
논문원본: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3707964
Introduction
Background
- 전통적인 거시경제 모델은 소수의 변수만 처리 가능(전통적 거시경제 변수)
- 빅데이터와 머신러닝의 부상으로 많은 변수를 포함한 졍교한 모델을 개발할 수 있음
Problem Definition
- 빅데이터, 머신러닝 기술을 효과적으로 사용할 필요가 있음
- 이를 위해 전통적 변수뿐 아니라 수많은 새로운 경제 변수의 통계적&구조적 관계를 모두 기술할 수 있는 새로운 지식체계 필요
Proposed Method
- 전통적 거시경제 변수와 대체 데이터 변수를 연결하는 지식 그래프를 구축
- 텍스트 데이터에서 NLP를 활용하여 다음 세가지 추출
- 전통적으로 관심을 가지는 변수(GDP, inflation rate, housing price, etc)
- 대체 데이터 변수(electricity usage, migration flow, etc.)
- 이러한 변수들 간의 관계(positive corr, negative corr, etc.)
- inflation rate 변수 중심 subgraph 예시
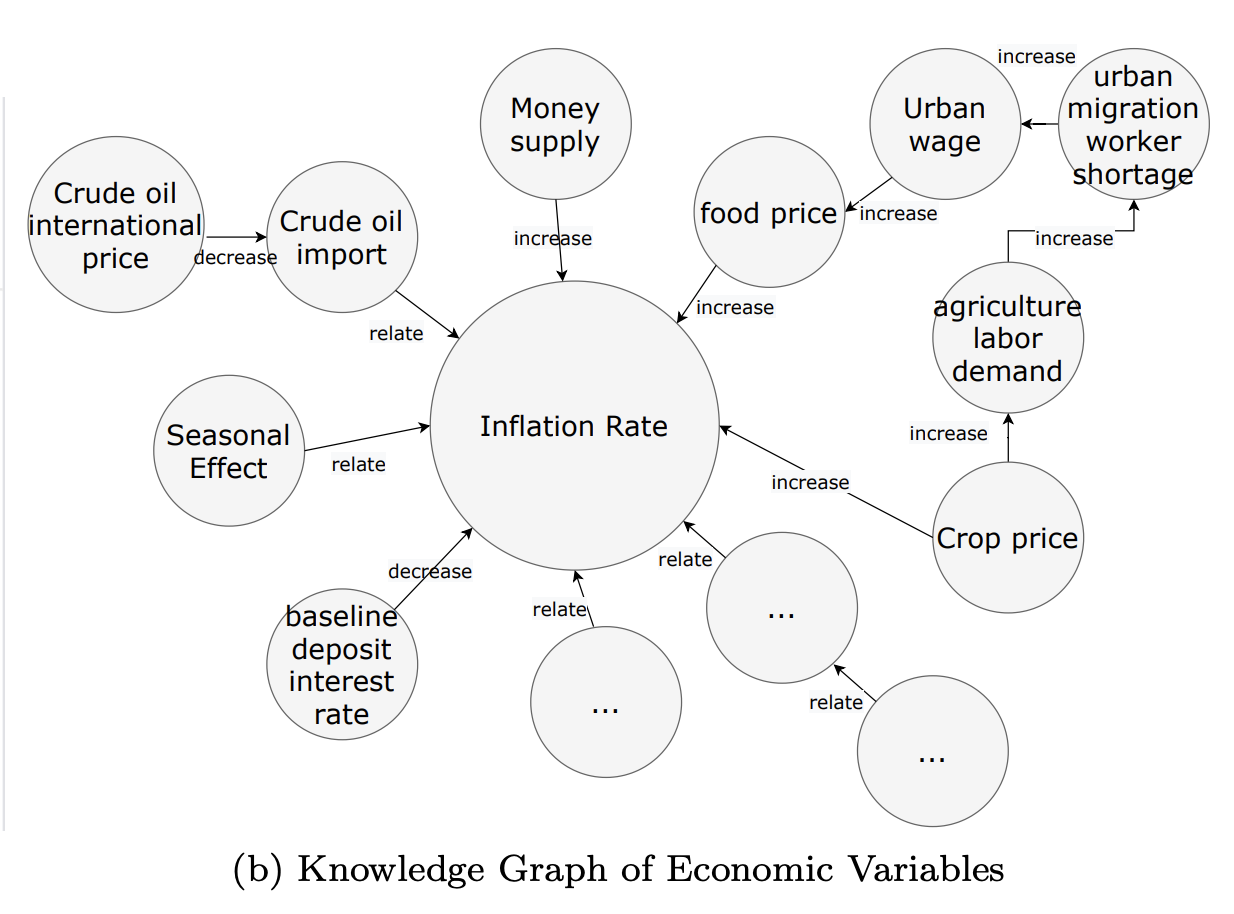
- 위 subgraph 예시에서 오른쪽에 crop price가 연쇄적으로 inflation rate에 어떻게 영향을 주는지 파악할 수 있다는 점 -> 지식그래프의 multi hop 추론 강점을 드러냄
Application
- 경제 예측의 변수 선택에 적용
Method
Data
- 중국 산업 연구 보고서 사용
- 주요 텍스트 데이터 소스로 사용한 이유
- 거시 변수의 동향 분석 또는 예측에 집중하고 변수가 명확히 제시
- narrative approach 채택 (관계들을 수학적으로 표현하지 않고 서술하는 방식)
- 무료 제공
Construction of Knowledge Graph
- 관심 변수 목록 및 변형어 작성
- 예시: GDP(output, economic growth), housing price(housing market), ...
- 문서에서 관심 변수 및 변형어 검출
- 문자열 매칭 기반
- 관심 변수 주변 다른 변수 간 관계 추출
- 변수와 관계의 개수 비율이 동일하지 않은 문장을 찾아서 사람이 직접 검수 및 추출
- 관계는 increase, decrease, relate 중 하나
- 추출된 변수와 관계를 RDF 트리플 구조로 표현하여 그래프에 추가
- co-references 병합 -> 최종 지식 그래프 구축
- 각 엔티티를 벡터로 표현하여 유사도 계산 및 사람이 직접 검수
지식그래프 구축 예시
- 예시 문장
“가오 박사는 2005년경 중국 이주 노동자 시장에서 장기적인 체계적 이주 노동자 부족이 발생하기 시작했으며, 이는 이주 노동자의 임금 상승률을 크게 높였고, 그 결과 식품 물가가 상승하였으며, 소비자물가지수의 상승을 촉발하여 평균 인플레이션을 약 100~200bp 상향시켰다.”
- 추출한 RDF 트리플
- {이주 노동자 부족, increase, 이주 노동자의 임금 상승률}
- {이주 노동자의 임금 상승률, resulted in, 식품 물가}
- {식품 물가, push up, 소비자물가지수}
- {식품 물가, make higher, 인플레이션}
- 서브그래프 구축
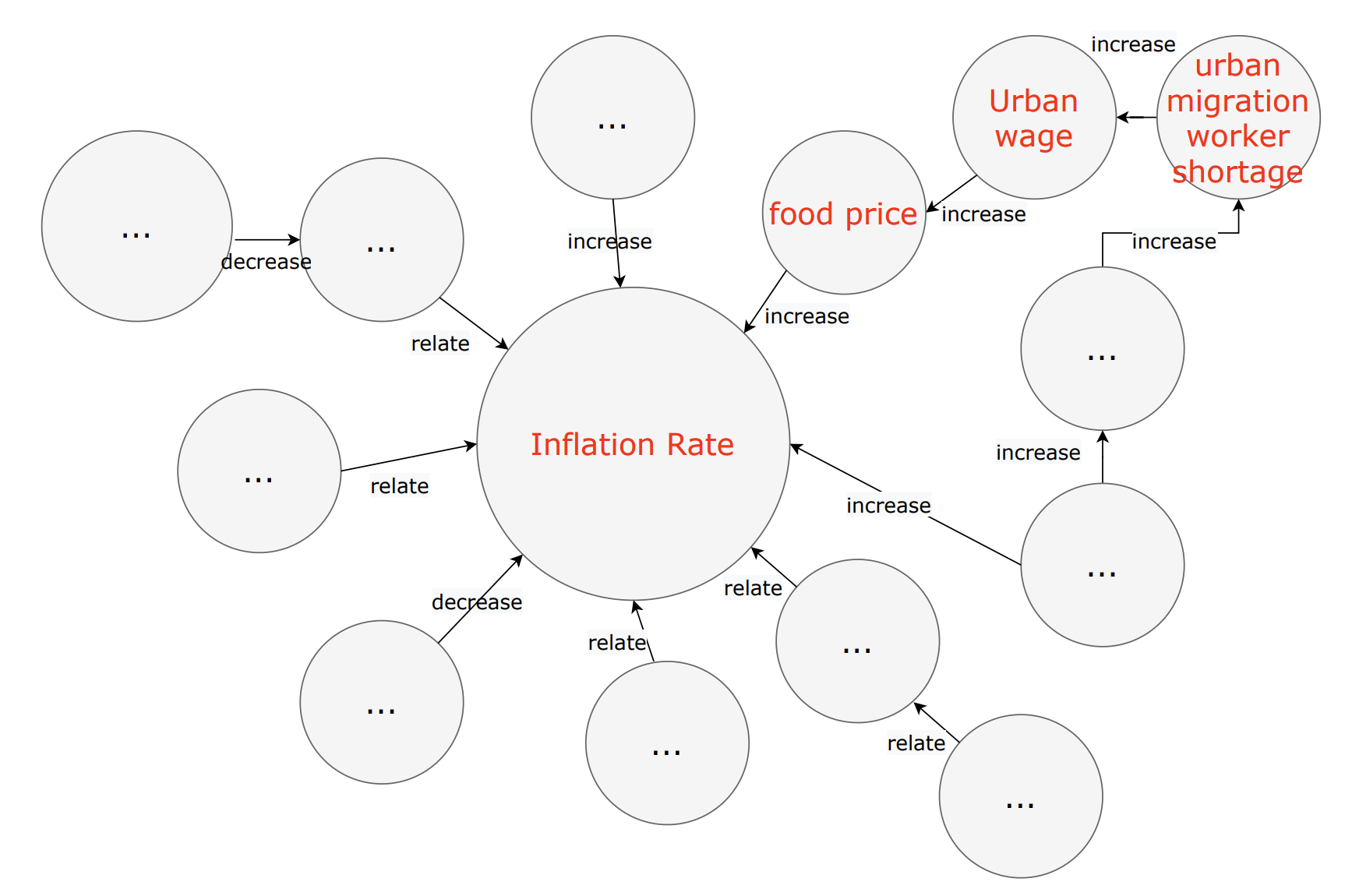
Application
Reinforcement Learning
- 거시경제를 하나의 강화학습으로 공식화 (상태공간, 행동, 보상)
- 지식그래프에서 얻은 변수간 인과관계 -> 어떤 행동이 어떤 상태를 변화시킬지 예측하고 목표 변수를 극대화하는 정책을 학습하는 것이 가능해짐
Economic Forecasting
- 두가지 경제지표를 예측
- china's monthly inflation rate
- china's nominal investment(중국 경제 전체 차원의 총투자 지출)
- 변수선택 방법에 차이를 두고 Lasso 회귀 학습 후 12개월 예측
- 전통방법: 고정된 12개 변수를 입력으로 사용 (GDP, Nominal Consumption, ...)
- KG 기반 방법: 지식그래프에서 예측할 지표와 직접 연결된 24개 또는 19개 변수를 입력으로 사용 (1년 대출금리, 환율, 도시 실업률, ...)
- 결과
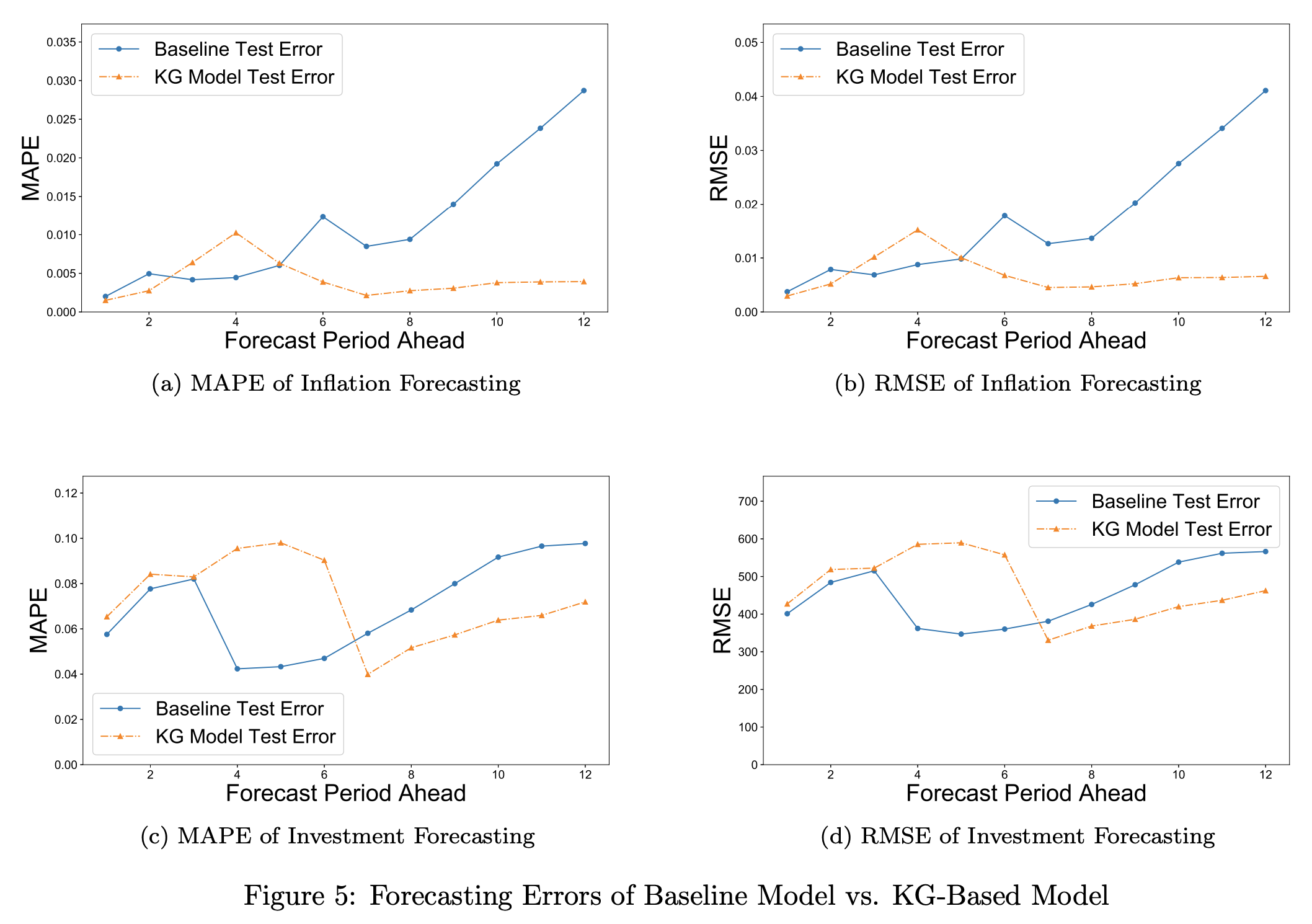
- 전통모델은 장기예측에서 성능이 떨어지지만 kg기반 모델은 장기 예측에서도 안정적인 성능이 나옴
- "단기예측은 데이터 기반, 장기 예측은 문제의 내재적 논리 포작이 중요" -> kg 기반 모델은 진정한 경제 시스템의 논리를 잘 반영함을 시사
Limitation & Impact
Limitation
- 텍스트에서 엔티티와 관계를 추출하는 과정에서 사람의 검수가 너무 많이 필요함
- economic forcating 활용에서 직접 연결된 변수들만 사용
- 전통방법과 kg기반 방법을 비교할때 선택 변수 개수의 차이가 있어서 형평성에 떨어짐
Impact
- "이주 노동자 부족" -> ... -> "인플레이션" 상향시킨다는 multi hop 관계를 보여주면서 지식그래프 구축이 갖는 강점을 잘 보여준 것으로 보인다.
- 엔티티와 관계를 LLM으로 추출한다면 사람의 검수가 덜 필요해지고 정확도도 더 높아질 것으로 생각된다.
- 텍스트 데이터를 통해 지식그래프를 구축한다면 시간에 따라 변화하는 macro 지표들 간에 관계를 잘 포착할 수 있을 것으로 예상된다.

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.