
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
논문원본: https://arxiv.org/pdf/2501.12948
Introduction
Background
- post-training이 training pipeline에서 중요한 역할로 자리잡고 있다.
- post-training: Instruction Tuning + RLHF
- post-training -> improve reasoning task, adapt user preference
- Chain-of-Thought 과정을 늘림으로써 inference-time scaling하는 연구를 통해 OpenAI's o1 시리즈 모델이 나옴
- 이를 통해 수학, 코딩, 과학적 추론와 같은 reasoning task에서 상당한 성능 향상
Problem Definition
- 효과적인 inference-time scaling을 위한 연구가 많이 나왔지만 reasoning task에서 o1 시리즈 모델과 동등한 수준에 도달하진
- 많은 양의 supervised data를 모으는 것은 매우 어려움
Proposed Method
- 오직 RL만으로 reasoning task의 성능을 향상시킨 -> DeepSeek-R1-Zero
- DeepSeek-R1-Zero 모델이 갖고 있은 poor readability, language mixing 문제를 해결한 -> DeepSeek-R1
- 작은 모델에서도 뛰어난 reasoning 능력을 갖는 -> Distillation Models
DeepSeek-R1-Zero
Approach
Reinforcement Learning Algorithm
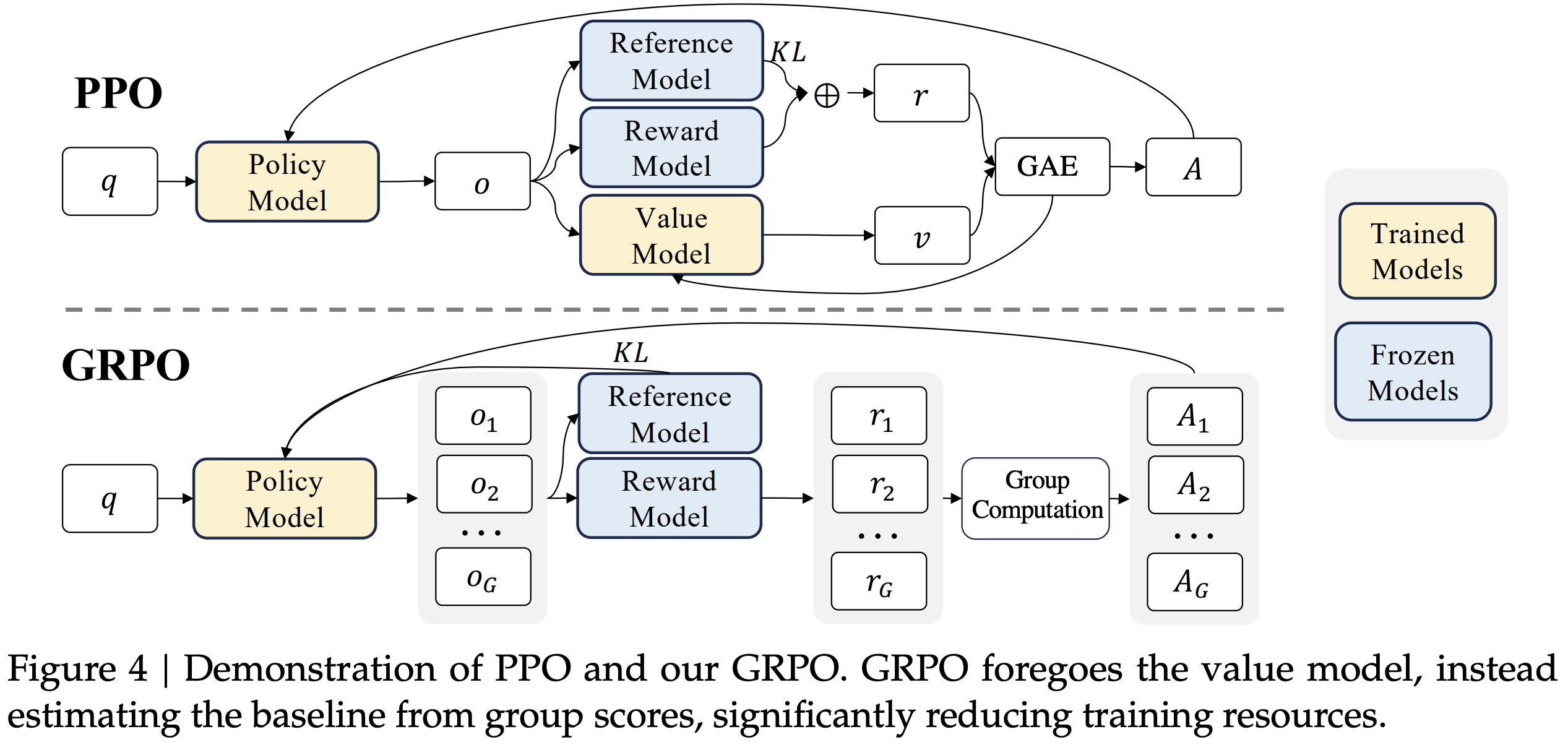
- DeepSeekMath 논문에서 사용한 GRPO를 그대로 사용 (Appendix에 자세한 설명)
- value function이 필요없기 때문에 training cost를 줄일 수 있음
Reward Modeling
- rule-based reward system 사용
- Accuracy rewards: 정답이 일치하는지를 기준
- Foramt rewards: 'think' 태그안에 생각을 잘 넣는지를 기준
- neural reward model 사용안한 이유
- reward hacking
- 추가 리소스 발생, 복잡한 training pipeline
Training Template

- 답변 형식 제한만 함, 어떤 reasoning 절차를 해야하는지 내용적 제한은 안함
Result
Performance
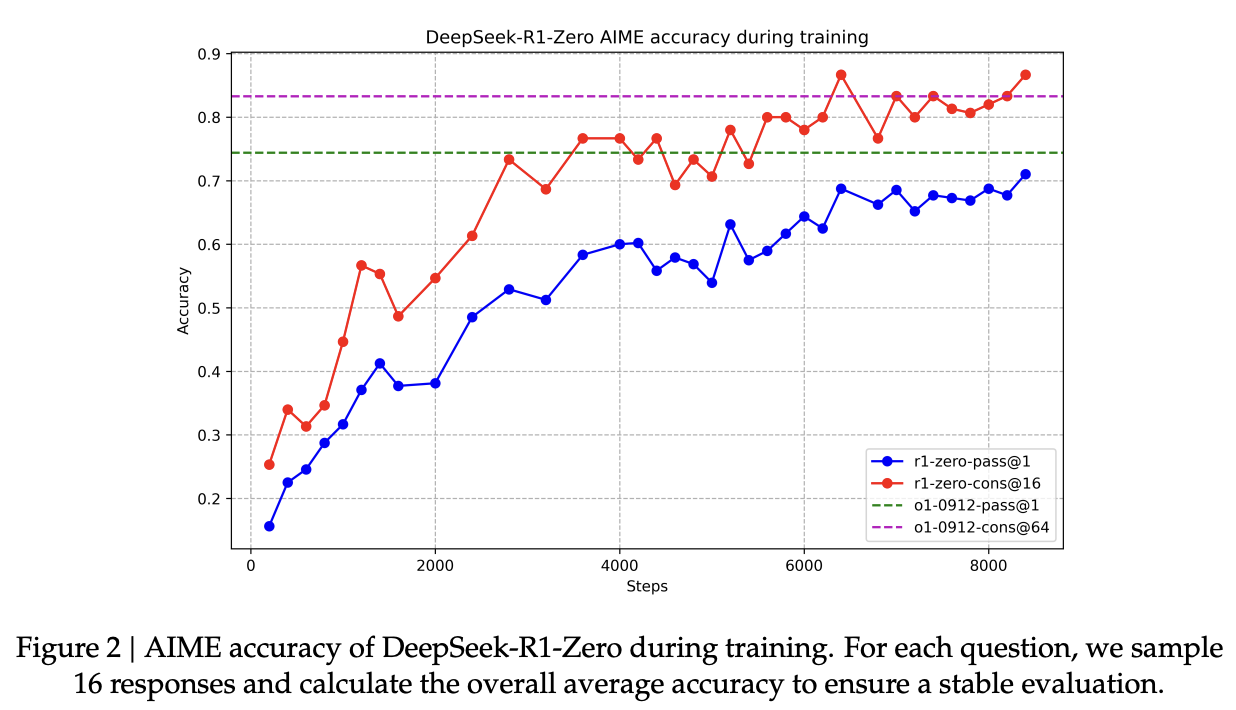
- 학습이 진행됨에 따라 성능도 향상됨
=> RL 알고리즘이 효율적이라는 증거

- o1에 상응하는 성능을 보임
Self-evolution
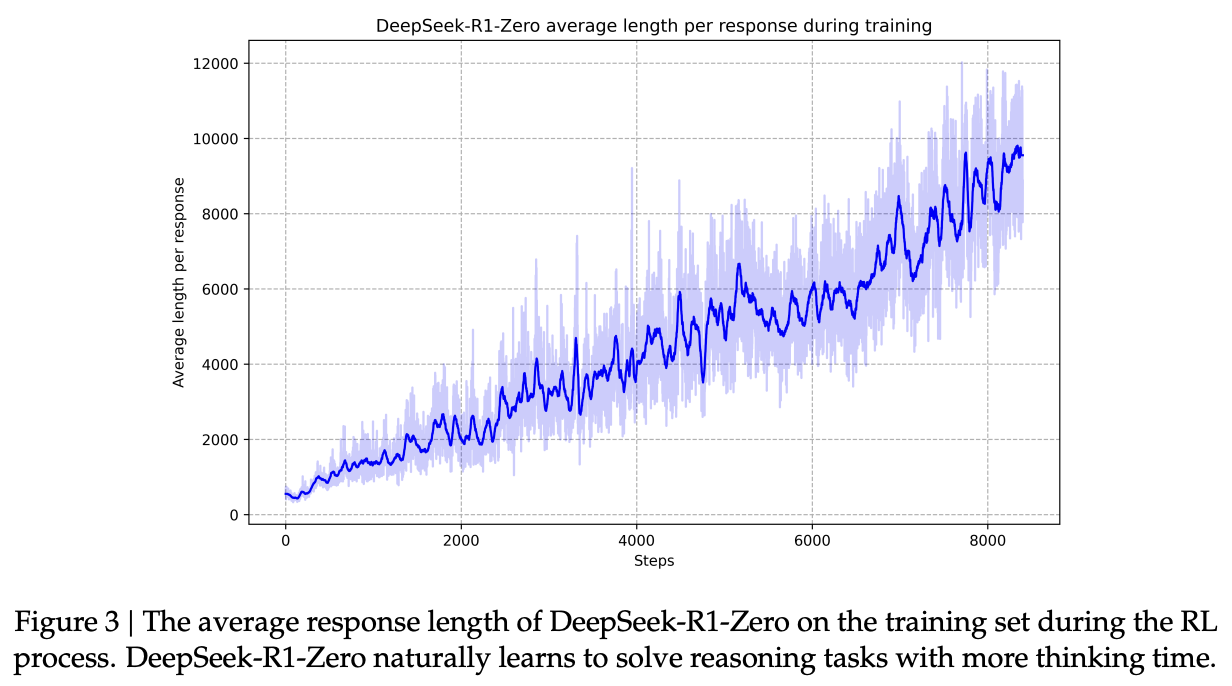
- 학습이 진행되면서 inference-time scaling 되고 있음
- inference-time을 늘림으로써 복잡한 reasoning task를 해결하는 방법을 자기가 알아서 터득한다는 것을 나타냄
=> self-evolution - inference-time이 증가하면서 reflection, exploration of alternative approaches 행동을 터득함
Aha Moment

- 초기 답변을 재평가하면서 (aha moment) thinking time을 늘리는 방법을 알아서 터득함
Drawback
- poor readability, language mixing
- 이를 해결하기 위해 DeepSeek-R1을 연구
DeepSeek-R1
Training Pipeline
1. Finetuning cold-start data (reasoning + readibility)
RL 초기에 불안정한 cold-start 문제를 막기 위한 과정
- 데이터 수집
- cot 예제가 있는 few-shot prompt + reflection & verification 유도하는 프롬프트 사용
- DeepSeek-R1-Zero 모델로 답변 생성
- human annotators로 후처리
- 답변 마지막에 요약을 추가하는 패턴 + 가독성 좋은 데이터로 필터링함
- 수집한 데이터로 DeepSeek-V3-Base 모델을 학습하고 이를 추후에 RL과정에서 초기 policy model로 사용
- 이 과정으로 가독성을 높일 수 있고 cold-start data를 잘 만들면 더 향상될 수 있음
2. Reinforcement Learning (reasoning + readibility)
reasoning 능력을 높이기 위한 과정
- DeepSeek-R1-Zero에서 RL과 거의 동일
- language consistency reward를 추가하여 language mixing 문제 줄임
3. Rejection Sampling & SFT (other domain)
other domain 능력 향상하기 위한 과정 (writing, role-playing, other general-purpose tasks)
- Reasoning data with rejection sampling
- 2번 과정의 checkpoint로 답변 생성
- 기존 rule base reward를 통해 필터링
- DeepSeek-V3에게 정답과 생성 답변을 보고 평가하여 필터링 (generative reward model)
- mixed language, long paragraphs, code blocks 등과 같이 가독성 떨어지는 거 필터링
- 600k 데이터 수집
- Non-reasoning data
- writing, factual QA, self-cognition, translation
- DeepSeek-V3에 SFT dataset 일부 사용
- 200k 데이터 수집
- 총 800k 데이터로 학습
4. Reinforcement Learning (human preference)
사람 선호에 맞게 답변 생성하기 위한 과정 (helpfulness, harmlessness)
- Reasoning data
- 2번 과정과 동일한 방법으로 학습
- General data
- DeepSeek-V3와 비슷하게 다양한 학습 프롬프트 분포도를 사용
- helpfulness 에선 마지막 summary 부분만 보고 reward model로 평가
- harmlessness 에선 모든 답변을 보고 reward model로 평가
Result

- knowledge benchmarks
- MMLU, MMLU-Pro, GPQA Diamond
- large-scale RL로 뛰어난 성능 나옴
- long-context-dependent QA
- FRAMES
- 뛰어난 성능 -> 문서 분석 능력
- factual benchmark
- SimpleQA
- english에서 DeepSeek-V3를 이김
- chinese에서는 안좋아진 것은 safety RL 때문
- format instructions benchmark
- IF-Eval
- 성능 안좋은데????
- writing task & open-domain QA
- AlpacaEval2.0, ArenaHard
- 좋은 성능
- coding benchmarks
- o1 모델에 상응하는 성능 나옴
- math benchmarks
- o1 모델을 능가하는 성능 나옴
Distillation Models
Approach
- Distillation을 통해 Qwen, Llama 시리즈 모델들의 reasoning을 개선해보자!
- DeepSeek-R1 학습 과정 중 3번 Rejection Sampling & SFT 과정을 사용하여 학습
- 단, 답변 생성에 사용하는 모델을 DeepSeek-V3-Base(RL checkpoint)에서 DeepSeek-R1로 변경
Result
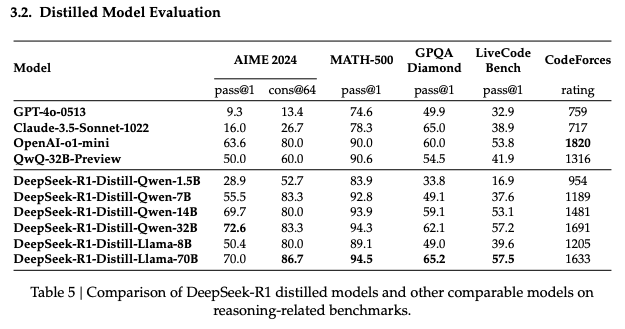
- distillation SFT 만으로 뛰어난 성능 나옴
- 이후에 RL을 하면 성능이 더 좋아질 것으로 기대됨
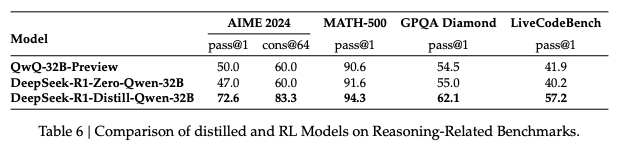
작은 모델은 RL을 통해 직접 reasoning 능력을 습득하는 것보다 distillation하는 것이 더 효율적으로 뛰어난 결과를 가져온다
Limitation & Impact
Limitation
- function-calling, multi-turn, complex role-playing, json output 부분에서 DeepSeek-v3보다 성능이 안좋음 (paper)
- DeepSeek-R1은 chinese & english에만 최적화됨 (paper)
- few-shot prompt를 하면 성능이 안좋아짐 (paper)
- software engineering task 성능이 좋지 못함 (paper)
Impact
- 적은 양의 supervised data로 뛰어난 reasoning 능력을 학습할 수 있다는 점
- GRPO, rule-based reward 등 효율적인 리소스를 사용하여 학습할 수 있다는 점
- 작은 모델은 직접 reasoning 능력을 터득하는 것보다 distillation이 더 효율적이고 성능도 더 좋다는 점
Appendix
PPO
surrogate objective

Advantage Function <- Generalized Advantage Estimation
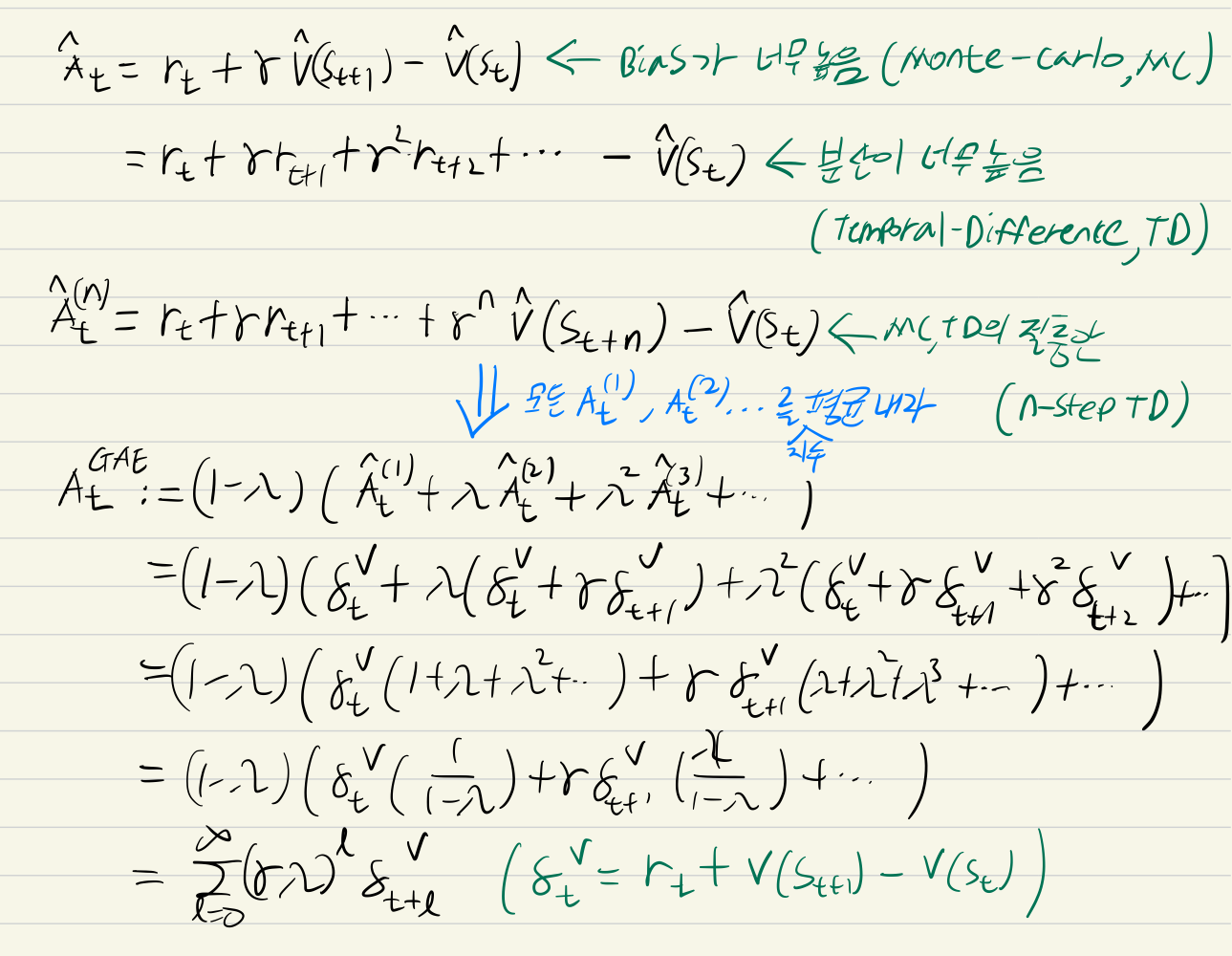
- 람다값이 0이면 TD와 동일하게 됨 -> 람다, 감마 값으로 편향-분산 조절 가능
Reward model

Value function model은 일반적으로 policy model과 동일한 크기로 사용하는데 이때 리소스 문제가 발생
일반적으로 reward는 가장 마지막 토큰에서 발생(sparse reward)
-> 이전 토큰에 대한 value function을 올바르게 학습하기 어려움
GRPO
surrogate objective
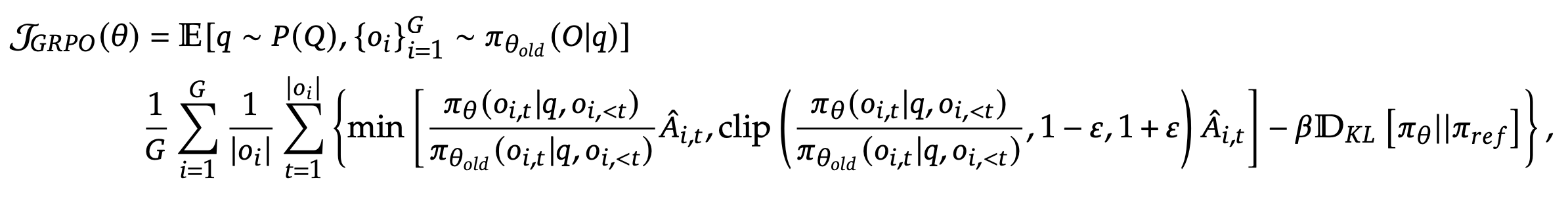
- 하나의 질문에 G개의 답변을 생성
- value function 없이 advantage 구할 수 있음
KL divergence
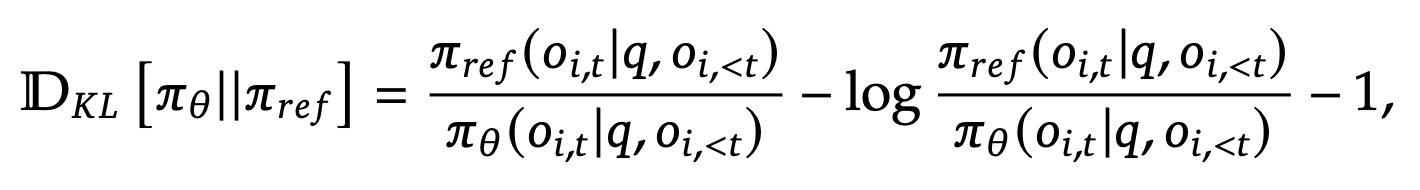
Advantage function
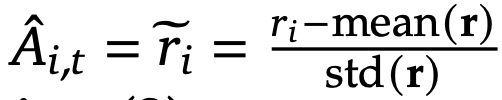 - i는 G개의 답변중 하나, t는 토큰 위치
- i는 G개의 답변중 하나, t는 토큰 위치
Algorithm

PPO vs GRPO
Reference

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.