
논문원본: https://arxiv.org/pdf/2404.16130
Introduction
Background
- LLM은 한번에 처리할 수 있는 최대 텍스트 단위인 context window 크기에 제한이 있음 -> 이를 해결하기 위해 RAG 사용
- RAG는 사용자의 질의와 개별적으로 관련성이 높은 문서들을 context window 내에 들어갈 수 있도록 검색하고 검색된 문서들을 기반으로 답변 생성
Problem Definition
- 표준 RAG는 글로벌 수준의 이해를 요구하는 질문에 적합하지 않음
| "과학적 발견이 최근 10년간 어떻게 학제 간 연구에 의해 영향을 받았는가?"
Proposed Method
- 글로벌 수준의 의미 이해를 가능하게 해주는 GraphRAG 방식 제안
- 정답이 명확하지 않은 폭넓은 주제나 테마에 대한 질문을 다루는 평가 방법 설계
- LLM-as-a-judge 방식으로 기존 RAG 방식과 비교 평가 수행
GraphRAG pipeline
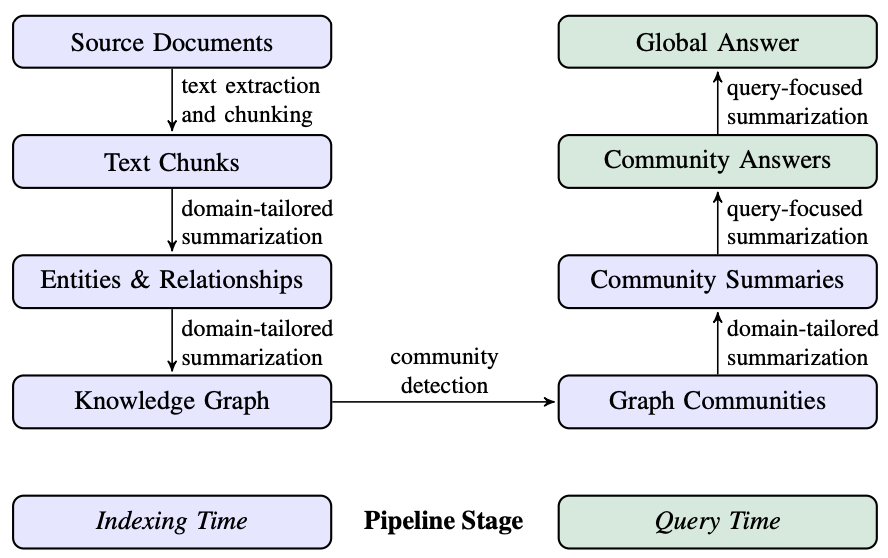
1. Source Documents -> Text Chunks
- 말뭉치 내 문서를 텍스트 청크로 나눔
2. Text Chunks -> Entities & Relationships
- LLM을 통해 각 청크에서
- 엔티티와 엔티티 간 관계를 추출
- 각 엔티티와 관계에 대한 설명 생성
- 엔티티에 대한 주장 도출
- Self-reflection -> entity 추출
- 추출한 엔티티를 LLM에게 주면서 모든 엔티티가 추출되었는가 를 평가하여 logit bias 를 100으로 설정하여 예/아니오 선택하도록 강제
- "아니오" 이면 추가로 "이전 추출에서 많은 엔티티가 누락되었습니다" 라는 말을 prompt에 추가하여 누락된 엔티티를 적극적으로 탐지하도록 유도
- 1,2 과정을 최대 지정 횟수만큼 반복
- 예시
"NeoChip(NC)의 주가는 NewTech 거래소 상장 첫 주에 급등했다. 하지만 시장 분석가들은 이 반응이 다른 기술 IPO의 흐름을 반영하지는 않을 수 있다고 경고했다. NeoChip은 과거에는 비상장사였고, 2016년에 Quantum Systems에 인수되었다. 이 반도체 회사는 웨어러블 및 IoT용 저전력 프로세서를 전문으로 한다."- 엔티티: NeoChip
설명: “NeoChip은 웨어러블 및 IoT 장치용 저전력 프로세서를 전문으로 하는 상장 기업이다.” - 엔티티: Quantum Systems
설명: “Quantum Systems는 과거 NeoChip을 소유했던 회사이다.” - 관계: Quantum Systems → NeoChip
설명: “Quantum Systems는 2016년부터 상장 시점까지 NeoChip을 소유했다.” - 주장 (claim)
- NeoChip의 주가는 상장 첫 주에 급등했다.
- NeoChip은 NewTech 거래소에 상장되었다.
- Quantum Systems는 NeoChip을 2016년에 인수했으며, 이후 상장까지 소유했다.
- 엔티티: NeoChip
3. Entities & Relationships -> Knowledge Graph
- 정확히 문자열이 일치하는 엔티티들의 중복 제거 - 어차피 클러스터링 과정이 있어서 중복에 강건함
- 관계의 중복 횟수는 엣지 가중치로 반영
4. Knowledge Graph -> Graph Communities
- Leiden 알고리즘을 사용해 강하게 연결된 노드 집단으로 재귀적 분할
- 실험시 C0~C3 단계까지 계층을 나눔
- C0: 가장 최상위 계층(가장 큰 단위로 클러스터링)
- C3: 리프 노드들에서 첫번째로 클러스터링한 결과
5. Graph Communities -> Community Summaries
- 각 커뮤니티에 대해 보고서 형태의 요약 생성
- 리프 커뮤니티
- 각 엣지를 중요도 순으로 정렬
- 노드, 엣지, 관련 주장을 context window 이후 제거후 삽입하여 LLM으로 요약 생성
- 상위 커뮤니티
- 하위 커뮤니티 요약과 개별 노드, 엣지, 주장을 삽입
- 만약 context window를 넘으면 하위 커뮤니티 요약만 사용하여 요약 생성
6. Community Summaries -> Community Answers -> Global Answer
- 특정 계층의 커뮤니티 요약들을 무작위로 섞은 뒤 일정 토큰 크기 단위로 분할
- map: 병렬적으로 각 요약을 바탕으로 답변 생성, 질문에 대한 유용도 점수도 계산
- Reduce: 유용도 점수에 따라 응답을 정렬하여 context window까지 삽입후 최종 글로벌 응답 생성
글로벌 의미 이해 평가
글로벌 의미 이해 질문 생성
- 개별 사실 검색이 아닌 전체 맥락 이해를 요구하는 질문 생성
- 알고리즘
- 입력: 말뭉치 설명(사람이 직접 작성), 사용자 수 k, 사용자별 과업 수 N, (사용자, 과업) 별 질문 수 M
- 출력: 총 KxNxM개의 질문 생성
- 과정: LLM에게 아래 수행하도록 프롬프트 작성
- k명의 가상의 사용자 페르소나 생성
- 각 사용자에 대해 N개의 과업 생성
- 각 과업에 대해 M개의 고차원 질문 생성(전체 말뭉치 이해 요구해야 하며 개별 사실 검색은 요구하지 말것)
글로벌 의미 이해 평가
- LLM-as-a-judge로 두 시스템 간 응답 비교
- 평가기준
- Comprehensiveness (포괄성): 질문의 모든 측면을 충분히 설명하는가?
- Diversity (다양성): 다양한 관점과 정보를 제공하는가?
- Empowerment (이해도 향상): 독자가 주제를 더 잘 이해하고 판단하는데 도움이 되는가?
- Directness (직설성): 질문에 얼마나 명확하고 간단히 답했는가?
- 질문, 두 시스템의 응답을 보고 평가기준을 참고하여 승자를 판단
- 5회 반복 실행후 평균으로 결과 산출
Experiments
Data
- 팟캐스트 전사본
- microsoft CTO가 다양한 기술 리더들과 나눈 대화내용
- 1669개의 600토큰 청크로 구성, 전체 크기는 약 100만 토큰
- 뉴스 기사
- 3197개의 600토큰 청크로 구성, 전체 크기는 약 170만 토큰
Experiment 1
-
실험 조건
- C0(루트 수준) 커뮤니티 요약만 사용
- C1 커뮤니티 요약만 사용
- C2 커뮤니티 요약만 사용
- C3(가장 낮은 수준) 커뮤니티 요약만 사용
- TS(Text Summarization): 문서 원문을 직접 map reduce 방식으로 요약
- SS(Semantic Search): 전통 RAG
-
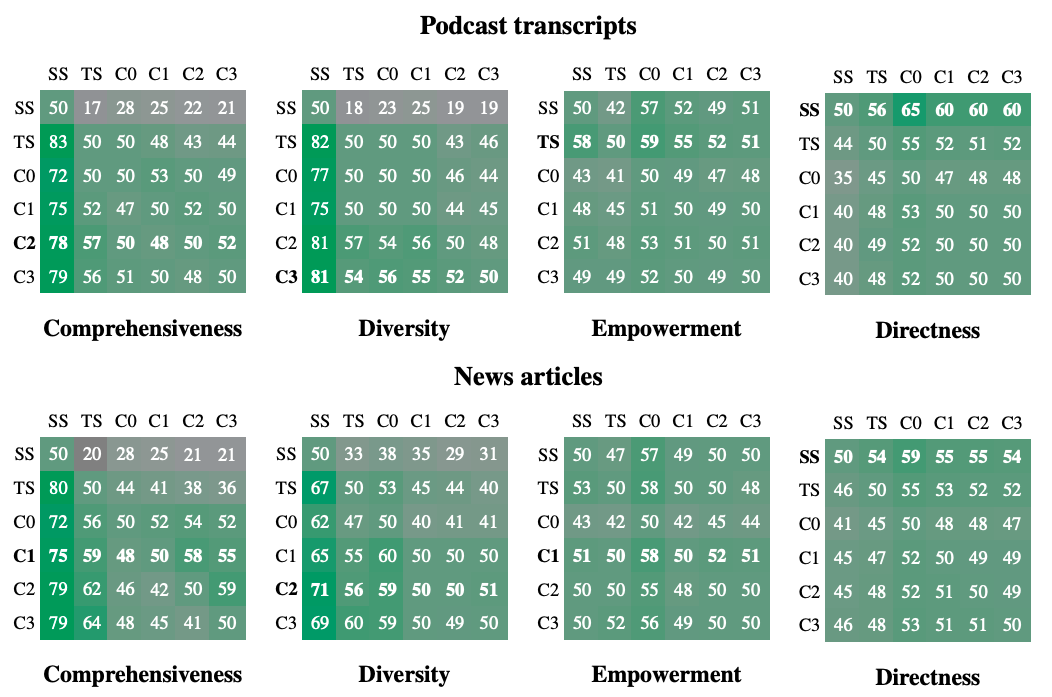
result

-
해석
- Comprehensiveness 포괄성
- 팟캐스트: 72~83% 우세(GraphRAG vs ss), 57% 승률(c2 vs ts)
- 뉴스: 72~80% 우세(GraphRAG vs ss), 64% 승률(c3 vs ts)
- Diversity 다양성
- 팟캐스트: 75~81% 우세(GraphRAG vs ss), 57% 승률(c2 vs ts)
- 뉴스: 62~71% 우세(GraphRAG vs ss), 60% 승률(c3 vs ts)
- Directness 직설성
- 팟캐스트: 56~65% 우세(ss vs GraphRAG)
- 뉴스: 54~59% 우세(ss vs GraphRAG)
- Emppowerment 이해도 향상
- 큰 차이 없음
- 효율성
- 97% 이상 토큰 절감(c0 vs ts)
- Comprehensiveness 포괄성
Experiment 2
- 응답에서 고유 주장을 추출하고 고유 주장들을 유사도 기준으로 클러스터링한 결과를 사용
- result

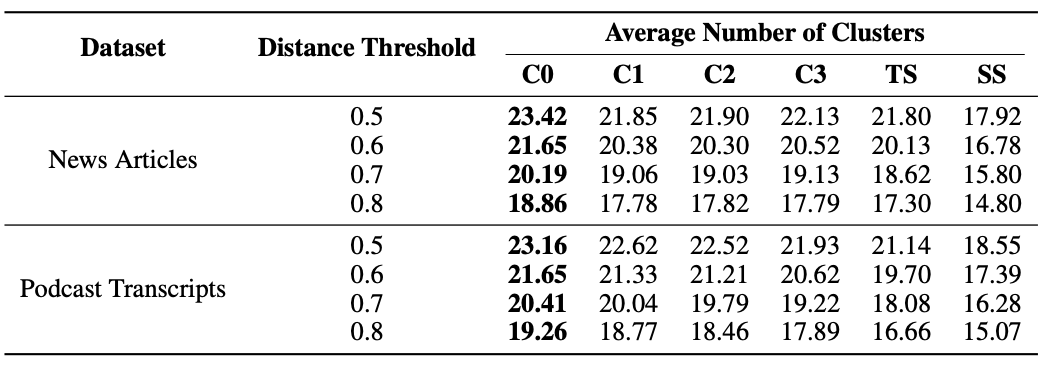
- GraphRAG가 ss보다 우세
Limitation & Impact
Limitation
- (c0 ~ c3)특정 계층을 선택해야 한다는 점 -> future work에 상위 커뮤니티에서 부터 리프 커뮤니티까지 탐색하는 전략 나옴
- 어떤 쿼리가 와도 모든 커뮤니티의 답변을 생성해야 한다는 점에서 비용, 시간 측면에서 비효율적 -> 추후에 이를 수정한 LightRAG paper review 예정
Impact
- 기존 RAG방식의 한계를 명확히 보여주고 GraphRAG의 장점을 잘 설명해준 논문으로 생각됨
- leiden 알고리즘으로 knowledge graph를 클러스터링 하는 방법론은 활용하기 좋아보임

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.