
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 10일 기준으로 작성되었습니다.
Chapter 5
AI 이미지 분석가
본 포스팅에서는 이미지를 활용해서 퀴즈를 만드는 실습을 해보겠습니다
Chapter 5의 두 번째이자 마지막 포스팅입니다
1. 이미지를 활용해 퀴즈 만들기
이미지를 분석해 영어 듣기 평가 문제를 만들어보자!
문제를 영어도 만들면 결과를 확인하기 어려우니 일단 한국어로 만들어보자
이전 포스팅에서 사용한 image_explanation.ipynb 코드를 활용해보자
또한 for문으로 여러 이미지 파일의 경로를 가져오기 위해 파이썬 라이브러리 glob를 미리 임포트 한다
# image_quiz.py
from glob import glob #for 문으로 여러 파일의 경로를 가져오기 위해 선언
from openai import OpenAI
from dotenv import load_dotenv
import os
import base64
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key = api_key)
# image_explanation.ipynb 에서 가져온 함수
# 이미지 인코딩하는 함수
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 이미지 경로를 받아 퀴즈를 만드는 함수
def image_quiz(image_path):
base64_image = encode_image(image_path)
quiz_prompt = """
제공한 이미지를 바탕으로, 다음과 같은 양식으로 퀴즈를 만들어주세요.
정답은 (1) ~ (4) 중 하나만 해당하도록 출제하세요.
아래는 예시입니다.
---- 예시 ----
Q : 다음 이미지에 대한 설명 중 옳지 않은 것은 무엇인가요?
- (1) 베이커리에서 사람들이 빵은 사는 모습이 담겨있습니다.
- (2) 맨 앞에 서 있는 사람은 빨간색 셔츠를 입었습니다.
- (3) 기차를 타기 위해 줄을 서 있는 사람들이 있습니다.
- (4) 점원은 노란색 티셔츠를 입었습니다.
정답: (4) 점원은 노란색 티셔츠가 아닌 파란색 티셔츠를 입었습니다.
(주의 : 정답은 (1) ~ (4) 중 하나만 선택하도록 출제하세요)
=====
"""
messages = [
{"role" : "user",
"content" : [
{"type" : "text", "text": quiz_prompt},
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
response = client.chat.completions.create(
model = "gpt-4o",
messages = messages
)
return response.choices[0].message.content이 함수가 잘 작동하는지 확인해보자 원하는 이미지를 추가해서 테스트 할 수 있다
책에서 사용한 것과 동일한 사진을 사용해보려고 한다
사진은 링크에서 다운로드 받을 수 있다

{kind=link}
위의 코드에서 아래 두 줄을 추가해서 코드를 실행시켜보자
q = image_quiz("./chap6/data/busan_dive.jpg")
print(q)Q: 다음 이미지에 대한 설명 중 옳지 않은 것은 무엇인가요?
- (1) 많은 사람들이 노트북을 사용하고 있습니다.
- (2) 'DIVE 2024 IN BUSAN'이라는 문구가 보입니다.
- (3) 천장에 큰 샹들리에가 걸려 있습니다.
- (4) 행사장은 넓고 개방된 공간입니다.
정답: (3) 천장에 큰 샹들리에가 걸려 있지 않습니다.이렇게 문제가 적절하게 잘 출력된 것을 볼 수 있다. 이 정도면 문제 퀄리티도 그다지 나쁜 수준은 아닌듯 하다
이제 문제를 만들 이미지 파일들을 원하는 폴더(./data/images/)에 저장하고 for 문으로 반복해서 실행하면 된다
나는 이전 포스팅에서 사용했던 사진(빵, 카페 사진)들과 방금 사용한 사진까지 총 4장을 사용해보았다
txt = ''
no = 1
for g in glob("./chap6/data/images/*.jpg"):
try:
q = image_quiz(g)
except Exception as e:
print(e)
continue
divider = f'##문제 {no}\n\n'
print(divider)
txt += divider
filename = os.path.basename(g)
txt += f'\n\n'
# 문제 추가
print(q)
txt += q + '\n\n------------------\n\n'
with open ('./chap6/data/images/image_quiz.md','w', encoding = 'utf-8') as f:
f.write(txt)
no += 1 #문제 번호 증가위 코드에서 확인해야 할 부분은 다음과 같다
- for g in glob("./chap6/data/images/*.jpg"):
for문을 이용해서 ./data/images/ 폴더 내의 모든 jpg 파일들을 사용한다
- txt 에 내용 추가 하는 부분
마크다운 형식으로 결과를 보기 좋게 출력하는 코드
GPT가 출제한 문제 위에 이미지를 표시하기 위해 이미지 파일명만 추출해서 링크를 만들고 이를 txt 에 덧붙인다
이 코드를 실행시킨 결과를 한번 확인해보자
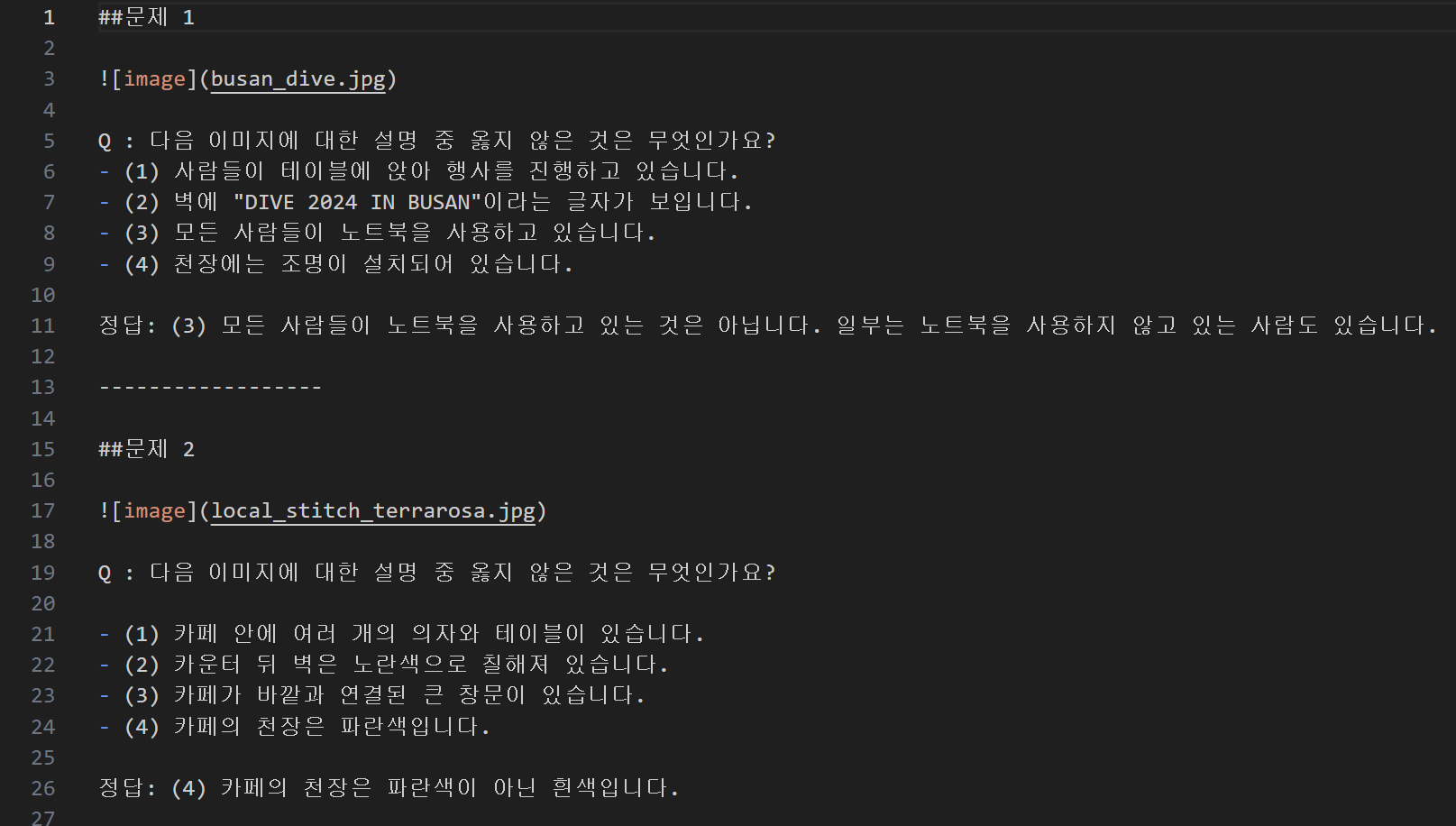
여러 사진 파일을 이용해서 한번에 문제를 만들어 내는 데에 성공했다!
2. 영어로 문제 출제하기
이제 원래 목적에 맞게 영어로 문제를 출제해보도록 하자
원래 만들었던 코드에서 image_quiz 함수를 수정해보도록 하자
# 수정된 image_quiz 함수
def image_quiz(image_path, n_trial = 0, max_trial = 3):
if n_trial >= max_trial: # 최대 시도 회수에 도달하면 포기
raise Exception("Failed to generate a quiz.")
base64_image = encode_image(image_path)
quiz_prompt = """
제공한 이미지를 바탕으로, 다음과 같은 양식으로 퀴즈를 만들어주세요.
정답은 (1) ~ (4) 중 하나만 해당하도록 출제하세요.
토익 리스닝 문제 스타일로 문제를 만들어주세요
아래는 예시입니다.
---- 예시 ----
Q : 다음 이미지에 대한 설명 중 옳지 않은 것은 무엇인가요?
- (1) 베이커리에서 사람들이 빵은 사는 모습이 담겨있습니다.
- (2) 맨 앞에 서 있는 사람은 빨간색 셔츠를 입었습니다.
- (3) 기차를 타기 위해 줄을 서 있는 사람들이 있습니다.
- (4) 점원은 노란색 티셔츠를 입었습니다.
Listening : Which of the following descriptions of the image is incorrect?
- (1) It shows people buying bread at a bakery.
- (2) The person standing at the front is wearing a red shrit.
- (3) There are people lining up to take a train.
- (4) The clerk is wearing a yellow T-shrt.
정답: (4) 점원은 노란색 티셔츠가 아닌 파란색 티셔츠를 입었습니다.
(주의 : 정답은 (1) ~ (4) 중 하나만 선택하도록 출제하세요)
=====
"""
messages = [
{"role" : "user",
"content" : [
{"type" : "text", "text": quiz_prompt},
{
"type" : "image_url",
"image_url" : {
"url" : f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
try:
response = client.chat.completions.create(
model = "gpt-4o",
messages = messages
)
except Exception as e:
print("failed\n" + e)
return image_quiz(image_path, n_trial + 1)
content = response.choices[0].message['content']
if "Listening:" in content:
return content, True
else:
return image_quiz(image_path, n_trial + 1)이 코드에서 확인해봐야할 부분은 다음과 같다
- def image_quiz(image_path, n_trial = 0, max_trial = 3):
시도 횟수와 최대 시도 횟수를 함수의 매개변수로 같이 전달한다
오픈 AI의 서버가 불안정하거나 부적절한 이미지 등의 여러 이유로 답변에 실패할 수 있기에 위와 같은 코드를 추가한다
- try & exception 구분
예외 처리를 위해 사용한다
시도가 성공할 경우 답변을 바로 반환하지만 실패한 경우 자기 자신 함수를 재호출하고 이때 시도 횟수를 더한 값을 넣는다
이렇게 함수를 수정한다면 호출하는 부분도 수정해야 한다
원래 image_quiz 함수를 호출할때 try & except 구문을 사용했는데 이제 함수 내에서 오류처리가 이루어지기 때문이다
그 대신 image_quiz 함수가 반환하는 두 개의 값 중 두 번째 값을 확인하여 만약 문제 생성에 실패하면 해당 문제는 건너뛰고 다음 문제로 넘어가도록 구성해보자
# 수정된 함수 호출 부분
txt = ''
no = 1
for g in glob("./chap6/data/images/*.jpg"):
q, is_suceed = image_quiz(g)
if not is_suceed:
continue
divider = f'##문제 {no}\n\n'
print(divider)
txt += divider
filename = os.path.basename(g)
txt += f'\n\n'
# 문제 추가
print(q)
txt += q + '\n\n------------------\n\n'
with open ('./chap6/data/images/image_quiz.md','w', encoding = 'utf-8') as f:
f.write(txt)
no += 1 #문제 번호 증가이제 다시 코드를 실행시켜서 영어로도 문제가 잘 출제되는지 확인해보자
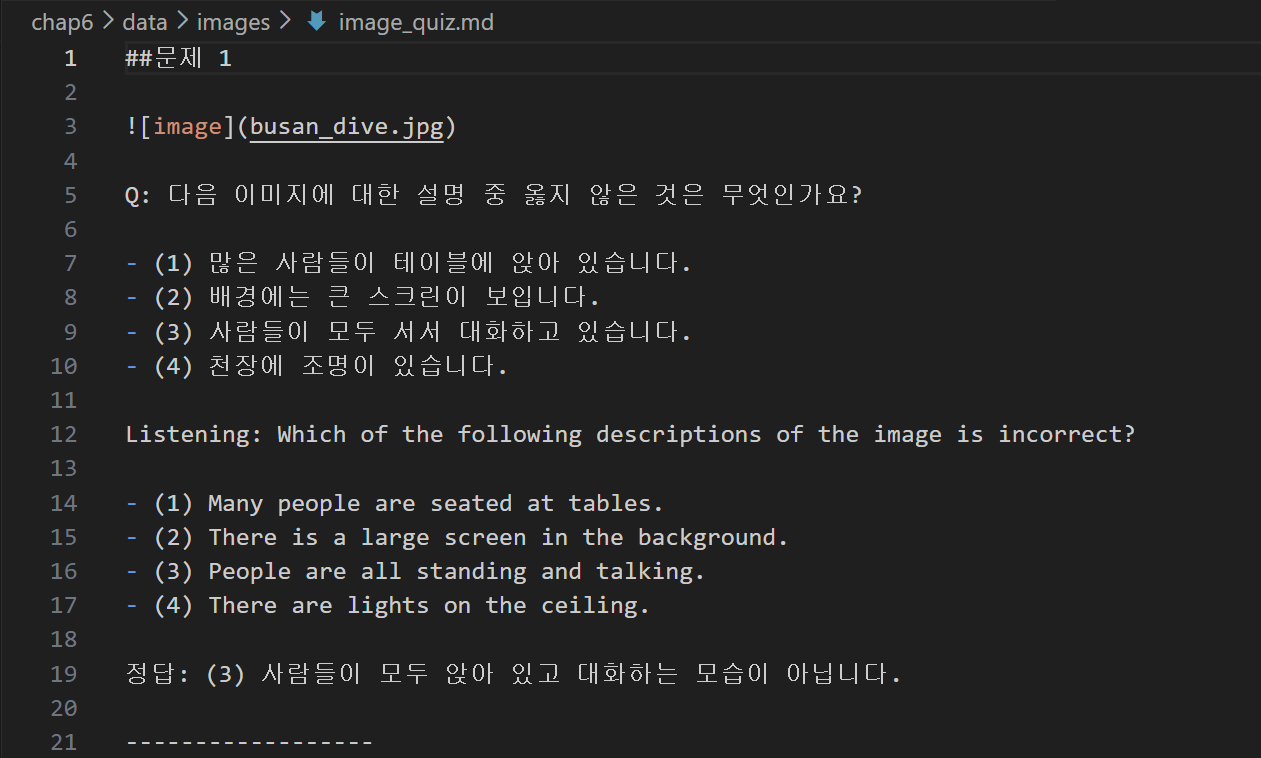
영어 문제까지 완벽하게 생성한 것을 볼 수 있다
3. TTS로 영어 듣기 평가 문제 만들기
이제 image_quiz.md 파일에 영어 시험 문제가 생겼다
문제를 읽는 MP3 음성 파일이 존재한다면 이를 뜨기 평가 문제로 활용할 수 있다
오픈 AI의 API에는 문장을 음성파일로 변환하는 TTS가 있으니 이 기능을 활용해보자
영어 문제 부분만 추출하기 위해 JSON 파일로 저장하는 기능을 추가한다
앞서 생성한 image_quiz.md 파일에서 영어 문제는 'Listening: ' 부터 '정답 : '사이에 작성되어 있는것을 볼 수 있다
따라서 이 부분만 추출하는 코드를 작성하자
이렇게 추출한 영어 문제는 eng 변수에 담고 문제 번호 no와 파일명 filename을 함게 딕셔너리 형태로 저장한다
그리고 이 딕셔너리를 eng_dict에 하나씩 추가한 수 각각 JSON 파일로 저장한다
기존 코드에서 변경해야 할 부분은 아래 코드로 확인해보자
import json # import 추가
txt = ''
no = 1
eng_dict = []
for g in glob("./chap6/data/images/*.jpg"):
q, is_suceed = image_quiz(g)
if not is_suceed:
continue
divider = f'##문제 {no}\n\n'
print(divider)
txt += divider
filename = os.path.basename(g)
txt += f'\n\n'
# 문제 추가
print(q)
txt += q + '\n\n------------------\n\n'
with open ('./chap6/data/images/image_quiz.md','w', encoding = 'utf-8') as f:
f.write(txt)
# 영어 문제만 추출
eng = q.split('Listening :')[1].split('정답:')[0].strip()
eng_dict.append({
'no' : no,
'eng' : eng,
'img' : filename
})
# JSON 파일로 저장
with open ('./chap6/data/images/image_quiz_eng.json','w', encoding = 'utf-8') as f:
json.dump(eng_dict, f, ensure_ascii = False, indent = 4)
no += 1 #문제 번호 증가이 코드를 실행하면 아래 사진과 같은 같은 image_quiz_eng.json 파일이 생성된 것을 볼 수 있다
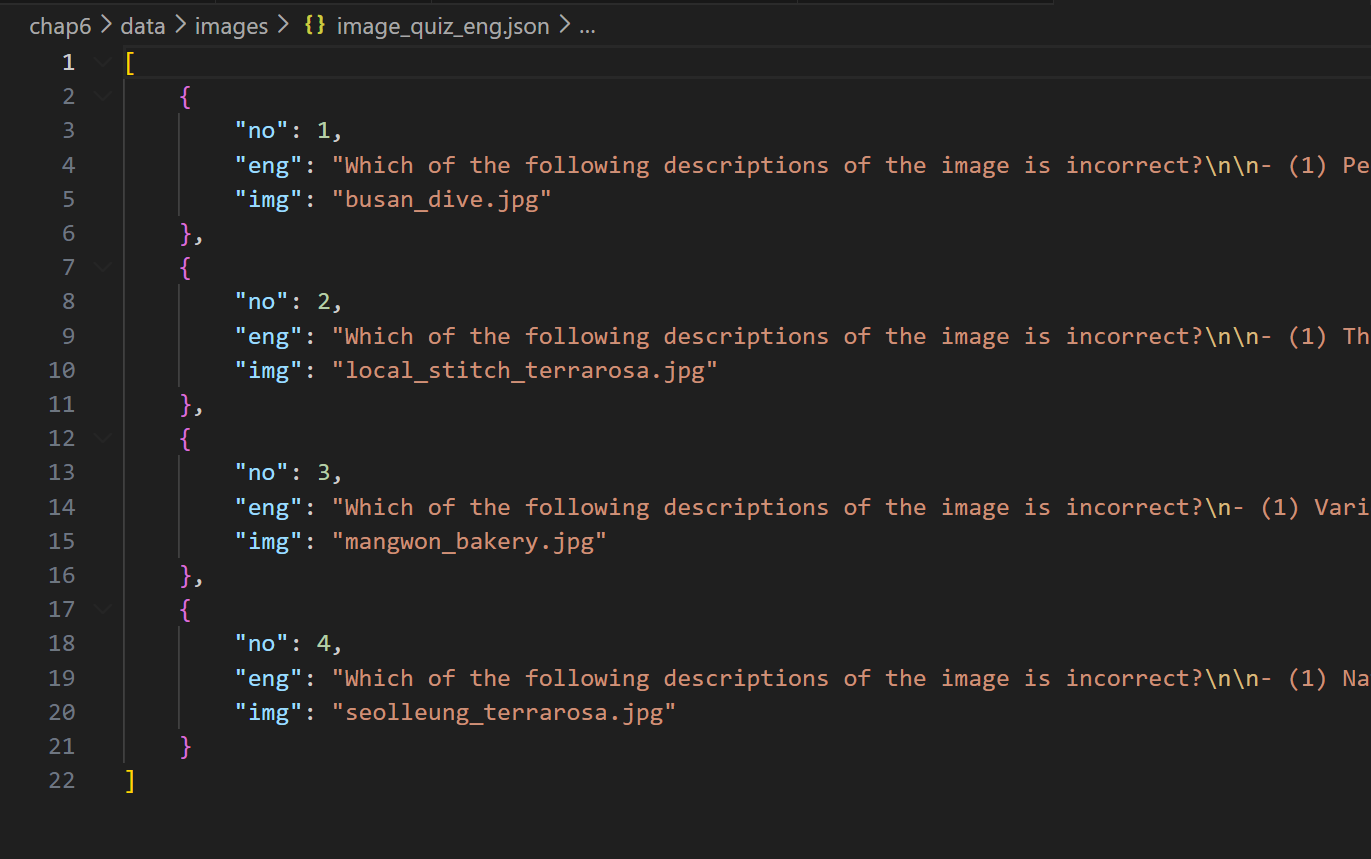
이제 오픈AI의 TTS 기능을 사용해보자!
TTs를 단계별로 학습하기 위해 주피터 노트북 파일을 생성한다
# tts.ipynb
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key = api_key)이제 이 코드는 매우 익숙하다
다음은 오픈AI의 TTS 공식 문서를 활용한 예제이다
오픈AI의 TTS는 다양한 목소리를 제공하는데 그 중에 alloy를 선택해보자
음성으로 생성할 내용을 input에 작성한다
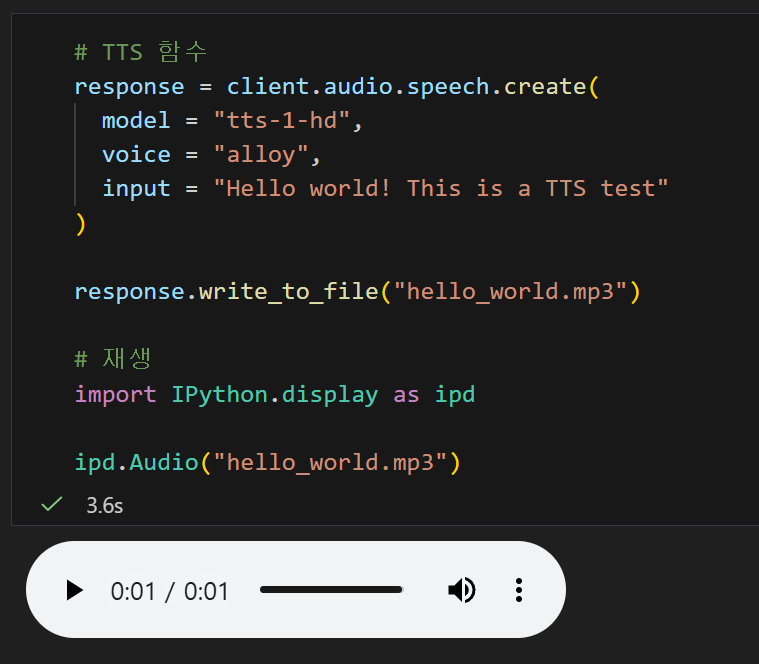
오픈AI의 TTS에서 반환한 값을 response에 답겨 있는데 이 내용을 .write_to_file(). 함수를 사용해 MP3 파일로 사용하자
# TTS 함수
response = client.audio.speech.create(
model = "tts-1-hd",
voice = "alloy",
input = "Hello world! This is a TTS test"
)
response.write_to_file("hello_world.mp3")
# 재생
import IPython.display as ipd
ipd.Audio("hello_world.mp3")사진에서 보이는 것처럼 플레이 버튼을 누르면 생각보다 꽤 그럴싸한 퀄리티의 음질과 발음을 느낄 수 있다
목소리를 바꿀 수도 있다
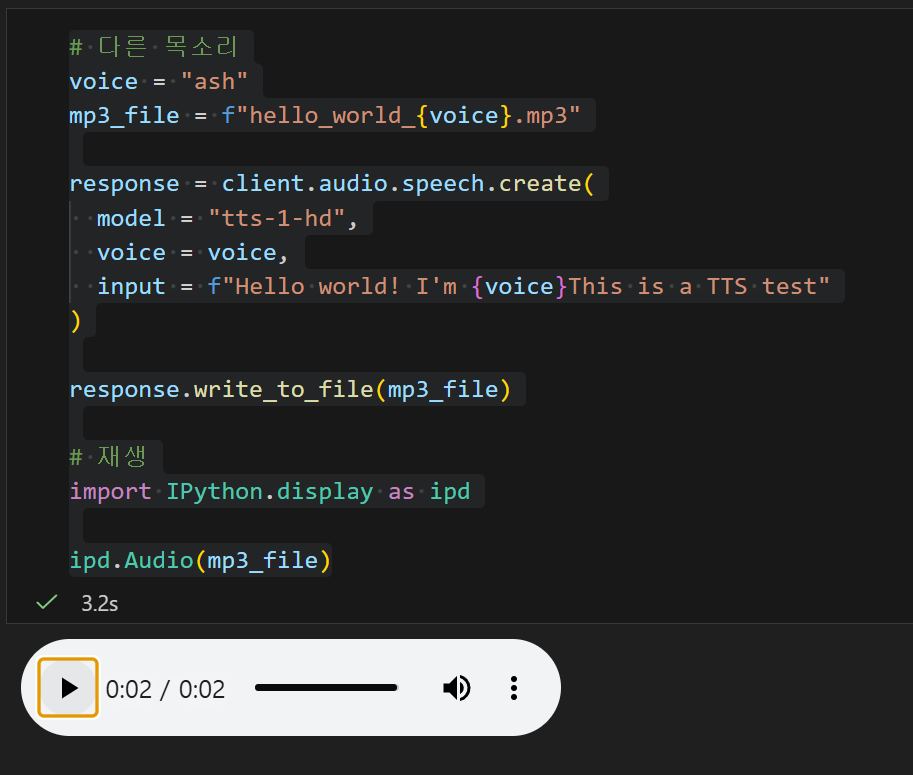
이번에는 ash 목소리를 선택하고 자신의 이름을 말하도록 input을 수정해보도록 하자
# 다른 목소리
voice = "ash"
mp3_file = f"hello_world_{voice}.mp3"
response = client.audio.speech.create(
model = "tts-1-hd",
voice = voice,
input = f"Hello world! I'm {voice}This is a TTS test"
)
response.write_to_file(mp3_file)
# 재생
import IPython.display as ipd
ipd.Audio(mp3_file)이번에는 꽤나 중성적인 남성의 목소리가 들린다번에는 꽤나 중성적인 남성의 목소리가 들린다
이제 미리 만들어놨던 image_quiz_eng.json 파일을 읽어보자
import json
# JSON 파일 열기
with open('../chap6/data/images/image_quiz_eng.json', 'r', encoding='utf-8') as f:
eng_dict = json.load(f)
eng_dict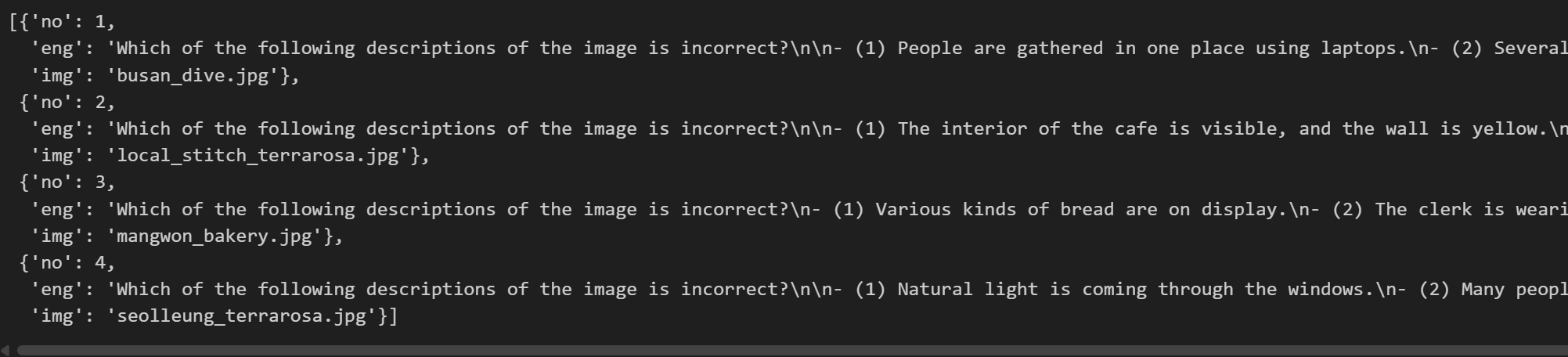
JSON 파일을 딕셔너리 형태로 읽는데 성공했다
for문을 이용해서 이 딕셔너리를 하나씩 읽어오자
다음 셀을 실행하기 전에 .write_to_file()내에 지정한 경로가 있는지 꼭 확인해야한다
만약 폴더가 없다면 폴더를 생성한 이후에 코드를 실행해야 함에 주의하자
voices = ['alloy', 'ash', 'coral', 'echo', 'fable', 'onyx', 'nova', 'sage', 'shimmer']
for q in eng_dict:
no = q['no']
quiz = q['eng']
quiz = quiz.replace("- (1)", "- One.\t")
quiz = quiz.replace("- (2)", "- Two.\t")
quiz = quiz.replace("- (3)", "- Three.\t")
quiz = quiz.replace("- (4)", "- Four.\t")
print(no, quiz)
voice = voices[no % len(voices)]
response = client.audio.speech.create(
model = "tts-1-hd",
voice = voice,
input = f"#{no}. {quiz}"
)
response.write_to_file(f"./data/audio/{no}.mp3")위 코드에서 확인해야 할 부분은 다음과 같다
- quiz = quiz.replace("- (1)", "- One.\t")
'- (1)' 을 '- One'으로 바꾼다
이 부분을 제외하고 음성파일을 생성한다면 종종 숫자를 생략하고 읽는 문제가 발생한다
- voice = voices[no % len(voices)]
voices에 사용할 수 있는 모든 목소리의 이름을 리스트에 담아 놓고, 문제 번호 no가 몇인지에 따라 음성이 선택되도록 한다
이렇게 하면 MP3파일을 각각 다른 목소리로 생성할 수 있다
이제 생성된 파일을 재생해보면 꽤나 그럴싸한 영어 듣기 평가 문제가 완성되었다!!
4. 마무리
이렇게 해서 사진을 이용해 영어 듣기 평가 문제 까지 만들어보았다
생각보다 TTS의 퀄리티가 좋아서 놀라웠다
이정도면 토익을 볼 때, 귀를 뚫는 정도로 활용할 수 있지 않을까? 싶을 정도로 퀄리티가 괜찮았던것 같다
프롬프트를 더 잘 사용하거나 TTS를 조금 더 깎아낸다면 실제 토익 시험에서 들리는 듣기 평가 문제가 되지 않을까 싶다
현재 JLPT 시험을 준비중인데 과연 일본어도 TTS로 구현이 가능할지 궁금하다
이 부분에 대해서는 추후 위의 코드들을 변형해서 시도해보면 좋을 것 같다
이번 포스팅이 Chap5의 마지막 포스팅이다
다음 포스팅부터는 AI 투자자를 만들어보는 실습을 한다고 하는데 이 부분도 상당히 기대가 된다
그 전에 펑션 콜링에 대해서 배워야 하는데 또 다시 새로운 것을 배우다니 꽤나 재밌다 ^0^
