What is DQN.
이전의 글에서도 다뤘다시피, 기본적인 강화학습은 Environment를 MDP를 통해 이해하고, Table* 형태로 학습하여 모든 state에 대한 action-value function의 값을 update해나간다. 이 action-value function을 최적의 값인 true action-value function에 가깝게 학습하며, 이를 토대로 optimal policy을 정하고, agent**는 이를 따라 최적의 행동을 한다.
하지만, 위와 같은 형태(table)로 학습하게 될 경우 학습이 극도로 느려지는 등의 문제가 있고, 그렇기에 action-value function(q-value)을 approximation(근사화)를 통해 해결하는 방법을 주로 사용한다. 이 때, q-value를 근사화하는 approximator로 비선형 함수인 Deep Nueral network를 사용하는 강화 학습 방법이 **Deep Reinforcement Learning이다.
또한, action value function 뿐만 아니라 policy 자체를 근사화할 수 있는데, 이 approximator로 DNN을 사용해도 DeepRL이라 합니다.
DQN이라는 용어는 강화학습 분야의 리딩그룹 DeepMind에서 발표한 연구 "Playing Atari with Deep Reinforcement"에서 처음 나왔다.
해당 논문에서 소개하는 DQN은 구체적으로 어떻게 사용되었을까?
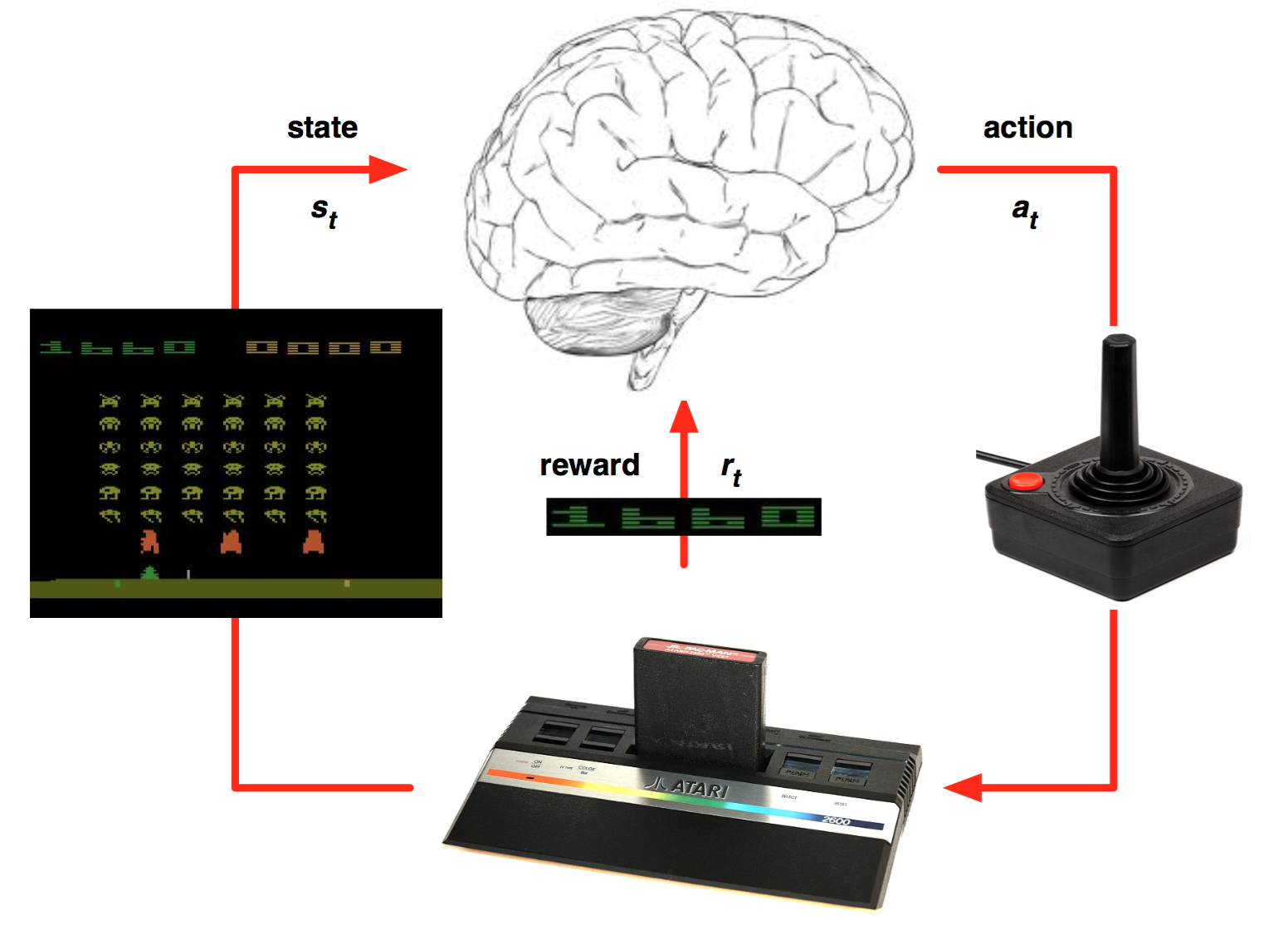
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards. We apply our method to seven Atari 2600 games from the Arcade Learning Environment, with no adjustment of the architecture or learning algorithm. We find that it outperforms all previous approaches on six of the games and surpasses a human expert on three of them.
위의 문장은 논문에서 발췌한 내용으로, raw pixel을 input으로 받아, value function(future rewards)를 output으로 반환하는 Q-Learning의 parameter를 학습하는 Convolutional Neural Network(CNN)을 사용했다고 한다. 즉, 고차원의 sensory input을 통해 control policies를 다이렉트로 학습하는 Deep learning model이라고 볼 수 있다.
실제 세계의 문제를 해결하기 위해 고차원 데이터를 거의 무조건적으로 활용할 수 있어야 한다. 이전까지는 이 고차원 데이터를 활용하기 힘들어 Hand-crafted features를 이용했지만, DQN의 등장으로 고차원 데이터를 직접적으로 활용할 수 있게 됩니다.
Deep Learning vs Reinforcement Learning
딥러닝과 강화학습 사이에 고차원 데이터를 활용하는 방법은 꽤나 다르다. 그렇기에 딥러닝 기반 방법을 강화학습에 곧바로 적용할 수 없었는데, 정확히 어떤 차이 때문에 강화학습에 딥러닝 기반 방법을 적용하기 힘들었을까?
- Deep-Learning 기반 방법들은 hand-labelled training dataset을 필요로 하지만, Reinforcement Learning에서는 오로지 Reward를 통해서 학습된다. 더욱이나 그 reward 조차 sparse, noisy, and delay한 성격을 가진다.
- Deep Learning에서는 data sample이 하다는 가정이 있다. 하지만, Reinforcement Learning의 경우 현재의 state가 어디인 지에 따라 가능한 다음 state가 결정된다. 즉, 독립적이지 않고 종속적이며, state간의 correlation(상관관계)또한 크다.
state간에 상관관계가 크다는 말은, data들 간의 correlation 또한 크다는 말과 같습니다.
위와 같은 문제들을 어떻게 해결했을까?
핵심적으로는 experience replay라는 방법을 통해 위의 issue를 해결했고, 비로소 RL에 DL 방법론을 성공적으로 적용할 수 있게 되었다.
- raw pixel을 받아와 directly input data로 다루었다.
- 하나의 agent가 여러 종류의 Atari game을 학습할 수 있다.
- CNN을 function approximator로 이용했다.
- Experience replay를 사용하여 data efficiency를 향상했다.
즉, 1,2를 통해 고차원 Input data을 다양한 task에 활용할 수 있게 되었고, 3,4를 통해 Reward를 활용할 수 있는 기반을 마련했다고 볼 수 있다.
Experience replay
기존의 알고리즘들은 Environment와 상호작용하며 얻어진 on-policy sample들인 을 통해 parameter를 update하였다. 하지만 이런 방법은 on-policy sample을 사용하기 때문에 sample에 대한 의존성이 크고, 그렇기에 policy가 수렴하지 못하고 진동할 수 있다.
이 문제를 해결하기 위한 아이디어가 Experience replay이다. 이 방법은 각 time-step별로 얻은 sample(experience)들을 아래와 같이 tuple 형태로 dataset에 저장해두고, 임의로 뽑아 mini-batch를 구성해 update하는 방법이다.
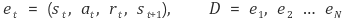
추가로 필요한 테크닉(dataset 개수를 으로 한정짓거나, input length를 미리 정해놓거나 하는 등의 기법)들은 구체적으로 다루지 않겠습니다.
이와 같은 Experience replay를 통해 아래와 같은 이점을 얻을 수 있다.
- data sample을 update하고 버리는 기존의 방법과 달리 random sampling을 함으로써 data usage efficiency를 늘릴 수 있다.
- RL에서 발생할 수 있는 state 간 high correlation 문제를 해결할 수 있다.
- 현재의 policy를 따라 argmax action을 고르고 난 뒤, 그 다음 training sample들은 이 action에 따라 결정된다. 즉, current sample에 의해 다음 training sample이 dominate된다. 이렇게 되면 불필요한 feedback loops를 돌거나 local minimum에 빠지거나, 발산하는 경우를 포착할 수 있다.
당연히 Experience replay는 current paramter와 update parameter가 다르기 때문에 off-policy를 기반으로 사용해야 합니다.
Algorithm of DQN

- 메모리와 용량을 초기화한다.
- action value function 를 초기화한다.
- episode를 1부터 까지 도는데, 각 episode에 대해 sequence를 초기화하고, 이를 아래와 같이 pre-process한다.
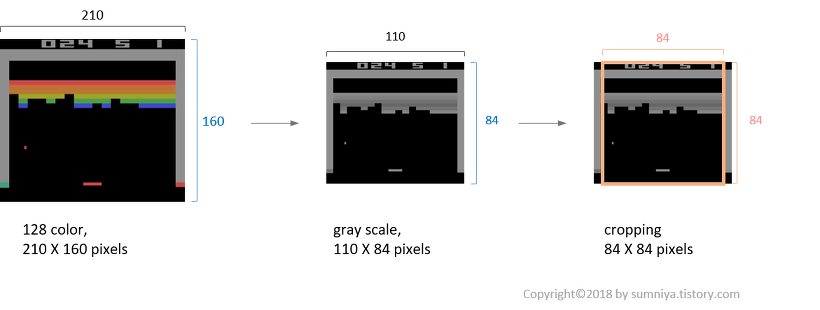
위의 전처리 과정은 down-sizing, gray-scaling, Sqaure cropping(for GPU), last 4 frame stacking 등이 포함된다.
- time-step마다 -greedy 방법으로 action을 취하고, 이를 통해 reward와 다음 state , 그리고 다음 이미지 를 얻는다.
- 역시나 마찬가지로 frame(), action(), state()는 전처리 과정을 거치며, 전처리 과정을 거쳐 얻어진 experience(여기서 )를 메모리에 저장한다.
- 메모리에서 얻은 mini-batch sample들을 통해 loss를 최소화하게끔 update를 진행한다.
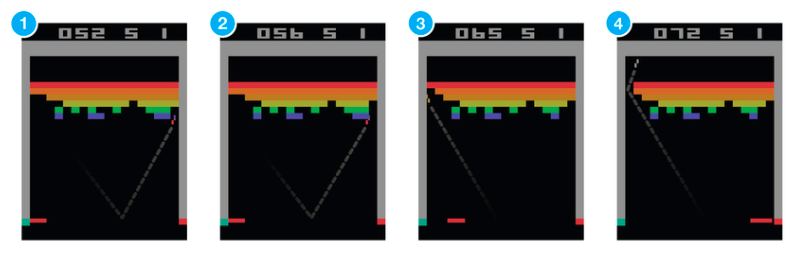
위의 그림처럼 단지 state가 pixel data로 바뀌었을 뿐이고, 그 화면을 인식해 Future reward를 계산하는 것이다. 이 때 아래와 같은 CNN을 사용한다.
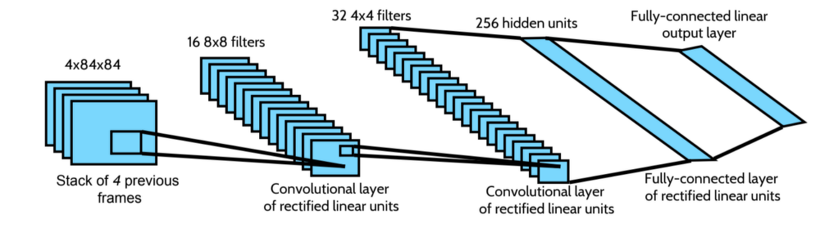
즉, state representation은 neural network로 들어가는 input frames 뿐이며, 그 input state에 대한 개별 action들에 대한 q-values를 output으로 반환한다.
추가적으로, 원 논문에서 발췌한 내용 중에 아래와 같은 내용이 있다.

위에서 말하는 q-value 는, 원래 Reward를 최대화 하는 를 사용해야 하지만, 반복적으로 학습을 하게 되면 결국 optimal q-value 에 다다를 수 있다는 가정하에 그냥 값을 사용한다.
또한, 최종적으로 이라고 불리는 function estimator의 parameter인 를 학습하게 된다.
기존의 Bellman-Equation을 이용해 반복적으로 value function을 업데이트 하는 방식과 거의 동일합니다.
다만, 기존의 방식을 활용할 수 없기 때문에 DNN(여기서 CNN)과 같은 function approximator를 활용하는 것입니다.
결론
결론적으로, Tensorflow 등에 잘 스며들어 있는 라이브러리들을 활용해 학습을 진행하되, 전체적인 구조만 신경써서 코딩하면 된다.
참고
https://dnddnjs.gitbooks.io/rl/content/deep_q_networks.html
https://sumniya.tistory.com/18?category=781573
