[논문리뷰]Clinical Natural Language Processing for Radiation Oncology: A Review and Practical Prime(Red journal, Jan 2021)
Medical AI
Paper: https://www.redjournal.org/article/S0360-3016(21)00118-8/fulltext
보다 domain-specific한 정보를 얻기 위해 방사선학 관련된 Clinical NLP를 다루는 서베이 페이퍼를 리뷰해봅시다.
0. Abstract
NLP 알고리즘들은 주로 unstructured free text를 structured data로 바꿔 여러 인사이트를 도출하곤 합니다.
의학 분야에서도, 만약 풍부하고 표현력 있는 수 많은 데이터들을 사용할 수 있다면, 임상 목적에 맞게 빅데이터 연구의 잠재력을 터뜨릴 수 있을 것이다.
아무튼 최근에는 NLP 분야가 발전하면서 다양한 학계/산업계에서 정보 추출 혹은 임상 기록으로부터의 피노타이핑등 여러가지 툴들이 개발되어 왔습니다.
피노타이핑 : DNA, 유전체, RNA, 단백질, 면역체, 미생물체, 후성유전체, 바이오센서, 소셜그래프, ... 즉, 개인을 심층적으로 정의하는 디지털 체계를 갖춘 모델정도.
(딥러닝을 이용하면 딥 피노타이핑이라고 불리는 것 같기도)
Radiation oncology(방사선 관련 종양학)도 역시 NLP 알고리즘으로부터 여러 수혜를 받을 수 있습니다.
- automated inclusion of radiation therapy details into cancer registries(자동 기록)
- discovery of novel insights about cancer care(케어에 대한 데이터 마이닝)
- improved patient data curation and presentation (환자의 데이터를 더 깔끔하게 기록, 열람)
하지만, 아래와 같은 챌린지들도 있습니다.
- 방사선 종양학 분야에서, 지나치게 많은 전문용어
- 표준이 잡히지 않은 명명법
- 모델 발전을 위해 필수적인 publicly available labeld data의 부족
- radiation database와 종양학 사이에서 교류가 없음.
컴퓨터 과학자와 방사선 종양학 커뮤니티 간에 활발한 교류가 필요하다. 정도?
본 서베이 페이퍼는 NLP 모델에 대한 입문 지침을 제공합니다.
- 알고리즘을 어떻게 평가할 것인지.
- oncology(종양학) 분야에서의 관련 연구 리뷰
- radiation oncology 분야가 나아가야 할 방향
- text 내 의미있는 관계 / 라벨 식별
- 사건 추출(요약)
- 텍스트 내 관련 요소 매핑
- 텍스트 내 진단 부정 내용 식별
- Question & Answering
- 챗봇 등..
1. Introduction
방사선 종양학(radiation oncology)은 Transformation이 굉장히 무르익은 분야라 할 수 있는데, 이는 디지털 방사선학 외에도 유전학적, 병리학적, 생체인식, 임상 Data를 받아서 수행하는 분야이기 때문입니다.
하지만, 엄청나게 많은 전자 의무 기록(EMR)이 있음에도 임상 텍스트는 unstructured data이기 때문에 빅데이터를 활용하기가 쉽지 않습니다.
구조적으로 데이터가 주어지는 "-omic" data와는 반대로 이 unstructed data는 EMR에서 자동적으로 추출되지 않습니다.
근데 기계학습을 활용하려면 unstructed data는 곤란한 면이 없지않아 있죠.
(의사가 참고하기에도 좋지 못합니다).
이를 다루기 위한 가장 간단한 방법은 이 데이터들로부터 manual하게 추출한 다음, 사용할 수 있는 데이터베이스를 구축하는 것이긴 한데요, 손이 너무나도 많이 갑니다.
전문지식이 필요할 뿐만 아니라, 실수를 범하기도 쉬우며, 비효율적입니다.
그렇기 때문에, NLP 기법들을 활용해 빠르고, 정확하게 임상 정보를 추출하는 방법을 추구해야 합니다.
최근 몇년 간 NLP 분야가 발전함에 따라 Medical data를 추출하는 데도 사용은 되고 있지만, 여전히 (다른 분야만큼) 만연하지는 못한 상황입니다.
clinical text를 분석하는 것은 개인이 진행하기 쉽지는 않은 태스크이기도 하구요.
본 서베이 논문에서 저자들은 이런 Clinical NLP 기법의 리스크와 이점을 다뤄, 방사선 종양학자들, 의사들, NLP 연구자들이 열심히 소통하길 바라며 서베이를 했다고 합니다.
특히 현대의 가장 큰 문제인 cancer care 관련해서요.
Topic in this survey paper
- Clinical NLP 연구에 대한 평가
- (종양학에 적용될 수 있는)다양한 task에 대한 리뷰
- NLP가 방사선 종양학과 관련해 줄 영향
2. What is NLP?
NLP는 specific tasks에 따라, 그리고 언어의 level에 따라 다양한 방법들을 취할 수 있습니다.
text에서 문자들과 관련된 details을 추출하는 것부터, 모든 서류들을 연산 가능한 representations으로 변환하는 것까지.
Low-level tasks
- part-of-speech tagging (pos tagging)
- 단어의 품사나 클래스를 식별
- extraction of discrete data(from unstructured texts)
High-level tasks - more abstracted tasks(추상적인 태스크)
- 가령, 문장과 문서를 이해해서 패턴과 주제를 알아낸다든지,...
혹은, 이 모든 걸 활용해서 paralle or hierarchical tasks를 수행하기 위한 파이프라인을 구축할 수도 있습니다.
이를 통해 아래와 같은 (이미 어느 정도 수행할 수 있는 수준의) task를 수행할 수도 있고,
- registry creation(의미 있는 데이터베이스 구축정도로 해석..?)
- medical research(의학 연구)
- postmarket surveillance(시장 출시 후 감시)
궁극적으로는 clinical care를 보조하는 역할을 할 수 있을 것입니다.
personalized medicine을 위한 자동화된 데이터 수집, 표현, clinical phenotyping을 통해서.
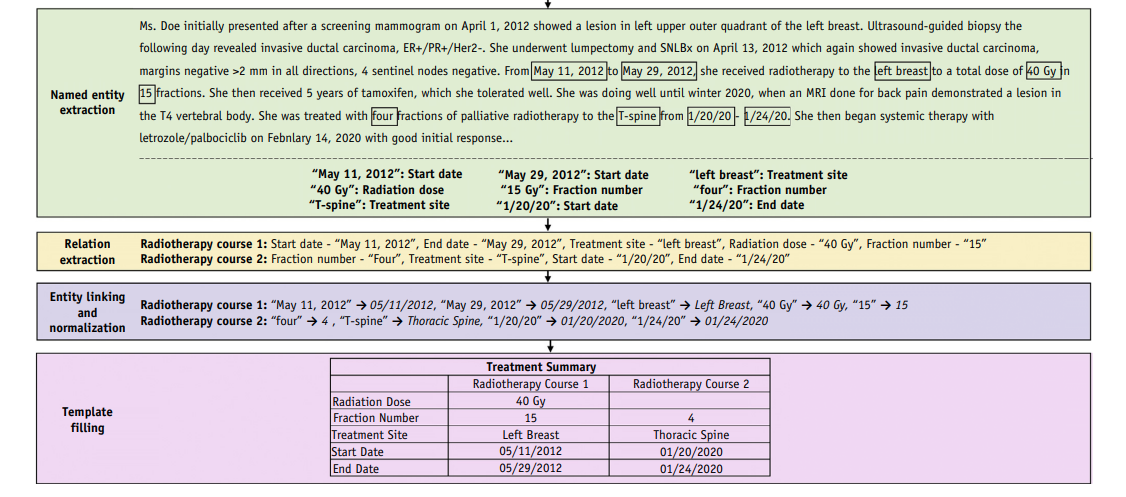
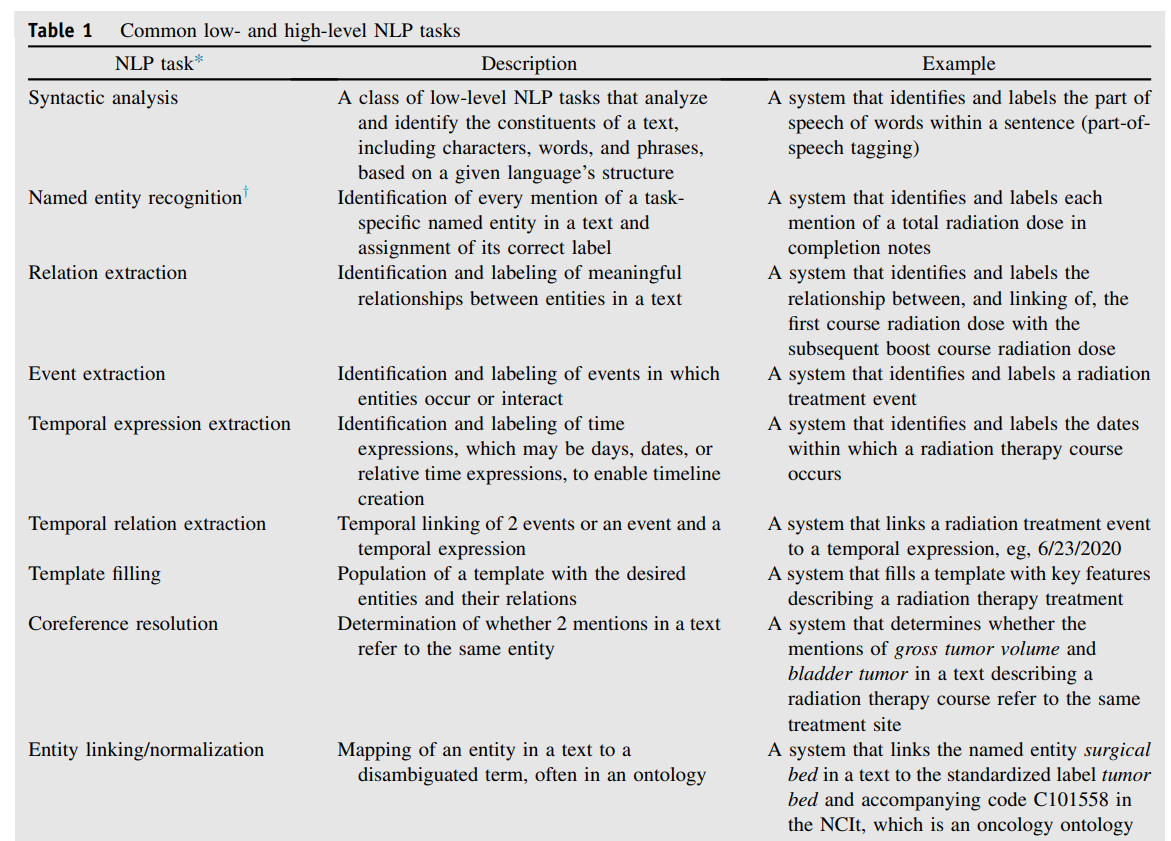
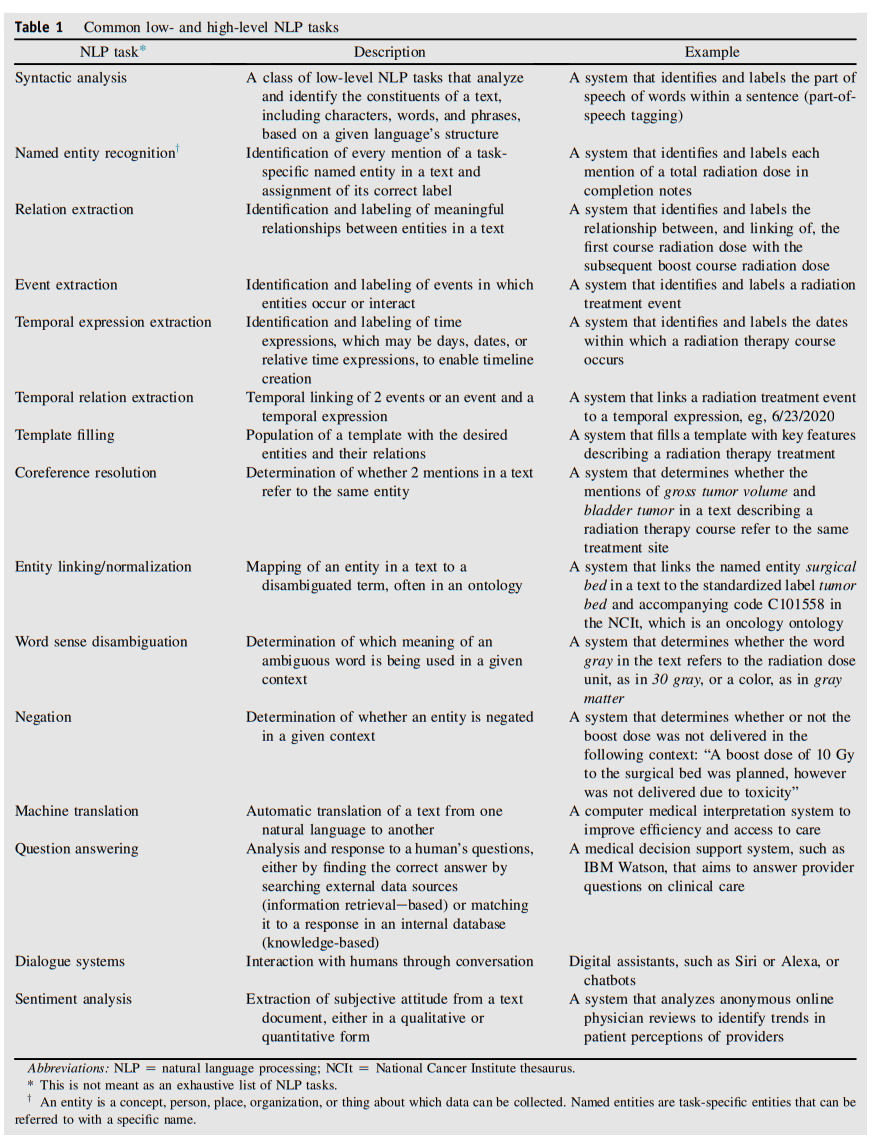
clinical domain에서는, EMR의 free-text로부터 의미 있는 정보를 추출하는 NER(Named Entity Etxraction)이나 의학 문서로부터 결과를 예측하는 태스크에 NLP가 널리 쓰였습니다.
아래의 표는 low-level에서 high-level까지의 clincal NLP 태스크들을 나타냅니다.
3. Recent Technical Advances in NLP
본 단락에서는 그냥 개인적으로 주목할 만한 점들이나, 의학과 관련된 문장만 간단히 발췌하도록 하겠습니다.
- Auto-Encoder는 노이즈 데이터로부터 의미있는 정보를 추출하거나, 혹은 잘 모르는 데이터의 기저 구조를 파악하는 데 도움이 된다.
- 데이터로부터 관계를 알아서 파악하는 딥러닝 모델들은 EMR Texts로부터 여러가지 clinical phenotypes을 알아내는 데도 도움이 될 수 있다.
- 다만 blackbox 때문에 임상 환경에서는 잘 쓰이지 못하고 있는 것 같다.
- 모델 예측에 대한 신뢰도에 따라서 그냥 automatic하게 진단을 내릴 수도 있고(사실 이것도 바람직하지는 못함), 만약 신뢰도가 낮다면(즉, 모델이 반환하는 softmax-probability가 낮다면) 전문가에 의해 추가적인 검증을 거칠 수도 있다.
- 딥러닝 모델 학습을 위해 (어지간하면) 구조적인 데이터가 필요할 때가 많은데, clinical 상황에서도 아래와 같이 이미 EMR 안에 존재하는 구조적인 데이터를 활용할 수 있다.
- diagnosis codes
- admission events
- dischrage events
- survival outcomes..
- 그래도 당연히 의학분야에서는 데이터 구축이 힘들기 때문에 한계는 있음(gold annotated texts)
- 이에 따라 필연적으로 비지도학습도 쓰였는데, 주로 새로운 clinical phenotypes이나 특정 환자 집단에서 공통적으로 발견되는 일련의 clinical features를 발견한다든가.. 하는 데 쓰였다.
- 나름 숨겨진 환자들 간의 패턴을 파악하고 이용하는 데 도움이 될 분야인 건 맞음.
- 근데 애초에 general domain에서도 다루기 힘든 분야이기 때문에 ㅎ..
- 다시 General domain으로 돌아와서, 현대 많은 NLP 기법들은 자기지도학습(Self-supervised Learning)을 기반으로 함(BERT, GPT,...).
- Self-supervised Learning은 블로그 내에서도 다루었으므로 생략
- 결론적으로 Language representation을 배워서 여러 downstream에 사용하게 된다.
- non-clinical texts에 학습시킨 모델도 clinical texts 관련 태스크의 성능을 높히는 데 일조함(ClinicalBERT, BioBert).
4. How to Evaluate the Performance and Limitations of a Clinical NLP Algorithm
의학 분야에서도 NLP는 애초에 대부분 General domain에서 먼저 진행된 연구를 기반으로 하기 때문에 특징과 단점도 공유합니다.
- 투명성 부족
- task-specific problem만 잘 해결함
- 일반화 성능을 위한 노력 필요
- 재생산성 좋음
다만, 의학 분야에서는 머신러닝 관련 연구가 엄청나게 활발하지는 않았기 때문에, 모델들의 성능과 이점을 비교하는 기준(벤치마크)가 별로 없었습니다.
테크니컬한 관점에서 the Biomedical Language Understanding and Reasoning Benchmark라는 Bio-medical text & task 관련 벤치마크가 최근에 도입되긴 했습니다.
이로 인해 약간은 (특히 본 논문에서 다루는 방사선 종양학 관련 커뮤니티에서) 기술 발전을 불러일으킬 수는 있을 것 같습니다.
물론, 의학분야의 특성상 clinical end-users는 이런 기술들의 디테일을 이해하기 힘들 가능성이 크긴 합니다만, 그래도 모델의 신뢰도를 위해 적어도 일반화 성능에 대한 보장이 필요하긴 합니다.
환자들은 의학적으로, 그리고 기술적으로 이해하지 못 할 것이고, AI 엔지니어라 할지라도 의학적인 이해는 하기 힘들 가능성이 큽니다.
때문에, 단순히 성능 지표 뿐만 아니라 모델의 작동 기제를 일반 User가 이해할 수 있게끔 제공하는 방법론들도 충분히 연구가 되어야 합니다.
(여전히 쉽지는 않지만 설명가능한 인공지능(XAI)의 주된 관심사 중 하나)
반대로, 의사들 또한 딥러닝 모델과 평가 메트릭에 대해서 익숙하지 않을 가능성이 큽니다. 실질적으로 딥러닝 모델이 의학계에 적용되더라도 최종적인 진단 결정권은 의사한테 있을 것이기 때문에 의사들이 이해할 수 있는 딥러닝 모델을 구축하는 것이 반 필수적이겠죠.
아무튼, 의학 분야 딥러닝에서 평가 기준이 되는 것은 보통 Accuracy, Recall, precision, F1 score 등이 있습니다.
클래스가 임밸런스할 경우 다수 클래스만을 예측한다면 Accuracy는 보통 높게 나오기 때문에 신뢰도가 낮은 경향이 없지 않아 있습니다(제일 간단하지만).
Recall같은 경우 위양성(False positive)를 높히는 경향이 있지만, 일반적으로 의학계에서는 False negative의 리스크가 너무 크기 때문에, 어느 정도 선호되는 메트릭이긴 합니다(물론 위양성 진단으로 인한 비용이 너무나도 큰 상황이라면 이 또한 조심스럽게 다루어야 하겠지만).
Precision은 positive predictive value, 즉 양성으로 판단한 사례들 중 제대로 판단한 비율을 뜻합니다. precision이 높으면 true positive 또한 많아지긴 하지만, False negative를 높히는 경우가 있기 때문에 '질병의 유무'를 판단할 때는 역시 조심해야 할 메트릭입니다(Recall과 반대에 있다고 봐도 무방).
F1 score는 Recall과 Precision을 적절한 비율로 고려한 메트릭.
How to Read Articles That Use Machine Learning: Users' Guides to the Medical Literature
(의학 관련 머신러닝 기법들을 접할 때 어떤 식으로 바라보아야 하는지 가이드라인을 제공해주는 연구 - 특히 모델을 비판적으로 평가하는 관점에서)
과적합(Overfitting)에 대해서 얘기해봅시다.
주어진 학습 데이터에 너무나 치중한 나머지, 새로운 데이터 셋에 잘 작동하지 않는 과적합 문제는 머신러닝의 고질적인 문제이자, 거의 대부분의 모델에서 피하고자 하는 요소입니다.
보통 파라미터가 많아지면 과적합 문제가 발생한다고 여겨지고 있는데요, 의학 분야에서는 여전히 통용되는 개념인 것 같습니다.
General Domain에서는 Transformer 관련 모델의 발달에 따라 위와 같은 "파라미터가 높을수록 과적합 가능성이 높아져 성능은 떨어질 수 있다"라는 생각이 적용되지 않는 분위기인 것 같습니다.
즉, 파라미터가 많아질수록 더 많은 데이터를 학습해 더 좋은 성능을 내곤 합니다.
(CNN, LSTM 계열과 다르게 Transformer 모델은 모델을 키우기 용이하고, 더 많은 데이터 학습에 유리한 경향이 있습니다.)
과적합에는 아래와 같은 요소들이 관여합니다.
- Regularization을 위한 (수많은)방법론들
- 적절한 데이터 스플릿(train,validation, test(hold-out),...)
- 평가 성능
- 데이터 타입
- 데이터 양
- 사용하는 아키텍처의 유형(CNN,LSTMs과 같이 inductive bias가 높은 모델인지, Tranformer처럼 inductive bias가 비교적 낮은 모델인지,...)
아무튼, 이런 일반화 성능을 결정짓는 과적합 문제는 해결하기 힘든 문제입니다.
negation detection(eg, "흉부에는 종양이 없다") task를 하더라도 이와 관련된 데이터가 꽤나 있어야 하며, 대장암 관련 태스크를 수행하려면 간암, 폐암이 아닌 대장암 관련 데이터가 충분히 있어야 합니다.
즉, 이러한 상황은 추후의 연구가 domain- and task-adaptive 방법들이 clinical NLP에도 널리 쓰여야 한다는 방향을 제시해줍니다.
그 외에도, 여러 데이터 셋에 평가를 진행한다할 지라도, 학습 데이터(혹은 나라)마다 인종, 사회적 지위 등이 편향되어 있기 때문에 임상 환경에 도입하기 힘들다든지, 각 병원이나 문서마다 EMR 등을 작성하는 양식이 다르다든지 하는 문제가 많기 때문에 학습 데이터(text, corpora)에 대해서도 깊은 주의를 기울여야 합니다.
gold annotated data를 이용해 모델을 학습하는 것도 굉장히 중요합니다.
하지만, 다른 분야와는 다르게, 주석처리에 전문지식이 필요한 만큼 manual data labeling을 하는 데에도 여러 문제가 있습니다.
가령, 방사선 치료에 대한 toxicity scores를 추출해 annotator의 신뢰를 평가하는 연구에서도 여러 문제가 있었습니다(증상이 있든 없든 같은 수치를 보였다거나..).
그렇기에 특정 데이터셋을 활용해 학습을 했더라도, 그 외의 많은 데이터셋(오픈 데이터든, 다른 annotator가 만든 데이터든)에 대한 평가도 병행되어야 합니다.
annotation 가이드라인도 충분히 작성되어야 하고요.
5. Applications of NLP in Oncology
본 단락에서는 여러 NLP 기법들 중 radiation oncology community와 관련된 부분만을 다룹니다.
NLP는 종양 및 치료 특성 추출을 통해 암 & 역학 관련 연구를 증진하는 데 쓰일 수 있습니다.
본래 cancer registries를 위해 데이터를 식별하고 추출하는 것은 거의 수작업으로 수행되고(SEER program), 그렇기 때문에 실수를 하거나 부적절한 정확도를 보이는 데이터를 다루게 될 수도 있습니다.
다만, NLP에서 암 환자에 대한 식별과 속성 추출은 생각보다 어려운 태스크입니다.
예를 들어서, 새로운 암을 진단하는 시스템을 사용한다면, 아래와 같은 요소들을 고려해야 합니다.
- 현재 활성화된 암에 대한 진단인지
- 과거 암에 대한 진단인지
- 환자나 가족과 관련하여 진단되어야 하는지
- Negation을 고려해야 하는지.
- 진단이 암을 고려해야 하는 수준인지, 아니면 결정지어야 하는 수준인지.
그렇기 때문에 보통 좋은 성능의 데이터 추출을 위해서 여러 개의 파이프라인을 구축할 필요가 있습니다.
암을 가지고 있는 환자를 식별하기 위해 EMR texts를 document-level에서, 혹은 환자의 EMR-record-level에서 분석한 여러 연구가 있습니다.
Document-level
- Validation of case finding algorithms for hepatocellular cancer from administrative data and electronic health records using natural language processing.
- Application of text information extraction system for real-time cancer case identification in an integrated healthcare organization.
- Pathologic findings inreduction mammoplasty specimens: A surrogate for the population prevalence of breast cancer and high-risk lesions.
- Development and validation of a natural language processing algorithm for surveillance of cervical and anal cancer and precancer: A split-validation study
EMR record-level
- Automated ancillary cancer history classification for mesothelioma
patients from free-text clinical reports.- Extracting and integrating data from entire electronic health records for detecting colorectal cancer cases.
또한, clinical free text로부터 암과 종양과 관련된 속성들을 추출하는 연구들도 많습니다(이를 이용해 데이터베이스를 구축하거나 cancer phenotyping을 구성하는 데 쓰일 수 있습니다).
여기서 말하는 cancer attributes는 아래와 같습니다.
- primary site
- tumor
- location
- stage
Pathology
- 생략
Radiology
- Automated identification of patients with pulmonary nodules in an integrated health system using administrative health plan data, radiology reports, and natural language processing.
- Automated annotation and classification of BI-RADS assessment from radiology reports.
특히, DeepPhe는 여러 NLP 방법들을 결합해 환자의 전체 EMR texts로부터 doument- & patient-level의 암(및 종양)에 대한 요약을 생성하고, 위에서 말한 cancer attributes(병리학적 관점에서)을 생성하는 오픈 소스 시스템 입니다.
흉부암, 난소암, 흑색종 등에 대한 태스크를 수행할 수 있다고 합니다.
treament나 adverse event의 결과에 대한 정보를 추출하는 것도 연구나 환자 케어에 도움이 굉장히 되고, 연구 또한 활발하게 진행되고 있습니다.
다만 연구자들마다 사용하는 언어도 다르고, 약자도 활발하게 사용하며, 여러 용어들이나 tex t 구조 등이 다르기 때문에 어려운 태스크입니다.
특히, 환자 케어가 변경되더라도 완벽하게 서류화되지 않는 경우도 많구요.
거의 수십번 반복해서 말한 것 같긴 한데..
2019년 7월에 수행된 연구 Assessment of deep natural language processing in ascertaining oncologic outcomes from radiology reports는 CNN과 radiology reports를 활용해 cancer output을 식별하는 연구를 수행했습니다.
1112개의 폐암 사례에서 14,230개의 radiology reports가 라벨링 됐으며, F1 score는 림프종의 경우 0.55, 다른 암의 경우 0.88까지 이르렀습니다.
clinical relevance 연구도 수행.
특히, 이 모델을 이용할 경우 사람이 annotation을 수행하는 데 기존의 (1인당) 6개월 걸렸던 소요 시간이 NLP를 사용할 경우 10분까지 줄어든 결과를 보였습니다.
다른 연구로는, EMR 내 creation of oncologic history를 위해 clinical timeline creation을 진행한 연구들도 있습니다.
- SemEval-2016 Task 12: Clinical TempEval.
- SemEval-2017 Task 12: Clinical TempEval.
- Neural architecture for temporal relation extraction: A Bi-LSTM approach for detecting narrative containers.
- Representations of time expressions for temporal relation extraction with convolutional neural networks
- Neural temporal relation extraction.
위에서 대략적으로 언급한 연구들을 다같이 활용하면 종합적인 암-케어 요약을 개인(혹은 인구집단)레벨에서 제공해 더 낫고, 효율적인 환자 케어가 가능해지리라 생각합니다.
마지막으로, automated clinical trial matching을 위한 NLP도 많이 연구됐습니다.
주로 clinical trial protocols으로부터 eligibility criteria를 추출하거나, patient specific eligibility를 평가하는 쪽에 집중했습니다.
eligibility criteria
- Automated classification of eligibility criteria in clinical trials to facilitate patient-trial matching for specific patient populations.
patient specific eligibility
- 연구 : Increasing the efficiency of trialpatient matching: Automated clinical trial eligibility pre-screening for pediatric oncology patients.
- Automatic trial eligibility surveillance based on unstructured clinical data.
NLP 기반 trial eligibility prescreening 알고리즘에 대해 평가를 진행하고, 작업량 감소에 대한 평가를 진행한 연구는 알고리즘을 사용할 경우 trials에 적합한 환자를 식별하는 작업량은 85%정도 감소했고, trials을 식별하는 작업량은 90%가량 줄어들었다고 합니다(위의 연구 ).
특히, 이 연구는 screening tool에서는 recall이 precision보다 중요하다는 것을 보였습니다(직관적으로는 당연?).
특히, 위에서 언급한 cnacer attribute extraction도 부분적으로 clinical trial matching & screening을 자동화하는데 도움이 될 수 있습니다.
Deep 6 AI or IBM watson for Clinical Trial Matching처럼 상업적으로 출시된 알고리즘도 있다.
특히, 위와 같이 상업화된 제품이라면 여러 인구 집단에 대한 다층적인 성능 평가가 같이 제공될 필요가 있다.
6. The State of NLP Research Specific to Radiation Oncology
여전히 radiation oncology에 관한 NLP 기법들은 너무나 적습니다.
환자가 radiation 관련 치료를 받았는지, 받지 않았는지 판단하기 위한 information extraction tools에 대한 연구는 있긴 합니다만, 방사선 치료의 종류나 목적의 변동성(or 다양성, variability)을 고려했을 때 너무 적은 가치를 갖습니다.
현존하는 Radiation oncology 기반 NLP 연구들은 치료 계획과 관련된 naming을 정규화하는 데 초점을 두고 있습니다.
가령, Syed et al은 불규칙한 physician-dtermined labels(전립선, 폐 관련)을 TG-263 standardized nomenclatures(명명법)으로 매핑하는 연구를 진행했습니다(Syed et al, Integrated natural language processing and machine learning models for standardizing radiotherapy structure names).
혹은 nonstandardized treatment sites들로부터 standardized treament sites를 추출하는 확률적 언어 모델을 연구했거나...
- Walker et al, Development of a natural language processing tool to extract radiation treatment sites
최근에는 single institution's unstructured radiation therapy로부터 toxicity data를 추출하는 cTAKES(Apache Clinical Text Analysis Knowledge Extraction System) 모델에 대한 평가가 진행됐습니다.
Hong JC et al, Natural language processing for abstraction of cancer treatment toxicities: Accuracy versus human experts
몇 몇 양성 증상의 경우 인간보다 좋은 성능을 보이긴 했으나, 음성 증상에 대한 texts의 경우 좋지 못한 성능을 보였습니다.
그 외에도 NER(Named Radiation Theraphy)나 RE(Relation Extraction) 관련한 최근 연구도 NLP 모델의 데이터 추출 능력과 정규화 능력에 대한 잠재력을 보여줍니다.
High Performing deep learning model for NER & RE
- Bitterman et al. Extracting radiotherapy treatment details using neural network-based natural language processing.
- Bitterman et al. Extracting relations between radiotherapy treatment details.
7. Potential Efect of NLP in Radiation Oncology Research Efforts
암 치료에 초석임에도 불구하고, 좋은 퀄리티의 방사선 치료 정보를 담고 있는 large database는 별로 없습니다.
SEER program에서 나온 데이터도 여러 문제로 삭제됐다고 하고..
The National Cancer Database도 방사선 치료에 관한 데이터셋을 포함하긴 하나, 이는 세분화도 부족할 뿐만 아니라 병원들 중 일부 병원의 데이터만을 포함하고 있습니다.
추가적으로, 이제 점점 전이성 질병들을 달고 사는 사람들이 많아짐에 따라 일련의 방사선 치료가 더더욱 빈번해지고 있고, 이런 치료가 결과에 어떻게 영향을 끼치는 지에 대해 이해하는 것도 너무나 중요해졌습니다.
이런 저런 필요에 따라 The American Society for Radiation Oncology와 " for Clinical oncology는 더욱 철저한 암-관련 정보 데이터베이스를 구축할 것이라고 밝혔습니다(for new natioanl cancer registry).
의학 분야에서는 자원이 한정된(resource-limited) 환경이기 때문에 기존에 존재하는 registires를 augment하고 새로운 것을 만드는 데에도 NLP가 큰 역할을 할 수 있습니다.
가령, 이 데이터를 이용해 Radiation therapy information을 (SEER program으로부터) 추출하고, 이를 사용한다든지..
이를 통해 역학과 희귀 종양의 결과에 대해 이해하는 데에도 큰 도움이 될 것입니다.
(현재 이에 대한 데이터는 별로 없으므로)
NLP는, dose-fractionation, modality, technique, detailed toxicity, outcomes data 등에 대한 요소를 다룬다면 방사선 업계쪽에도 널리 도움이 될 것입니다.
패스..
8. Outstanding Challenges of NLP in Radiation Oncology
임상 환경에서 NLP를 사용하는 데 있어서 장애물은 아래와 같습니다.
- 사용가능한 데이터가 적다(특히 gold annotated dataset).
- 동의어, 전문용어, 약어, 오타 등이 많다(데이터나 도메인 자체에).
- 의학 전문가가 별로 없다(NLP community에).
애초에 (gold annotated clinical text) publicly available corpora는 거의 없는데,
심지어 radiation oncology clinical doumentation에 관한 publicly available corpora는 없다고 합니다.
아래는 위에서 언급한 gold annotated clinical text에 관한 publicly available corpora
gold annotated clinical texts dataset
11. DeepPhe: A natural language processing system for extracting cancer phenotypes from clinical
records.
63. SemEval-2015 Task 6: Clinical TempEval(SemEval 2015).
93. SemEval-2016 Task 12: Clinical TempEval(SemEval-2016).
94. SemEval-2017 Task 12: Clinical TempEval(SemEval-2017).
SemEval : Proceedings of the 11th International Workshop on Semantic Evaluation
gold annotated clinical texts dataset
118. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text.
119. SemEval-2015 task 14: Analysis of clinical text(SemEval 2015)
120. DDiscovering body site and severity modifiers in clinical texts.
121. Evaluating the state of the art in coreference resolution for electronic
medical records.
122. Towards generalizable entity-centric clinical coreference resolution.
123. Evaluating the state-of-the-art in automatic de-identification.
124. Recognizing obesity and comorbidities in sparse data.
125. Automated systems for the deidentification of longitudinal clinical narratives: Overview of 2014 i2b2/UTHealth shared task Track 1.
126. De-identification of psychiatric intake records: Overview of 2016 CEGS N-GRID shared tasks Track
127. A shared task involving multi-label classification of clinical free text.
128.Towards comprehensive syntactic and semantic annotations of the clinical narrative.
물론, 위의 public corpora의 labeled data를 이용하면 일부는 radiation oncology로 번역해 사용할 수 있지만(disease site, signs, sympotoms, comorbidities 등),
radiation oncology 관련 분야의 독특한 용어나 전문용어들은 이런 other medical domains에는 좀처럼 나타나지 않습니다(gross/clinical/planning tumor volume, boost, point A/B, Gy 등).
아무튼, 위와 같이 oncology-specific corpora가 부족해서 생기는 문제는 아래의 federated learning(연합 학습)(?)을 이용해서 일부 개선할 수는 있다고 합니다.
Federated Learning
129. Federated learning of predictive models from federated Electronic
Health Records.
130. FADL: Federatedautonomous deep learning for distributed electronic health record.
131. Two-stage federated phenotyping and
patient representation learning.
132. Communication-efficient learning of deep networks from decentralized data.
133. Federated learning: Strategies for improving communication efficiency.
134. Patient clustering improves efficiency of federated machine learning to
predict mortality and hospital stay time using distributed electronic medical records.
135. LoAdaBoost: Lossbased AdaBoost Federated Machine Learning on medical data.
nonclinical texts(혹은 not-radiation-specific texts)를 학습한 pre-trained language model을 이용하는 경우
39. BERT: Pre-training of deep bidirectional transformers for language understanding.
40. Deep contextualized word representations.
136. Contextual string embeddings for sequence labeling.
논문 저자들은 아래와 같은 문제점과, 미래 방향들도 길게 제안하고 있습니다.
- naming이나 convention이 병원, 데이터, 의사들마다 다르기 때문에 이를 통합하려는 노력이 필요하다.
- extraction이나 strandardization이 필요하긴 하지만, 굳이 NLP 기반 방법을 사용할 필요는 없다.
- 즉, 간단한 rule-based 방법으로도 충분히 파싱할 수 있다.
- Synoptic reporting이라거나..
- 물론 방대한 양을 빠르게, 효율적으로, 정확하게 처리하는 건 NLP기반 방법이 아무래도 제일 잘 하긴 할 것.
9. How NLP May Transform Clinical Practive in the Future
- pass
