
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 8일 기준으로 작성되었습니다.
Chapter 4
회의록을 정리하는 AI 서기
본 포스팅에서는 지난 포스팅에 이어서 회의록을 요약하는 코드를 작성해보겠습니다
Chatper 4의 마지막 포스팅입니다!!
1. 전체 회의 내용 요약하기
이전 포스트에서 만든 CSV 파일에서 화자의 이름을 넣고 GPT에게 회의 내용을 요약해보도록 해보겠습니다
# summarize_and_correct.ipynb
import pandas as pd
meeting_note_csv_path = "./audio/싼기타_비싼기타_final.csv"
df_rttm = pd.read_csv(meeting_note_csv_path, sep="|")
display(df_rttm)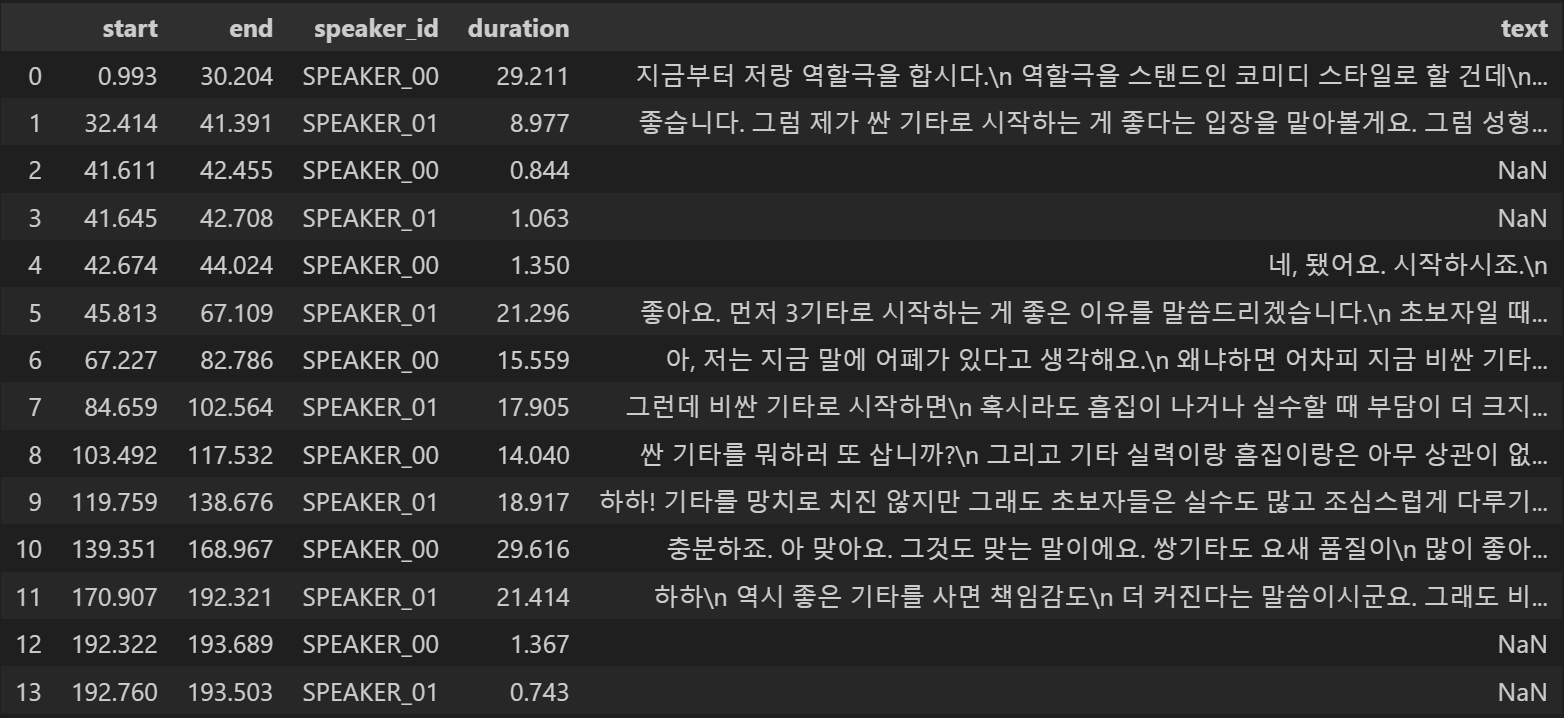
이 상황에서 SPEAKER_00 에는 책의 저자인 "이성용"의 이름을, SPEAKER_01 에는 AI를 넣어서 데이터프레임의 새로운 열을 만들어 추가해보도록 하자
# 이름 넣기
name_dict = {
"SPEAKER_00" : "이성용",
"SPEAKER_01" : "AI"
}
df_rttm["name"] = df_rttm["speaker_id"].apply(lambda x : name_dict[x])
display(df_rttm)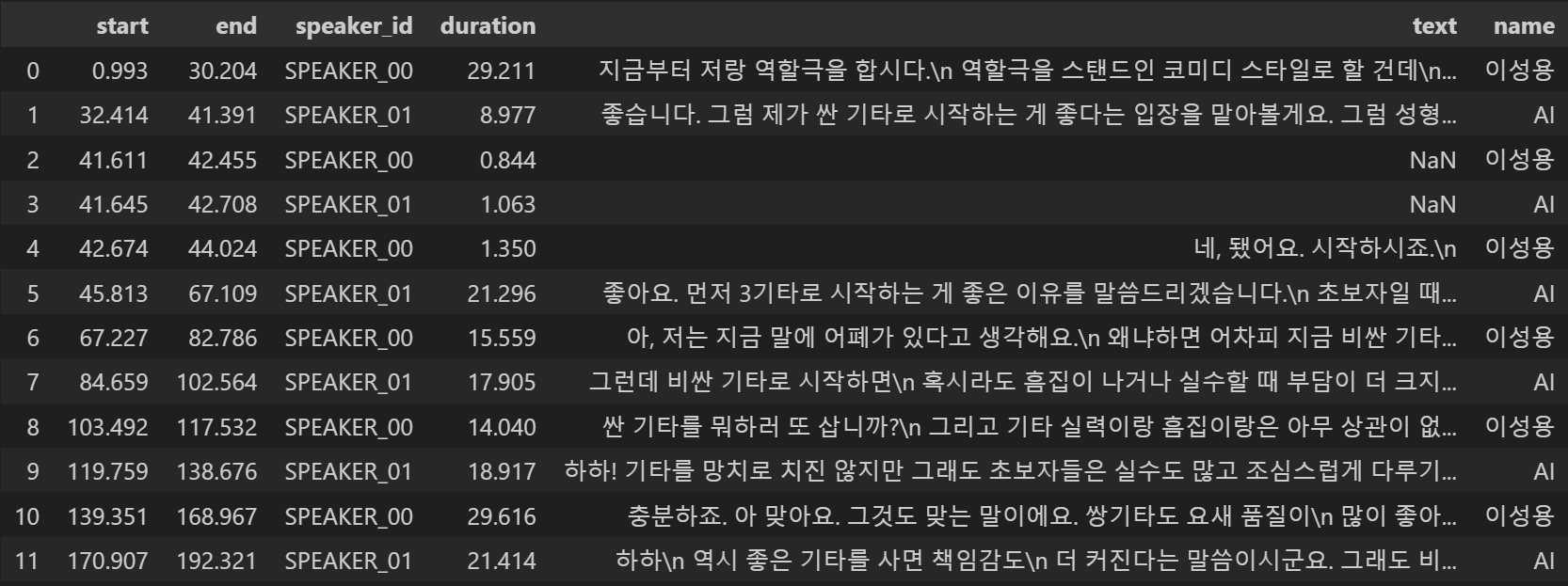
화자의 이름이 들어간 열을 추가하였다
text 열을 보면 중간중간에 값이 NaN 으로 채워진 구간들이 있다
이 부분은 대사가 없는 구간이므로 회의를 요약하는데에 필요하지 않다
text의 값이 NaN인 행을 삭제해보도록 하자
df_rttm = df_rttm.dropna(subset=["text"])
display(df_rttm)
회의를 요약할때 필요하지 않은 항목도 있으므로 df_rttm에서 필요한 정보만 추출해보도록 하자
start, end, name, text 항목만 선택하고 이를 JSON 형식으로 변환하자
이렇게 변환한 텍스트는 나중에 프롬프트에 추가해서 GPT에게 회의 내용을 요약하는데 사용할 수 있다
meeting_note_text = df_rttm[['start', 'end', 'name', 'text']].to_json(orient='records', force_ascii=False)
print(meeting_note_text)이 결과로 나온 JSON 파일을 GPT의 프롬프트에 추가하면 된다
그 전에 GPT에 넣을 시스템 프롬프트를 아래와 같이 작성하자
system_prompt = f'''
너는 회의 내용을 요약하는 봇이야
아래 회의록을 읽고, 주요 내ㅔ용을 요약해
결과는 마크다운 형식으로 작성해
정리해야 하는 형식은 아래와 같아
# 회의 제목
## 주요 내용
## 참석자별 입장
## 결정사항
=========== 이하 회의록 ===========
{meeting_note_text}이제 예전처럼 GPT를 호출해서 prompt에 위에서 만든 시스템 프롬프트를 넣어주면 된다
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
# 오픈 AI API를 이용해 요약 결과 설정
response = client.chat.completions.create(
model = 'gpt-4o',
temperature = 0.1,
messages = [
{"role" : "system", "content" : system_prompt}
]
)
# 요약 결과를 파일로 저장
summary = response.choices[0].message.content
summary = summary.srtip() # 좌우 공백 제거
print(summary)
책에 수록된 결과와는 꽤나 다르지만 그래도 회의 내용을 요약해준 것을 확인할 수 있다
이제 이 파일을 마크다운 형식으로 저장하면 끝!!
저장된 내용은 위의 사진에서의 결과랑 똑같다
with open('audio/guitar_summary.md', 'w', encoding = 'utf-8') as f:
f.write(summary)2. GPT로 녹취록 교정하기
이렇게 음성 파일을 텍스트 파일로 변환한 후, 텍스트 파일을 요약하는 것 까지 진행해보았다
하지만 CSV 파일을 자세히 보면 음성을 잘못 받아 적은 내용이 보인다
화자의 발음이 불명확하거나 전문 용어, 사람 이름, 사건 이름 등이 포함되면 실시간으로 받아쓰기가 어려울 수 있다
따라서 이를 GPT를 이용해서 교정하고 완성된 회의록을 만들어보자
앞서 만들었던 STT 파일을 GPT를 이용해서 교정해보도록 하자
df_rttm에서 필요한 항목은 start, end, name, text이다
이 항목들만 복사해서 새로운 데이터프레임인 df_meeting_note에 넣어보자
이때 데이터프레임을 딕셔너리 형태로 변환해서 meeting_note_dict 변수에 저장한다
df_meeting_note = df_rttm[['start', 'end', 'name', 'text']].copy()
df_meeting_note.dropna(inplace= True)
meeting_note_dict = df_meeting_note.to_dict(orient = 'records')
meeting_note_dict
이제 이 녹취록에 기재된 메세지를 for문으로 확인하며 GPT에게 수정을 요구해보자
for row in meeting_note_dict:
# 텍스트가 아닌 다른 형식인 경우 통과
if not isinstance(row['text'], str):
continue
correction_system_prompt = f'''
너는 주어진 회의 녹취록을 수정 및 보완하는 봇이야
주어진 회의 녹취록은 STT로 작성된 겨로가이므로, 이 중에 오류가 있는 부분을 찾아내고 수정해
표현, 말투는 최대한 원본과 일치하도록 유지하되, 잘못 받아적은 내용을 수정할 것
원본의 내용을 최대한 살리되, 잘못된 내용만 수정해
어떤 경우에는 A라는 사람이 말한 내용을 B가 말한 것으로 잘못 기록된 경우도 있을 수 있다. 이런 경우에는 문맥을 고려해서 수정해
원본 내용 중 빠지거나, 추가되거나, 잘못 기록된 부분을 찾아내서 수정해
수정된 메세지 이외에는 아무것도 작성하지마
------------------------
회의 요약문 : {summary}
------------------------
회의 녹취록 전문 : {df_meeting_note.to_json(orient= 'records', force_ascii= False)}
------------------------
확인할 메세지 원본: {row['text']}
'''
response = client.chat.completions.create(
model = 'gpt-4o',
temperature = 0.1,
messages = [
{"role" : "system", "content" : correction_system_prompt}
]
)
correction = response.choices[0].message.content
# "수정: "과 같은 같은 형식으로 반환되는 경우 해결
if ':' in correction:
correction = correction.split(':')[-1]
correction = correction.strip() # 좌우 공백 제거
print("이름 : " + row['name'])
print("내용 : " + row['text'])
print("수정된 내용 : " + correction)
print('----------------------')
row['corrected_text'] = correction
위 코드에서 확인해야 할 내용은 다음과 같다
- if not isinstance(row['text'], str):
간혹 text에 빈 값이나 숫자가 들어갈 수 있으므로 isinstance를 사용해 문자열이 아닌 경우에는 통과시킨다
- correction_system_prompt
교정을 위한 요구사항을 자세히 작성한다
- 회의 녹취록 전문 : {df_meeting_note.to_json(orient= 'records', force_ascii= False)}
GPT가 회의 전문을 파악하고 맥락을 알 수 있게 한다
이때 회의 전문은 to_json을 이용해서 텍스트로 입력한다
- if ':' in correction:
correction = correction.split(':')[-1]
종종 GPT가 '수정 :' 의 형식으로 반환할 때가 있는데 그럴 대는 ':'를 기준으로 분할하고 뒷부분만 사용하도록 한다
- row['corrected_text'] = correction
GPT가 수정안을 제공하면 수정된 내용은 딕셔너리에서 'corrected_text'에 추가한다

결과를 보면 위와 같이 '성형님은' 이라고 잘못 받아적은 내용을 '성용님은'으로 올바르게 수정한 것을 알 수 있다
이렇게 만든 meeting_note_dict를 JSON 파일 형식으로 저장하자
import json
with open('audio/guitar_meeting_note_corrected.json', 'w', encoding = 'utf-8') as f:
json.dump(meeting_note_dict, f, ensure_ascii=False, indent = 4)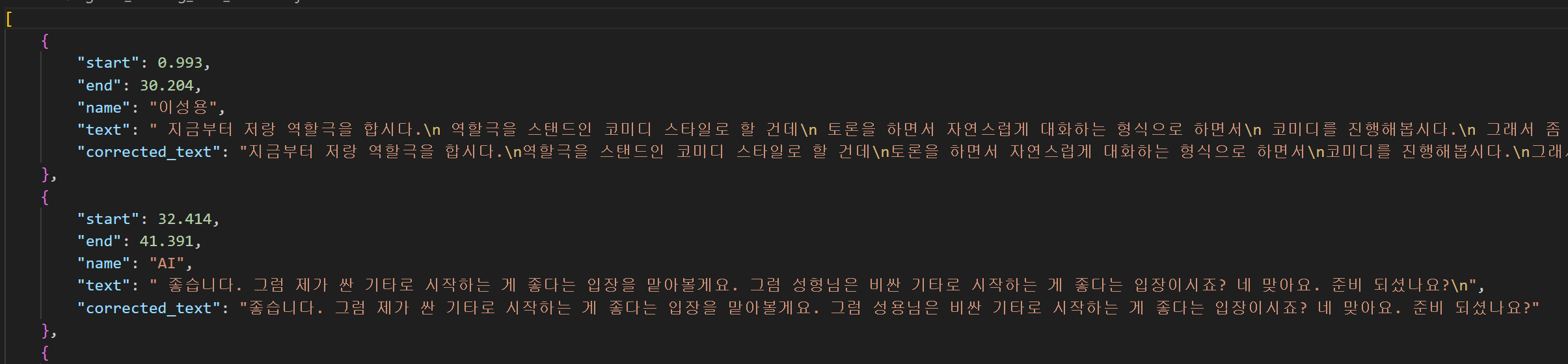
사진과 같이 올바르게 JSON 형식으로 저장된 것을 확인할 수 있다
3. MS 워드 파일로 출력하기
마지막으로 GPT로 교정한 guitar_meeting_note_corrected.json 파일을 마크다운 형식과 MS 워드파일로 출력해보도록 하자
아래 코드를 이용해서 guitar_meeting_note_corrected.json 파일을 마크다운 형식으로 저장할 수 있다
회의록의 화자 이름과 발언을 마크다운 리스트 항목으로 변환해서 하나의 문자열로 결합한다
md_template = ""
for row in meeting_note_dict:
md_template += f"- **{row['name']}** : {row['corrected_text']}\n"
with open('audio/guitar_meeting_note_corrected.md','w', encoding = 'utf-8') as f:
f.write(md_template)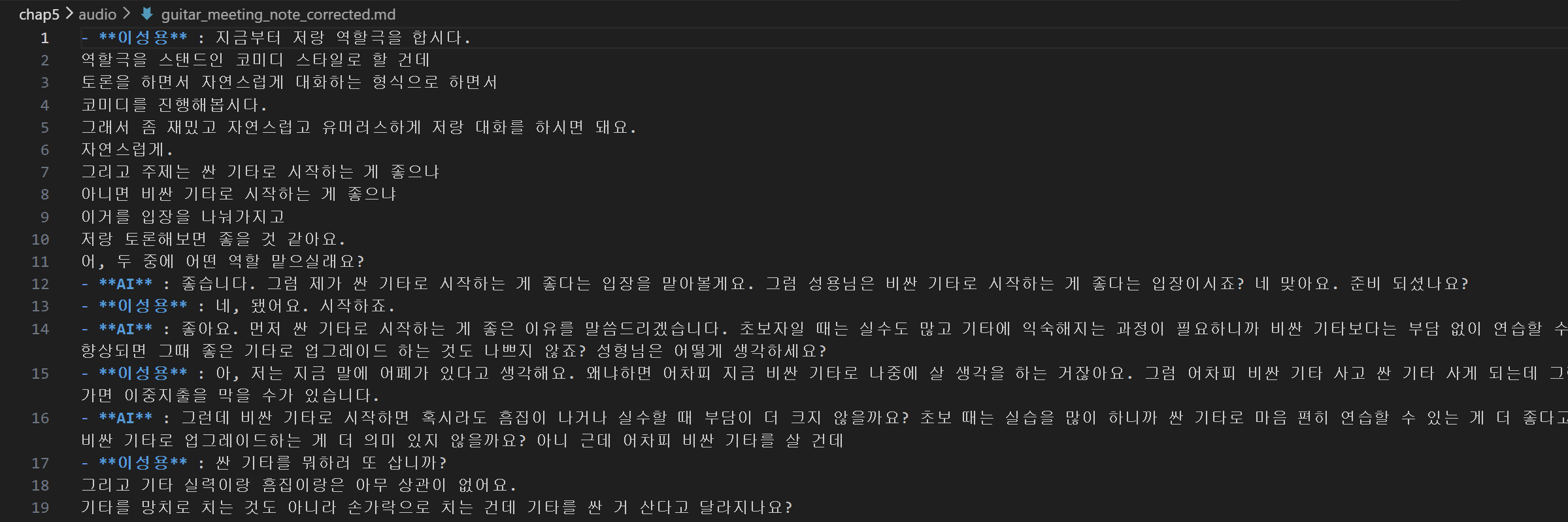
위와 같이 마크다운 형식으로 잘 저장된 것을 볼 수 있다
이번엔 MS 워드로 출력해보자
파이썬에서 MS 워드를 출력하려면 python-docx라는 패키지를 사용해야한다
아래 코드를 이용해서 python-docx를 설치하자
%pip install python-docx이제 python-docx를 이용해서 MS 워드에 저장해보자
meeting_note_dict의 내용을 for문으로 순회하면서 첫 번째 열에는 화자 이름, 두 번째 열에는 수정한 내용을 넣는다
from docx import Document
document = Document() # docx 객체 생성
document.add_heading('회의록', level = 1) # 제목 추가
table = document.add_table(rows = 1, cols = 2) # 테이블 생성
table.style = 'Table Grid' # 테이블 스타일 지정
hdr_cells = table.rows[0].cells # 첫 번째 행에 셀 추가
hdr_cells[0].text = 'Speaker' # 첫 번째 셀에 Spaeker 추가
hdr_cells[1].text = 'Content' # 두 번째 셀에 Content 추가
# 수정된 녹취록 파일을 읽어 들여서 테이블에 추가
for row in meeting_note_dict:
row_cells = table.add_row().cells
row_cells[0].text = row['name']
row_cells[1].text = row['corrected_text']
document.save('audio/guitar_meeting_note_corrected.docx')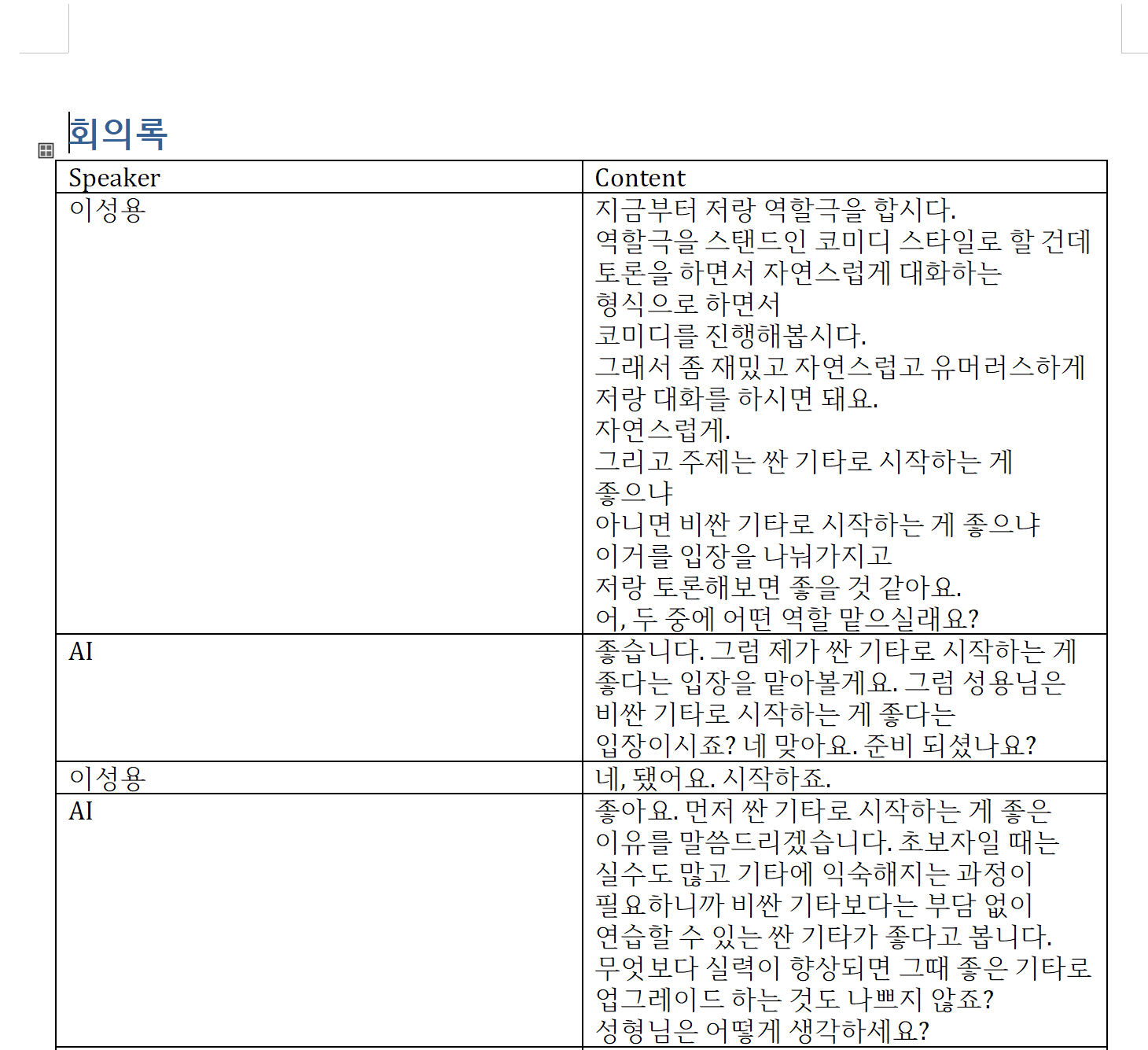
생성된 워드 파일을 보면 사진과 같이 정리된 것을 볼 수 있다
4. 마무리
이렇게 음성 파일을 이용해서 GPT와 놀아보는 시간이 끝났다
개인적으로 pyannote를 이용하고 허깅페이스를 이용하면서 모델을 설치할 때 오류가 많이 발생하였고
이 오류를 해결하는데 많은 시간이 걸렸다 (물론 코드를 수정하는데에서는 GPT의 도움을 받았다)
다음 챕터는 AI를 이용해서 이미지 분석을 해보는 챕터이다
개인적으로 음성파일보다는 다루기 쉽지 않을까 라는 생각이 든다
대학에서 전공 수업으로 '디지털 영상 처리' 와 '데이터 압축' 과목을 수강하면서 이미지 파일과 동영상 파일을 처리하는 방식에 대해서 흥미를 가지게 되었는데, 물론 이번 챕터에서는 그런 부분을 다루지는 않겠지만 괜히 기대가 된다
