Paper: https://academic.oup.com/jamia/article/27/3/457/5651084?login=true
0. Abstract
Objective
해당 서베이 페이퍼는 임상 분야에서 딥러닝 기반 NLP 연구들에 대해 체계적으로 리뷰합니다.
특히, methods, scope, context 3가지 체계를 위주로 정량적인 평가를 제공합니다.
Materials and Methods
저자들은 주로 전자 의무 기록을 토대로 하는 여러 NLP 방법론들을 다뤘습니다.
MEDLINE, EMBASE, Scopus, ACMDL(Association for Computing Machinery Digital Library), ACLA(Association for Computational Linguistics Anthology) 등의 저널을 기반으로.
Results
모델 관점에서는 RNN 계열이 60.8%, word2vec embeddings 계열이 74.1%로 가장 많이 쓰였습니다(2018년까지).
태스크 관점에서는 text classification, named entity recognition, relation extraction같은 정보 추출 태스크가 89.2%로 가장 많았습니다.
물론 다른 태스크들도 (규모는 적을지 언정) 많았습니다(long tail).
Discussion
의학 도메인 관련 NLP 기술들이 많아졌음은 당연하고, 그 중에서도 일종의 공통적인 관계를 찾아볼 수 있었습니다.
가령, sequence-labelling named entity recognition에 대해선 RNN을 주로 사용했다든지..
Conclusion
clincal NLP 분야는 아직 왕성하게 연구되지 않았기 때문에, 본 리뷰는 인기 있고 독특한 트렌드를 다룹니다.
1. Introduction
딥러닝은 현재 엄청나다.
그 와중에, 의학 분야에서는 전자의무기록(EHR)을 채택함으로써 엄청난 양의 digital text가 발생하고 있는 상황이고, 이를 활용하기 위해 NLP 기술을 연구하고 있습니다.
세상의 모든 분야 중 딥러닝 분야의 연구가 가장 큰 규모로 진행되고 있습니다.
본 리뷰 논문의 저자들도 clincal NLP와 Deep Learning 사이의 관계를 다룰 예정이고, 주로 아래와 같은 질문을 중심으로 본문을 기술해나갑니다.
- Methods : 어떤 딥러닝 모델이 확실한 기여를 하고 있는가?
- Scope : 주로 어떤 종류의 문제가 다루어지나?
- Context : 이 연구들은 어떤 맥락에 해당할까?
저자들은 이러한 질문에 답하기 위해 2014-2019.4에 주로 투고된 212개의 article을 다루었다고 합니다.
- clinical NLP 분야는 매년 규모가 2배 커집니다.
- 연구의 다수는 주로 영어 clinical notes 내 information extraction tasks**를 대상으로 수행했습니다.
해당 서베이 페이퍼는 역시나 의학 분야에 한정해서 다루는데요, 다른 데이터는 배제하고 전자 의무 기록(EHR, Electronic Health Records)에 작성된 텍스트만을 다룹니다.
전자의무기록 : 주로 환자 건강에 대한 정보, 병력 등이 기재된 정보입니다.
전문가들이 작성합니다.
EHR이 아닌 소셜 미디어, 웹 포럼, 메신저 플랫폼 등은 EHR과 꽤나 다르기 때문에 배제했습니다(데이터 이용 가능성, 데이터 타입 등 여러모로 다르다고 합니다).
뿐만 아니라 이 서베이 페이퍼 제목에는 Methodical review라는 단어가 붙었는데요, 이는 다른 페이퍼들과 다르게 Preferred Reporting Items for Systematic Reviews and Meta-Analyses(PRISMA) 가이드라인을 따랐기 때문에 붙힌 이름이라고 합니다.
1.1. Related Works
참고로, clincal NLP는 비교적 인기 있는 분야기 때문에 아래와 같이 다양한 리뷰 페이퍼들이 존재합니다.

2. Materials and Methods
아까도 언급했다시피 본 논문은 PRISMA 가이드라인을 따릅니다.
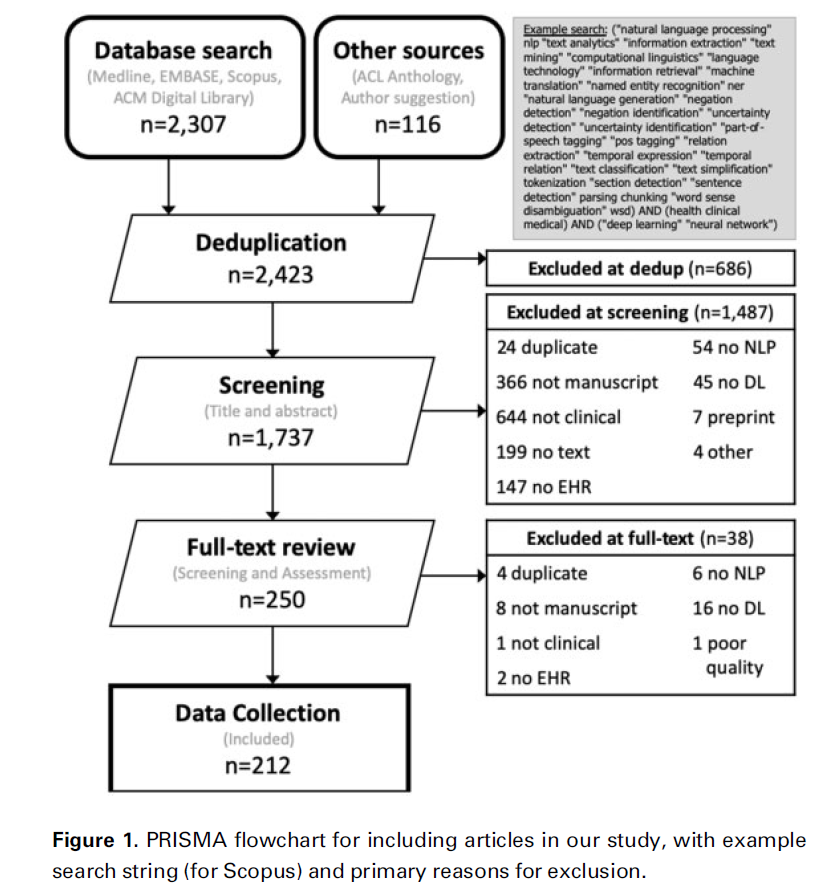
본 논문이 다루는 데 적합한 연구들은 아래와 같은 특징을 지닙니다.
- Natrual Langauge Processing일 것
- 딥러닝(neural networks)일 것
- EHR data를 활용한 clinical domain일 것
연구들은 주로 MED-LINE, EMBASE, Scopus, ACM(Association for Computing Machinery), ACL(Association for Computational Linguistics).
(EHR & DL-related keywords로)
그 외에 뭐 많은 기준들로 페이퍼를 구축했다고 하는데, 관심 있는건 결과이므로 생략하겠습니다.
3. RESULTS
3.1. 어떤 딥러닝 방법이 clincal-NLP에 기여하고 있으며, 널리 쓰이고 있을까?
3.1.1. Methods : Deep learning architecture
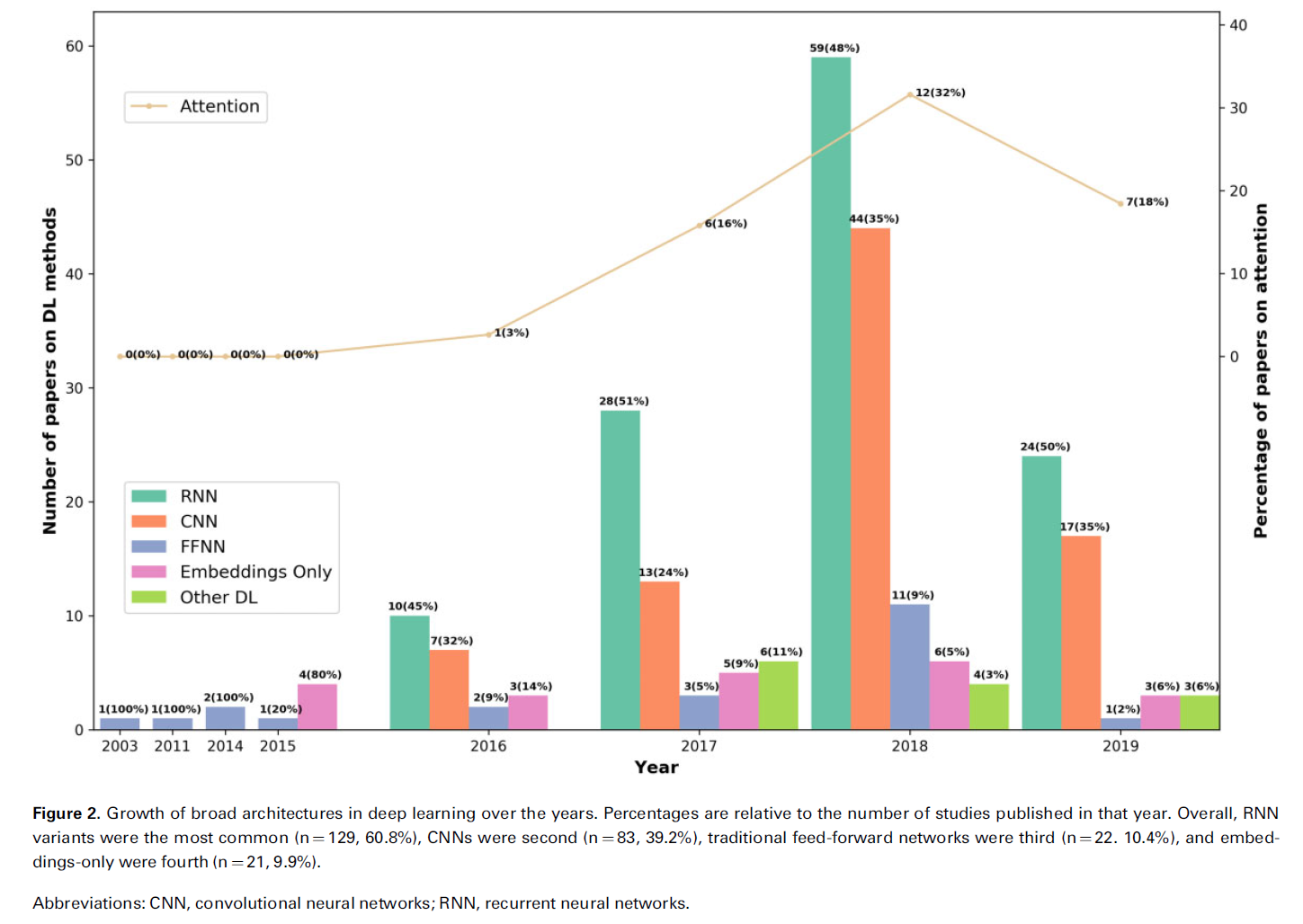
- Embedding only는 SVM같은 전통적인 머신러닝 아키텍처를 사용합니다.
- 의학 분야 해당이기 때문에 BERT, Transformer 등을 다루는 "Other DL"의 비중은 높지 않습니다(general domain이랑 꽤나 차이가 나는듯 합니다. 시기도 시기지만).
꺾은선으로 나타난 Attention 매커니즘은 점점 더 많이 쓰이고 있으며, 모델의 설명가능성을 높히거나 성능을 향상시킬 수 있어서 널리 쓰이고 있습니다.
BERT 때문에 Attention 매커니즘이 미래의 방향이 아닐까 생각합니다(그리고 실제로 20-21년에는 어디에든 널리 사용되는 중입니다).
Adversarial Learning은 사실 비전 분야에서 많이 쓰일뿐, NLP 분야에서는 별로 안 쓰이는 것 같습니다(심지어 의학 도메인에는 더더욱).
사실 정석적인 접근 방식은 기존에 연구된 NLP 모델을 clinical NLP tasks에 맞게 재구성하는 것인데요, clincal tasks와 domain을 특별히 고려한unique architectures도 종종 있었습니다.
가령, Xie et al은 tree-of-sequence LSTM을 ICD codes의 트리구조에 피팅했으며, 적대적 학습을 사용했다거나, concept-level embeddings을 input으로 사용해 downstream layer에 통과시킨다거나 하는 deep averaging networks도 있었습니다.
이런 모델들은 특정한 context 없이 다양한 피노타이핑 태스크의 조건을 활용할 수 있다고 하는데요, 잘 모르니 넘어가겠습니다.
3.1.2. Methods : embeddings

- 사실 2014~2019년의 연구다 보니까 word2vec 쓰는 연구가 많았는데, 사실상 최근에는 BERT가 우세한 게 맞을 것 같습니다.
Large & Unlabeled data soruce는 종종 워드 임베딩을 학습하는데 쓰입니다.
연구들의 절반 이상이 pre-trained resources를 사용했으며, 그 중에는 clinical word embedding은 MIMIC-III 같은 clinical notes가 29%, PubMed같은 biomedical literature가 25%, health websites가 5% 등을 차지했습니다.
나머지 46%는 word embeddings(layer)를 단순히 initialize하고, 사용하는 dataset에 학습시켰습니다.
몇몇 개의 연구는 다양한 resource에 pre-training시킨 것을 비교했는데요, pre-training data가 많지 않다 보니까 clinical NLP에서는 뭐가 효과적인지 보장하기 힘든 것 같습니다.
대신, 하나의 연구는 domain-specifc한 임베딩과 domain-agnostic(도메인과 상관 없는) 임베딩을 concat했을 때 가장 좋은 결과를 보였다고 주장했씁니다.
3.1.3. Methods: medical knowledge
Clinical NLP는 (전통적으로) 의학 중심의 지식에 의존해왔습니다.
UMLS 같은 resource
하지만, (딥러닝 분야에서는), 17.9%의 모델만이 externel medical knowledge를 사용했습니다.
이 중 5.7% 가량만이 딥러닝 아키텍처에 이런 외부 지식을 통합했고, knowledge-resource embeddings을 사용했습니다.
즉, UMLS의 분류되지 않은 정보 임베딩을 word embeddings과 concat해 사용.
3.2. 어떤 종류의 문제가 주로 다루어지는지?
3.2.1. Scope: tasks
아래 그림은 NLP & clinical tasks가 얼마나 다루어졌는지 보여줍니다.
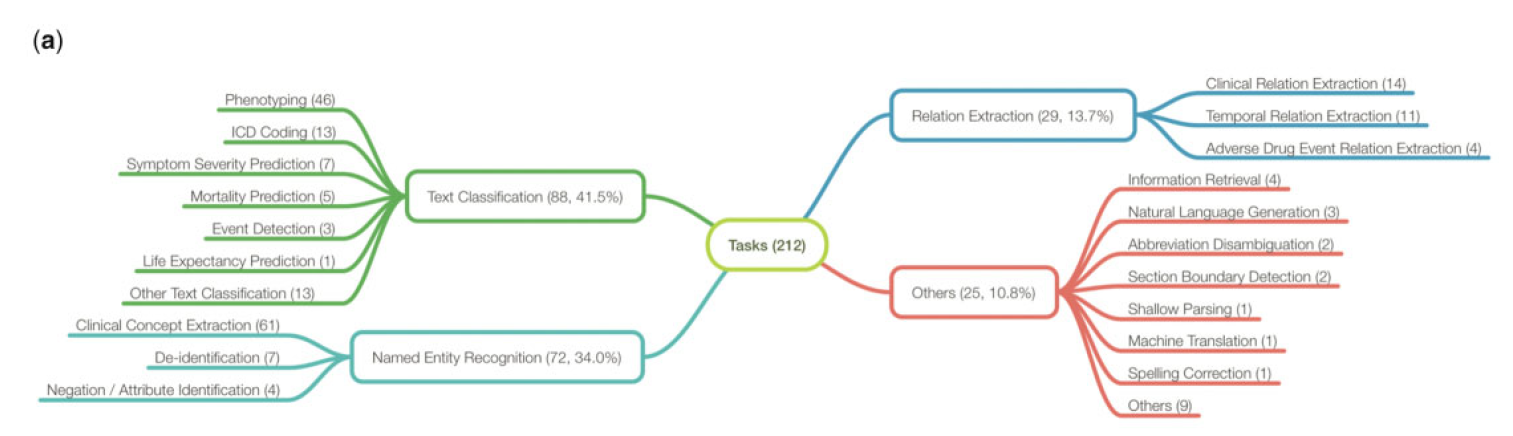
특히 clinical domain-specific tasks로도 나누어져 있습니다.
저자들은 NLP tasks를 주로 4개의 타입으로 분류해습니다.
- 텍스트 분류(Text Classification) - 40.5%
- Document-level : 74%
- Setence-level : 14%
- 기타 : 12%
- 개체명 인식(Named Entity Recognition) - 34.0%
- 관계 추출(Relation Extraction) - 13.7%
- 기타 - 10.8%
위의 그림에 따르면 가장 많이 연구된 clinical tasks는 아래와 같습니다.
- clinical concept extraction
- phenotyping
- **clasinical relation extraction
뿐만 아니라, 해당 그림은 (주로 Others에) 연구 규모는 적지만 굉장히 다양한 tasks가 수행되고 있음을 보여줍니다.
- Information Retrieval
- Natural Language Generation
- Abbreviation Disambiguation
- Section Boundary Detection
- Shallow Parsing
- Machine Translation
- Spelling Correction
- ...
전반적으로 많은 clinical NLP tasks가 있습니다만은,
- negation/attribute 식별
- event detection
- adverse drug event relation extraction
다른 task는 아예 없거나 연구가 적게 이루어지고 있습니다.
- sentence detection
- part-of-speech tagging
- text simplification
아래 그림은 각 task에 대한 알고리즘 분포를 보여줍니다.
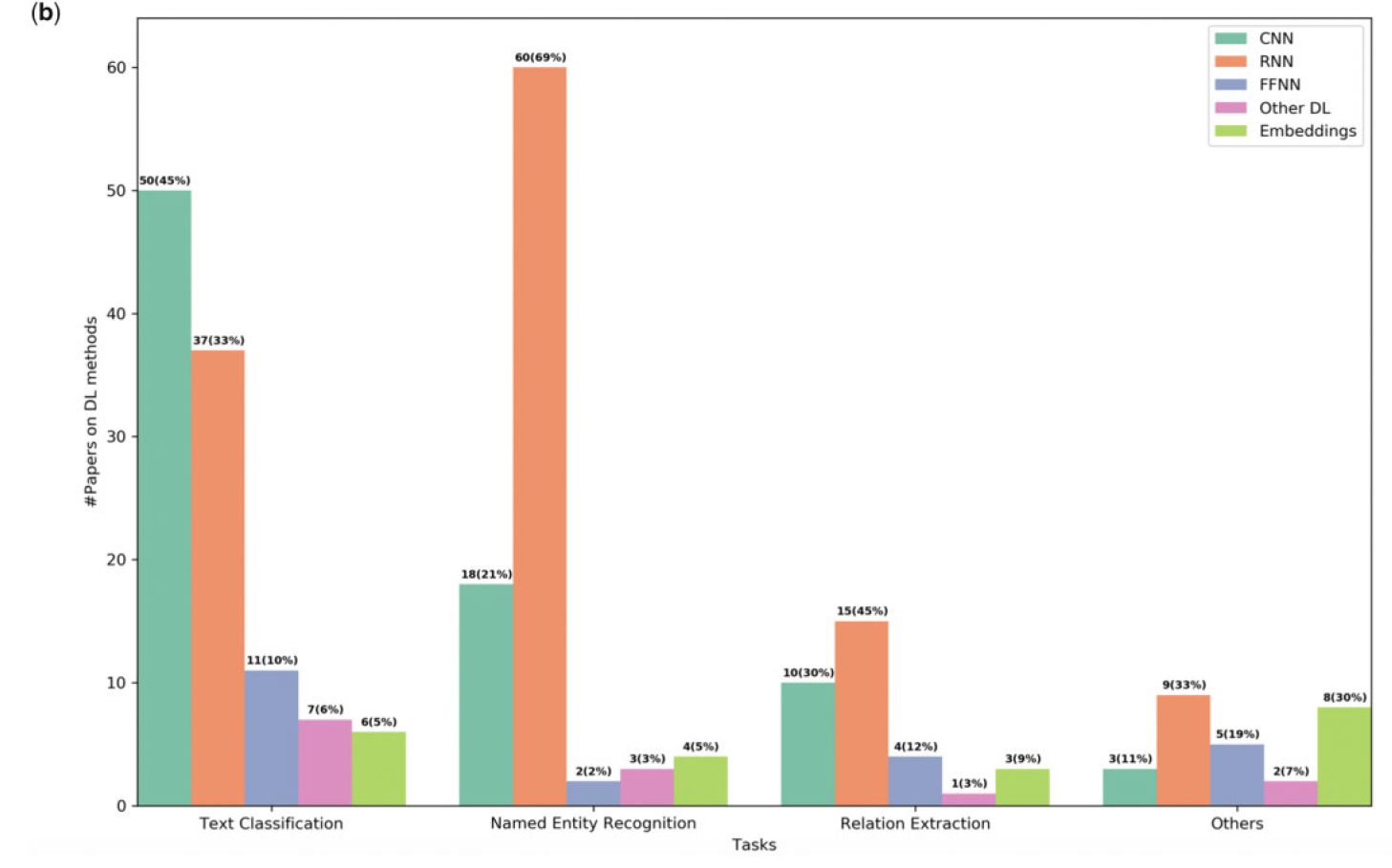
CNN 이 Text Classification에 생각보다도 더 많이 쓰였다.
3.2.2. Scope: data source
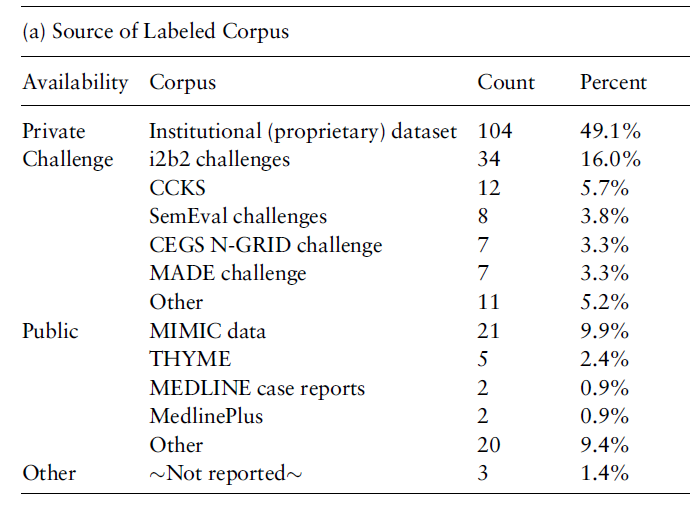
위의 테이블은 해당 연구들이 사용한 corpora를 보여줍니다.
거의 49.06%의 연구들이 private datasets을 사용했는데요, 의료 정보 자체가 환자의 사생활에 대한 우려가 존재해 서로 공유하지 않기(못하기) 때문입니다.
그렇긴 하지만, 이제 나머지 51% 가량은 publicly available data source를 이용하긴 했습니다.
위에 나와있는 것처럼 주로 Challenge가 많고, MIMIC, MEDLINE 등 Public data도 꽤나 많이 이용했습니다.
약간 구체적으로 들어가자면, Text Classification에는 MIMIC data가 가장 많이 쓰였으며, NER/concept extraction에는 i2b2 challenge, Relation Extraction에도 i2b2 challenges, 그리고 temporal event / relations에는 SemEval challenges가 가장 많이 쓰였습니다.
3.2.3. Scope: contributions
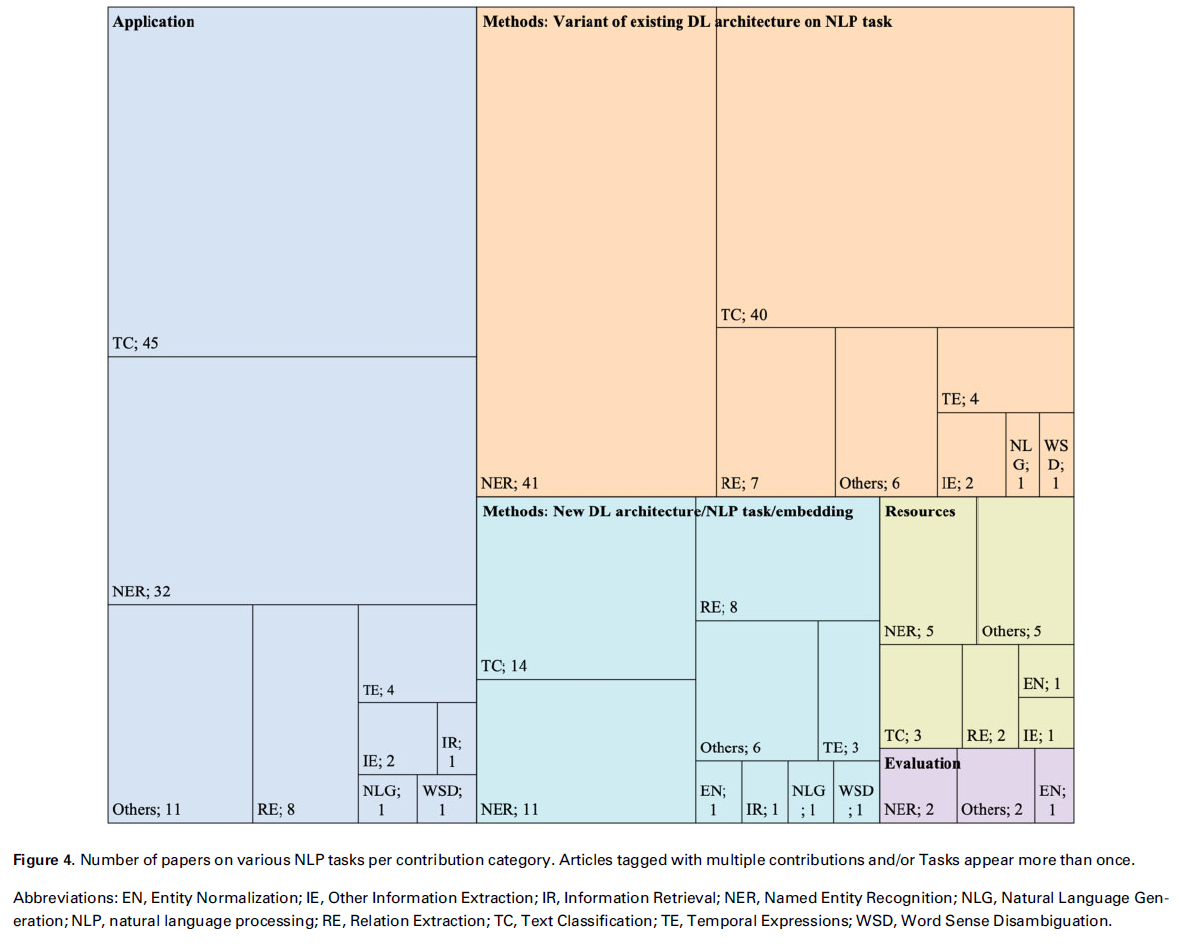
- 논문 흐름을 파악하지 못해 해당 단락은 패스.
3.3. 해당 연구들은 어떤 연구 맥락으로 행해졌을까.
3.3.1. Context: research communities
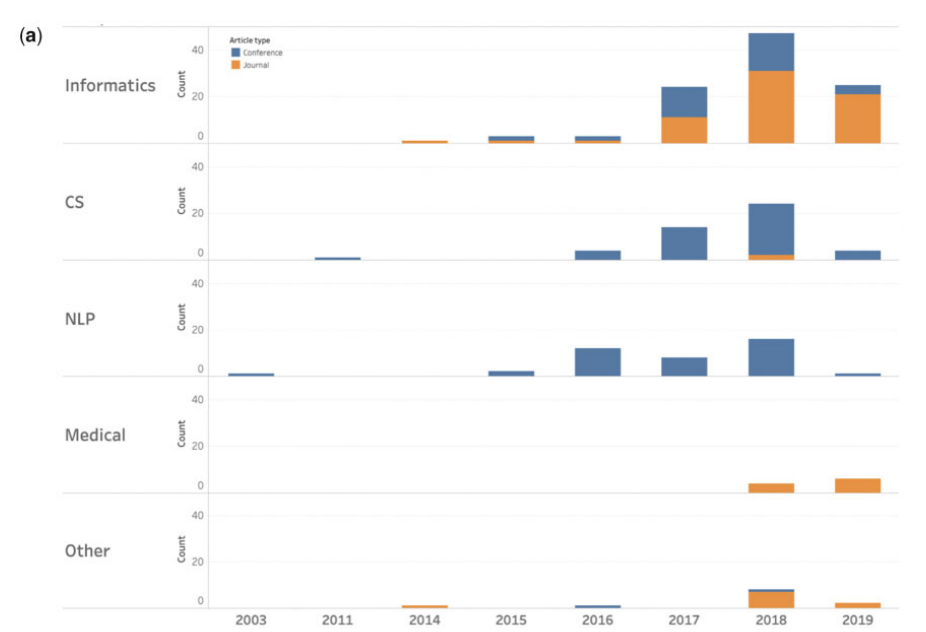
위의 그림에서 볼 수 있다시피, 의료 인공지능은 여러 분야가 접목한 분야이기 때문에, 연구가 투고되는 저널(or 컨퍼런스)들도 다양한 것을 볼 수 있습니다.

눈에 띄게 볼 것은, Medical 저널같은 경우 (당연하게도) 컨퍼런스의 비중이 낮다는 것과, 다른 분야에 비해 뒤늦게연구가 되고있는 것을 알 수 있습니다.
이는 사실 투고가 비교적 오래 걸리는 저널 위주로 투고가 된다거나,'블랙박스'라는 인공지능의 특징으로 인해 연구가 더뎠거나, 전향적 연구를 하기 힘들다거나하는 여러 문제에서 기인한다고 봅니다.
3.3.2. Context: preprint status
보통 인공지능 분야는 피어리뷰 저널에 투고하기 전에 아카이브같은 preprint server에 먼저 싣곤 합니다.
저자들이 조사한 212개의 연구들 중에 약 35개가 arXiv에 게재했으며, 그 중 9개 가량이 JAMIA, JBI, BMC Medical Informatics and Decision Making과 같은 정보 관련 저널에 게재되었습니다.
3.3.3. Context: scientific rigor(과학적 엄격함)
본 단라에서는 연구들이 후속 연구에 어떻게 기여했는지 디테일들을 다룹니다.
인공지능 분야의 큰 특징 중 하나는 연구의 재생산(reproducbility)을 위해 코드를 오픈소스로 공개한다는 것입니다.
- Software : Open-source vs Restricted(라이센스필요) vs Not provided
- Hyperparmeters : Present vs Partially provided vs Not provided
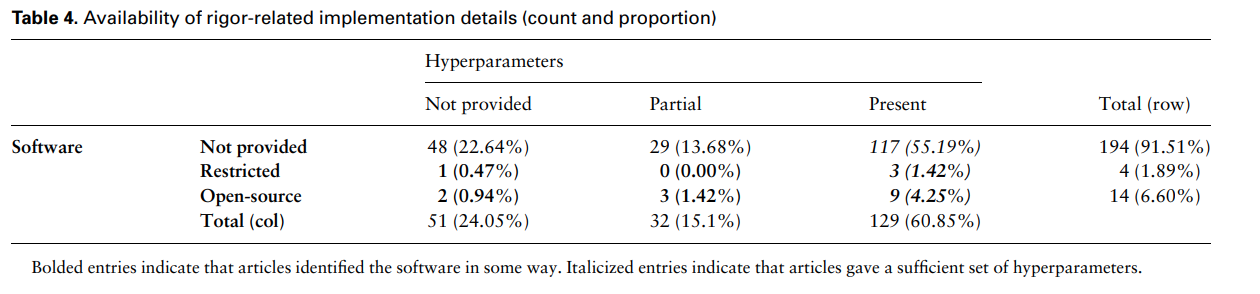
사실 위에서 말하는 Software는 다소 엄격한 기준으로 선정한 것 같습니다.
가령, 딥러닝 관련 논문들은 논문에 실린 아키텍처, 학습, 그 외 테크닉들에 대한 github을 제공하는 경우가 훨씬 많습니다.
3.3.4. Context : comparisons with traditional machine learning
(212개중 108개)
예상하다시피 전통적 머신러닝(나이브베이즈, 결정트리, 서포트벡터머신 등)을 비교 대상으로 하는 연구는 점점 감소하고 있습니다.
물론, 본 서베이 논분에서 조사한 시기도 시기고, 또한 의료 분야의 데이터 규모 특성상 머신러닝의 효율이 비교적 좋기 때문에 만큼 생각보다 많이 다뤄졌긴 합니다(212개중 108개)
그 중 72%의 연구에서 딥러닝의 성능이 좋았음.
4. Discussions
Clinical NLP를 위한 딥러닝 기법들은 더더욱 널리 쓰이고 있습니다.
정보학자와 임상의사들도 딥러닝 기반 기법들을 임상 환경에서도 널리 사용할 것이구요.
이는 큰 기회이기도 하지만, 역시 위험도 산재해있기 때문에 조심스럽게 다룰 필요가 있습니다.
4.1. Substantiating vs surprising results
(사실 제 예상과는 반대로) CNNs이 초기 Text Classification task에 굉장히 많이 쓰였습니다.
CNN 기반 방법들이 (우선 이미지 분야에서) 굉장히 잘 작동했기 때문인 걸로 보입니다.
비슷하게, LSTMs 계열은 NER Task에도 널리 쓰였는데, 이는 sequence에 관한 task이기 때문에 효과적이었습니다.
마찬가지로 이러한 연구들은 웬만하면 NLP 관련 학술지에 게재됐고, 정보학 관련 학술지에는 최신 기법들이 비교적 늦게 다루어지고 있으며, 의학 관련 학술지는 훨씬 더 딥러닝 기반 최신 기법들의 채택이 느린 모습을 보입니다.
그밖에도 주목할 점이 여럿 있습니다.
clinical NLP에 쓰이는 접근법들은 적극적으로 knowledge resources를 활용한 것으로 보입니다.
기존 딥러닝 방법들은 (필요가 없는지는 더 연구가 되어야 하겠지만) 외부 지식을 좀처럼 사용하지 않습니다.
또한 의외로 arXiv에 먼저 게재된 논문이 생각보다 적었다는 것도 주목할만한 점이라고 주장합니다(16.5%가량의 연구만 아카이브 게재).
4.2 Projections
미래 방향에 대해 간단히 다루어보겠습니다.
clinical AI 관련 분야에서는 라벨링 혹은 사생활 등의 문제로 데이터를 마련하기가 쉽지 않은 상황입니다.
그렇기 때문에 domain adaptation과 transfer learning 전략은 상당히 중요합니다.
다만, 이에 대해 시스템적으로 분석한 연구가 많지는 않습니다(서베이).
결과가 생각보다 없어서 그렇겠지요.
BERT같은 pre-trained model이 NLP 분야에서는 굉장히 성공한 만큼, 전이 학습을 잘 정제해서 사용한다면 이 역시 clinical NLP 분야에서 아주 잘 사용될 수 있을 것으로 보입니다.
그럼에도 불구하고, medical knowledge resources는 생각보다 덜 활용됐다고 생각합니다.
사실 딥러닝 분야가 고전적인 기계학습 분야와 다른 특징 중에 가장 대표적인 "Hand-craft features를 활용하지 않고 딥러닝 모델이 알아서 중요한 부분을 학습하자!" 라는 특징 때문이기도d 한데요,
그럼에도 불구하고 (최근 inductive bias에 대해서 언급한 여러 연구들에 따르면) 그래도 딥러닝 모델은 여전히 human input이 필요합니다.
즉, (이미 다른 분야보다는 활발하게 적용되고 있지만), data-driven 딥러닝 알고리즘을 확실하게 이용하기 위해 Knowledge resource가 계산 가능한, 객관적인 가이드 수단을 줄 수도 있습니다.
그 외에도 놓치지 말아야 할 부분은 생각보다 딥러닝 성능이 안 좋은 경우가 종종 있다는 것입니다.
기본적인 logistic regression 보다도요.
그럼에도 불구하고 Deep Learning이 전통적인 머신러닝보다 성능이 안 좋은 경우는 (전체에 비해서는) 많이 없기 때문에 이런 딥러닝 모델의 실패에 대해 심층적으로 분석한 연구는 별로 없습니다.
왜 실패했는지. 과적합 때문인지, 데이터 때문인지, 아니면 그 밖의 의학 분야에서의 독특한 특징때문인, 언어때문인지, 전문지식 부족 때문인지,
initialization, hyperparameters selection에 따른 불안정성도 고려해야 할 수도 있구요.
아무튼, 저자들은 이 분야에서 핵심적이고, 중요한 기여는 생각보다 정체될 수 있을 거라고 주장합니다.
새롭고, 좋은 여러 딥러닝 모델을 활용해 clinical tasks를 수행해가면서, 이런 시행착오를 줄이고 의학 분야에서의 딥러닝 채택을 가속화하는 편이 좋을 것 같습니다.
4.3. Limitations
저자들이 논문들을 모으다 보니 emrQA, CliCR과 같이 ACL Anthology에 투고된 연구가 몇 개 빠졌다고 말합니다.
비슷하게, condensed memory networks, graph-based model, BERT와 같이 NLP 미래 연구의 주축인 연구들 또한 많이 생략됐구요.
이런 미래 연구들이 아닌 전통적인 clinical tasks들에 쓰였던 이전 연구들(de-identification, automatic ICD-9, diagnostic inference, patient representation learning)도 마찬가지입니다.
또한, 굉장히 흥미로운 쟁점 중 하나인 clinical NLP vs open-domain NLP를 비교하기도 어려웠다고 합니다.
이를 하기 위해서는 논문이 다루는 주제를 약간 좁혀서 LSTMs, Text Classification만을 다룰 필요가 있다고 합니다.
Medical VQA에 관련된 Survey 논문은 General VQA와 차이를 잘 담고 있는 것처럼
Medicla VQA Survey
5. Conclusion
저자들은 212개 가량의 DL In clincal NLP 논문들을 여러 방법으로 분석했습니다.
그 결과 CNNs이 classification에 많이 쓰였다거나, NLP 커뮤니티는 저널보단 컨퍼런스를 선호한다거나, Medical 커뮤니티는 반응이 상당히 느리며 저널에만 투고한다든가 하는 사실들을 파악할 수 있었습니다.
