[간단정리]Towards Sample-efficient Overparameterized Meta-learning(NIPS 2021)
메타 러닝에서 파라미터 개수를 얼마나 늘릴 수 있을까?
Paper: https://openreview.net/pdf?id=-KU_e4Biu0
- 머신러닝에서 궁극적인 목표는 데이터가 적을 때도 잘 작동할 수 있는 generalizable model을 만드는 것.
- 이를 위해서 파라미터 개수를 과하게 늘리는 overparameterization이 좋은 역할을 할 수 있다고 생각함.
- 특히, 본 연구에서는 메타러닝을 위한 overparameterization을 다룰 것(데이터가 적기에 파라미터도 작아야 된다는 과거의 통설과 배치될 수 있음).
- (1) 학습을 위한 태스크들이 주어졌을 때, downstream 태스크에 알맞는 optimal linear representation을 찾을 수 있을까?
- 이는 일종의 task-기반 regularization으로 해석할 수 있음.
- 이 regularization은 inductive bias를 유발하게 되는데, 다downstream 태스크가 overparameterization으로부터 얼마나 수혜를 받을 수 있는지를 설명함.
- 한 마디로, 이전 모듈의 정보를 일종의 regularization으로 바라본다는 것.
- (2) optimal representation을 찾는 게 가능하다면, 얼마나 많은 데이터 샘플이 필요할까?
- feature covariance가 (DoF 한에서) sample complexity를 줄이는 데 도움이 된다는 이론을 제안.
- (1) 학습을 위한 태스크들이 주어졌을 때, downstream 태스크에 알맞는 optimal linear representation을 찾을 수 있을까?
- 이런 저런 의문들을 활용해 전반적으로 성능 향상을 시킬 수 있는 overparameteriezd meta-learning 알고리즘을 제안함.
-
최근 딥러닝 연구들은 overparameterization이 전통적인 single-task 환경에서 일반화 능력을 높혀준다고 주장함.
-
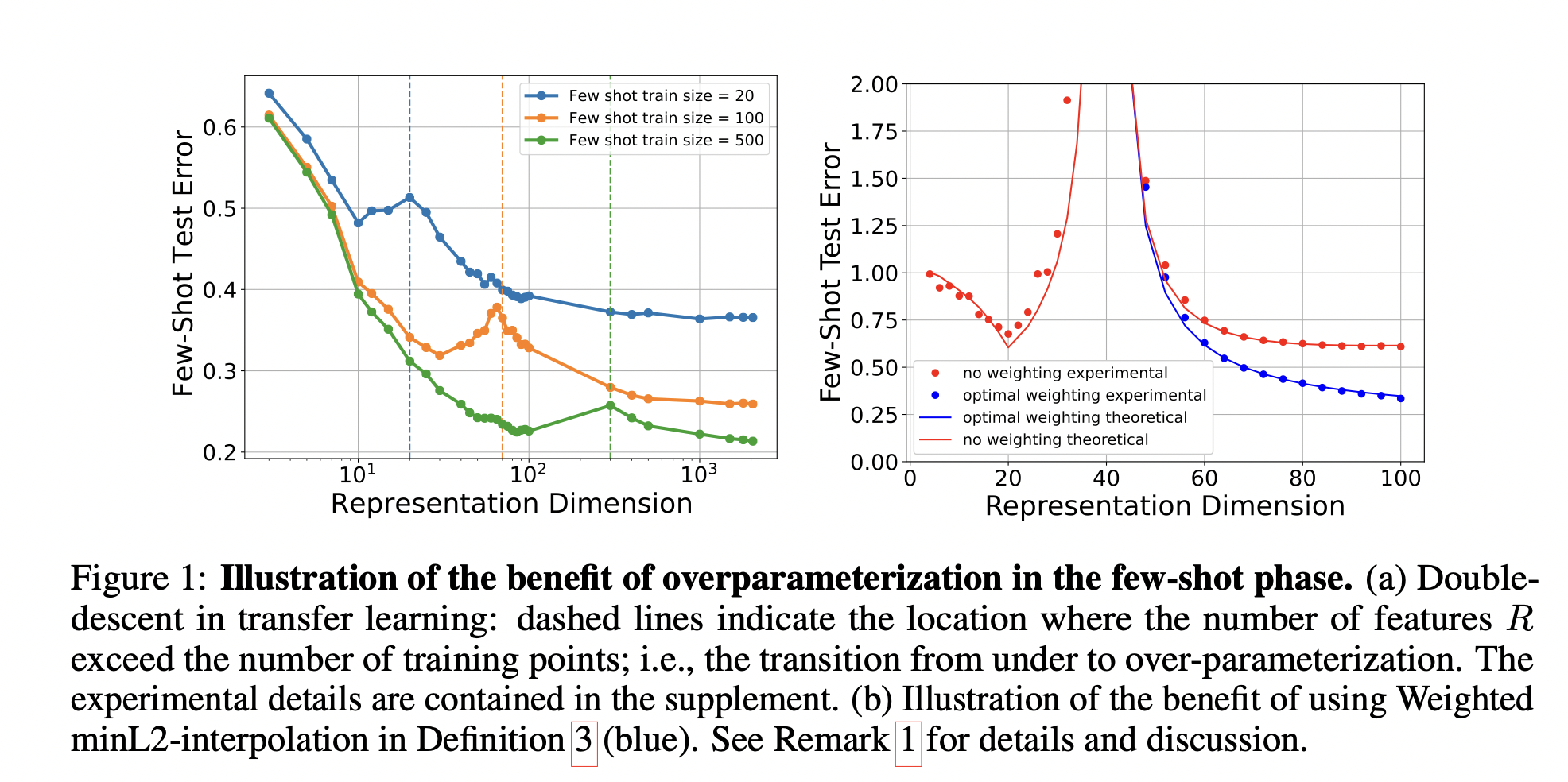
즉, 모델의 capacity가 높아짐에 따라 test loss가 증가하는 과적합이 일어나는 것처럼 보이지만, 파라미터를 더더욱 늘릴 경우 다시 test loss가 감소한다는 Double Descent에 관한 얘기.
-
이게 메타러닝에서도 유사하게 작동하며, 특히나 Linear Regression과 같은 간단한 task에서도 유사한 현상을 관찰할 수 있었음.
-
즉, 메타러닝에서의 overparameterization에 관한 현상들은 어느 정도 linear model로 간소화해 바라볼 수 있다는 것(대표화).
-
이제 우리는 메타러닝 대신 linear model을 디테일하게 분석하고, 이를 전반적인 메타러닝 환경에 적용할 수 있게됨(일반화).
-
사실 이는 완전히 새로운 관찰은 아니며, 최근 연구들은 딥러닝 모델이 (비선형임에도 불구하고) kernel regression같은 선형 문제들이 (overparameteried)(비선형) 딥러닝 모델들의 이론적인 이해를 돕는 데 좋은 근사를 제공해준다고 주장해왔음.
-
메타러닝에서도 데이터를 낮은 차원에 사영시키는 Subspace-based 메타러닝 기법들이 널리 쓰여왔지만, Double Descent 현상은 차라리 overparameterized interpolator가 PCA 기반 모델들보다 훨씬 더 좋을 것을 암시함.
Contribution
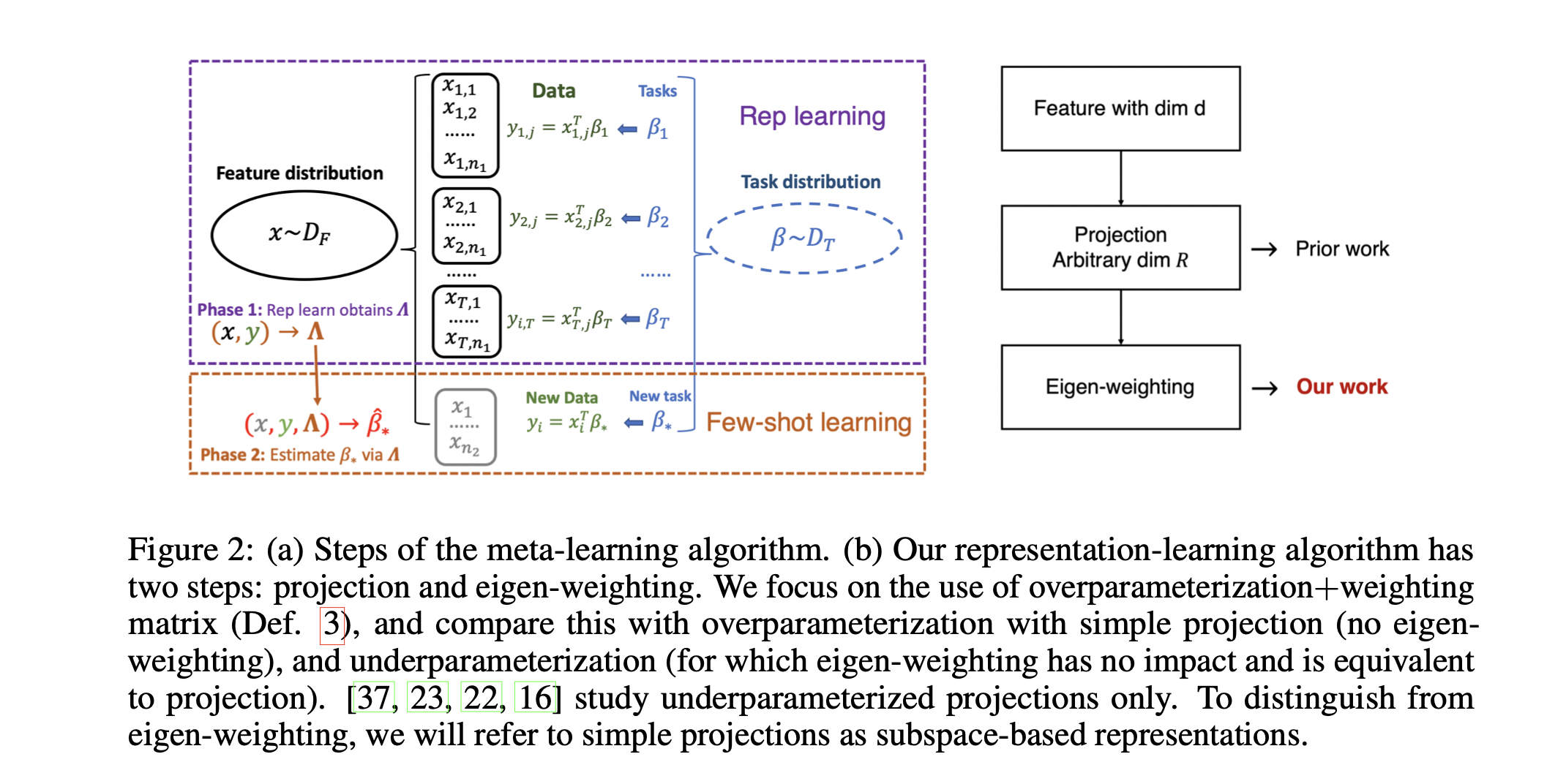
- 각 task를 선형회귀 문제로 가정한 뒤, 주어진 earlier tasks에서 배운 linear representation을 기반으로 다음의 downstream task(fewshot task) 성능을 늘리기 위해 어떤 linear representation matrix를 골라야 하는지 방법을 제안함.
- 본 논문에서는 이 방법으로 eigen-weighting을 사용함.
- 즉, 선형 매핑 을 사용해 d차원의 데이터 를 차원의 로 매핑시킴.
- 이 때 매핑하는 차원인 과 함수 를 어떻게 설정해야 하는가?
- 그리고, 데이터가 (Dof?) 보다 작을 때도 이런 representation을 배울 수 있는가?
- 데이터가 작아도,
- 임의의 representation 차원에 대해,
- overparameterization 환경에서, 잘 작동하는(일반성 있는) representation을 탐구.