
A Large Language Model Enhanced Conversational Recommender System paper review
논문원본: https://arxiv.org/pdf/2308.06212
Introduction
Background
- LLM으로 인해 대화 지능이 발달함으로써 CRS의 관심이 높아짐
- CRS의 sub-tasks
- User preference elicination

- recommendation

- explanation

- item information search
- User preference elicination
Problem Definition
- CRS의 challenges
- 해당 turn에서 어떤 sub-task를 해야할지
- 각 sub-task를 어떻게 잘 해결할지
- 어떻게 좋은 답변을 생성할지 (사람이 말하는 것처럼 자연스러운 답변)
Proposed Method
- LLM을 통해 sub-task를 결정
- 각 sub-task의 expert model을 사용해 각 sub-task 성능 향상
- LLM을 사용해 답변생성
LLMCRS framework & RLPF 제안
Framework
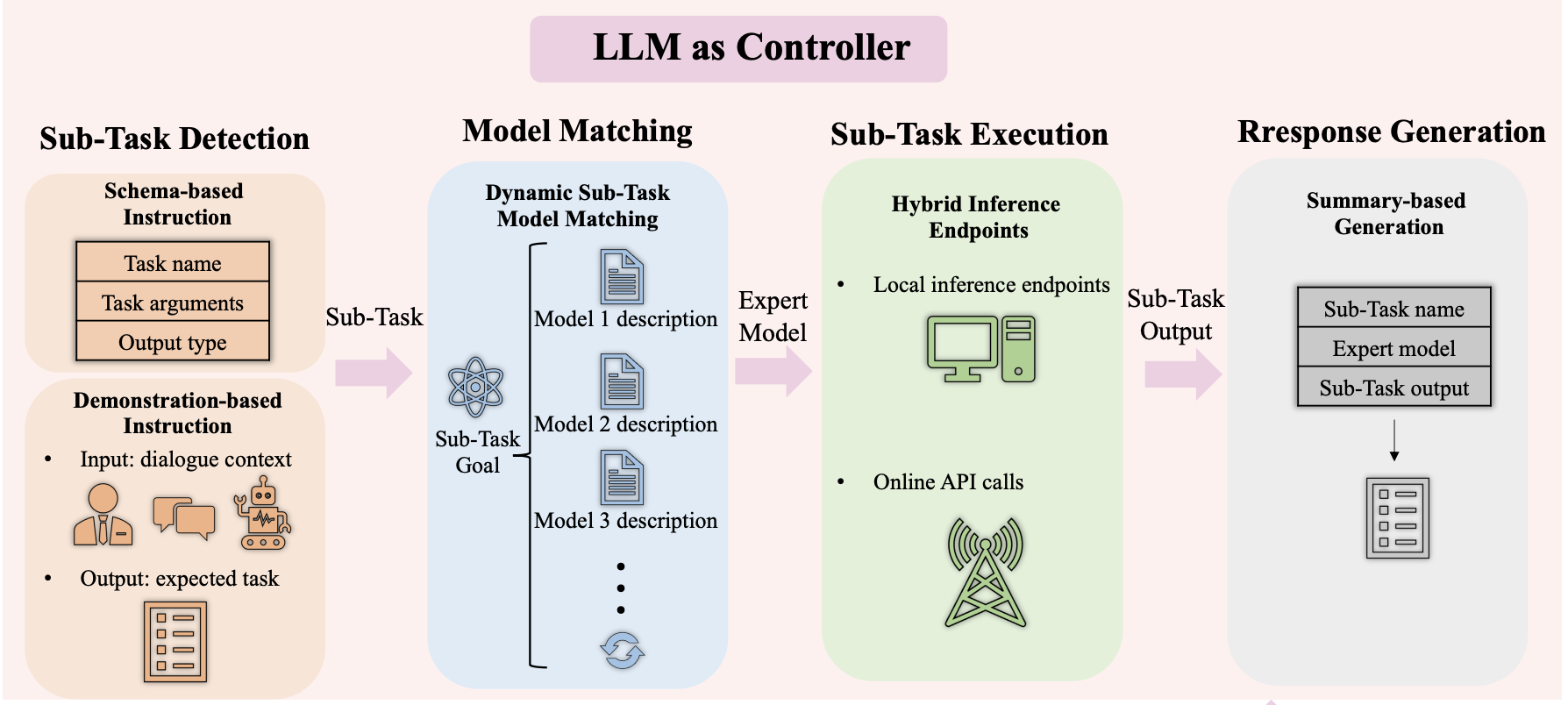
Sub-Task Detection
- LLM을 사용해 이전 대화기록을 바탕으로 현재 turn에서 어떤 sub-task를 해야할지 결정
- sub-task: 위에 CRS의 sub-task와 동일
- Instruction prompt 기술 사용
- Schema-based Instruction
- 각 sub-task의 name, arg, output_type
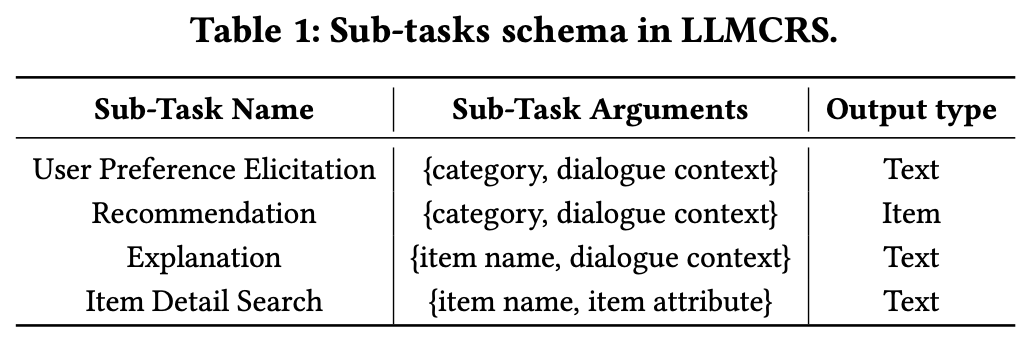
- 각 sub-task의 name, arg, output_type
- Demonstration-based Instruction
- few-shot prompt라고 생각하면 됨
- Schema-based Instruction
- Prompt
The AI assistant should analyze the dialogue context to detect which sub-task should be selected. The subtasks include: {{ Sub-Task List }}. The selected sub-task need to represent by its corresponding sub-task schema. The sub-task schema is {{ Sub-Task Schema }}. There are some cases for your reference: {{ Demonstrations }}. The dialogue context is {{ Dialogue Context }}. From this dialogue context, which sub-task should be selected? The sub-task MUST be selected from the above list and represented by the schema.
Model Matching
- sub-task detection 과정에서 선택된 sub-task에 적절한 expert model을 결정
- Dynamic sub-task and Model Matching
- LLM은
expert model의description들을 보고 선택된sub-task의 목표에 적절한 model을 결정 - expert model을 추가하고 싶으면 해당 description만 prompt에 추가하면 됨 ⇒
Dynamic
- LLM은
- Prompt
The AI assistant should select the most appropriate expert model to process the sub-task based on the subtask goal and expert model description. The sub-task goal is {{ Sub-Task Goal }}. The list of expert models is {{ [ID, Description] }}. Please select one expert model. The expert model MUST be selected from the above list and represented by the ID.
Sub-Task Execution
- sub-task detection 과정에서 얻은 argument를 input으로 expert model 실행
- output을 LLM에 전달
Response Generation
- dialogue context, sub-task, Expert Model, sub-task output 을 입력으로 받아서 최종 답변 생성
- Prompt
With the dialogue context and the sub-task results, the AI assistant needs to generate a response to the user. The dialogue context is {{ Dialogue Context }}. The sub-task results can be formed as: Sub-Task Name: {{ Sub-Task Name }}, Expert Model: {{ ID, Description }}, and SubTask Output: {{ Output }}. Please generate a response to answer the user’s request.
REINFORCEMENT LEARNING
RLPF
- 추천 성능, 답변 생성 성능 향상
Reward
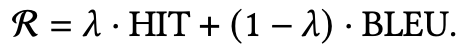
Policy gradient
 - Appendix 참고
- Appendix 참고
EXPERIMENTS
Used Expert models in LLMCRS
- user preference elicitation task
- KBRD
- KGSF
- recommendation task
- TG-ReDial method
- explanation task
- KBRD, KGSF
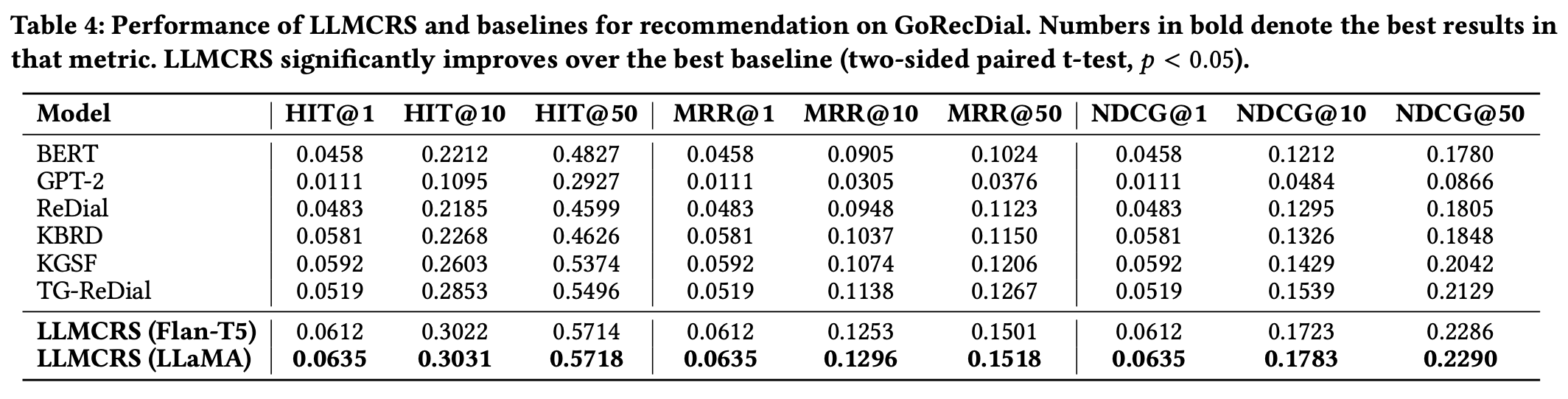
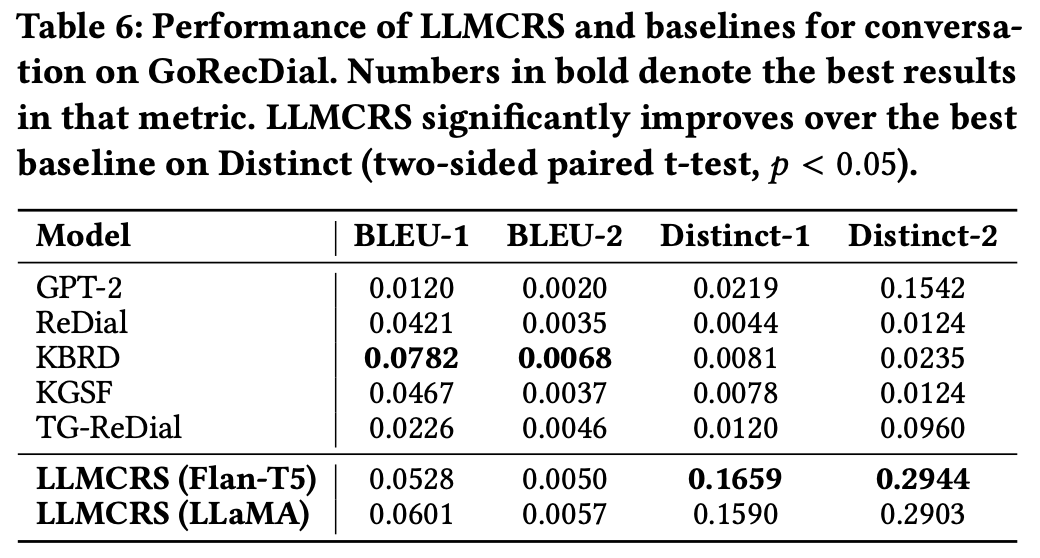
Overall Result
- 두개의 벤치마크 데이터셋에서 추천성능 지표, 대화생성성능 지표에서 뛰어남을 보임
Ablation Study
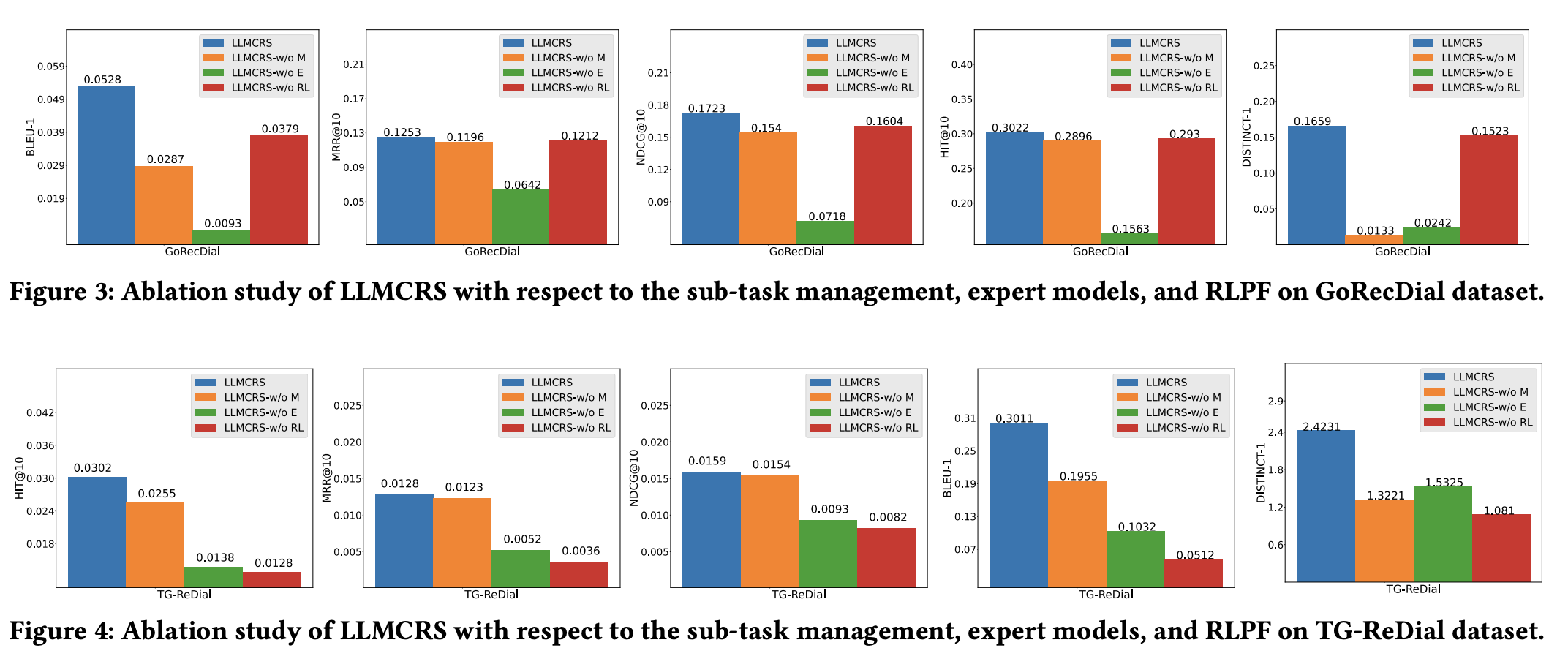
- GoRecDial dataset 결과 해석
- 각 작업을 Expert model로 수행하는것이 모든 지표에서 중요한 요소임 (Model Matching)
- Distinct 지표에서 sub-task를 구별하는 것이 중요 요소임 → 답변의 다양성에 중요 요소 (sub-task detection)
- TG-ReDial dataset 결과 해석
- RLPF가 중요한 요소로 작용 → 해당 데이터셋이 특정 주제에 대한 대화임 ⇒ 특정 도메인 최적화에 도움이 된다는 증거
Mechanisms to Instruct LLM
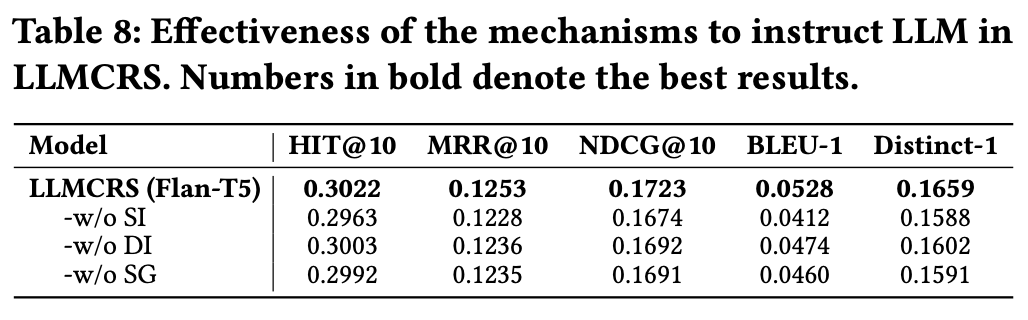
- w/o SI: schema-based instruction
- w/o DI: demonstration-based instruction
- w/o SG: summary-based instruction
Case Study
 - ground truth와 비교했을 때 적절한 영화를 추천해줌 → **정확한 추천 성능**
- LLMCRS는 단순 영화 제목 추천이 아니라 추가 정보를 제공함 → **자연스러운 대화생성 성능**
- ground truth와 비교했을 때 적절한 영화를 추천해줌 → **정확한 추천 성능**
- LLMCRS는 단순 영화 제목 추천이 아니라 추가 정보를 제공함 → **자연스러운 대화생성 성능**
CONCLUSION
- LLMCRS는 LLM을 통해 기존 CRSs 의 문제를 해결함
- LLM을 통해 sub-tasks를 결정하고 각 sub-task에 대해 expert model의 결과를 조합하여 대화생성 성능을 향상
- RLPF를 통해 추천시스템 데이터셋에 맞게 fine-tuning 하여 성능 개선
DISCUSSION
Key Findings
- 모호한 대화형 추천시스템을 4가지 sub-task로 구분한다는 점에서 모듈화의 장점을 얻을 수 있음
Prompt engineering,sota expert model두가지 기술이 해당 성능을 좌지우지할 것을 예상- template을 제공하고 있고 사용한 expert model이 있으므로 기술 도입에 큰 어려움이 없을 것으로 생각됨
Limitation
- LLM inference를 여러번 진행하여 답변을 생성하게 되는데 RLPF로 어느 부분의 policy gradient를 구해야하는지 정확히 안나와있음
- Model matching 부분은 Dynamic 을 위해서 LLM을 사용하는데 단순하게 sub-task와 model을 하나의 쌍으로 묶어서 사용하는게 더 좋아보임
APPENDIX
Policy Gradient
- object function에 대한 policy (LLM)의 gradient를 구하는 과정
- 논문에서 나오는 policy gradient 유도

REINFORCE
- Monte-Carlo Policy Gradient
- policy gradient 이론에서 사용하는 action-value function을 return으로 변경
- return: discount reward 총합
KBRD
- 2019년도 paper에서 제안한 framework
- 대화에서 enttity를 추출하여 지식그래프를 통해 관련 항목을 추천 → 대화 기반 추천
- Transformer 모델을 활용해 사용자 선호도에 맞는 어휘 선택 → 추천 기반 대화
KGSF
- 2020년도 paper에서 제안
- 지식그래프를 통한 항목과 동의어등 단어 관계 기반을 합하여 상품 추천
TG-ReDial
- 2020년도 paper에서 제안
- 대화형 추천시스템

아이스 바닐라 라떼 좋아하는 ML Engineer 입니다.