[논문리뷰/정리] Image-to-Image Translation with Conditional Adversarial Nets(pix2pix)
Generative Model
Pix2Pix
먼저, image-to-image translation은 무엇을 뜻할까요?
Image 분야에서 Translation은 특정 이미지의 '이동'을 뜻하기도 합니다만(Image Transformation),
Image-to-Image Translation은 이미지를 입력으로 받아 또다른 이미지를 출력으로 반환하는 태스크들을 주로 뜻합니다.
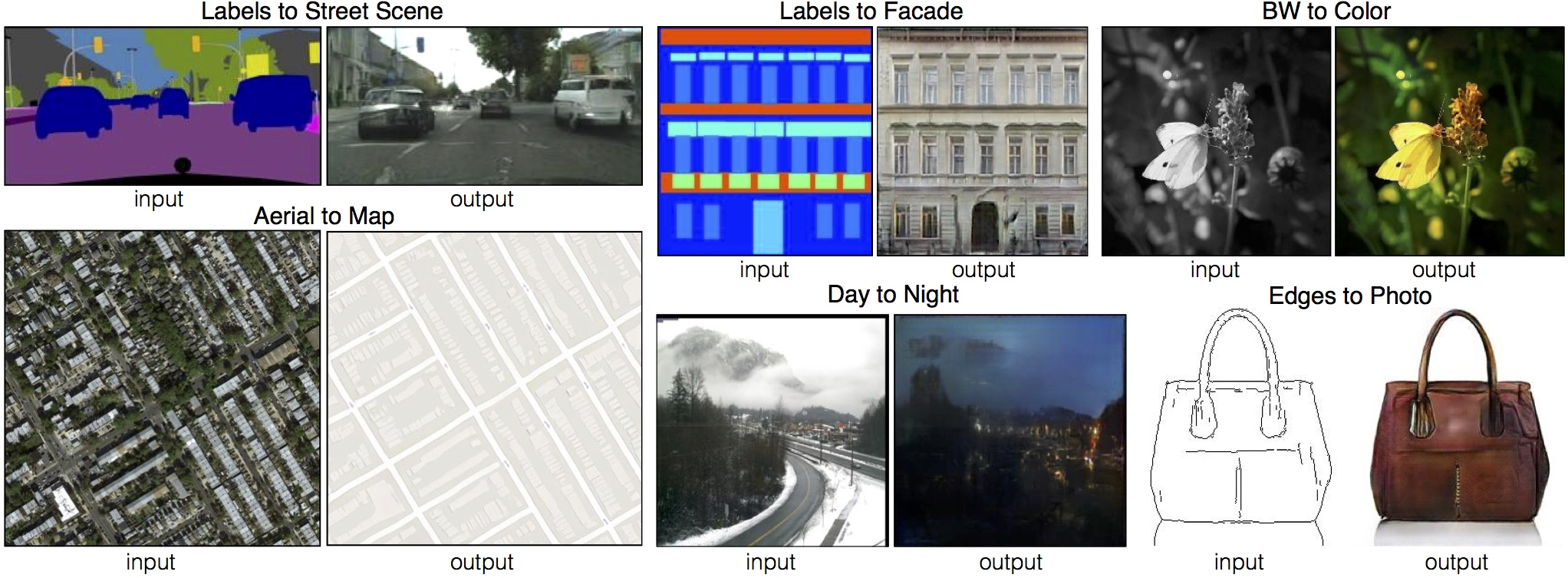
기존에는 이런 task를 위해 각기 다른 모델이 필요할 뿐더러 리서쳐가 직접 manual한 조작을 해주는 과정이 필요한 모델이 많았습니다.
하지만 현대 들어 딥러닝이 발전하면서 딥러닝 아키텍처를 활용해 비교적 direct하게 이미지 간 도메인 변화 task를 할 수 있게 되었습니다.
Introduction
보통, Image 분야에서 CNN을 사용하려면 직접 Loss-function을 정의해주어야 합니다.
가령, 예측 이미지의 픽셀과 ground truth 이미지의 픽셀 간 Euclidean distance()를 Loss함수로 단순하게 정의한다든가 말이죠.
다만, 이렇게 단순하게 정의한다면 결과 이미지의 퍼포먼스가 좋지 못한 문제(blurry, not semantic)가 생길 수 있습니다.
L2 loss의 경우 이상치에 과하게 반응(이상치 -> loss ↑↑)하는 경향이 있어, loss함수를 낮추려면 최대한 값들을 골고루 퍼지게 해야 합니다.
(blurry의 원인)
자세한 건 L1 norm vs L2 norm참고
loss function을 직접 정의해주는 것 또한 manual한 요소가 들어가기에 최적의 함수를 찾기 힘든 문제도 존재하구요.
GAN은 이런 문제를 해결합니다.
GAN은 두 이미지 간 차이를 loss함수로 정량화하는 게 아닌, Discriminator를 이용해 판별하고, 그로부터 feedback을 받아 새로운 이미지를 생성하게 됩니다.
CGAN
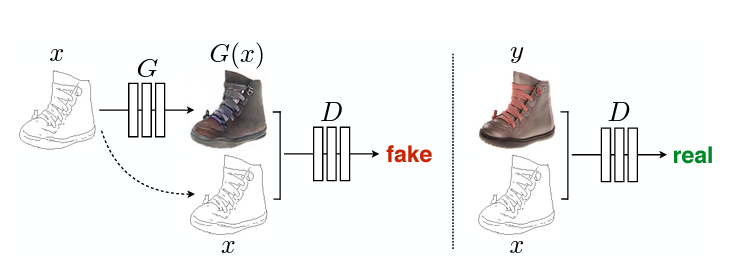
(그림은 cGAN입니다. 기존의 GAN과 다르게 는 condition 를 받아 생성하며, 또한 condition 를 받아 판별하게 됩니다 - 따지고 보면 판별자는 를 안 받아도 판별 자체는 할 수 있지만, 너무 불공평하니까 ㅎ..).
본 글에서 Image-to-Image Translation에 적합한 cGAN을 기반으로하며 다양한 task에서 좋은 결과를 보이는 프레임워크 pix2pix를 다룹니다.
Image-to-Image Translation은 보통 GAN의 변형 중 CGAN(Conditional GAN)을 기반으로 합니다.
가령, 위 그림에서는 edge를 조건으로 받아 실제 이미지를 생성하고, 판별자 또한 이 edge와 생성 이미지를 받아 판별하면서 모델을 발전시키게 됩니다.
: Generator
: Discriminator
: input image
: output image
: latent vector
를 로 변환하는 Translation이라고 가정합시다.
가 하나의 Train data pair입니다.
즉, 와 를 비교해야 합니다.
CGAN의 손실함수는 위와 같습니다.
위 식에서 보다시피 최적의 생성자 를 얻기 위해 생성자 는 위 loss 함수 를 최소화 하는 방향으로, 판별자 는 최대화하는 방향으로 학습을 진행합니다.
단, 위의 loss를 단순히 사용하기 보다는 L1, L2 Norm과 같은 traditional loss를 추가해 사용한다면 조금 더 나은(즉, 덜 블러리한) 이미지를 생성할 수 있게 됩니다.
위 식은 에 관한 식입니다.
즉, 판별자 에 대해서 사용하지는 않고, 단지 생성자 가 생성 이미지를 타겟 이미지와 가까워지게끔 추가한 LOSS이라 할 수 있습니다.
다만, 아마 본 논문에서도 가 더 좋다고 판단해, 최종적인 loss를 아래와 같이 정의합니다.
생성모델은 사실 latent vector 가 없어도 의 매핑을 학습할 수는 있습니다.
다만, 가 없다면 다양한 매핑을 생성할 수는 없겠죠(는 deterministic).
생성 이미지에 영향을 주기 위해 쓰이기 때문에 잠재 벡터 를 random noise vector라고 부르기도 합니다.
다만, 기존 GAN에서는 를 단지 Gaussian Distribution에서 샘플링되는 잠재 벡터로 가정하고 학습을 진행했는데, 이처럼 했을 경우 본 실험에서는 입력된 노이즈가 무시되면서 학습되는 현상이 일어났습니다.
이를 해결하기 위해 pix2pix의 저자들은 train, test time에 dropout을 적용해 노이즈를 부여했습니다.
"Instead, for our final models, we provide noise only in the form of dropout, applied on several layers of our generator at both training and test time"
Architecture
Generator
UNET
pix2pix 연구에서 Generator로는 인코더-디코더 구조에 스킵커넥션이 추가된 U-Net을 사용합니다.
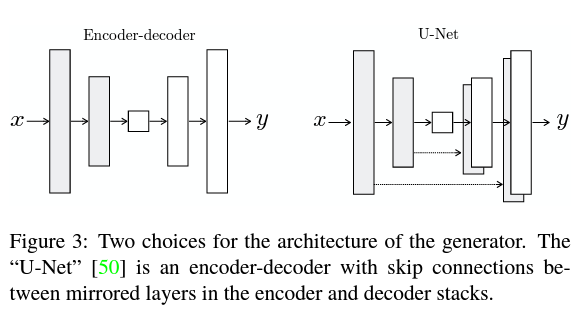
즉, 인코더와 디코더가 대칭적으로 연결되어 있습니다.
만약, skip connection을 사용하지 않는다면 어떻게 될까요?
입력 를 인코더로 단순히 압축하고, 압축된 벡터를 다시 디코더로 복원해 를 만들 경우, 굉장히 핵심적인(global) 정보만 남게 됩니다.
즉, 디테일한 정보(fine)는 유지하기 쉽지 않은 것이죠.
그래서 U-Net은 skip connection을 (대칭적으로) 추가해 이 경로를 통해 detail(fine)한 부분 또한 전달할 수 있게 해줍니다.
U-Net 심화
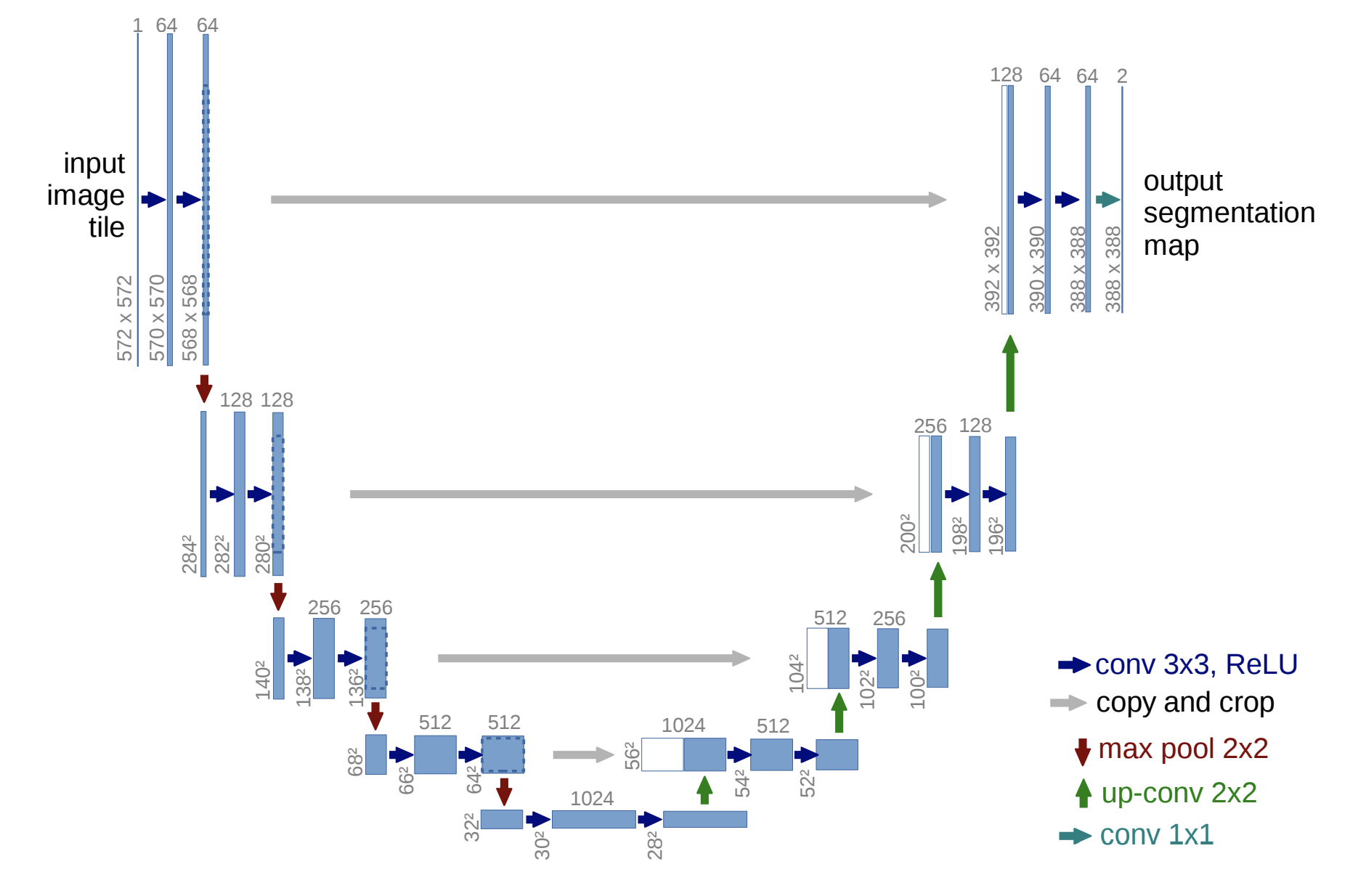
U-NET은 그림에서 보다시피 대칭구조로 되어있습니다.
이 때, U-NET은 이미지의 전반적인 context 정보를 얻기 위한 네트워크인 Contracting path와 정확한 지역화(Localization)을 위한 네트워크인 Expanding path로 이루어져 있습니다.
위 구조의 좌측 부분이 핵심적인 부분, 포괄적인 부분을 포착해 나가는 contracting path입니다.
또한 위 구조의 우측 부분은 expand path라 해, 이미지의 세밀한부분과 localization을 책임지는 부분입니다(디테일한 결과를 생성해야 하므로).
이 때 사용할 세밀한 정보가 바로 skip-connection을 통해 주어지게 됩니다(레이어가 깊기 때문에 어디선가 받지 않는 이상 세밀한 정보는 잘 남지 않습니다 - 아래 참고)
얕은 layer의 경우 조금 fine(local)한 정보를 담고 있고, 깊은 layer의 경우 corase(global)한 정보를 담게 됩니다.
이는 아래 그림으로 정확히 나와 있으며, CNN의 계층 구조와 유사합니다.
출처 : https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a
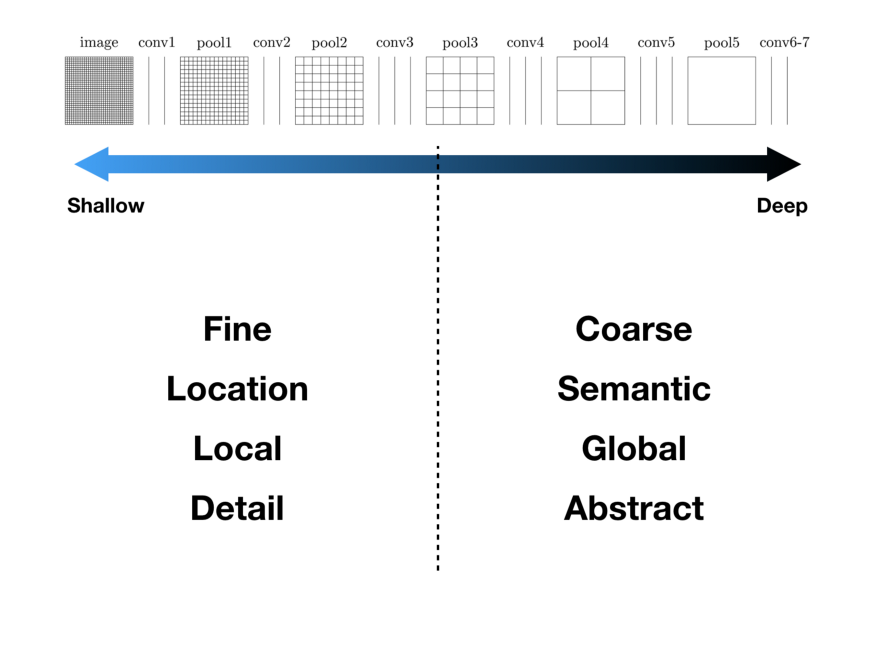
이러한 구조를 통해 정보 손실을 낮추고, 기존의 Localization(details, fine)과 Context(semantic, global)의 trade-off 관계를 해결할 수 있게 됩니다.

인코더 디코더 구조에 스킵커넥션을 추가할 경우 조금 더 좋은 생성 성능을 보이게 됩니다.
Discriminator(PatchGAN)
pix2pix2의 판별자로는 PatchGAN을 사용합니다.
생성자 는 판별자 를 속이는 게 목적입니다.
하지만, 이 목적만을 위해 학습한다면 사람이 인식하기에 품질이 좋지 못한 이미지를 생성하게 될 수도 있습니다.
PatchGAN은 이러한 문제를 약간 해결해줍니다.
그 이전에, 의 성질을 간단히 알아봅시다.
 )
)
위에서 볼 수 있다시피, L1 loss만을 사용할 경우 이미지의 Low-frequency 성분들을 잘 검출해내는 특징을 지닙니다.
이미지에서의 Frequency란
한 마디로 픽셀 변화의 정도입니다.
즉, 사물에 대해서는 사물 내에서는 색 변화가 크지 않기 때문에 low-frequency라 할 수 있고, 사물 경계(즉, edge)에서는 색이 급격하게 변하기 때문에 high-frequency라 할 수 있습니다.
L2 loss를 사용하면 더 blurry하겠죠?
그나마 L1 loss라 저정도입니다.
즉, L1 loss를 사용할 경우 blurry하지만 low-frequency 성분들을 잘 검출해내므로, 이는 그대로 두고 Discriminator에서 high-frequency의 검출을 위한 모델링을 진행하게 됩니다.
또한 이를 위해서는 이미지 전체가 필요 없고 local image patch를 사용해 판별을 진행해도 상관 없습니다.
high-frequency, 즉 디테일한 부분을 파악하는 데에 전반적인 이미지는 필요 없으니까요.
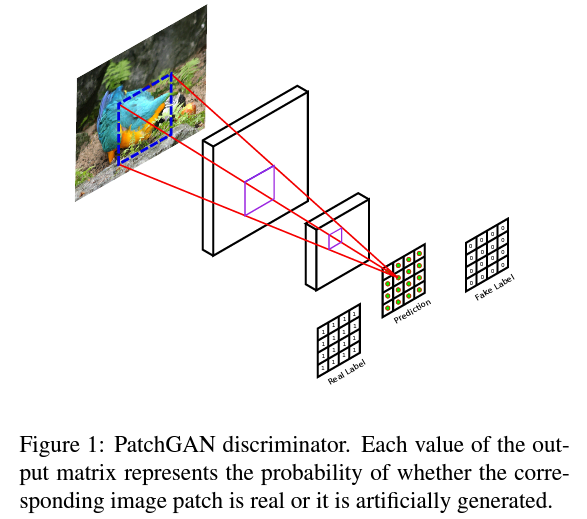
PatchGAN 심화
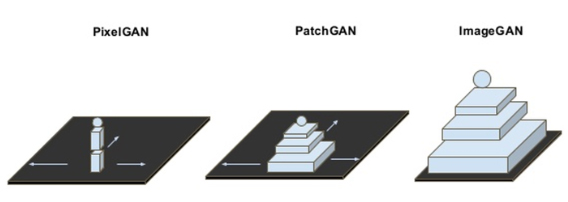
- ImageGAN : 일반적인 GAN은 이미지 전체에 대한 진위 여부를 판단합니다.
- PatchGAN : cGAN에서는 종종 PatchGAN을 사용하게 되는데, 이 때는 사이즈의 이미지 패치 단위에 대한 진위 여부를 판단하게 됩니다.
- PixelGAN은 이미지 픽셀 단위에서 진위 여부를 판단합니다.
이는 모두 GAN에 대한 얘기이며, 아래에서 (Classification, Regression을 위한) 일반적인 CNN을 사용하는 아키텍처를GAN과 비교해봅시다.
| CNN | Conditional GAN |
|---|---|
| - 픽셀 단위의 비교(classification, regression)으로 문제를 해결 - 각 출력 픽셀들은 다른 픽셀들에 대해 독립적 | - Structure loss를 사용해 목표 이미지와 출력 이미지의 다름에 대해 핸디캡을 준다 - Discriminator로 종종 PatchGAN을 사용 |
여기서는 PatchGAN에 대해 간략히 개조식으로 정리하고 넘어가겠습니다.
- 기존의 GAN은 이미지 전체를 보고 가 판단하기 때문에, 결과 이미지에 블러(Low-frequency)가 껴서 나타날 수 있습니다(만 사용하는 것보다는 낫습니다만).
- 왜냐면, 전체적인 이미지만 그럴듯하게 만들면 될 뿐, 사물의 디테일들을 디테일하게 만들 필요가 없습니다.
- 그래서 전체 이미지에 대한 (Low-frequency)를 에게 맡기고, (High-frequency)의 성분들을 이 맡는 것입니다.
- 그 High-frequency를 추출하기 위해 이미지들을 잘게 잘라서 에게 판별을 맡기는 것이구요(전체 이미지를 보고 가 판단한다면 생성 이미지가 blurry 해지니까).
단, 아래와 같은 가정이 필요합니다.
- patch의 직경보다 더 멀리 있는 픽셀들은 서로 독립이라 가정합니다.
- 다만 마르코프 개념이 쓰이므로 여기서는 패스 ^^..
Experiments

위와 같이 Input segmentation이 cGAN의 조건으로 주어지게 됩니다.
Input이랑 Condition을 나누는 건 크게 의미가 없어서, 그냥 보통 Condition을 Input으로 퉁치곤 합니다.





너무 많이 비어있으면 안 된다.
급 마무리
Ref
https://velog.io/@tobigs16gm/Image-Translation-pix2pix-CycleGAN
https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a
https://arxiv.org/abs/1611.07004

좋은 글 감사합니다. ^^