DKT 1강 : DKT란?
Deep Knowledge Tracing : 지식 상태 추적 (교육계의 AI 라고 불리우기도 한다)
지식 상태를 기반으로 다음 문제를 예측한다. → 그 문제를 기반으로 지식 상태를 최신화 한다.
사칙연산 예제
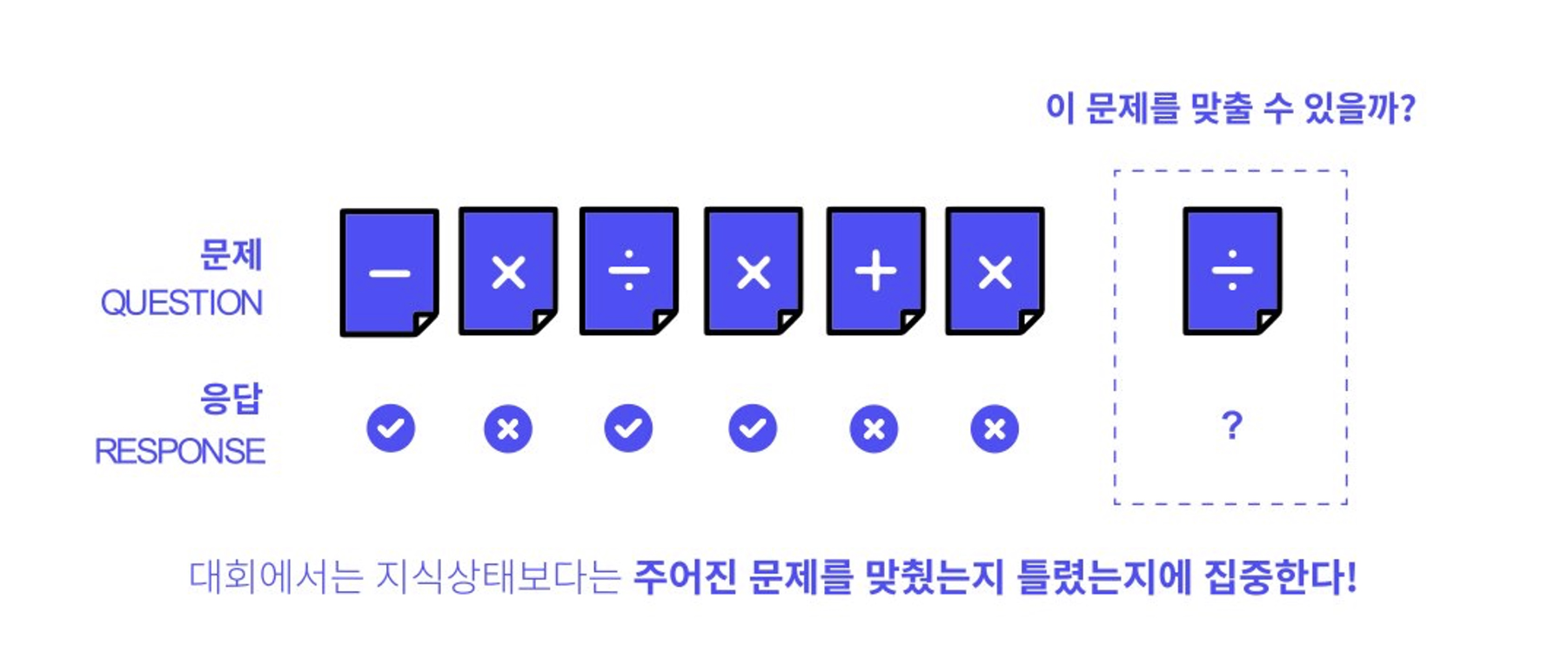
데이터가 많아야지 오버피팅 방지 가능 → 힘들다면 Regularization, dropout 등등
문제 추천 혹은 예측에 활용 가능하다.
시퀀스 데이터가 주어지고 test data의 경우 마지막 데이터의 정답 여부를 예측하는 문제
- 데이터 설명
문제, 응답여부, 풀이 시간, 난이도 등 다양한 feature들이 존재
- Metric 이해
Binary classificaiton (0/1) : 모델의 예측은 0~1사이 값의 proba (float), 실제 값은 0,1 중 하나
즉, threshold를 어떻게 설정할 것인가 (기존대로 0.5? or 조금 더 기준을 높여서 0.7? …)
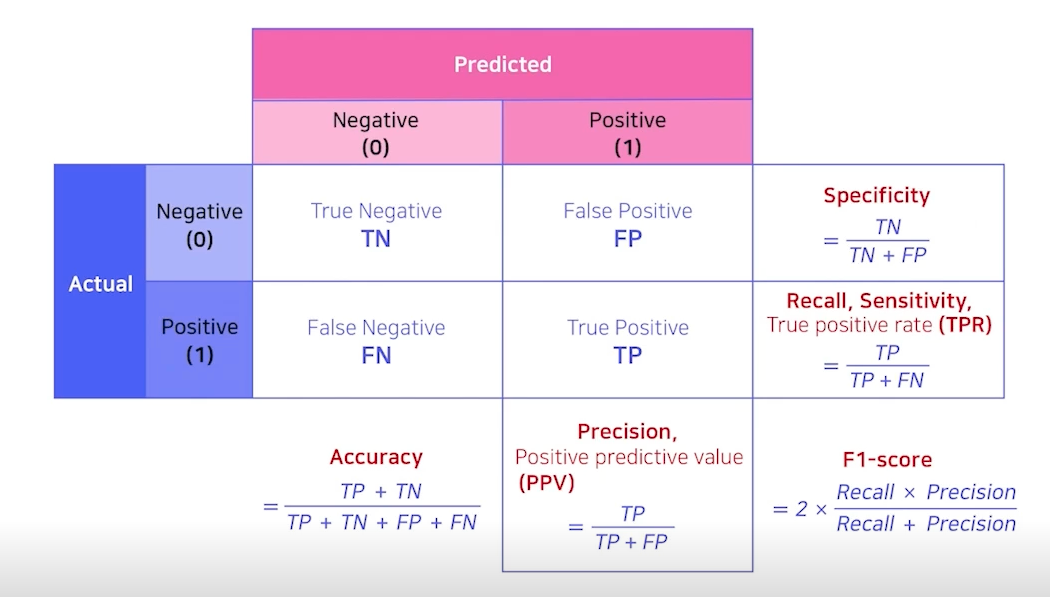
Precision, Recall, f1-score, AUC, Accuracy이 있지만 우리는 AUC 사용
scikit learn의 기본 confusion matrix 형태
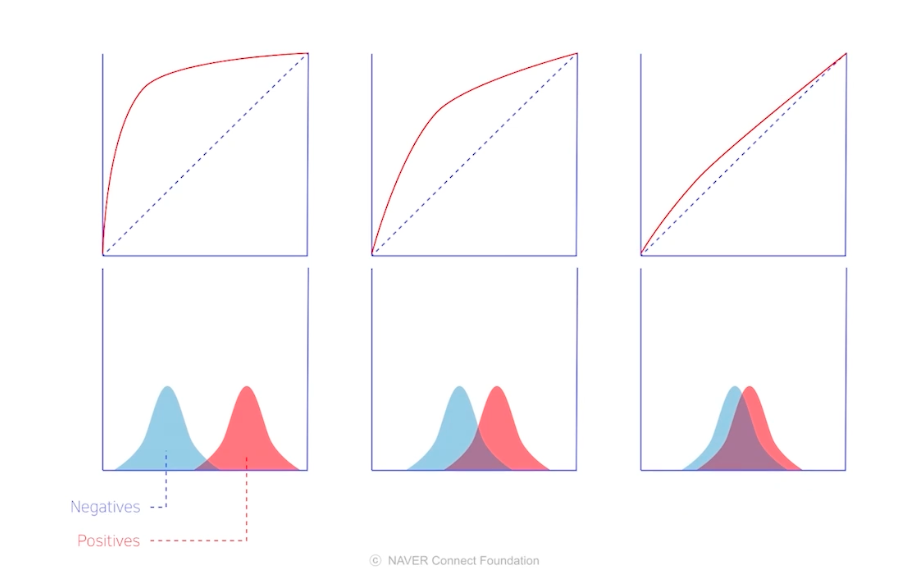
AUC는 분포 metric이다
장단점이 존재한다
장점
1) 척도 불변 : proba의 절대적인 값에는 의존 x, 0-1 분포 간 겹치는 부분에 의존
2) 분류 임계값 불변 : threshold값에 의존하지 않고 모델의 예측 품질 측정 가능단점
1) 척도 불변이 항상 좋지만은 않음
ex) 0.9라는 확률 값 자체로 갖는 의미를 훼손할 수 있음 (0.7과 0.9가 같은 의미를 가질 수도 있다.)2) 분류 임계값을 변화 시켜야 할 때도 있다.
FN과 FP를 최소화 시켜야 하는 목적에 따라 threshold 값을 조정할 필요가 있을 때도 있다.
ex) 스팸메일을 분류할 때, 되도록이면 확실한 스팸메일만 스팸메일함에 넣어줘야 나에게 오는 중요 소식들을 놓치지 않고 전달 받을 수 있다. → 스팸메일이 아닌데 스팸메일로 분류하면, 영영 못 볼 수도 있음Imbalance data에는?
AUC가 높게 측정되는 경향이 있다.
왜냐하면, 0과 1의 개수가 현격히 차이나기 때문에 FPR과 TPR의 눈금 수가 차이나고, 거기서 생기는 비대칭이 존재하기 때문이다.
하지만, Test data를 동일하게 유지하면 모델간 상대적 성능 비교는 가능하다.
Sequence 모델의 변천사
RNN → 장기기억 문제 해결 → LSTM → 번역 모델로 활용 해보자 → SEQ2SEQ → context vector 의존성을 문제 해결(또한, 문장이 길어지면 자연스레 문제 발생) → ATTENTION → 병렬 처리 문제 해결(positional encoding으로 순서 정보 유지) → TRANSFORMER
DKT 2강 : i-Scream 데이터 EDA
2526700건의 interaction 존재 (한 행을 보통 Interaction이라고 한다.)
- features 구성
userID, assessmentItemID(시험 문항), testId(시험지), answerCode(정답 여부), Timestamp(문제를 푼 시간), KnowledgeTag(지식 태그(덧셈, 뺄셈,…))
- userID : 7000개 정도
- assessmentItemID : 9000개 정도, 총 10자리, 첫자리는 A, 그 다음 6자리는 시험지 번호, 마지막 3자리는 시험지내 문항의 번호 → 중간 6자리가 같으면 같은 시험지인것.
- testId : 1500개 정도, 총 10자리, 첫 자리는 A, 그 다음 9자리중 처음 3자리, 끝 3자리가 시험지 번호, 가운데 3자리는 000
- 처음 3자리
0x0의 형태, x에는 1-9가 들어가고 1-9 별로 정답률이 다르다 → 대분류 feature로 사용 가능
- answerCode : 1이 맞은 것, 0이 틀린 것인데 ,1의 비율이 전체의 65%정도 → Imbalance
- Timestamp : 사용자가 Interaction을 시작한 시간 정보 → 다음문항의 시작시간을 비교해서 한 문제 푸는데 걸리는 시간을 전처리 할 수도 있겠다.
- KnowledgeTag : 912개의 태그 존재 (중분류 역할)
- EDA를 할 때는..
feature 변수를 분류하라 (연속, 이산, 범주형 …)
그 후 기술통계량을 살펴보고 시각화 하라
정답률 혹은 타겟변수에 맞춰서 진행하는 것이 유리하다. ex) 문제집 별 정답률 비교, 문제 푸는데 걸리는 시간 별 정답률 등등
- 기술통계량 분석
-
사용자 분석
사용자당 푼 문항은 평균 339문항, 최소 9문항 최대 1860문항 (histogram) 오른쪽 긴 꼬리 (파레토 분포 비슷)
학생 별 정답률은 평균 62.8%, 중앙값 65.1%
-
문항, 시험지 별 정답률 분석
문항별 정답률 추이 : 평균 65.4%, 최소 4% 최대 99.67%
시험지별 정답률 추이 : 평균 62.8%, 최소 0%, 최대 100%, 중앙값 65.1%
-
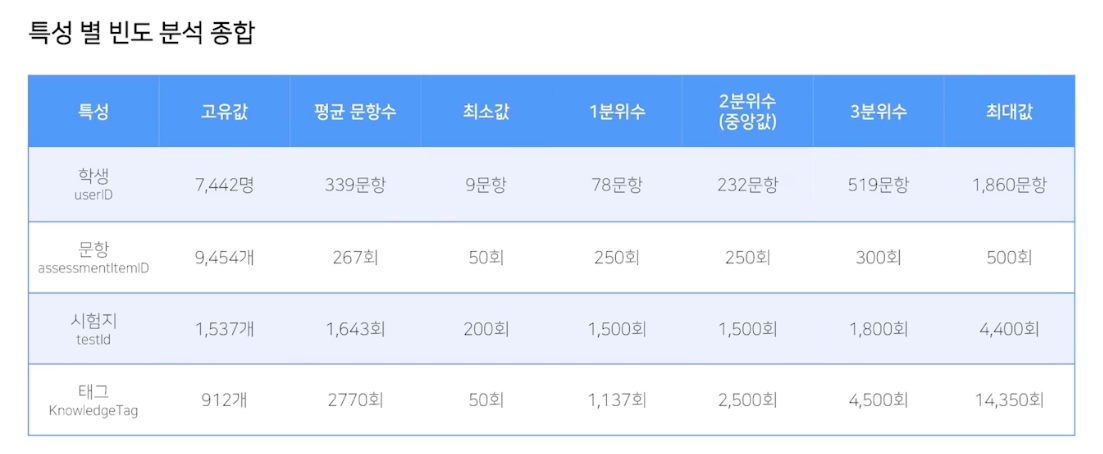
특성 별 빈도 분석 종합
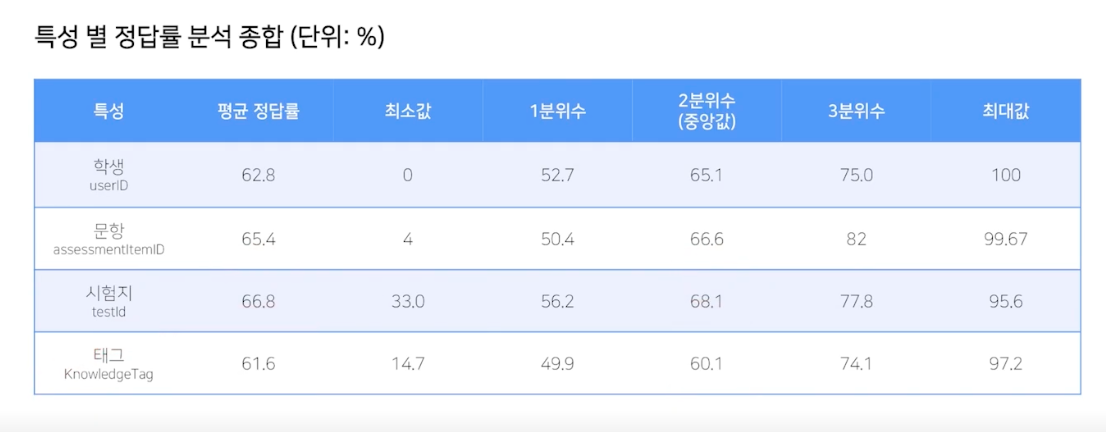
문제풀이 수와 정답률 간의 상관관계 탐색
문제를 많이 풀면 자연스레 정답률이 올라갈 것 같은데, 실제로 그럴까?
평균보다 많이 푼 그룹 : 파란색, 평균보다 적게 푼 그룹 : 주황색
분포가 조금 달라보이긴 한다.
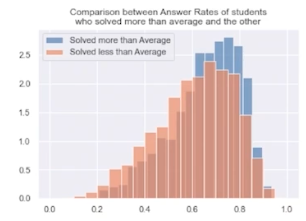
태그의 노출 횟수와 정답률간의 상관관계 탐색
평균보다 많이 노출 된 그룹 : 파란색, 평균보다 적게 노출 된 그룹 : 주황색
- 해볼 만한 추가 작업 노출된 태그 수를 기준으로 일정 범위로 자르고 (0-10, 10-20, … 각 그룹에서의 평균 정답률을 그려서 시각화 해보자
- 문항을 풀면 풀수록 실력(정답률)이 늘어날까?
전체 누적 정답률로 그래프를 그려보면, 초기에는 1 or 0으로 시작해서 평균으로 수렴해가는 모습을 보여준다
때문에 시퀀스 데이터임을 고려하여 Moving Average를 구해야 조금 더 추세를 확인할 수 있을 것 같다. (window 사이즈를 조절해가며)
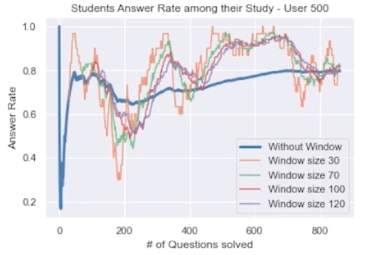
위 그림은 500번 유저의 정답률 추이인데, window 사이즈를 조절해 MA 계산하여 시각화한 자료이다.
들쭉날쭉함을 알 수 있다. 보통 문제집별로 푸는 것 같았는데 (A 문제집 다 풀고, B 문제집 풀고) 그렇다면 문제집간의 난이도 때문에 들쭉날쭉함이 보이는 것은 아닐까? 그렇다면, 문제집의 문제 수로 window 사이즈를 설정하거나 문제집 별 평균 정답률을 계산해보는 것은 어떨까? 그리고 문제집 내에서 특정 번호는 어렵다는 패턴도 있는지 파악하면 좋을 것 같다.
- 문항을 푸는데 걸린 시간과 정답률간의 관계
(배경지식)
쉬운문제 → 시간 적게 소요 → 정답률 높다
어려운문제 → 시간 많이 소요 → 정답률 낮다
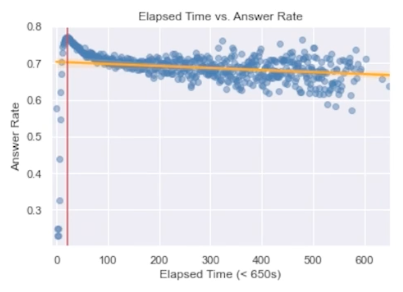
그런데, 너무 어려운 문제라서 풀지 못한다고 판단하는 경우 찍고 넘어가기 때문에 시간소요가 굉장히 적지 않을까?
이 때문인지, 특정 시간(22초)에서 정답률이 가장 높고, 그 전에 너무 빨리 푼 문제는 정답률이 낮았으며, 그 이후에 푼 문제들은 정답률이 차츰 낮아지는 모습을 보였다.
- 추가로 고려해볼만한 사항들
- 더 많이 노출된 시험지는 정답률이 높을까?
- 같은 시험지의 내용 혹은 같은 태그의 내용을 연달아 푸는 경우 정답률이 오를까?
- 시간대가 영향이 있을까? (밤에 잘 풀린다거나, 새벽에 잘 풀린다거나)
위 자료는 부스트캠프 AI Tech 4기 강의를 참고하여 만들었습니다.
