Tabular Methods
따로 언급한 적은 없지만, 지금까지 살펴본 강화학습은 모두 action value function을 Table(행렬)로 만들어 푸는 Tabular Methods였다. 이러한 방법론은 state나 action (차원)이 작을 경우에만 가능하며, Table이 점점 커질수록 값들을 기억할 메모리는 물론이고 학습 자체에도 엄청난 시간이 소요된다.
즉, 앞으로 다양한 실생활 문제에 Generalization(일반화)를 하려면, (실제 세상은 continuous state space로, 사실상 무한대의 state를 가지므로) 새로운 방법론을 가져올 필요가 있다.

Parameterizing value function
해답은 바로 state나 action을 table로 작성하는 것이 아닌, 라는 새로운 변수를 이용해 value function을 함수화 하는 것이다.

즉, state가 함수의 input으로 지나가면, 라는 parameter를 지나 action value function을 output으로 내보내는 것.
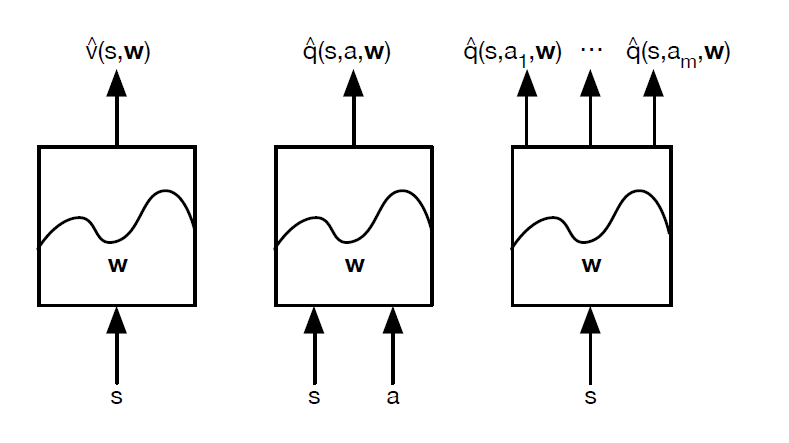
더욱 직관적으로 살펴보자.
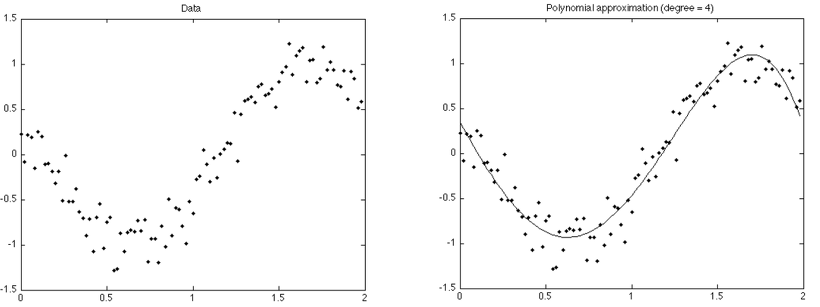
만약, 우리가 사용할 data가 위의 왼쪽 그림과 같다 가정해보자. 이 값들을 각각 저장해 학습시키는 것은 사실상 불가능에 가깝기 때문에 오른쪽 그림처럼 data의 경향을 나타내는 function으로 approximation(근사화)하는 것이다.
이로부터 얻을 수 있는 이점은 아래와 같다.
1. 실제로 가지고 있지 않은 data도 function을 통해 sampling할 수 있다.
2. 실제 data의 noise를 배제하고 학습할 수 있다.
3. 고차원의 data도 효율적으로 저장이 가능하다.
실제 data의 noise를 배제하고 학습을 할 수 있다는 것은, 반대로 특이 케이스에 대한 학습을 못해 exploration 능력이 떨어진다고 볼 수도 있겠죠?
즉, data대신 parameter(가령, 에서 )만을 저장하고, 이 parameter를 인자로 가지는 function approximator를 통해 실제 값에 근사하는 것이다.
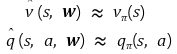
그리고, 학습을 통해 이 라는 parameter를 update하여 true value function과 근사하게끔 알고리즘을 작성한다.
atari게임에서는 이 function approximator로 deep learning을 사용했기 때문에, deep reinforcement learning이라고도 합니다.
Learning with Function Approximator
이후에는, true value function과 estimated value function의 차이(즉, error)를 parameter 의 함수로 잡고, 이 함수를 최소화하는 식으로 진행이 됩니다.
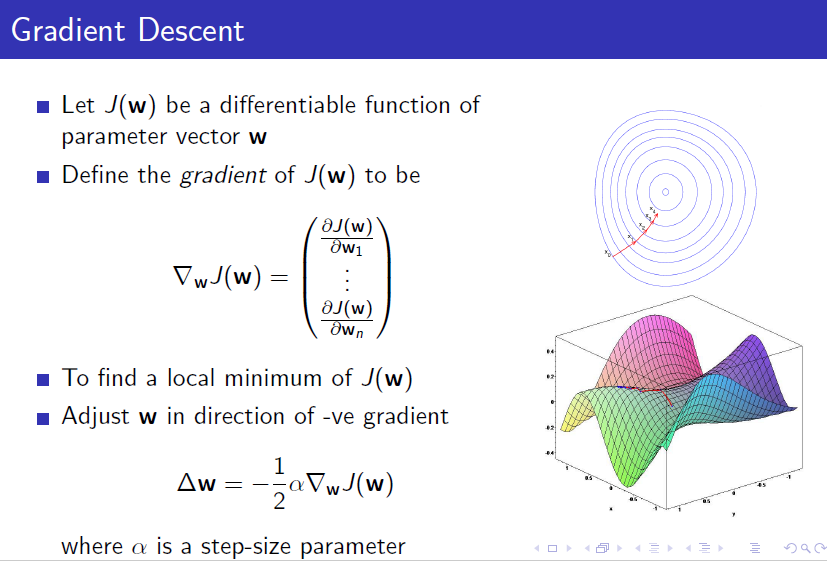
머신러닝 / 딥러닝을 한 번이라도 해본 사람이라면 추가적인 설명 없이 이해가 가능하기에, 이하 과정은 생략하겠습니다.
Gradient Descent on RL
For state-value function

위의 그림에서, update가 되는 것은 true value function이고, error 함수 를 true value function과 approximated value function의 MSE로 잡는다.
그 후, Gradient를 통해 경사 하강법을 진행한다.
딥러닝과 마찬가지로 Stochastic gradient descent(확률적 경사 하강법)을 적용하게 될 경우 sample들 중에 하나 만을 사용하여 update를 진행한다(전체 sample을 이용해 update할 경우 일반(혹은 full) gradient descent).
딥러닝에서는 supervisor(혹은 target, label 등) 에 의해 학습이 되는 반면, RL에서는 supervisor가 없고, 오직 rewards 뿐이다.
그렇기에 일반적으로 를 target으로 대체한다.
특히, True value function 부분은 update의 target을 변형해 sample return을 사용하든(MC), TD target을 사용하든 할 수 있다.

For action-value function
앞에서는 state-value function을 나타냈지만, model-free를 위해서는 action-value function을 사용해야 한다. 그 알고리즘을 그림으로 보면 아래와 같다.
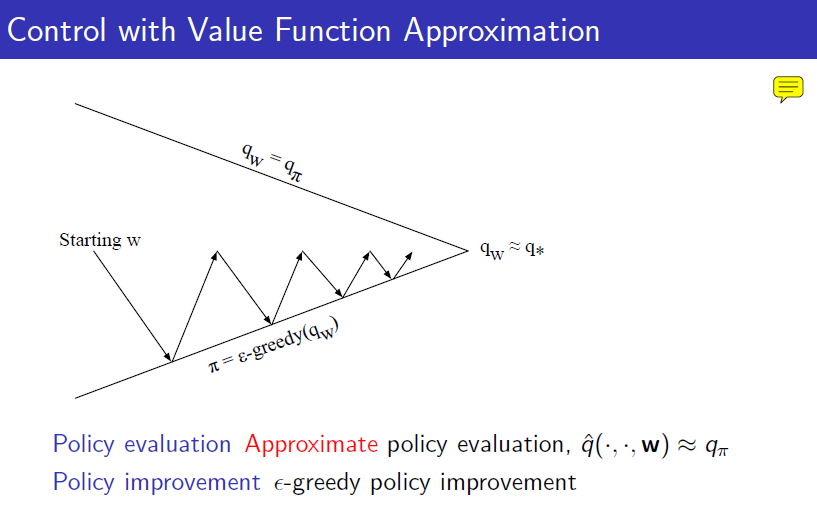
policy evaluation은 parameter의 update로 진행하며, policy improvement는 그렇게 update된 action value function에 -greedy한 action을 취함으로서 improve를 진행한다.
이하 과정은 state-value function 때와 동일하다.


Example(Mountain Car)
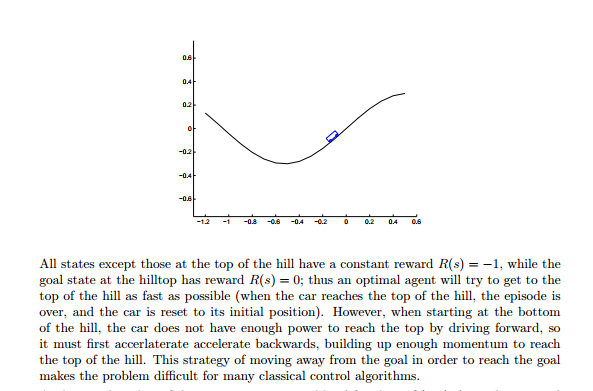
위와 같은 Mountain Car 문제는 위치, 그리고 속도로 state가 정해지는 2차원 state problem이다. 강화학습을 통해 optimal policy를 얻으려면 각 state의 value function을 알아야 한다. 하지만, state가 continuous하게 변하기 때문에 기존의 table 방법으로는 풀 수가 없다.
그러므로 value function approximator를 통해 모든 state의 value function을 함수화해서 표현할 수 있고, 이 함수를 통해 sampling을 함으로써 나온 experience를 통해 value function을 학습해나간다.
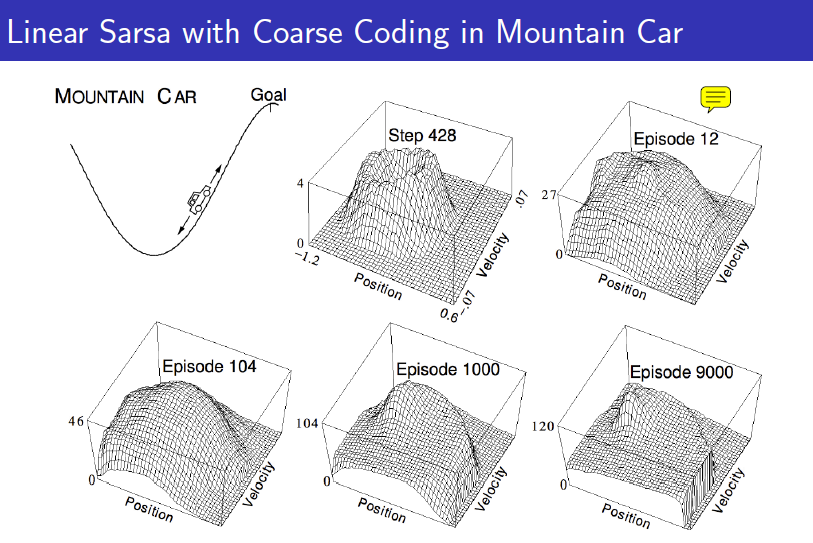
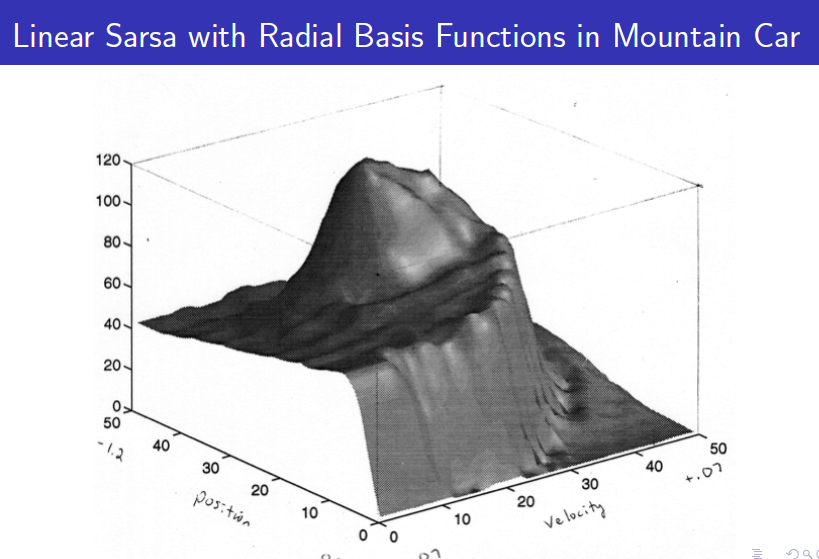
위와 같이 학습이 완료된 value function을 통해 agent는 각 state에서 가장 높은 value function을 가진 state로 계속 이동하게 디ㅗㄴ다.
E.T.C
BATCH Method
딥러닝과 유사하게 SGD, Full Batch GD보다는 mini-batch SGD를 활용한다.
Optimizer
이 또한 마찬가지로 일반적인 SGD 외에 Momentum, Nag, RMSProp, Adam 등 다양한 Otimization 방법을 사용한다.
Experience Replay
구글 딥마인드가 Atari Game problem에 사용했던 알고리즘이다. replay memory라는 것을 만들어 놓고, agent가 경험했던 것들을 time-step마다 끊어서 저장해놓는다. action value function의 parameter를 update하는 것은 time-step마다 하지만 하나의 transition에 대해서만 하는 것이 아닌, 메모리에 저장해놨던 모든 transition을 모아서 그 mini-batch에 대해 update한다.

이렇게 함으로써 sample을 효율적으로 이용할 수도 있고, episode 내에서 step by step으로 업데이트를 하면 그 데이터들 사이의 상관관계 때문에 학습이 잘 안되는 문제도 해결할 수 있다.
다음
다음으로 딥마인드의 연구 "Playing Atari with Deep Reinforcement Learning"이라는 논문에서 처음 소개된 DQN(Deep Q-Learning)에 대해서 간략히 다룰 것이다.
출처
https://dnddnjs.gitbooks.io/rl/content/value_function_approximator.html
https://sumniya.tistory.com/17?category=781573
