
본 포스팅은 "Do it! LLM을 활용한 AI 에이전트 개발 입문"을 독학하며 쓴 글입니다.
내돈내산 포스팅임을 참고해주시면 감사하겠습니다.
2026년 2월 19일 기준으로 작성되었습니다.
Chapter 8
RAG로 문서에 기반해 답변하는 챗봇 만들기
본 포스팅에서는 RAG를 이용한 실습을 만들어보겠습니다!!!
1. PDF 파일 텍스트로 변환하고 청크 단위로 쪼개기
이제 RAG의 기본 개념은 알았으니 실제 개발을 해보자!!
PDF 문서나 웹사이트를 기반으로 답변하는 챗봇을 만드는 실습을 한다고 한다
우선 주피터 노트북에서 단계별로 실습을 하고 이후에 스트림릿을 이용해 챗봇을 만들어보자
rag_practice.ipynb 파일을 생성하고 필요한 라이브러리를 설치해보자
%pip install pymupdf pypdf langchain_community그리고 RAG를 구현하기 위해 사용할 문서를 다운로드 받아보다
다음 두개의 링크를 이용해서 예시로 사용할 PDF를 내려받자
PDF 링크1 PDF 링크2
프로젝트 폴더 안에 data 폴더를 만들고 내려받은 문서 2개를 옮겨놓자
이제 [OneNYC 2050] 문서의 내용을 data_nyc에 담아 텍스트를 추출해보자
PyPDF Loader는 랭체인에서 제공하는 모듈로 PDF 파일을 읽어 텍스트 데이터를 추출하고 PDF 내용을 랭체인의 다른 도구들과 연결해서 사용할 수 있다
from langchain_community.document_loaders import PyPDFLoader
# PDF 파일을 읽어서 텍스트 데이터 추출
loader = PyPDFLoader("../chap9/data/OneNYC_2050_Strategic_Plan.pdf")
data_nyc = loader.load()
print(data_nyc)이 셀을 실행한 결과는 다음과 같다 파일의 용량이 큰건지 실행하는데 은근 시간이 걸린다
[Document(metadata={'producer': 'Adobe PDF Library 15.0', 'creator': 'Adobe InDesign 14.0 (Windows)',
'creationdate': '2019-04-30T13:48:30-04:00', 'moddate': '2020-01-03T15:55:12-05:00',
'title': '', 'trapped': '/False', 'source': '../chap9/data/OneNYC_2050_Strategic_Plan.pdf',
'total_pages': 332, 'page': 0, 'page_label': '1'}, page_content='OneNYC \n2050\nBUILDING A STRONG \nAND FAIR CITY \n
VOLUME 1 OF 9 \nA\nPRIL 2019\nTHE CITY OF NEW YORK\nMAYOR BILL DE BLASIO\n
DEAN FULEIHAN \nFIRST DEPUTY MAYOR \nD\nOMINIC WILLIAMS \n
CHIEF POLICY ADVISOR\nD\nANIEL A. ZARRILLI eator': 'Adobe InDesign 14.0 (Windows)', 'creationd (생략)RecursiveCharacterTestSplitter를 사용해 출력된 긴 텍스트 데이터를 청크 단위로 나눈다
이때 텍스트 데이터를 1000자씩 나누고 100자의 오버랩을 설정해서 중요한 정보가 잘려서 사라지지 않도록 한다
오버랩은 인접 천크 간에 중복된 내용을 포함시켜 중요한 정보가 빠지지 않도록 한다
이렇게 설정한 text_splitter로 문서를 쪼개 all_splits에 담는다
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 텍스트 데이터를 1000자 단위로 나눔 / overlap은 100자로 설정
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000, chunk_overlap = 100)
all_splits = text_splitter.split_documents(data_nyc)
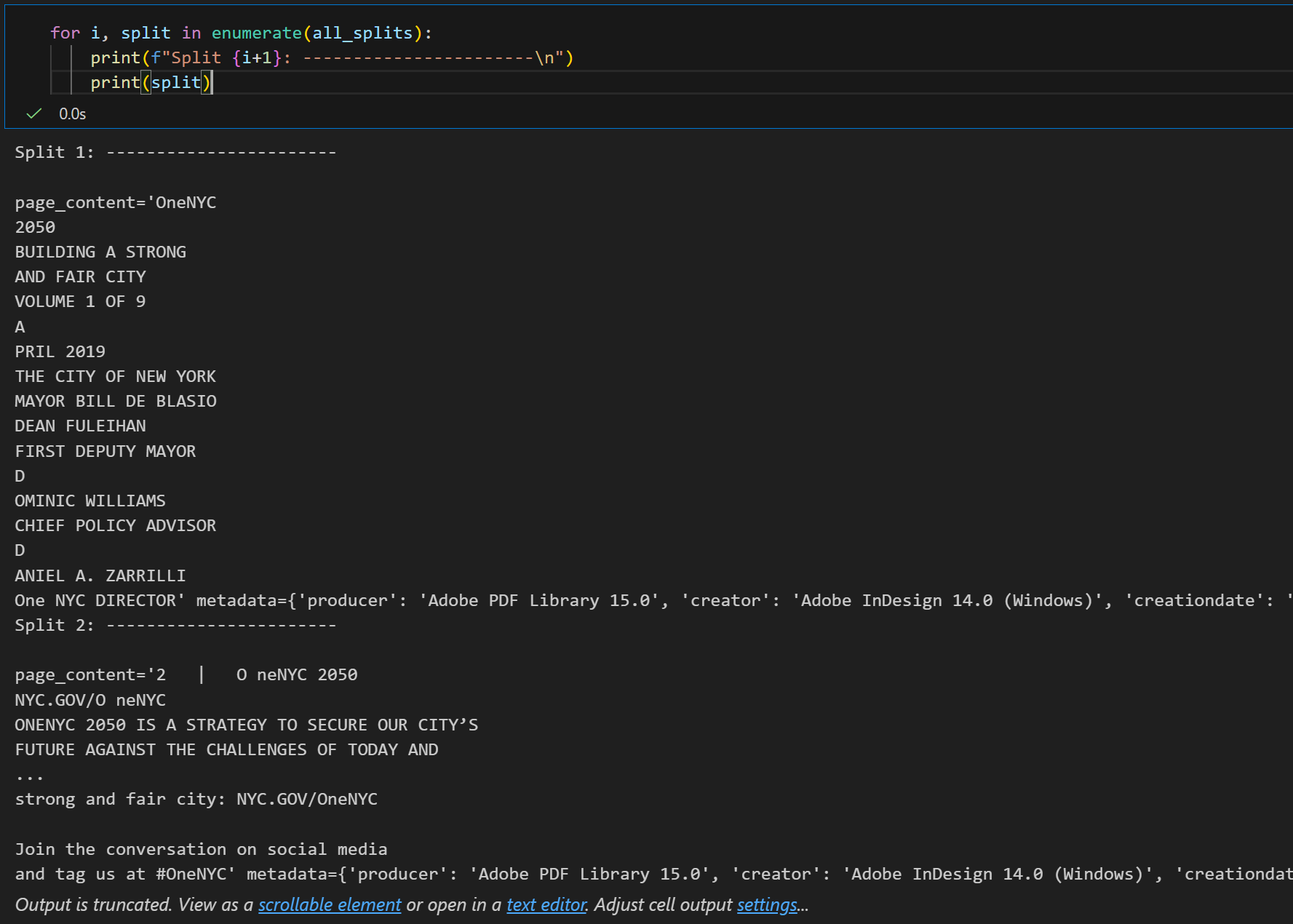
for i, split in enumerate(all_splits):
print(f"Split {i+1}: -----------------------\n")
print(split)반복문을 이용해서 문서가 적절하게 나눠졌는지 확인할 수 있다
실제로 실행한 결과를 보면 PDF의 내용이 오버랩을 포함해서 적절하게 잘 나눠진 것을 볼 수 있다
구체적인 내용은 PDF 버전이나 pypdf, 랭체인 버전에 따라 조금씩 달라질 수 있다
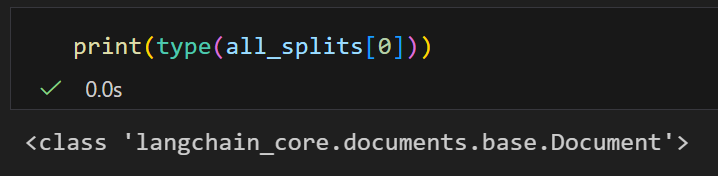
all_splits에 담긴 요소들이 어떤 데이터 타입인지 type()을 이용해서 출력해 보면 랭체인에서 제공하는 Document 클래스의 인스턴스임을 알 수 있다
랭체인에서는 외부 문서를 Document 객체를 이용해 저장한다
Document 클래스는 텍스트 데이터와 관련 메타데이터를 저장하고 관리하는 랭체인의 기본 단위이다
[2040 서울도시기본계획] 문서도 앞에서 사용한 코드를 응용해 다음과 같이 문서를 청킹하고 출력해보자
loader_seoul = PyPDFLoader("../chap9/data/2040_seoul_plan.pdf")
data_seoul = loader_seoul.load()
seoul_splits = text_splitter.split_documents(data_seoul)
for i, split in enumerate(seoul_splits):
print(f"Split {i+1}: -----------------------\n")
print(split)이 코드를 실행해보면 중복되는 내용 없이 페이지 단위로 청크가 끊어져 있는것을 볼 수 있다
각 청크를 오버랩해서 빠지는 내용이 없게 하려던 의도와는 달리 페이지 단위로 텍스트가 나눠진다
이처럼 문장이 페이지 경계에서 끊어지는 문제가 발생한다면 오버랩이 되도록 하는 코드를 추가로 작성해야 할 수도 있다
오버랩 없이 생성된 청크들에 강제로 오버랩을 처리해보자
오버랩 유무를 보기 위해 50번, 51번 청크를 출력해서 확인해보고 오버랩 시킨 이후의 작업과 비교해보자
print(seoul_splits[50].page_content)
print('-----------------------')
print(seoul_splits[51].page_content)32제2장 미래상과 목표
9) 대기질 개선과 폐기물 관리 등 광역거버넌스 차원으로 풀어야 할 과제 발생증가하는 생활폐기물 배출량,
다시 우려되는 대기오염Ÿ서울에서 발생하는 폐기물을 처리해 왔던 인천 수도권매립지의 매립 종료가 2025년 예정되면서 폐기물 처리는 주요한 이슈로 떠올랐다.
(생략)
-보육시설, 아동·노인여가·재가노인복지시설, 장애인생활시설과 문화시설, 공공도서관, 공공체육시설, 병원, 공원 등의 시설도
지속적인 확충 중Ÿ2020년 65세 이상 노년인구는 전체 인구의 15.4%로 최근 10년 사이 비율이 6.0%p 늘어나면서 노인복지시설에 대한 수요가 증대되고 있다.
-----------------------
제1절 서울의 변화진단33-노인여가복지시설 역시 확충되고 있으나, 노령화의 속도를 따라잡지 못해
(생략)
[그림 2-16] 세계 주요 도시의 1인당 공원면적(2014)자료: 서울연구데이터서비스(공원녹지 부문)
3) 서울연구원 서울연구데이터서비스 생활인프라 공원녹지 부문 참조해 재가공각 청크는 Document 인스턴스로 생성되어 있고 내용은 page_content에 있다
앞 청크 끝에 뒷 청크의 첫 100자를 추가하기 위해 다음과 같이 코드를 작성해보자
for i in range(len(seoul_splits)-1):
seoul_splits[i].page_content += "\n" + seoul_splits[i+1].page_content[:100]
print(seoul_splits[50].page_content)
print('-----------------------')
print(seoul_splits[51].page_content)32제2장 미래상과 목표
9) 대기질 개선과 폐기물 관리 등 광역거버넌스 차원으로 풀어야 할 과제 발생증가하는 생활폐기물 배출량, 다시 우려되는 대기오염Ÿ서울에서 발생하는 폐기물을 처리해 왔던 인천 수도권매립지의 매립 종료가 2025년 예정되면서 폐기물 처리는 주요한 이슈로 떠올랐다.
(생략)
-보육시설, 아동·노인여가·재가노인복지시설, 장애인생활시설과 문화시설, 공공도서관, 공공체육시설, 병원, 공원 등의 시설도 지속적인 확충 중Ÿ2020년 65세 이상 노년인구는 전체 인구의 15.4%로 최근 10년 사이 비율이 6.0%p 늘어나면서 노인복지시설에 대한 수요가 증대되고 있다.
제1절 서울의 변화진단33-노인여가복지시설 역시 확충되고 있으나, 노령화의 속도를 따라잡지 못해 2020년에는 노인 천 명당 2.1개소로 2010년에 비해 0.9개소 감소Ÿ다양한
-----------------------
제1절 서울의 변화진단33-노인여가복지시설 역시 확충되고 있으나, 노령화의 속도를 따라잡지 못해
(생략)
[그림 2-16] 세계 주요 도시의 1인당 공원면적(2014)자료: 서울연구데이터서비스(공원녹지 부문)3) 서울연구원 서울연구데이터서비스 생활인프라 공원녹지 부문 참조해 재가공
34제2장 미래상과 목표위의 결과를 비교해봤을 때 오버랩이 생긴것을 볼 수 있다
이제 all_splits에 seoul_splits를 추가해보자
print(len(all_splits))
all_splits.extend(seoul_splits)
print(len(all_splits))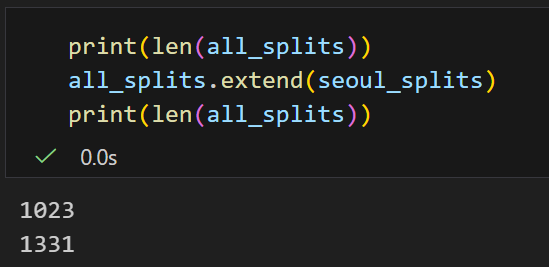
기존 1023개던 청크가 1331개로 늘어난 것을 볼 수 있다
2. 오픈AI 임베딩 모델 사용하기
수백 쪽짜리 문서를 청크 단위로 잘랐으니 이제 이를 벡터로 임베딩해야할 차례이다
이 실습에서는 크로마 DB를 사용하려고 한다
일단 크로마DB를 사용하기 위해 langchain_chroma를 설치하자
%pip install langchain_chroma만약 오류가 발생했다면 C/C++ 컴파일러를 설치해야한다
langchain_chroma는 벡터 계산, 텍스트 처리, 모델과의 상호작용을 위한 수학적 연산에 Numpy 라이브러리를 활용한다
이 과정에 C/C++ 컴파일러가 필요한다
만약 오류가 발생한다면 Visual C++ Build Tools를 설치하면 된다
이제 청크들을 벡터로 임베딩하고 이를 벡터 DB에 저장하는 작업을 진행해보자
텍스트를 벡터로 임베딩하는 모델은 여러 가지가 있다 하지만 한 임베딩 모델을 선택하면 계속 같은 모델을 사용해야 한다
여기서는 오픈AI에서 API로 제공하는 임베딩 모델인 OpenAIEmbeddings를 사용해보려 한다
이 임베딩 모델을 사용하려면 API 키가 필요하다
OpenAIEmbeddings의 인스턴스 embedding을 만들고 embedding.embed_query()를 사용해서 원하는 텍스트를 벡터로 변환한다
이때 임베딩 모델은 text-embedding-3-large를 사용하고 오픈AI의 API키는 .env에서 불러온다
이렇게 설정한 후 .embed_query()에 원하는 텍스트를 넣으면 벡터로 변환된 값을 반환한다
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
import os
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
embedding = OpenAIEmbeddings(model = "text-embedding-3-large", api_key = OPENAI_API_KEY)
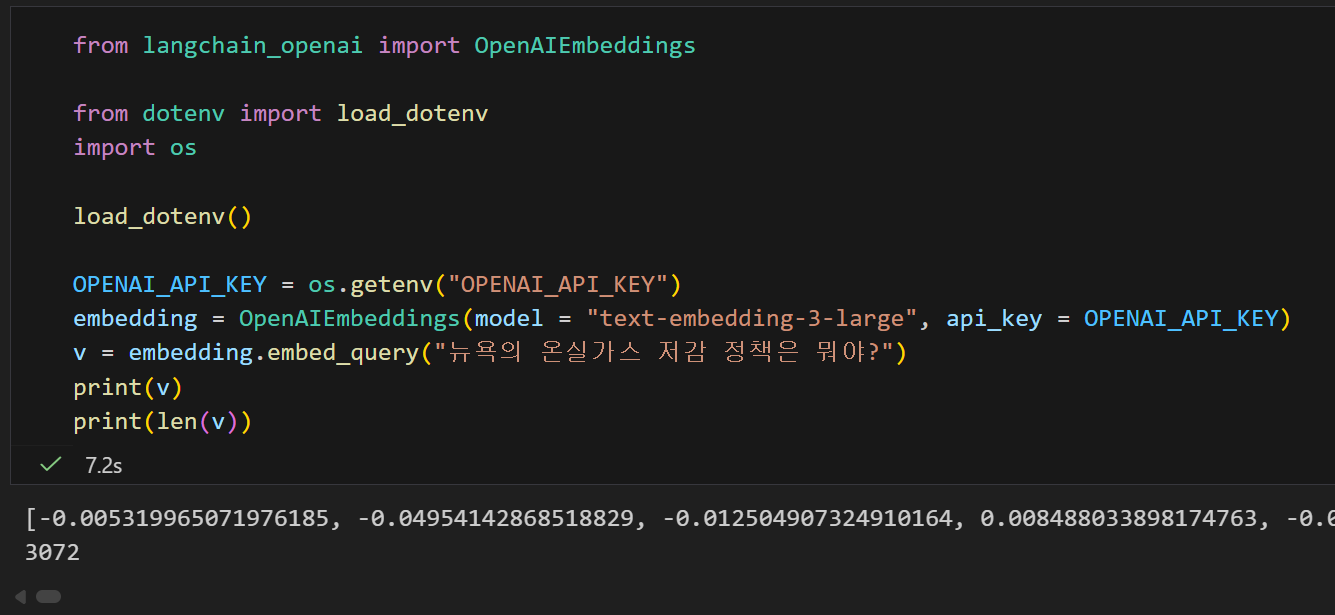
v = embedding.embed_query("뉴욕의 온실가스 저감 정책은 뭐야?")
print(v)
print(len(v))생각보다 간단한 쿼리인데 무려 3072차원의 벡터로 임베딩 된것을 볼 수 있다
(솔직히 안에 어떤 구조로 되어있는지 궁금함....)
3. 벡터 DB와 리트리버
all_splits의 모든 청크들을 벡터로 변환해서 크로마 DB에 저장해보자
앞서 만든 all_splits에는 PDF를 청크로 쪼개놓은 Document 객체들이 있다
이 객체들을 백터화해서 저장해보도록하자
from langchain_chroma import Chroma
import os
persist_directory = './chroma_store'
if not os.path.exists(persist_directory):
print("Creating new Chroma store")
vectorstore = Chroma.from_documents(
documents = all_splits,
embedding = embedding,
persist_directory = persist_directory
)
else:
print("Loading existing Chroma store")
vectorstore = Chroma(
persist_directory = persist_directory,
embedding_function = embedding,
)
- persist_directory = '../chroma_store'
크로마 DB를 생성하고 저장할 위치를 persist_directory로 지정한다
이 경로에 크로마DB가 생성되면 sqlite3 파일이 저장된다
- if not os.path.exists(persist_directory):
해당 경로가 없다면 os.path.exists()로 디렉토리를 확인 후 새로 생성한다
- vectorstore = Chroma.from_documents( )
랭체인에서 크로마DB를 사용할 수 있도록 지원하므로 langchain_chroma의 Chroma를 이용해 벡터는 vectorstore에 저장한다
앞서 생성한 청크 all_splits를 documents에 넣고 정한 임베딩 모델을 포함시킨다
- vectorstore = Chroma( )
이미 디렉토리가 존재한다면 임베딩 과정을 반복할 필요 없이 기존 데이터를 바로 이용할 수 있도록 한다
이때 Chroma에 persist_directory와 embedding_function만 지정한다
이 셀을 실행시키면 같은 폴더 안에 chroma_store가 생성된 것을 볼 수 있다
이제 vectorstore에서 청크 3개를 가져오도록 설정한 retriever를 만들었다
retriever.invoke()안에 텍스트를 입력하면 해당 내용이 벡터로 임베딩된 후, 크로마 DB에서 가장 유사한 청크 3개를 가져온다
여기에서는 서울시의 환경 정책을 물어보자
retriever = vectorstore.as_retriever(k = 3)
docs = retriever.invoke("서울시의 환경 정책이 궁금해")
for d in docs:
print(d)
print('--------------')실행해보면 해당 PDF를 기반으로 서울시의 환경 관련 계획을 찾아낼 수 있다

4. 주어진 청크에 기반하여 언어 모델로 답변 생성하기
이제 사용자가 질문하면 리트리버를 이용해서 관련 내용을 찾고
이를 바탕으로 언어 모델을 사용해 답변을 생성하는 기능을 개발해보자
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_classic.chains.combine_documents import create_stuff_documents_chain
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model = "gpt-4o-mini")
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"사용자의 질문에 대해 아래 context에 기반해 답변해라.:\n\n{context}",
),
MessagesPlaceholder(variable_name = "messages"),
]
)
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
- ChatPromptTemplate : 언어 모델에 전달할 프롬프트를 정의하는 템플릿 클래스
이 템플릿을 이용하여 시스템의 역할과 메세지를 설정한다
- MessagePlaceHolder : 사용자 메세지와 같은 동적 데이터를 프롬프트에 삽입하기 위해 사용하는 클래스
여러 메세지 입력을 처리할 수 있다
- create_stuff_documents_chain은 여러 텍스트를 결합해 답변 생성 체인을 만드는 함수
기존 프롬프트를 기반으로 언어 모델을 통해 최종 답변을 생성한다
- question_answering_prompt = ChatPromptTemplate.from_messages()
답변을 생성할 때 사용할 프롬프트 템플릿을 생성
- "사용자의 질문에 대해 아래 context에 기반해 답변해라.:\n\n{context}",
시스템 역할을 설정하고 주어진 context를 바탕으로 답변하도록 모델에 지시함
{context}는 문서 청크를 포함하는 자리 표시자로, 검색된 컨텍스트를 모델에 전달하는 빈칸 역할을 함
- MessagesPlaceholder(variable_name = "messages"),
messages 변수를 자리 표시자로 설정해서 사용자와 대화를 나눈 메세지를 동적으로 삽입할 수 있다
이를 통해 사용자가 한 질문을 바탕으로 답변을 생성할 수 있다
- document_chain
검색된 문서 청크와 사용자 질문을 바탕으로 언어 모델을 호출하고 답변을 생성한다
이제 마지막 한단계가 남았다
랭체인에서 제공하는 도구 가운데 ChatMessageHistory를 사용해서 채팅 메세지를 쉽게 저장할 수 있다
ChatMessageHistory 객체인 chat_history를 만들고 add_user_message와 add_ai_message 메소드를 이용해
사용자와 AI의 메세지를 차례대로 저장할 수 있다
앞에서 만든 document_chain을 사용하여 생성된 답변얼 add_ai_message로 chat_history에 추가하고 그 후 결과를 출력해보자
from langchain_community.chat_message_histories import ChatMessageHistory
# 채팅 메세지를 저장할 메모리 객체 생성
chat_history = ChatMessageHistory()
# 사용자 질문을 메모리에 저장
chat_history.add_user_message("서울시의 온실가스 저감 정책에 대해 알려줘")
# 문서 검색하고 답변 생성
answer = document_chain.invoke(
{
"messages" : chat_history.messages,
"context" : docs,
}
)
# 생성된 답변 메모리에 저장
chat_history.add_ai_message(answer)
print(answer)이 셀을 실행하면 실제 PDF 문서를 참고해서 추출한 내용으로 답변이 생성된 것처럼 보인다
서울시는 온실가스 저감을 위해 다양한 정책과 전략을 추진하고 있습니다. 주요 내용은 다음과 같습니다:
1. **탄소중립 목표**: 서울시는 2050년까지 탄소중립을 목표로 하고 있으며, 이를 위해 건물, 교통, 에너지 등 도시 인프라의 혁신이 요구됩니다.
2. **친환경 기술 개발 및 적용**: 건물 부문에서 탄소배출을 감축하기 위한 친환경 기술을 개발하고 이를 적극적으로 적용합니다.
3. **친환경 수송 인프라 확충**: 미래 모빌리티 기술을 활용하고 친환경 차량 및 관련 인프라를 확대하여 교통 부문에서의 온실가스 배출을 줄입니다.
4. **청정에너지 기반 구축**: 에너지 전환을 위한 청정에너지 기반을 마련하고, 분산형 발전시설 확대와 대체에너지 설치 지원을 통해 지역 내 에너지 생산 및 관리 능력을 향상시킵니다.
5. **대기환경 관리체계 강화**: 대기 환경을 고려한 공간계획 및 배출원 관리 체계를 강화해 PM2.5, NOx 등 대기오염물질의 배출을 원천적으로 감축할 수 있는 대책을 추진합니다.
6. **자원순환 체계 구축**: 자원순환·관리의 자립성을 확보하기 위해 분산형 폐기물 처리 시설을 구축하고 자원순환 문화를 활성화합니다.
7. **시민 참여와 교육**: 시민의 기후 행동을 촉진하기 위해 친환경 교육 계획을 수립하고, 대중교통 이용 및 일회용품 사용 감축 등의 가이드라인을 제공합니다.
8. **협력적 거버넌스**: 서울시와 중앙정부, 민간 부문 간의 협력적 거버넌스 체계 구축을 통해 기후 환경 관리를 체계적으로 진행하고 시민들의 참여를 유도합니다.
이외에도 서울시는 기후 재난에 대한 대비, 도심 녹지 공간 조성 등 다양한 방면에서 온실가스 저감 정책을 강화하고 있습니다.이제 지금까지 chat_history에 저장된 대화 기록들을 한번 확인해보자
for m in chat_history.messages:
print(m)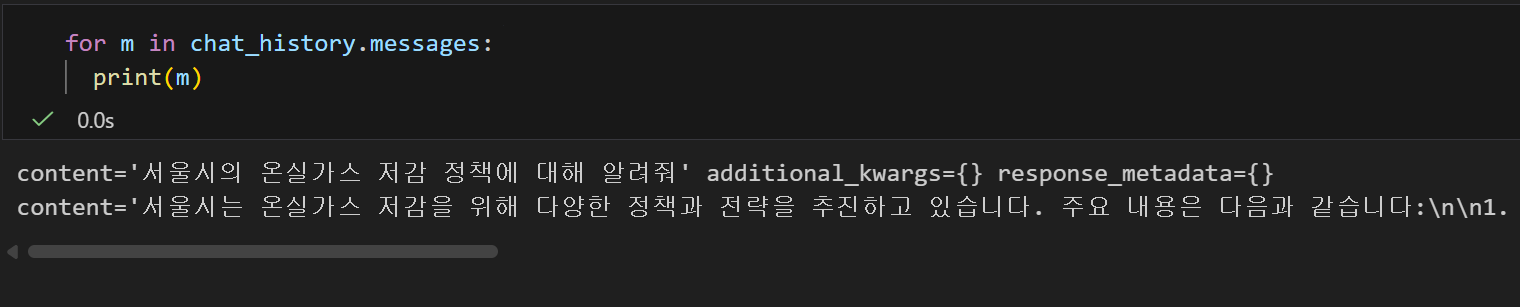
5. 질의확장 구현하기
서울의 환경 정책에 대해 계속 질문하다가 "그럼 뉴욕은?" 이라는 질문을 하게 된다면 그 의도는 "뉴욕의 환경 정책은?" 이라고 물어볼 가능성이 크다
이를 올바르게 처리하려면 질문을 문맥에 맞게 확장하여 관련된 청크를 검색하고 답변을 생성해야 한다
즉 "그럼 뉴욕은?" 이라는 질문을 "뉴욕의 환경 정책은 뭐야?" 처럼 구체적인 형태로 변환하는 질의 확장이 필요하다
우선 필요한 라이브러리를 불러오자
StrOutputParser는 저번 포스팅에서도 사용한 라이브러리로 언어 모델이 생성한 응답을 문자열로 변환해주는 역할을 한다
from langchain_core.output_parsers import StrOutputParserquery_for_nyc에는 '뉴욕은?'이라는 질의 확장이 필요한 질문을 설정한다
이 질문을 기존 대화 내용을 이용해 구체적인 질문으로 변환하려고 한다
ChatPromptTemplate.from_messages로 질문을 확장하는 프롬프트를 작성해보자
MessagesPlaceholder로 기존 대화 내용을 전달할 자리를 마련하고 시스템 메세지로 의도를 파악한 후
질문을 명확하게 변환하도록 지시한다
query_for_nyc = "뉴욕은?"
# query augmentation
# 기존 대화 내용을 활용해 query_augmentation 수행
query_augmentation_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name = "messages"), # 기존 대화 내용
(
"system",
"기존의 대화 내용을 활용하여 사용자가 질문한 의도를 파악해서 한 문장의 명료한 질문으로 변환하라 대명사나 이, 저, 그와 같은 표현을 명확한 명사로 표현하라:\n\n{query}"
)
]
)앞에서 ChatOpenAI로 정의한 chat 객체와 프롬프트를 연결하고 결과를 문자열로 반환하기 위해 StrOutputParser를 사용한다
query_augmentation_chain = query_augmentation_prompt | chat | StrOutputParser()이렇게 만든 query_augmentation을 실행하기 위해서는 사용자의 질문과 이전 대화 내용을 묶어서 제공해야한다
messages와 query 변수를 딕셔너리 형식으로 묶어 invoke 메소드를 사용해 전달한다
augmented_query = query_augmentation_chain.invoke(
{
"messages" : chat_history.messages,
"query" : query_for_nyc
}
)
print(augmented_query)이 셀을 실행시키면 '뉴욕은?' 이라는 애매모호한 질문이 '뉴욕 시의 특징이나 주요 정보는 무엇인가요?'로 반환된다
이제 이렇게 만들어진 augmented_query를 이용해 관련 내용을 검색할 수 있다
이전에 썼던 코드를 활용해 리트리버를 실행하고 결과를 출력해보자
docs = retriever.invoke(augmented_query)
for d in docs:
print(d)
print('--------------')
이제 이 내용들을 활용해서 언어 모델로 답변을 생성해보자
(영어로 된 내용은 바로바로 해석이 어려우니까...)
앞에서 작성했던 코드를 그대로 활용하되 .add_user_message에 '뉴욕은?'이라는 질문이 담긴 query_for_nyc를 추가한다
chat_history.add_user_message(query_for_nyc)
answer = document_chain.invoke(
{
"messages" : chat_history.messages,
"context" : docs,
}
)
# 생성된 답변 메모리에 저장
chat_history.add_ai_message(answer)
print(answer)
물론 해당 내용이 진짜인지는.... 한번 PDF를 보고 판단해봐야하지 않을까 싶다
6. 마무리
이렇게 RAG에 기반한 챗봇을 만들어봤다
개인적으로 벡터를 임베딩하고 크로마 DB에 저장하는데 까지는 이해할만 했는데
갑자기 언어 모델을 불러오면서 답변을 생성하는 부분에서 코드가 확 어려워진 느낌이다
question_answering_prompt를 만들때 MessagesPlaceholder하고 프롬프트 양식이 아직 낯설어서 그런듯하다
일단 이렇게 만든 부분을 스트림릿에서 챗봇을 완성시켜보려고 한다!!
항상 터미널로 챗봇을 만드는거 까지는 좀 괜찮은데
스트림릿으로 옮기는건 또 많은 코드를 갈아 엎는 느낌이...
