
Sky-T1: Train your own O1 preview model within $450
Post: https://novasky-ai.github.io/posts/sky-t1/
Github: https://github.com/NovaSky-AI/SkyThought
Introduction
Background
- O1, Gemini 2.0와 같이 reasoning 성능이 뛰어난 모델들이 나오고 있다.
- 하지만 이러한 모델들은 기술적 세부 사항과 weight가 공개되지 않음 -> 재구현이 어려움
- Reasonging 학습 방법론, data, model weights를 모두 공유함으로써 학계와 오픈소스 커뮤니티에 기여함을 목표로함
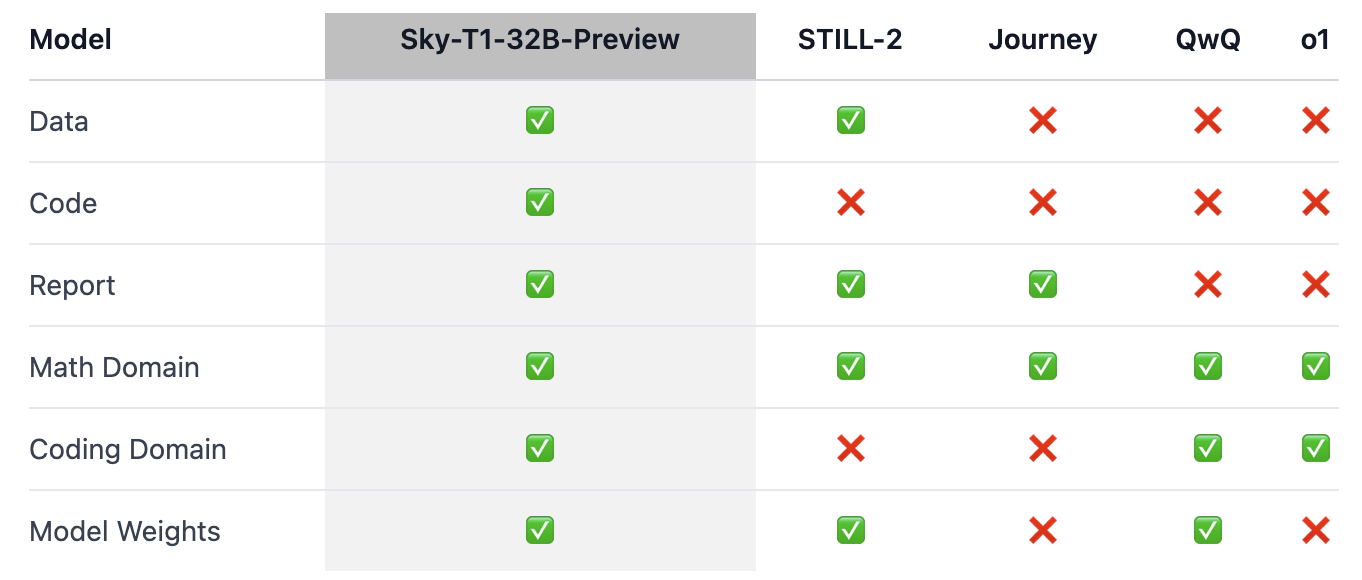
Method

Data Generation
- QwQ-32B-Preview
=> generate training data - Data mixture
=> cover diverse domains - Reject sampling
- 수학문제의 경우: 정답과 매칭되는지 확인
- 코딩문제의 경우: 단위 테스트로 확인
=> improve data quality
- rewrite answer with GPT-4o-mini
- QwQ model로 생성한 답변을 GPT model로 구조화된 형태로 재생성
=> 답변 파싱에 용이하도록 함
- QwQ model로 생성한 답변을 GPT model로 구조화된 형태로 재생성
최종 데이터
- 5k conding dataset (APPs, TACO)
- 10k math dataset (AIME, MATH, Olympiads subsets of the NuminalMath)
- 1k science & puzzle dataset (STILL-2)
Training
- fine-tuning Qwen2.5-32B-Instruct
- 3 epochs
- 1e-5 learning rate
- 96 batch size
- DeepSpeed Zero-3 offload
- Llama-Factory
Evaluation
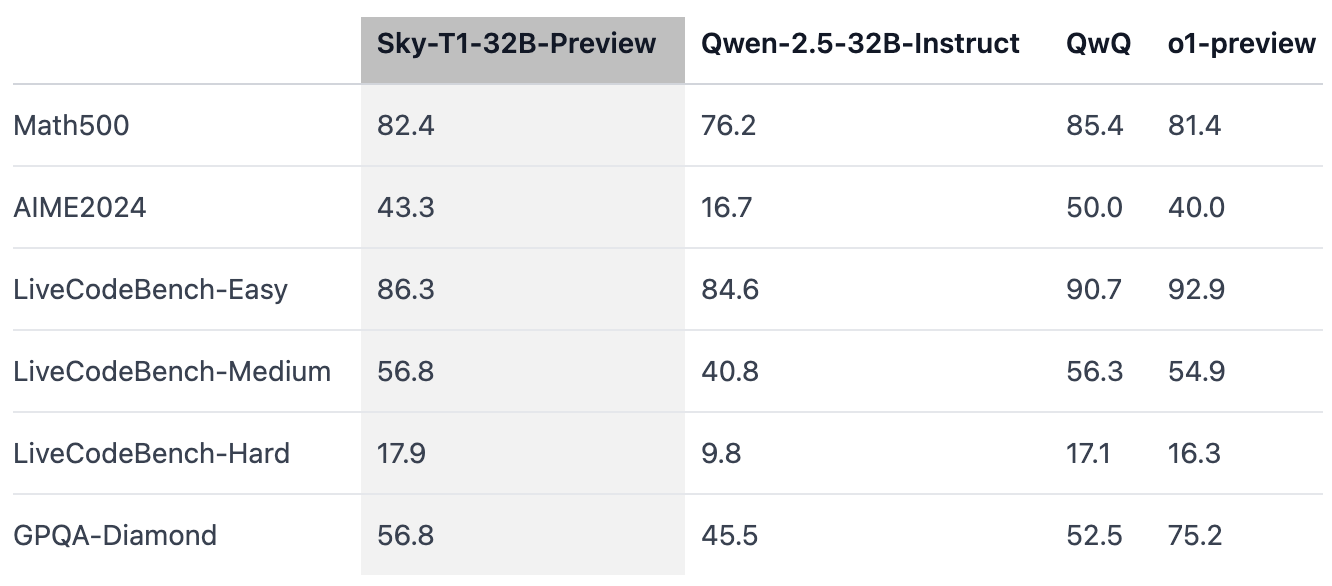
Findings
Model size matters
- 32B보다 작은 모델은 학습시 성능 개선이 미미한 수준임
- 작은 모델은 답변 생성시 반복되는 경향이 있어 성능 개선이 미미하다고 예상
Data mixture matters
- coding dataset 학습시 math 분야 성능이 감소하는 문제 발생
- 코딩문제는 추가 논리적 단계가 요구되지만 수학문제는 더 직관적이고 구조화된 방식임 -> 이러한 차이로 인해 성능 감소 문제 발생
- 이를 해결하기 위해 더 높은 난이도의 데이터를 추가 학습하여 성능 감소 문제 해결
Impact
Reasoning 개선할려면 32B 이상의 모델이 필요한듯
특정 task를 학습하면 다른 task의 성능이 하락하는 문제 발생
=> 이를 해결하기 위해선 더 다양한 난이도의 많은 학습 데이터셋을 구성해야함
해당 포스트에서는 학습 기술이 크게 안중요한듯
데이터 생성부터 평가까지 모든 코드가 정리되어 있어서 재구현하기 좋은듯

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.