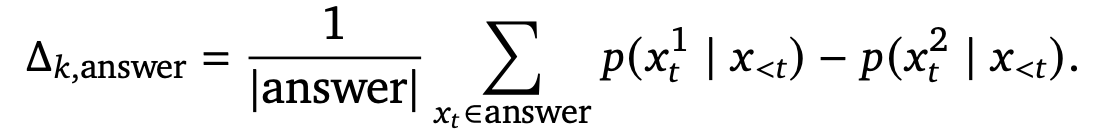
- 각 decoding step에서 softmax를 거친 top1, top2의 확률의 차이를 계산하고 decoding path에서 평균을 계산 = confidence
- confidence가 가장 큰 decoding step을 선택
-
GSM8k 100개에 대해 CoT-Decoding을 적용했을 때 88%가 cot path로 나옴
=> confidence와 cot-path는 high correlation

-
self-consistency vs CoT-Decoding
=> CoT-Decoding이 더 다양성이 높음
-
1번째 decoding step에서 top-k개의 token을 뽑는게 다양성을 가장 높일 수 있음 -> 단, 예외 task가 있긴 함
-
더 정확한 Aggregation 방법
- 여러 decoding path의 답변들 중 confidence 합이 가장 큰 답변을 선택하는 방법론 -> 최종적으로 이 방법을 사용
- self-consistency 방법론과 유사
Experiments
- setup
- standard QA format -> "Q: {question}\nA:"
- cot-decoding 뿐만 아니라 비교에 사용하는 다른 decoding 방법에 대해 k=10을 적용
- Datasets
- GSM8K: mathmatical reasoning
- MultiArith: multi-step arithmetic dataset
- 유명인사의 출생연도 짝홀수 문제: commonsense reasoning
=> sota model인 GPT-4도 50% 이하의 정확도 보임
- Models
- PaLM-2 (X-Small, Small, Medium, Large)
- Mistral-7B
- Gemma-7B
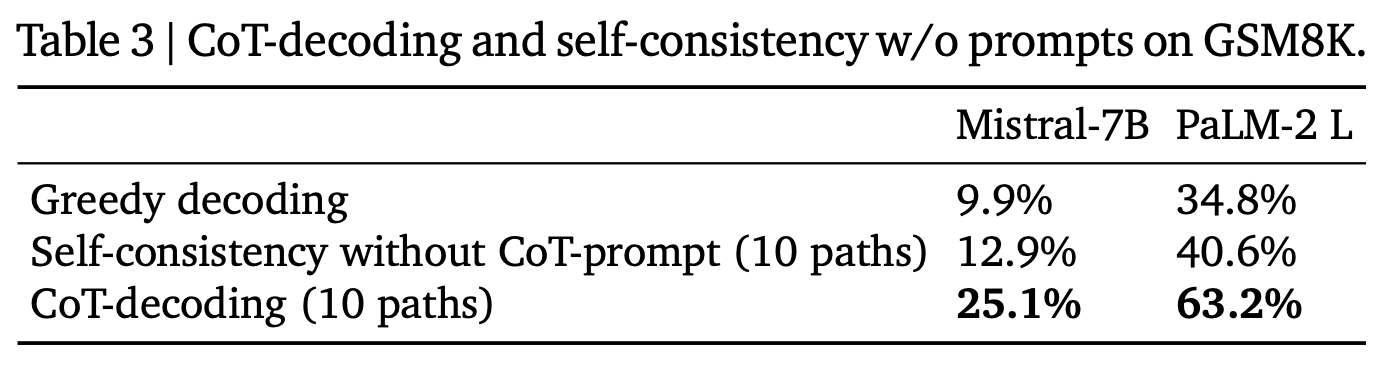
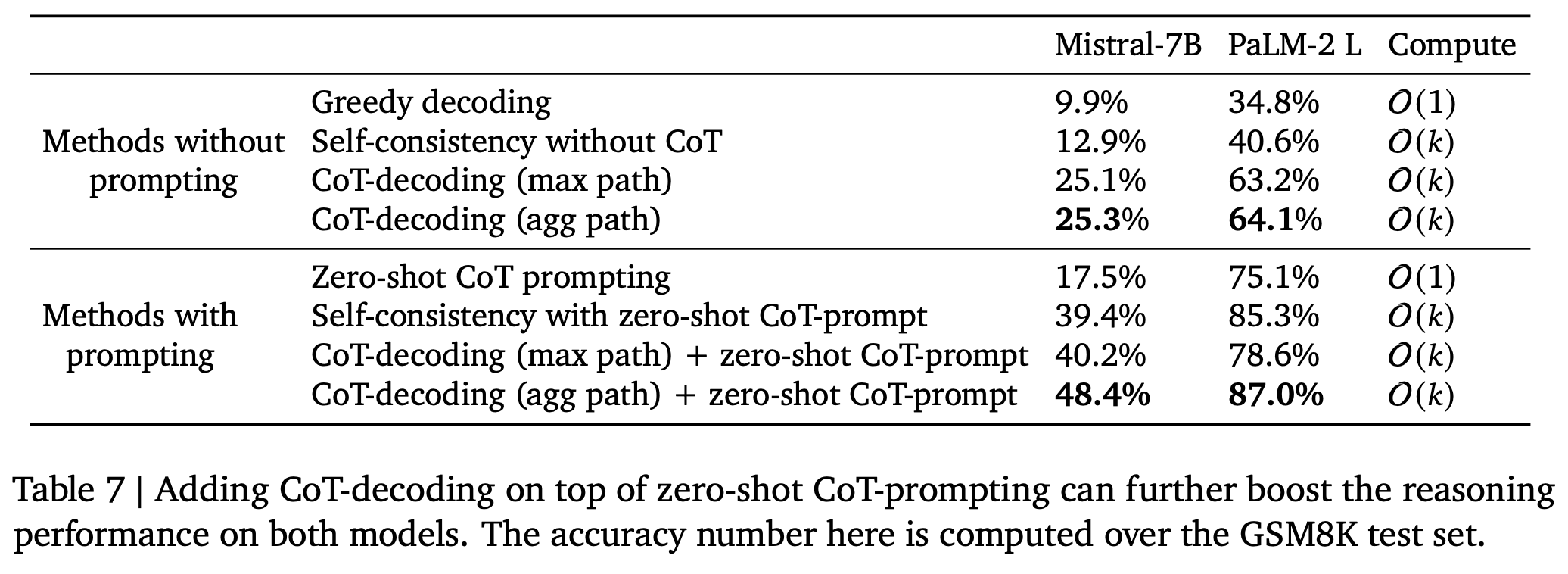
CoT-Decoding 방식이 다른 Decoding 방식에 비해 reasoning을 답변을 잘 갖고옴
- Mistral-7B로 실험했을 때 다른 Decoding 방법은 GSM8K 정확도가 Greedy decoding에 비해 떨어졌지만 CoT-decoding 방식은 정확도를 매우 크게 향상시킴

다른 LLM에 대해서도 모두 성능 향상
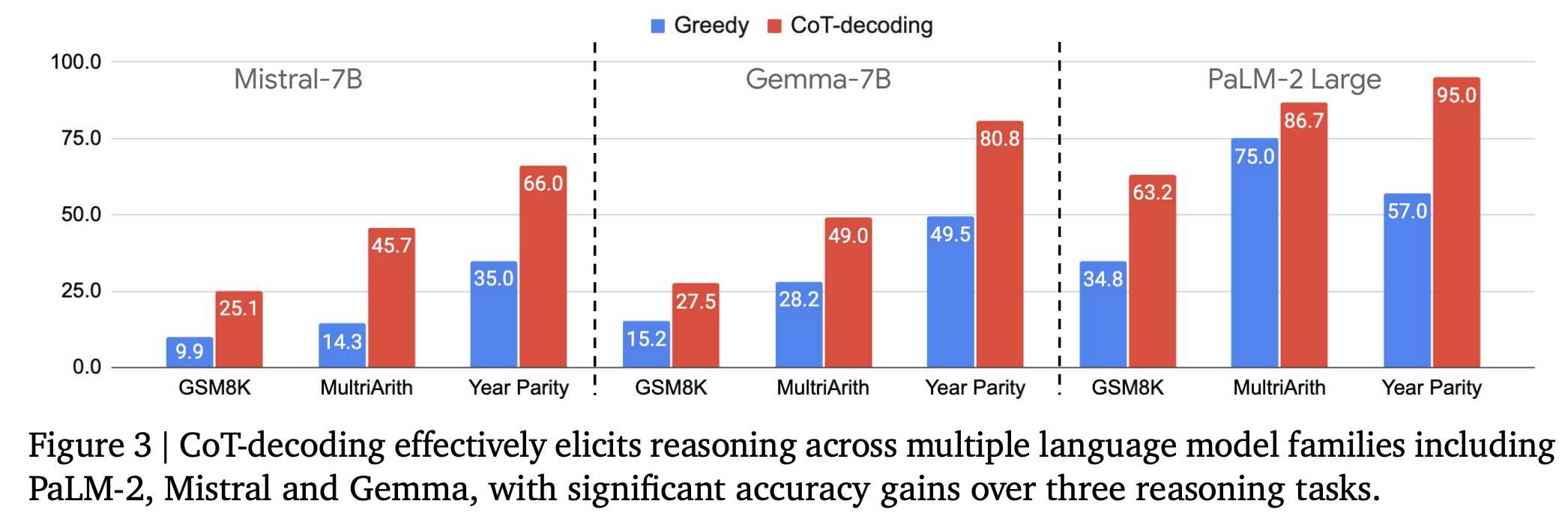
LLM scale에 대해서도 모두 성능 향상
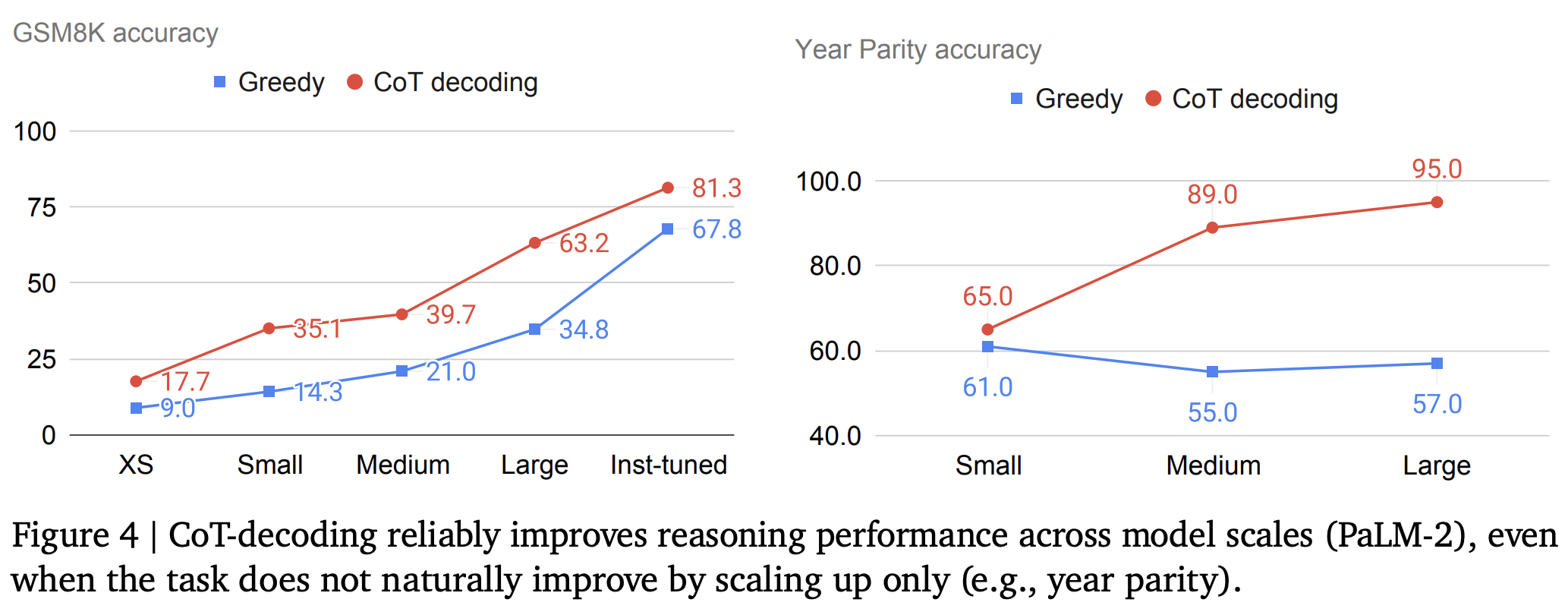
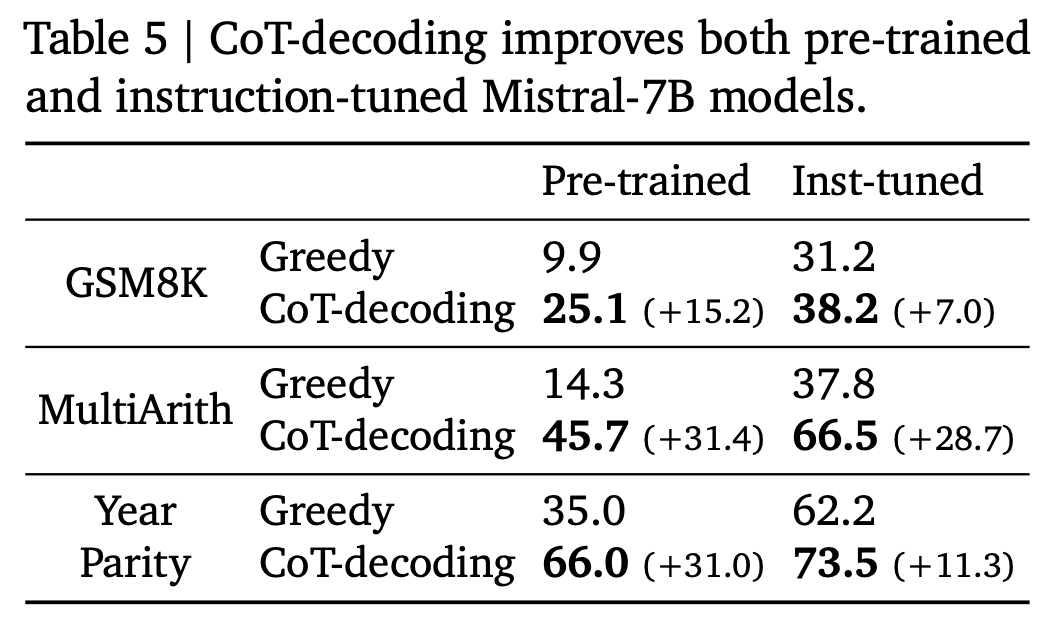
Instruction-tuned
- Instruction-tuned를 수행하면 reasoning을 할려는 경향이 커짐
=> reasoning path가 더 상위에 랭크됨 - Instruction-tuned 모델에도 CoT-Decoding 수행하면 성능 향상
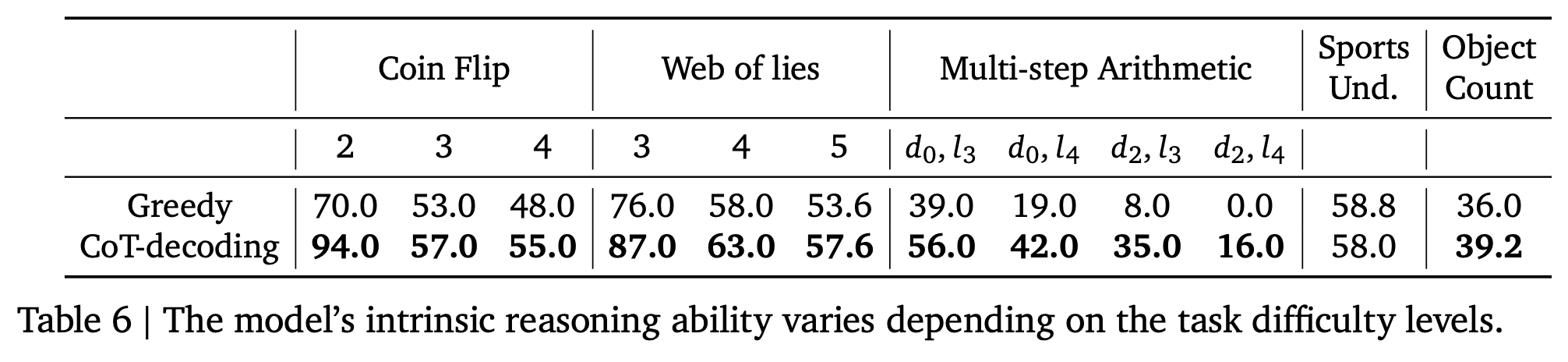
올바른 CoT path와 문제 난이도는 비례
CoT-prompting에도 CoT-Decoding를 적용하면 성능 향상
Limitation & Impact
Limitation
- paper: top-k개에 대해 greedy decoding을 수행해야 하기 때문에 computational cost 증가 -> 논문에서는 fine-tuning 데이터셋으로 활용하면 좋을 것 같다고 함
- paper: open-ended 유형에서는 confidence를 통한 선택이 좋지 못함
Impact
- CoT-Decoding을 적용하기 쉬움
- 어떤 조건에서든 성능 향상이 된다는 점에서 좋은듯
- future work: vllm에 적용해보고 최신 모델 (qwen2.5, gemma2)를 사용해 실험해볼 예정
Appendix
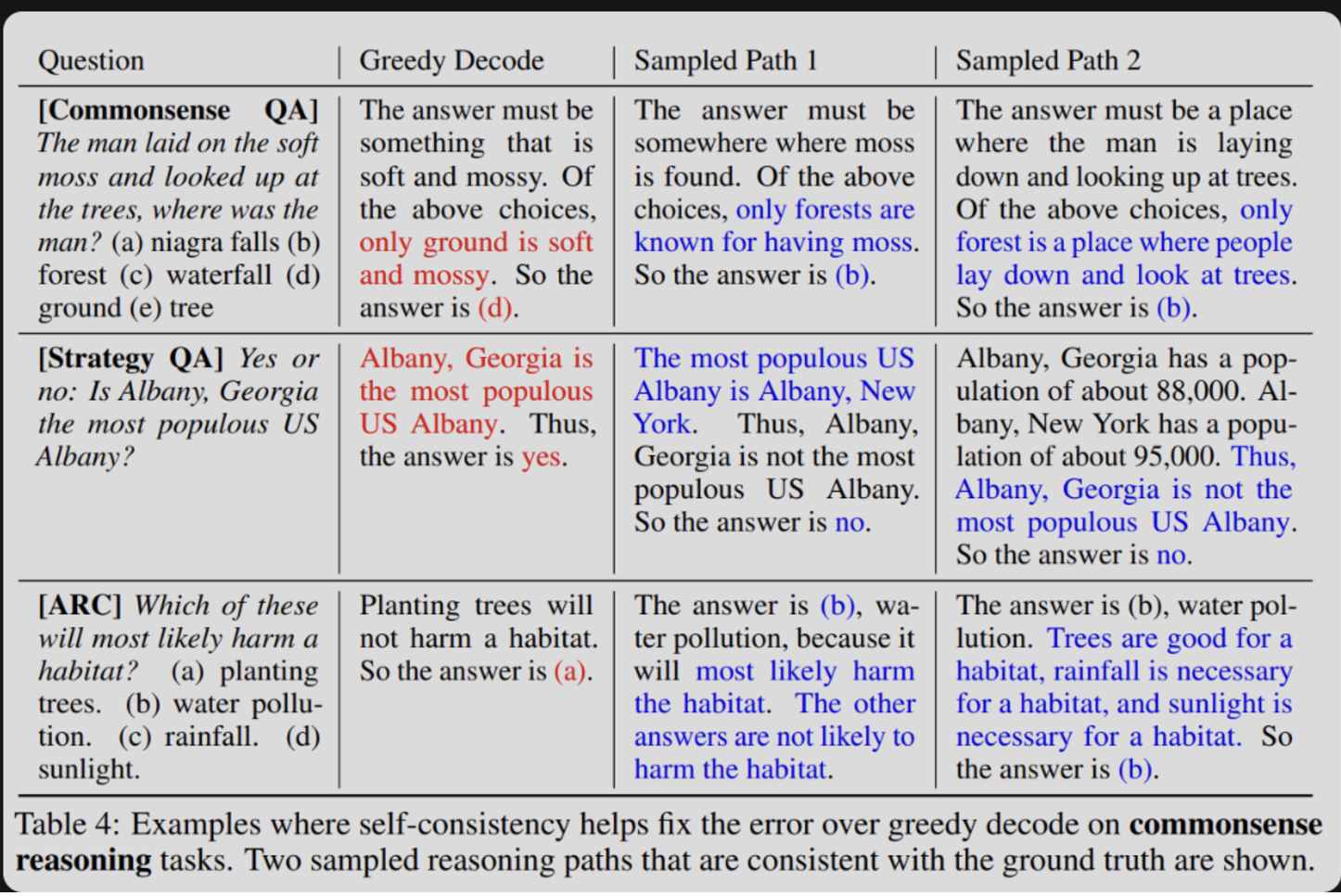
self-consistency
- 동일한 프롬프트에 대해 독립적으로 여러번 답변을 생성한 뒤에 일관성 있는 답변을 선택

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.