[간단정리]Adversarial Self-Supervised Contrastive Learning(NIPS 2020)

Paper: https://proceedings.neurips.cc/paper/2020/file/1f1baa5b8edac74eb4eaa329f14a0361-Paper.pdf
- (2020년 기준) 현존하는 적대적 학습(adversarial learning) 방법들은
- 특히, semi-supervised adversarial learning 또한 여전히 class label을 필요로 함.
- 본 연구는 self-supervised contrastive learning framework를 제안하는데, 이로부터 labeled-data 없이 적대적 학습을 진행해 DNN의 robustness를 강화할 수 있게 된다.
- 구체적으로는, 특정 데이터 샘플의 augmented-version꽈 (instance-level에서의) adversarial sample과 유사도를 늘리는 방향으로 학습을 하게 됨.
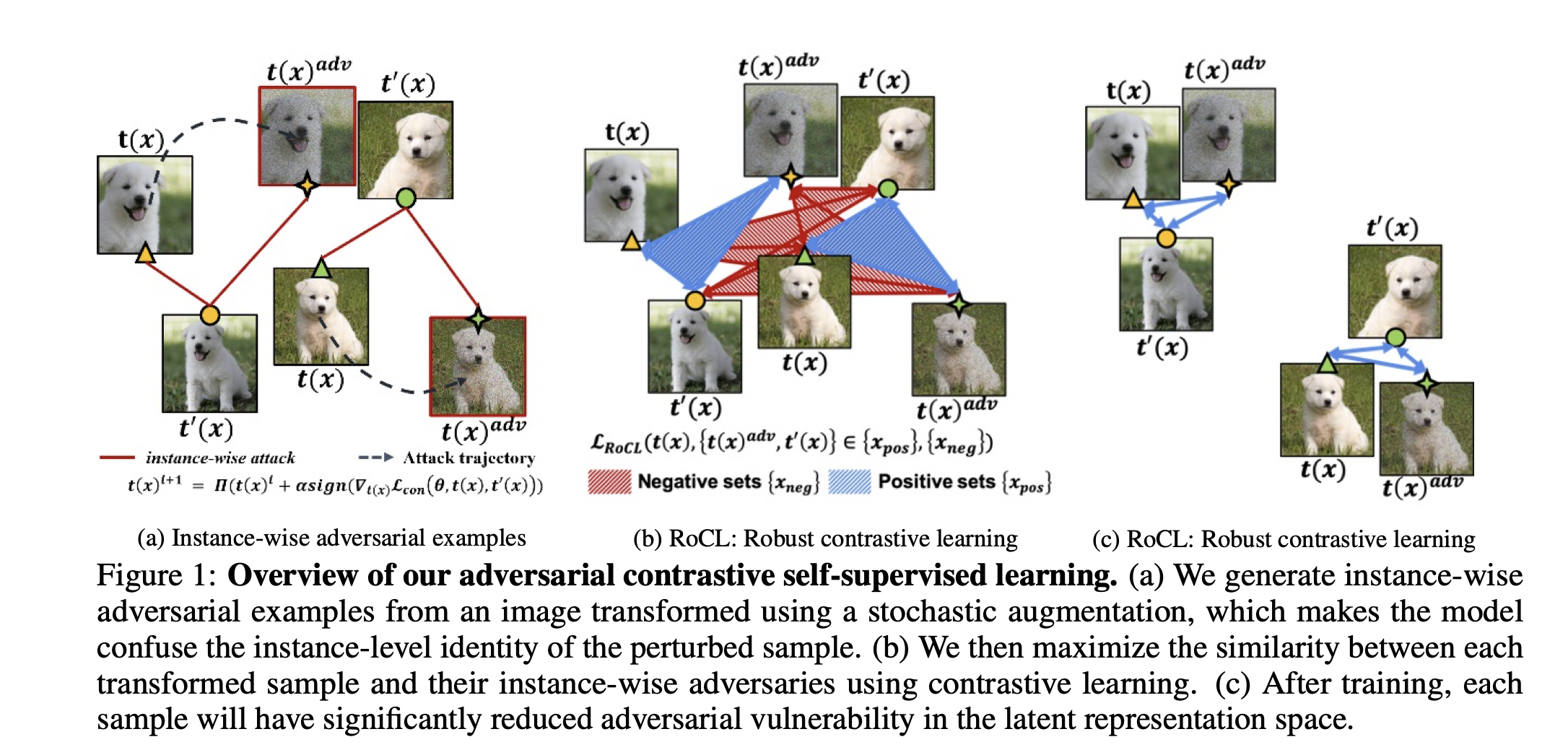
Contribution
- 새로운 instance-wise adversarial perturbation(don't require any labels)
- representation space의 (적대적 공격에 대한) 취약성을 완화시키는 adversarial self-supervised learning 방법 제안
- supervised adversarial learning 방법에 필적할만한 성능과, fine-tuning을 사용할 경우 더 좋은 robustness 보장.
- 일반적으로 DNN의 (Noise/adversarial attack에 대한) robustness와 clean sample에 대한 classification accuracy는 trade-off 관계에 있음.
- 어쨋든 일종의 regularization을 주는 것이기에 피하기 힘든 단점이기도 하고..
- 이런 trade-off 관계는 노이즈에 강한 robust network를 실질적으로 활용하기 힘든 이유이기도 함(아무리 노이즈에 강한들, 주어진 task를 못하면 소용이 없지 않은가).
- 다만 저자가 제안하는 방법과 지도적 방법을 결합할 경우 clean accuracy 하락 없이 robustness를 더욱 늘릴 수 있었다는 것. --> 아주 상당한 결과

-