
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 6일 기준으로 작성되었습니다.
Chapter 4
회의록을 정리하는 AI 서기
본 포스팅에서는 음성 파일을 분석해서 화자를 분리하는 기능을 구현해보겠습니다
1. 문장과 화자 구분하기
위스퍼AI는 음성을 잘 받아쓰지만 화자를 구분해 주지는 않는다
따라서 화자를 구분하는 기능을 추가하기 위해서는 허깅페이스에서 화자 분리 모델을 사용해서 구현해야 한다
화자를 구분하는 기능은 pyannote.audio를 이용해 개발할 수 있다
pyannote.audio는 화자를 분리하는 오픈소스 툴킷으로 파이토치 머신러닝 프레임워크에서 동작한다
이 모델을 사용하려면 토큰을 발급받아야 한다
허깅페이스에 로그인 한 뒤 프로필 로고를 클릭해 [Settings]를 클릭한다
이동한 페이지에서 [Access Token]을 클릭하고 [+Create new token]을 이용해 토큰을 발급받는다
이후 허깅페이스 홈페이지에서 'speaker-diarization'을 검색하고 pyannote의 speaker-diarization-3.1 모델을 선택한다
모델을 사용하려면 소속 기관과 웹 사이트 정보를 입력해야 하는데 대충 입력해주도록 하자
정보를 입력한 후에 아래의 Agree and access repository 버튼을 누른다
또한 아래의 Requirements를 잘 읽고 순서대로 진행하면 된다
speaker_diarization.ipynb 파일을 생성 후 필요한 패키지를 다운로드 해보자
%pip install pyannote.audio
%pip install numpy==1.26책에서 2025년 4월 기준으로 pyannote.audio는 numpy 1.x 버전에서 작동한다고 한다
그래서 책과 똑같이 numpy 1.26 버전을 사용하였다
모델 상세 페이지의 Usage 영역의 예제 코드를 참고해서 코드를 작성해보자

# instantiate the pipeline
from pyannote.audio import Pipeline
import torch
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.1",
token='(발급받은 토큰)')
if torch.cuda.is_available():
pipeline.to(torch.device("cuda"))
print('cuda is available')
else:
print('cuda is not available')
코드를 작성했으니 이제 사용할 음성파일을 마련해야 한다
음성 파일은 책에 설명해놓은 파일을 그대로 사용하려고 한다
MP3 파일 받기
해당 링크에서 싼기타_비싼기타.mp3 파일을 다운로드하자
위의 코드에서 선언한 pipeline을 이용해서 MP3 파일을 화자 분리 객체 diarization으로 만들고 그 결과를 RTTM 파일로 저장해보자
- 책과의 차이점
- MP3을 사용하다보니 오류가 발생하는 것 같아서 wav 파일로 변경
- pyannote 입력 포맷으로 직접 변환
- diarazation.write_rttm에서 오류가 나서 diarization.speaker_diarization.write_rttm으로 변경
# ✅ torchcodec 대신 torchaudio로 파일을 직접 로드
wav_path = "./audio/싼기타_비싼기타.wav"
waveform, sample_rate = torchaudio.load(wav_path)
# pyannote 입력 포맷
audio = {"waveform": waveform, "sample_rate": sample_rate}
diarization = pipeline(audio)
with open("./audio/싼기타_비싼기타.rttm", "w", encoding="utf-8") as f:
diarization.speaker_diarization.write_rttm(f)에러 (1)
하지만 코드를 실행시키는 도중에 다음과 같은 오류메세지가 발생했다NameError: name 'AudioDecoder' is not definedpyannote-audio의 요구 조건은 아래와 같은데 내가 설치한 torch 버전이 2.9여서 문제가 발생했다
pyannote-audio 4.0.3 requires torch==2.8.0 pyannote-audio 4.0.3 requires torchaudio==2.8.0 pyannote-audio 4.0.3 requires torchcodec==0.7.0
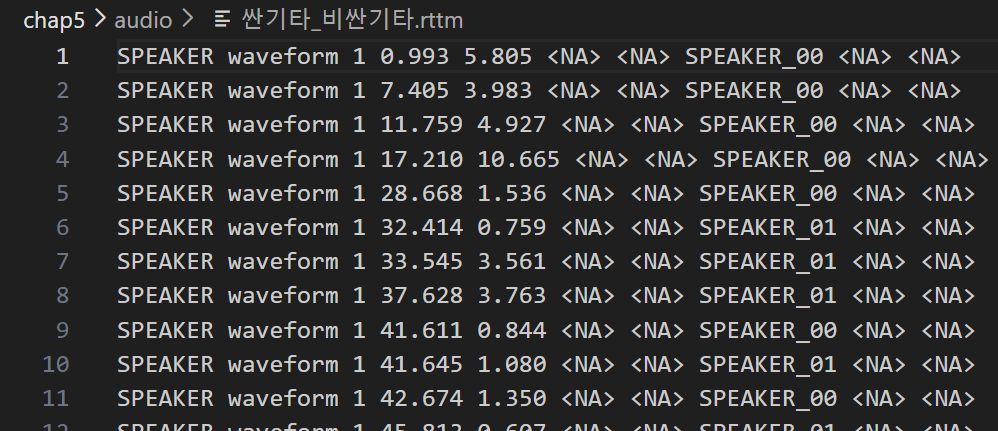
코드를 실행한 결과 rrm 파일이 생성된 것을 알 수 있다
파일에서 발화 시작시각, 지속 시각을 알 수 있고 화자가 SPEAKER_00, SPEAKER_01로 구분되어있다
위의 사진에서 확인할 수 있듯 화자 분리는 잘 되었지만 같은 화자의 발언이 분리되는 문제가 발생한다
이렇게 화자가 변하지 않을 때에는 하나로 합쳐보도록 하자
2. 판다스 데이터프레임 형태로 저장하기
위의 결과를 보면 rttm 파일이 총 10개의 정보 항목이 존재한다는 것을 알 수 있다
따라서 판다스의 .read_csv 팜수를 이용해서 RTTM 파일을 판다스의 데이터프레임 형태로 저장하려 한다
아래 코드를 이용해서 정보를 저장했다
import pandas as pd
rttm_path = "./audio/싼기타_비싼기타.rttm"
df_rttm = pd.read_csv(
rttm_path,
sep= ' ',
header= None,
names= ['type', 'file', 'channel', 'start', 'duration', 'C1', 'C2', 'speaker_id', 'C3', 'C4']
)
display(df_rttm)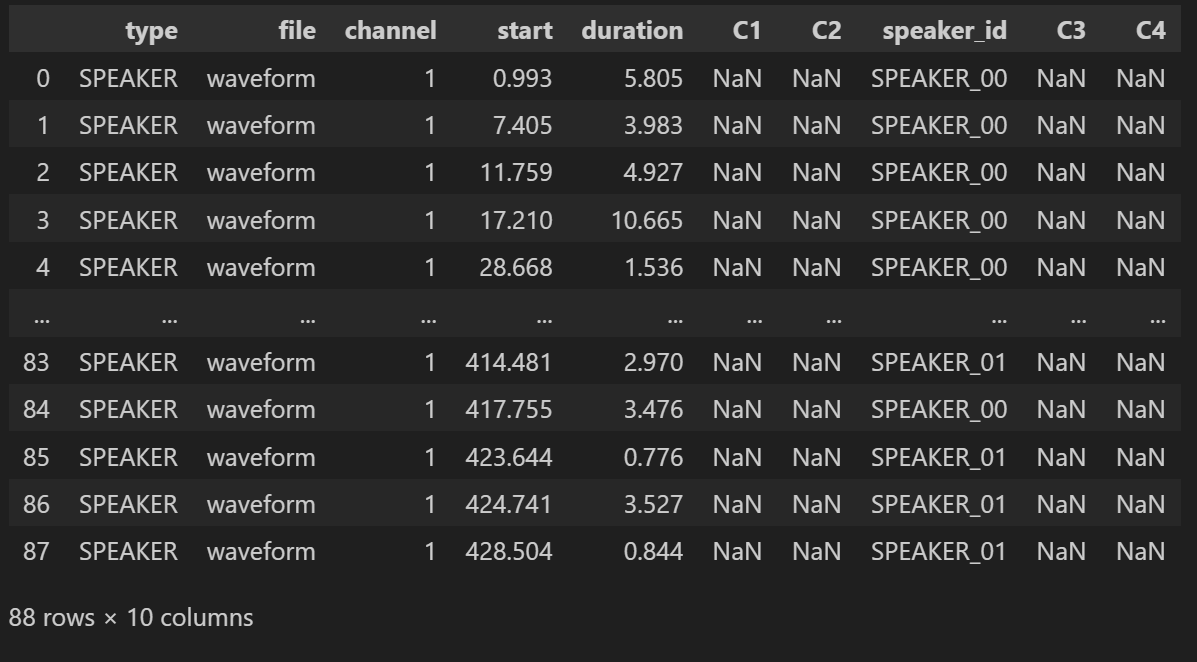
이렇게 하면 결과를 조금 더 보기 쉽게 확인할 수 있다
출력된 내용에는 발언이 시작한 시간인 start와 발언의 지속시간인 duration을 알 수 있으므로 이를 이용해서 발언 종료시점을 알 수 있다
화자의 발언이 종료된 시점을 계산하고 이를 df_rttm에 추가해보도록 하자
# start + duration = end 로 반환
df_rttm['end'] = df_rttm['start'] + df_rttm['duration']
display(df_rttm)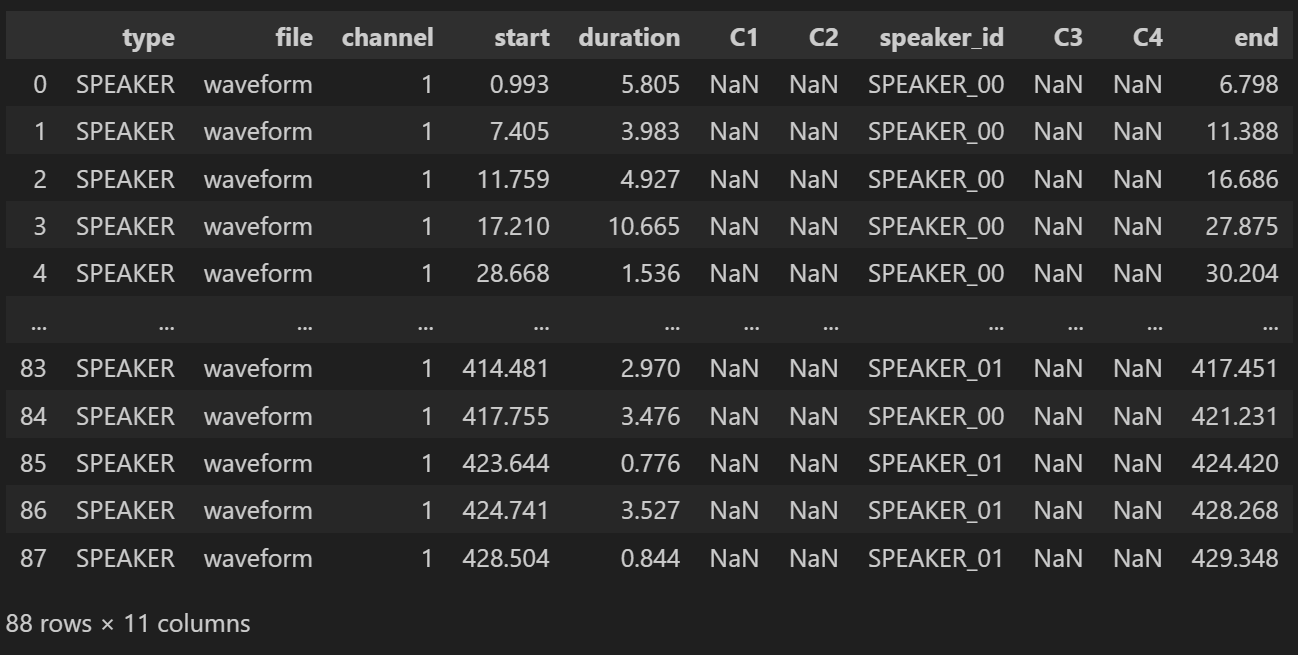
df_rttm의 맨 마지막 열에 end 칼럼이 추가된 것을 확인할 수 있다
화자를 구분하고 발언 순서를 기록하기 위해 화자가 바뀔 때마다 번호를 부여해보도록 하자
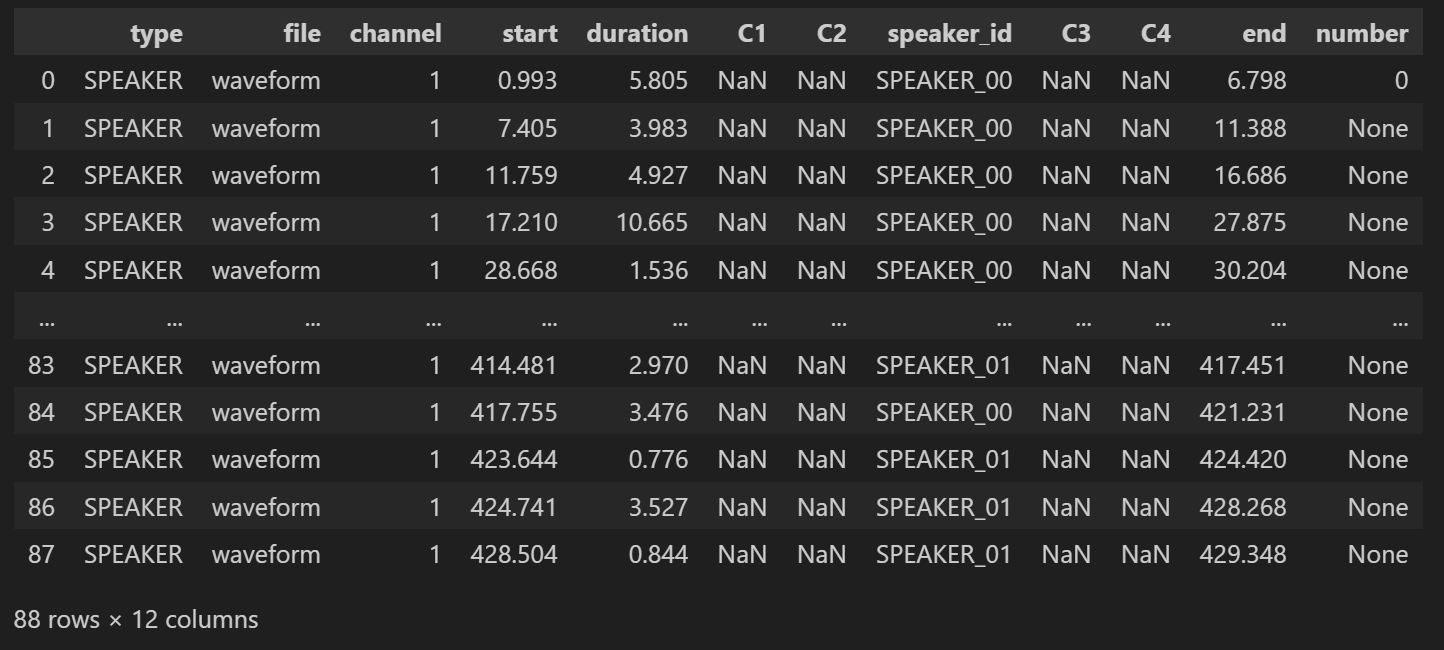
df_rttm["number"] = None
df_rttm.at[0, "number"] = 0
display(df_rttm)발언 번호인 number 열을 만들고 None 으로 초기화한다
그리고 첫번째 행만 0으로 지정한다
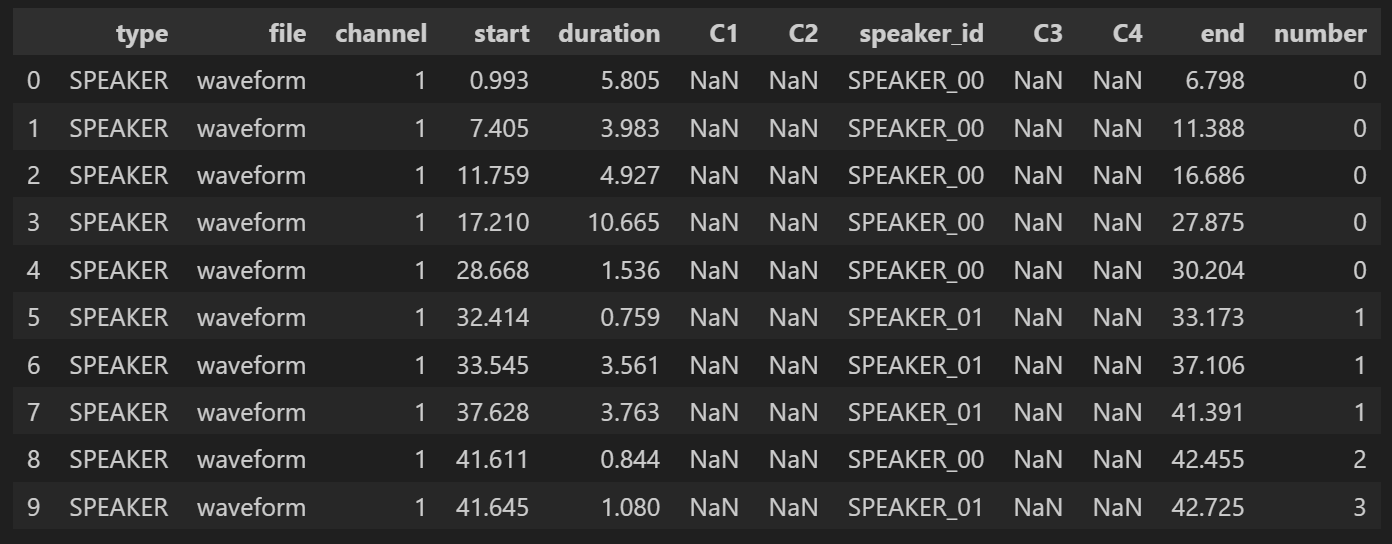
for i in range(1, len(df_rttm)):
if df_rttm.at[i, "speaker_id"] != df_rttm.at[i-1, "speaker_id"]:
df_rttm.at[i, "number"] = df_rttm.at[i-1, "number"] + 1
else:
df_rttm.at[i, "number"] = df_rttm.at[i-1, "number"]
display(df_rttm.head(10))speaker_id 가 다른 경우에 number에 1을 더하고 그렇지 않으면 유지한다
이제 마지막으로 같은 화자끼리 묶어서 dr_rttm_grouped에 저장해보도록하자
df_rttm_grouped = df_rttm.groupby("number").agg(
start = pd.NamedAgg(column="start", aggfunc="min"),
end = pd.NamedAgg(column="end", aggfunc="max"),
speaker_id = pd.NamedAgg(column="speaker_id", aggfunc="first")
)
display(df_rttm_grouped)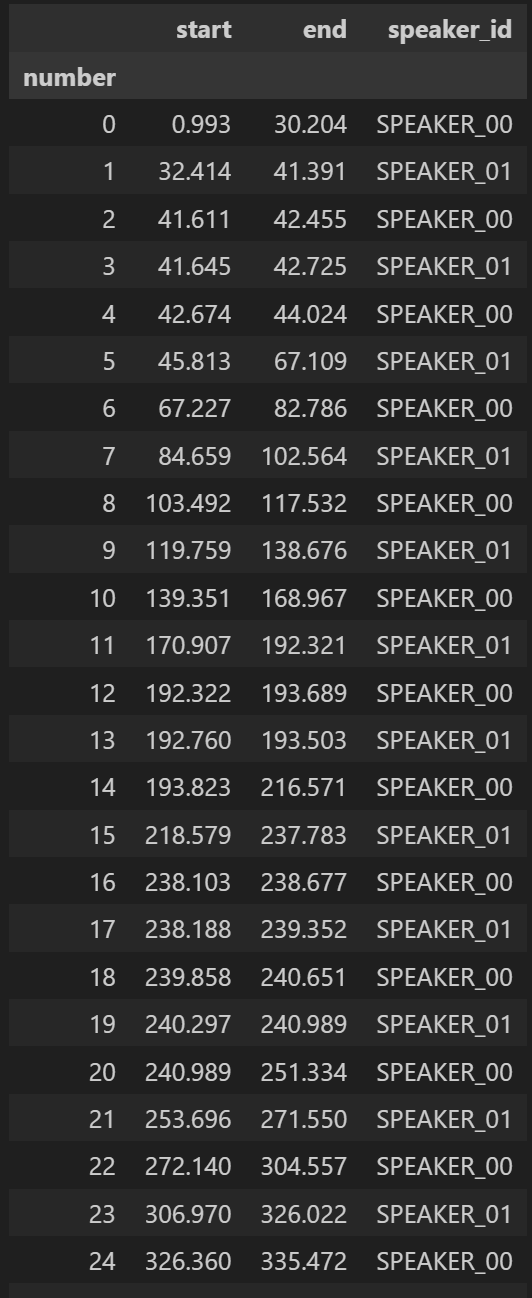
화자별 발화시간을 구하고 인덱스를 제거해보자 end 에서 start를 빼서 duration을 구할 수 있다
그리고 .reset_index를 이용해서 인덱스를 제거한다
df_rttm_grouped["duration"] = df_rttm_grouped["end"] - df_rttm_grouped["start"]
df_rttm_grouped = df_rttm_grouped.reset_index(drop=True)
display(df_rttm_grouped)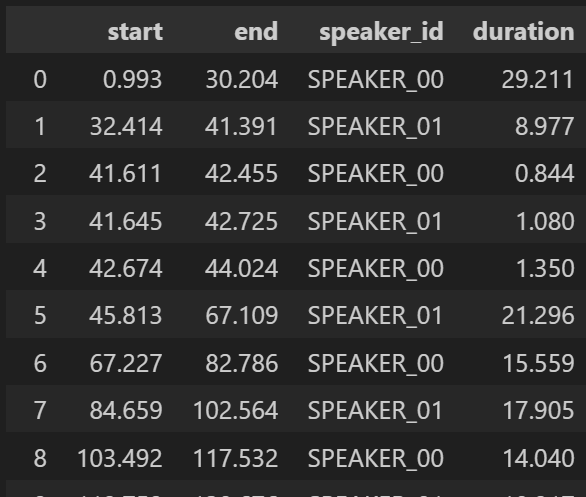
이제 이 파일을 csv 파일로 저장하면 끝!!
df_rttm_grouped.to_csv("./audio/싼기타_비싼기타_rttm.csv", sep = ' ',index=False)3. 마무리
생각보다 오래 걸려서 다음 내용은 나중에 작성하려 한다
기본적으로 허깅페이스를 사용할 때, 모델이 요구하는 버전이 있고 그 버전이 내가 이미 설치해놓은 버전과 맞지 않는 경우에 문제가 발생한다
일단 아무생각없이 따라하기 보다는 한번쯤 요구사항을 찾아보고 지금 내 버전과 맞는지 확인하는 습관이 필요할 것 같다
그리고 화자를 분리하는 코드에서 책과 다르게 진행하면서 실제 결과도 책과 다르게 나오고 있는데 이 부분에 대해서는 어쩔 수 없는 것 같다.....
