DRIT


기존의 I2I Translation 모델들은 아래와 같은 한계점이 존재합니다.
- 데이터 수집이 어렵다.
- single input에 대해 다양한 output이 존재할 수 있다.
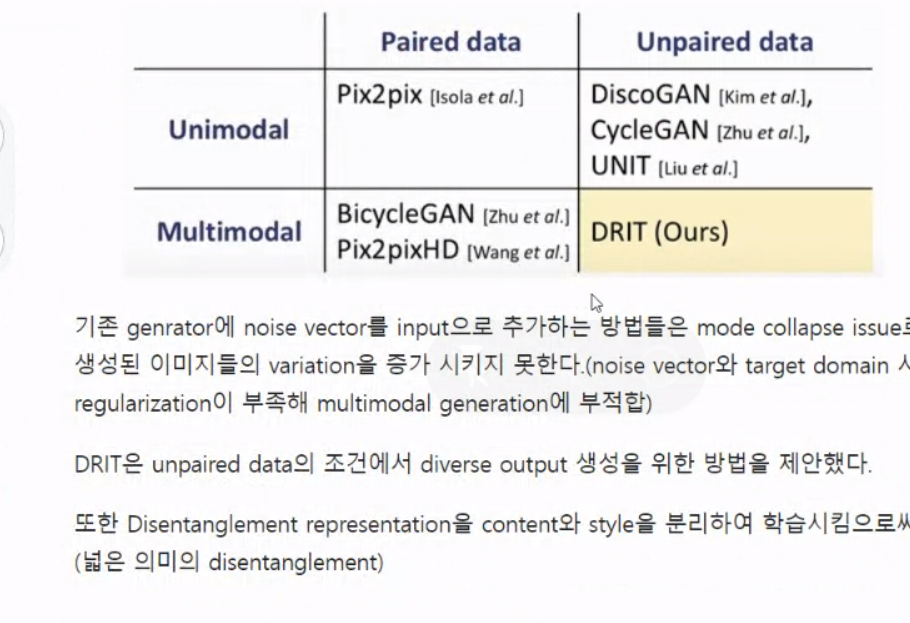
해당 모델은 Unpaired data의 조건에서 다양한 output 생성을 위한 방법을 제안합니다.
대략적인 모델 구조는 아래와 같습니다.
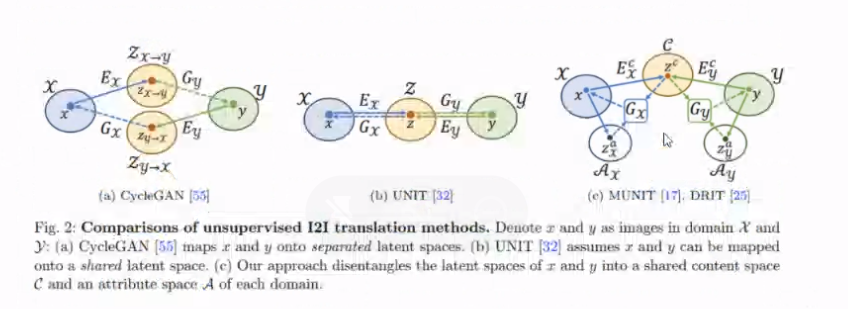
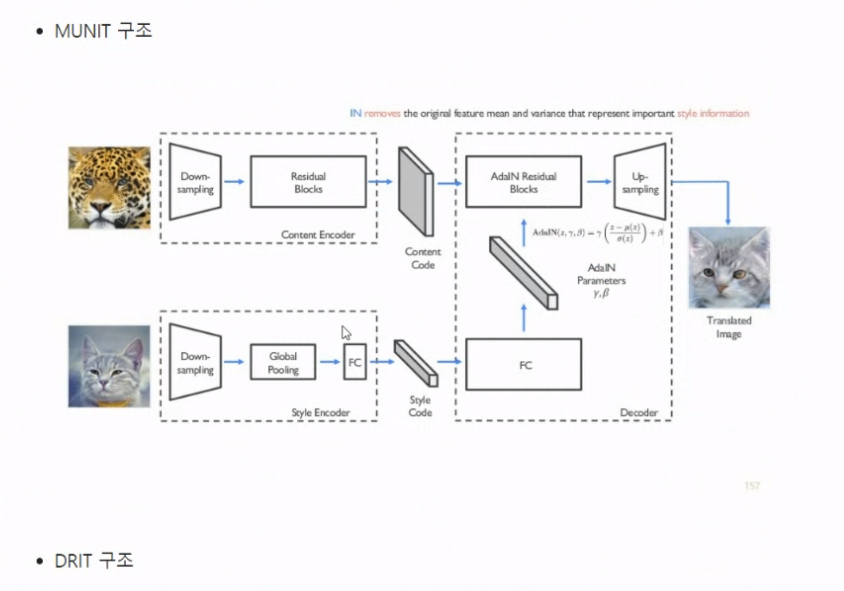
MUNIT과 DRIT은 구조가 유사한데, input image를 content와 syle로 구분해서 임베딩한다는 점이 바로 그것입니다.
DRIT은 Weight Sharing을 먼저 진행하게 됩니다.
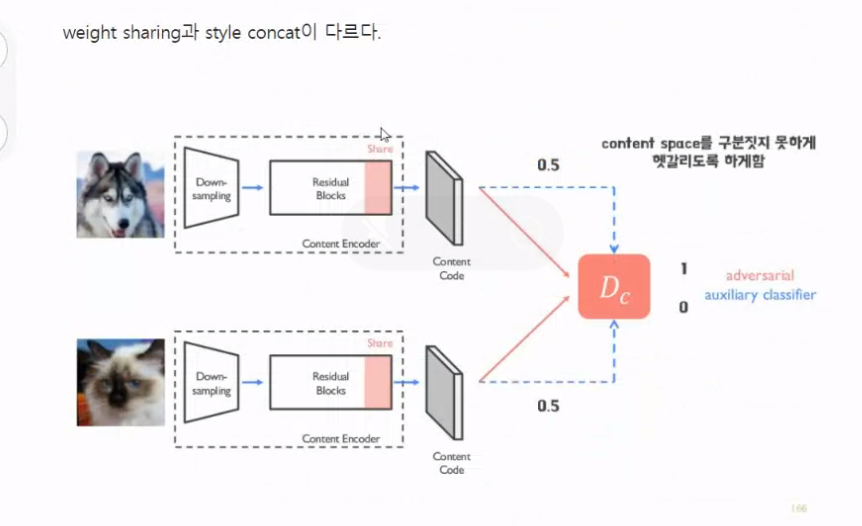
- 추가적인 분류기를 도입해 disentanglement를 수행합니다.
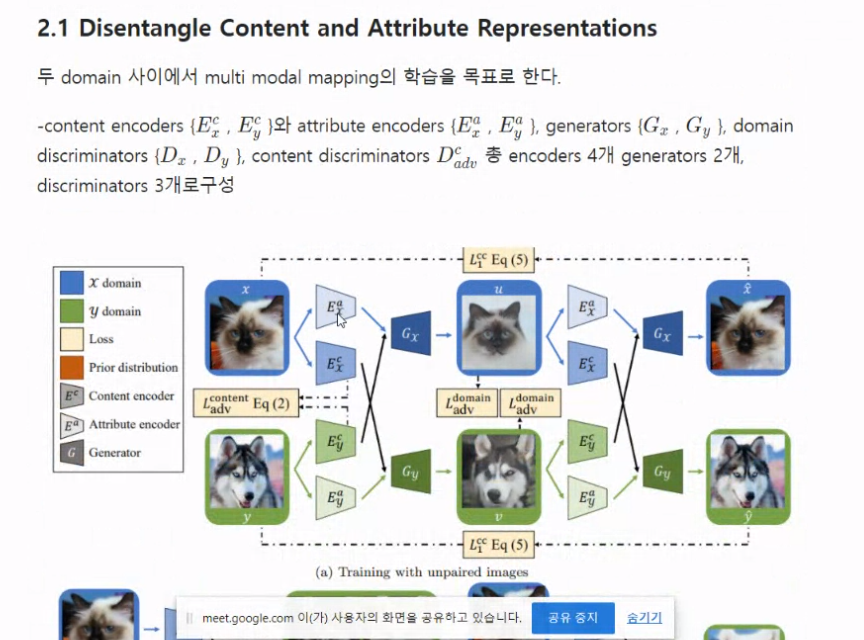
: Encoder
: 도메인
Content Encoder와 Attribute Encoder 총 4개가 존재합니다.
--
도메인 를 기준으로 살펴봅시다.
생성자는 우선 style과 content embeddings을 받아서 이미지를 합성하게 됩니다.
- 특히 이 때, x에서 style을 받고 y에서 content를 받아서 생성을 하게 됩니다.
content 판별자는 두 도메인 사이의 콘텐츠 표현을 구분하게끔 학습됩니다.
즉,
콘텐츠 판별자와 가중치 공유를 disentanglement를 위해 활용합니다.
즉, 공유된 정보들이 같은 공간에 매핑되도록 강제적으로 가중치 공유를 하게 되고, 같은 공간에 매핑되더라도 동일 정보를 인코딩할 지는 모르므로 이런 매핑 벡터들이 어떤 도메인에서 나온 것인지 구분하는 content discriminator를 제안한 것입니다.
반대로 이와 반대로, 도메인을 구분할 수 없도록 인코더는 학습합니다.
도메인을 구분할 수 없다는 것은, 두 도메인 사이의 공유된 정보를 동일 공간 내에 인코딩이 잘 됐다라는 것입니다.
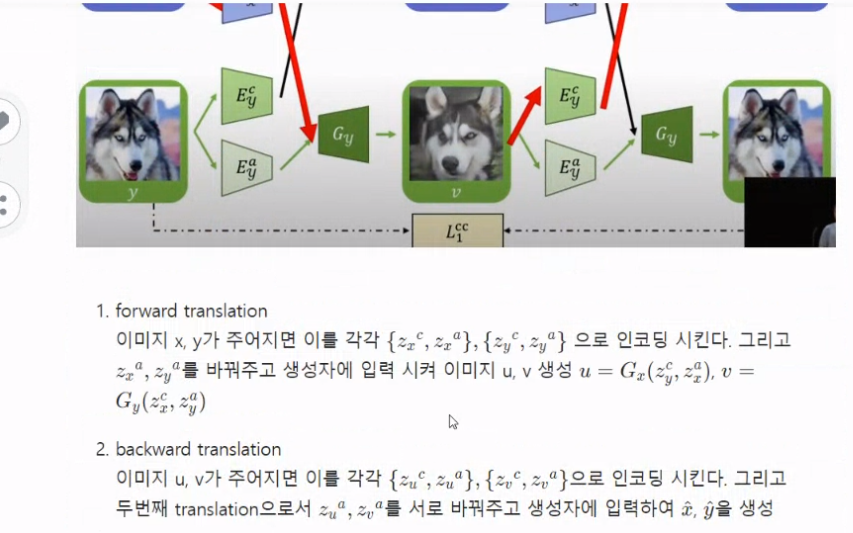
뭐 왼쪽이 forward, 오른쪽이 backword..
Loss

원본 이미지와 생성한 이미지를 비교하게 됩니다.
이 때, 생성 이미지는 두 도메인 사이에서 style, attribute를 잘 뽑아내 생성한 친구들입니다.
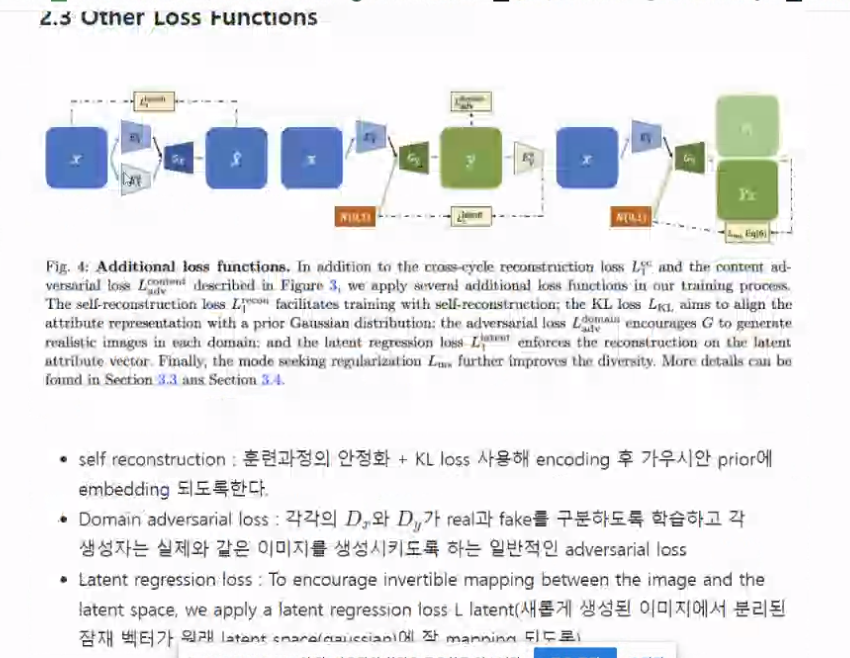
다른 loss도 존재합니다. (self reconstruction)
- 다양한 이미지 생성을 위한 self-reconstrution..)
- 가우시안에서 추출한 latent vector가 image latent vector가 비슷해지도록 loss 추가(latent regression loss)
이미지 다양하를 위한 Mode Seeking Regularization

x대신 이미지 I를 투입하고, 생성된 이미지 간 거리가 멀도록(대신 잠재벡터는 공유하도록)
즉, 조그마한 변화만 생겨도 이미지가 많이 변화가게끔 규제를 주게 됩니다.
