
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 9일 기준으로 작성되었습니다.
Chapter 5
AI 이미지 분석가
본 포스팅에서는 AI를 이용해서 이미지를 분석해봅니다
Chapter 5의 첫 포스팅입니다!!
1. 인터넷에 있는 이미지 설명 요청하기
GPT 에게 인터넷에 올라와있는 이미지를 설명해달라고 요청해 보도록 하자
저작권 문제가 없은 언스플래쉬에서 이미지 URL을 가져와 사용해보겠다

아래 코드에서는 위의 사진을 설명해달라고 요청하였다
# image_explanation.ipynb
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
# 오픈 AI API를 이용해 요약 결과 설정
messages = [
{"role" : "user",
"content" : [
{"type" : "text", "text": "이 이미지에 대해 설명해줘"},
{
"type" : "image_url",
"image_url" : {
"url" : "https://images.unsplash.com/p
hoto-1761839258045-6ef373ab82a7?q=80&w=2670&auto=format&fit=crop&ixlib=
rb-4.1.0&ixid=M3wxMjA3fDF8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
}
}
]
}
]
response = client.chat.completions.create(
model = "gpt-4o",
messages = messages
)
response.choices[0].message.content이 코드를 실행시키면 아래와 같이 설명해주는 것을 볼 수 있다
'사진에는 들판에서 세 사람이 걷고 있는 모습이 담겨 있어요. \n\n-
왼쪽 인물은 흰색 탱크톱과 청바지를 입고 있으며, 머리를 두 갈래로 땋았습니다.\n-
가운데 인물은 줄무늬 티셔츠와 청 멜빵을 착용하고 있습니다.\n-
오른쪽 인물은 체크무늬 셔츠와 청바지를 입고 있습니다.\n\n
그들은 자연 환경 속에서 산책을 즐기고 있는 것처럼 보입니다. 배경에는 나무들이 우거져 있습니다.'위의 messages 에서 이전 코드와 달라진 점이 하나 있다
이전에는 messages를 작성할 때 content에 텍스트를 넣었지만, 이 코드에서는 텍스트와 함께 "type" : "image_url"을 넣은 것이다
이렇게 코드를 구성하면 GPT에서 인터넷 상의 URL을 이용해서 분석한다
하지만 꼭 이렇게 이미지를 인터넷에서 가져와야만 할까?
2. 내가 가진 이미지로 설명 요청하기
만약 인터넷에 올라가 있는 사진이 아니라 내가 가지고 있는 사진으로 GPT에게 분석을 요구하려면 어떻게 해야할까?
이런 경우에는 Base64를 이용해 이미지를 문자열로 변환해야 한다
Base64를 이용하여 인코딩할 경우, 사람이 직접 읽기는 편하지 않지만 텍스트로 표현될 수 있는 형태가 되어 GPT에게 전달할 수 있다
- Base 64
이진(Binary) 데이터를 아스키 문자로 바꾸는 인코딩 방식
알파벳 대분자 (A-Z), 알파벳 소문자 (a-z), 특수문자를 이용해 데이터를 인코딩한다
장점 1. 전송 및 저장시 호환성이 좋다
장점 2. 데이터 손상 방지
장점 3. 프로토콜과의 호환성
분석해야 할 이미지로는 책의 예제에서 사용하고 있는 동일한 이미지를 사용하려 한다
해당 링크를 클릭해서 다운로드 받아서 사용해보자

import base64
# 이미지를 인코딩하는 함수
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
image_path = "./data/mangwon_bakery.jpg"
# 이미지를 base64로 인코딩
base64_image = encode_image(image_path)
print(base64_image)위의 코드를 실행시키면 이미지가 긴 문자열의 형태로 변환된 결과를 확인할 수 있다
코드에서 확인해봐야 할 점은 다음과 같다
- with open(image_path, "rb") as image_file:
이미지 파일의 경로를 함수의 매개변수로 받아서 바이너리 모드(rb)로 열고 base64로 인코딩 해야 한다는 점이다
그리고 이 데이터를 텍스트로 변환 후 utf-8로 디코딩한다후 utf-8로 디코딩한다
이제 base64로 인코딩된 이미지를 데이터 URL 형식으로 구성해서 GPT에게 전달할 수 있다
messages = [
{"role" : "user",
"content" : [
{"type" : "text", "text": "이 이미지에 대해 설명해줘"},
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
response = client.chat.completions.create(
model = "gpt-4o",
messages = messages
)
response.choices[0].message.content'이 이미지는 빵집의 진열대를 보여주고 있습니다.
다양한 종류의 빵들이 진열되어 있으며, 각 빵에는 가격과 이름이 적힌 작은 표가 있습니다.
진열되어 있는 빵은 머핀, 바게트, 크로와상과 같은 종류로 보입니다.
뒷쪽에는 직원들이 모자를 쓰고 작업 중인 모습도 보입니다.
가게는 깔끔하고 정리된 분위기입니다.'사진을 적절하게 설명하고 있는 것을 볼 수 있다!!
3. 여러 이미지 비교 분석 요청하기
한 번에 여러 이미지를 보내고 그 이미지들도 설명해달라고 할 수 있을까?
messages의 내용을 수정한다면 충분히 가능하다!!
사진은 책의 예제에서 사용하는 것과 같이 아래의 두 장을 사용하려고 한다
마찬가지로 링크에서 다운로드 받을 수 있다
<테라로사 선릉점>

링크 <테라로사 홍대서교점>

seolleung_terrarosa_base64 = encode_image("./data/seolleung_terrarosa.jpg")
local_stitch_terrarose_base64 = encode_image("./data/local_stitch_terrarosa.jpg")
messages = [
{"role" : "user",
"content" : [
{"type" : "text", "text": "두 카페의 차이점에 대해 설명해줘"},
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/jpeg;base64,{seolleung_terrarosa_base64}"
}
} ,
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/jpeg;base64,{local_stitch_terrarose_base64}"
}
} ,
]
}
]
response = client.chat.completions.create(
model = "gpt-4o",
messages = messages
)
response.choices[0].message.content'두 카페의 주요 차이점은 다음과 같습니다:\n\n1. **인테리어 스타일**:\n
- 첫 번째 카페는 어두운 톤의 우드 바닥과 천장을 사용하여 따뜻하고 아늑한 분위기를 자아냅니다.\n
- 두 번째 카페는 밝은 톤과 모던한 디자인을 특징으로 하며, 금속 재질의 오픈 키친과 화려한 노란색 벽이 돋보입니다.\n\n2.
**조명**:\n
- 첫 번째 카페는 조명이 차분하고 부드럽게 설계되어 있습니다.\n
- 두 번째 카페는 밝고 공간을 잘 밝히는 조명으로 구성되어 있습니다.\n\n3.
**좌석 배치**:\n
- 첫 번째 카페는 널찍한 테이블과 함께 여유로운 사이 공간을 제공하여, 편안하고 비공식적인 대화를 나누기에 좋습니다.\n
- 두 번째 카페는 더 컴팩트하게 좌석을 배치하여, 서로 가깝게 앉을 수 있는 구조입니다.\n\n4.
**탁 트인 느낌**:\n
- 첫 번째 카페는 넓고 트인 느낌을 주며, 커다란 창문으로 자연광을 많이 받습니다.\n
- 두 번째 카페도 큰 창문이 있지만, 실내 인테리어가 더 가득 차있어 조금 더 반듯한 느낌을 줍니다.\n\n
각 카페는 다른 분위기와 디자인을 제공하여 다양한 취향에 맞는 경험을 제공합니다.'세 가지 항목에 대해서 알아서 잘 비교해주는 것을 볼 수 있다
4. GPT 비전의 한계 알아보기
그러면 GPT는 언제나 완벽할까?? 정답은 "그렇지 않다" 이다
따라서 정확성을 요구하는 작업에서 GPT를 활용할 대에는 주의해야 한다
예를 들어 그래프 이미지를 설명해달라고 요청하는 경우, 성공적으로 설명해주는 경우가 있고 아닌 경우가 있다
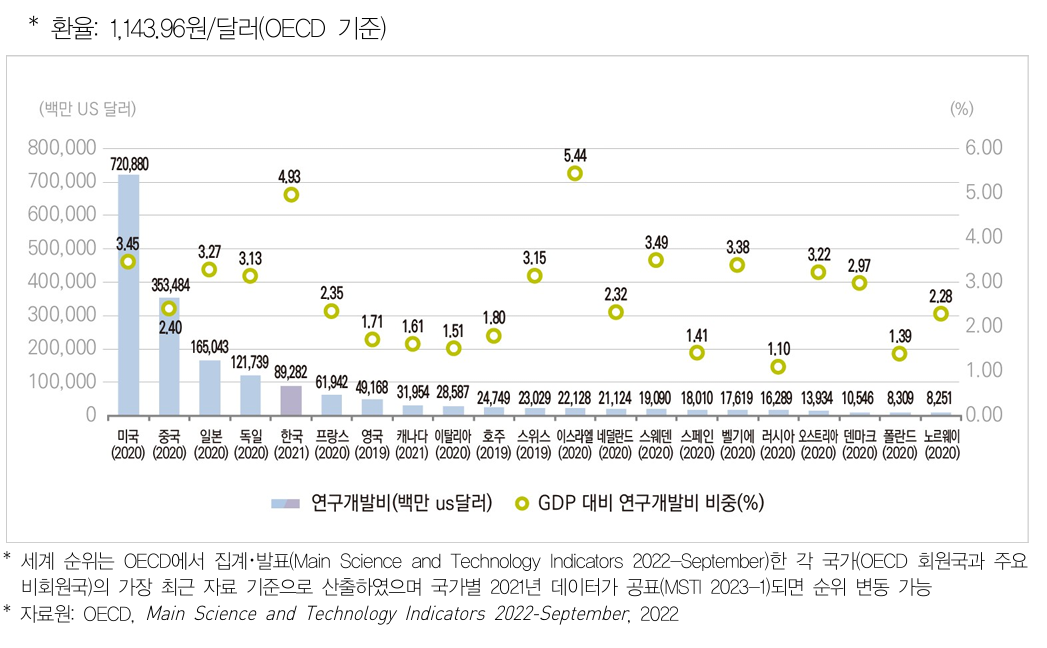
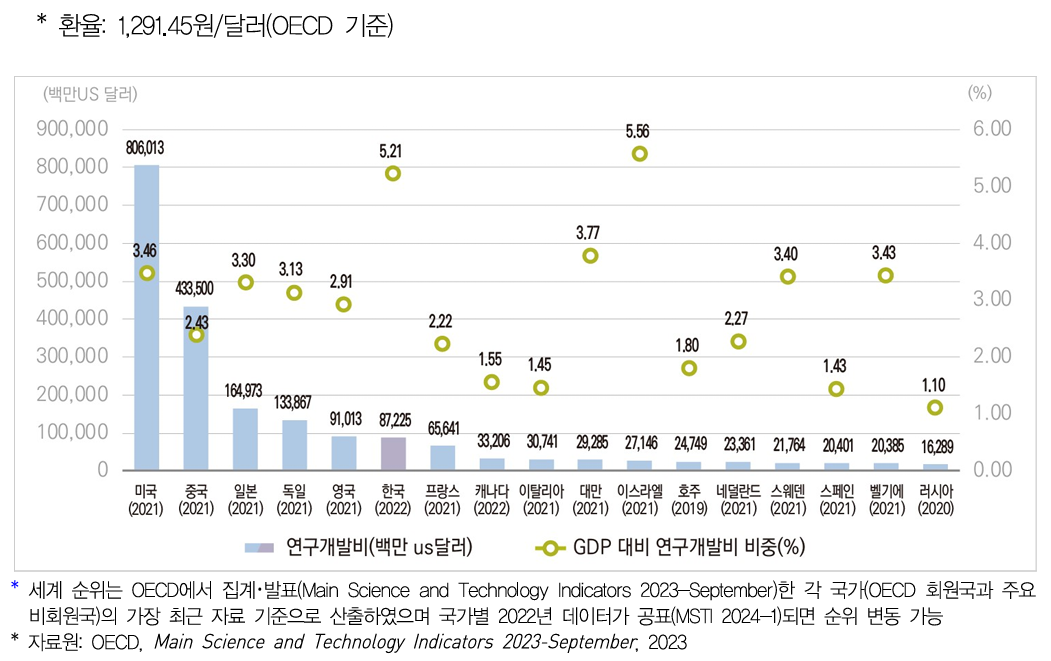
다음은 한국과학기술기획평가원에서 발간하는 보고서에 수록된 그래프이다
아래 그래프는 2021년과 2022년 OECD 가입국의 연구개발비를 비교한 내용을 담았다
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
우선 GPT에게 위의 두 사진을 비교해달라고 요청하자
이전에 사용하던 코드와 거의 비슷하다!!
oecd_rnd_2021_base64 = encode_image("./data/oecd_rnd_2021_large.png")
oecd_rnd_2022_base64 = encode_image("./data/oecd_rnd_2022_large.png")
messages = [
{"role" : "user",
"content" : [
{"type" : "text", "text": "첫 번째는 2021년 데이터이고, 두번재는 2022년 데이터이다.
이 데이터에 대해 설명해줘. 어떤 변화가 있었나 한국 중심으로 설명해"},
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/png;base64,{oecd_rnd_2021_base64}"
}
} ,
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/png;base64,{oecd_rnd_2022_base64}"
}
} ,
]
}
]
response = client.chat.completions.create(
model = "gpt-4o",
messages = messages
)
response.choices[0].message.content'2021년과 2022년 데이터를 비교하여 한국을 중심으로 한 변화를 설명해 드리겠습니다.\n\n###
2021년 데이터\n- *
*한국의 연구개발비**: 89,282백만 달러\n- **GDP 대비 연구개발비 비중**: 4.93%\n\n###
2022년 데이터\n-
**한국의 연구개발비**: 91,013백만 달러\n- **GDP 대비 연구개발비 비중**: 4.93%\n\n###
변화 분석\n1.
**연구개발비 증가**: 한국의 연구개발비는 2021년 89,282백만 달러에서 2022년 91,013백만 달러로 증가하였습니다.\n2.
**GDP 대비 비중 유지**: 2022년에도 GDP 대비 연구개발비 비중은 4.93%로 2021년과 동일하게 유지되었습니다.
\n\n이러한 변화는 한국이 지속적으로 연구개발에 투자하고 있음을 시사하며,
GDP 대비 비중이 높다는 것은 한국이 연구개발을 국가 경제의 중요한 요소로 보고 있다는 것을 의미합니다.
다른 나라들과 비교하면 한국이 연구개발에 상당한 비중을 두고 있음을 알 수 있습니다.'셀을 실행하면 위와 같은 결과가 출력된다. 꽤나 복잡한 그래프치고는 잘 이해한 것 같다
하지만 2022년 그래프에서 영국의 수치를 한국의 데이터로 착각한 사실을 볼 수 있다
2022년 한국의 값은 87,225백만 달러인데 91,013백만 달러로 인식하고 있다
이렇게 GPT가 복잡한 이미지를 인식하는 데에는 한계가 있으므로 주의해야 한다
이번에는 기존에 사용하던 파일보다 조금 해상도가 낮은 파일을 사용해보자
기존의 2021년 정보에서는 oecd_rnd_2021_large.png를 사용했지만 이번에는 oecd_rnd_2021_medium.png을 사용해보려한다
해당 파일은 그래프를 다운 받았던 링크에서 images 폴더에서 다운로드 받을 수 있다
oecd_rnd_2021_base64 = encode_image("./data/oecd_rnd_2021_medium.png")
oecd_rnd_2022_base64 = encode_image("./data/oecd_rnd_2022_large.png")
messages = [
{"role" : "user",
"content" : [
{"type" : "text", "text": "첫 번째는 2021년 데이터이고, 두번재는 2022년 데이터이다. 이 데이터에 대해 설명해줘. 어떤 변화가 있었나 한국 중심으로 설명해"},
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/png;base64,{oecd_rnd_2021_base64}"
}
} ,
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/png;base64,{oecd_rnd_2022_base64}"
}
} ,
]
}
]
response = client.chat.completions.create(
model = "gpt-4o",
messages = messages
)
response.choices[0].message.content'첫 번째 이미지와 두 번째 이미지는 연구개발비(R&D)와 GDP 대비 비율을 비교한 것입니다.
한국을 중심으로 설명해보겠습니다.\n\n
### 2021년 데이터\n- **한국의 연구개발비**: 915억 2천 8백만 USD\n- **GDP 대비 연구개발비 비중**: 5.44%\n\n
### 2022년 데이터\n- **한국의 연구개발비**: 872억 2천 5백만 USD\n- **GDP 대비 연구개발비 비중**: 4.93%\n\n
### 변화 및 분석\n1.
**연구개발비 총액의 감소**: 한국의 R&D 비용이 2021년 대비 2022년에 감소하였습니다. 이는 연구 투자 규모의 조정이 있음을 나타냅니다.\n \n2.
**GDP 대비 비중 하락**: 연구개발비가 전체 GDP에서 차지하는 비중이 줄어들었습니다.
이는 경제 규모가 성장하면서 상대적으로 연구개발에 대한 투자 비율이 낮아질 수 있음을 의미합니다.\n\n
이러한 변화는 경제 상황 변화, 우선순위 조정 등에 의해 발생할 수 있으며, 한국의 과학기술 및 산업 전략과 연관이 있을 수 있습니다.'이 결과는 이전보다 더 실망스러운 결과를 보여준다
일단 2021년 한국의 연구개발비는 대략 915억 USD 로 설명했는데, 2021년의 사진을 보면 해당 수치를 가진 국가는 존재하지 않는다
또한 GDP 대비 연구개발비 비중이라고 한 5.44%는 한ㄴ국의 값이 아니라 이스라엘의 값이다
이렇게 GPT를 이용한 이미지 인식 기능은 일반적인 이미지 분석에는 적절할 수 있지만 그래프와 CT 같은 고차원적인 목적에서는 적합하지 않다는 것을 보여준다
심지어는 동일한 이미지도 해상도에 따라서 결과가 완전 달라진다는 점에 대해서 주의해야 한다
5. 마무리
이번 포스팅을 작성하면서 사진을 직접 GPT에게 넘겨봤는데 개인적으로 추가적인 라이브러리를 설치하는 과정이 없어서
음성파일을 다루는 것 보다는 매우 수월하게 느껴졌다
다음 포스팅에서는 이미지를 활용해 퀴즈를 만드는 실습을 해보려한다
제목만 들어서는 토익스피킹에서 사진을 영어로 묘사하듯 말해야 하는 것과 비슷한 느낌인것 같은데
혹시나 내가 사진을 묘사하면 토익스피킹처럼 채점해주는 것도 만들 수 있지 않을까? 라는 생각이 들긴 한다
