[논문리뷰] MedFuseNet: An attention-based multimodal deep learning model for visual question answering in the medical domain(2021, Scientific reports)
Medical AI
Paper: https://www.nature.com/articles/s41598-021-98390-1
0. Abstract
전 세계적으로 의료 종사자가 많지 않기 때문에 진단하는 데 있어서 여러 고충을 앓고 있습니다.
그렇기 때문에, 의학 분야에서 'second opinion'(보조 의견)을 제공하기 위한 reliable VQA 시스템을 구축할 필요가 있습니다.
하지만, 현존하는 대부분의 VQA system은 Medical Image를 다루게끔 설계되지 않았을 뿐만 아니라, 데이터의 양 또한 현저하게 떨어집니다.
본 연구에서 저자들은 위와 같은 문제들을 고려한 Attention-basd multimodal deep learning model인 MedFuseNet를 제안합니다.
MedFuseNet은 기본적으로 문제를 simpler tasks로 세분화하여 복잡도를 최소화하게끔 학습을 유도합니다.
MedFuseNet은 categorization(classification)과 generation 기반 방법을 모두 다르며, SoTA를 달성했습니다.
뿐만 아니라 Attention 기반 방법을 사용하기 때문에 attention weight의 visualization을 통해 모델 결과에 대한 intepretability도 (아마 꽤나 잘) 보여주는 듯 합니다.
1. Introduction
WHO는 전 세계의 45%의 국가에서 의사 부족 현상을 겪고 있다고 발표했습니다.
의사들에게 이런 부담을 지우는 것은 오진, 피로, 번아웃 등의 악영향을 끼칠 수 있기 때문에 CAD(Computer-Aided Diagnosis) System 통해 진단에 도움을 주는 것은 꽤나 중요한 부분입니다.
특히나 육안으로 파악하기 힘든 수준의 질병이라면.
뿐만 아니라, Visual Question Answering system과 같은 자동화된 지능 시스템을 통해 온라인 포털을 구축한다면, 의사(병원)과 환자 간 트래픽을 줄임으로써 과부하를 막을 수 있습니다.
2010년 대에 이르러 딥러닝 모델이 전반적인 자동화 시스템에 엄청난 발전을 불러왔고, 이에 따라 의학 분야에서도 뇌, 피부, 여러 장기에 대한 tumer segmentation과 같은 Image recognition task 성능의 향상이 이루어졌습니다.
NLP 분야에서도 환자의 병력을 분석해 여러가지 task를 수행하는 연구들이 많구요.
Vision과 NLP를 결합한 VQA 또한 흥미로운 태스크입니다.
의학 분야에서의 VQA는 보통 이미지와 그에 관련된 question을 받아 pre-defined limited set에 속하는 answer를 예측하거나, 혹은 sequence of words를 (생성적으로) 예측하는 task로 볼 수 있습니다.
다만, 의학 분야에서는 데이터 부족(by high labelling cost) 문제로 인해 기존의 VQA 분야보다 훨씬 적은 데이터(보통 많아야 수천개)를 사용하고 있어 Medical VQA에서 딥러닝 모델을 사용하는 데 어려움을 제기합니다.
아무튼, VQA는 Image와 Question에 해당하는 Multimodal input을 다루기 때문에 이 두 개의 모달리티에서 나오는 정보를 최대한 활용할 필요가 있습니다.
간혹 language prior라고 불리는, Question-Answer 간의 통계적 규칙만을 학습하는 문제가 있곤 합니다.
(이미지 정보를 충분히 활용하지 못함)
또한 다른 분야와는 다르게 Medical data에 담긴 정보는 너무나도 많기도 합니다(clinical report / radiology scan, ...).
게다가 scan data나 report data에는 scanning을 할 때나, reporting을 할 때 노이즈나 아티팩트가 있을 수 있습니다.
따라서, 좋은 VQA system은 이러한 data availability와 이질성 문제(heterogeneity challenges)를 다룰 필요가 있습니다.
또 다른 문제는 generation of the answer입니다.
VQA를 기본적으로 answer classification 방법으로 접근할 수도 있지만, 보다 자연스럽고 풍부한 대답을 하기 위해 answer generation 방법으로 접근하는 게 좋을 때가 많습니다.
Medical VQA Challange에서도 보통 classification 방법으로 접근하거나, generation 방법으로 접근하거나, 아니면 문제에 따라 적절히 swiching(두 개의 방법을 모두 사용)하는 방법으로 접근하곤 합니다.
Medical VQA Survey(본 velog)
더군다나 의학 분야에서 모델 예측의 투명성(transparency)과 신뢰성(trustworthiness)는 너무나도 중요하기 때문에 VQA results는 당연 해석가능해야 하구요.
결론적으로, 의학 분야에서의 VQA는 제한된 라벨링 의학 데이터를 신중하게 고려해 error를 줄이고, 동시에 해석가능한 결과를 제공하는 참신한 접근법이 필요합니다
저자들은 위에서 열거한 문제들을 다루기 위해 Attention을 기반으로 하는 멀티모달 딥러닝 모델인 MedFuseNet을 제안합니다.
이름에서 알 수 있다시피 Image와 Question, 즉 멀티모달 인풋을 attention을 활용해 (optimally) fusion하는 모델입니다.
(MedFuseNet뿐만 아니라 거의 최근 VQA 연구 / 컴피티션에서 절반 가량의 연구진이 fusion stage에서 attention을 활용합니다.
다만 다른 모델들과 MedFuseNet이 정확히 어떻게 다른지는 잘 ^^..)
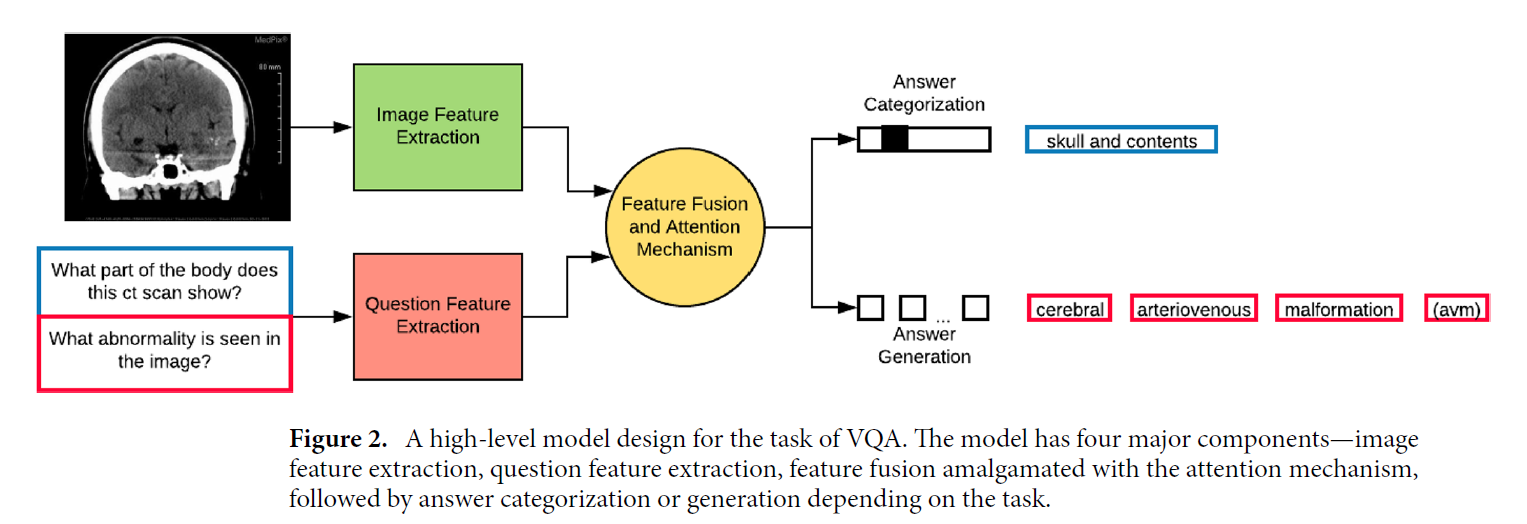
MedFuseNet은 아래와 같은 4가지 요소로 구성됩니다.
- Image Feature Extraction
- Question Feature extraction
- Feature Fusion Module
- Answer Prediction Module
추가적으로 이미지와 질문 간에 가장 관련 있는 부분을 포커싱하는 attention module도 수행합니다.
Answer Prediction Module는 답을 도출하기 위해 possible answer로부터 답을 고르는 answer categorization 서브모듈과 답을 자연어로 생성하는 answer generation 서브모듈로 이루어져 있습니다(후자의 경우 full-fledged generative decoder를 활용).
이를 통해 MED-VQA 2019와 PathVQA dataset에 대해 다른 attention 기반 모듈들을 상회하는 (아마 State-of-The-Art의) 성능을 보였습니다.
해당 모델이 기여한 점은 아래와 같습니다.
- LSTM-based generative decoder along with heuristics는 모델의 성능을 증진시킬 수 있었음.
- 방사선학과 병리학에서의 대표적인 두 개의 데이터셋에 대해 SoTA를 달성했으며, 각 component의 중요성을 다루는 (엄청나게 많은 ㅎㅎ) abalation study를 진행
- MedFuseNet의 해석가능성을 다루기 위해 다양한 어텐션 매커니즘에 대한 시각화를 진행.
위에서 말하는 along with heuristics은 후술하겠지만 Beam Search heuristic을 뜻합니다(answer를 regressive하게 생성할 때 Greedy하게 높은 확률의 단어만을 생성하는 게 아니라, 여러 후보들을 동시에 고려하는 NLP 방법론).
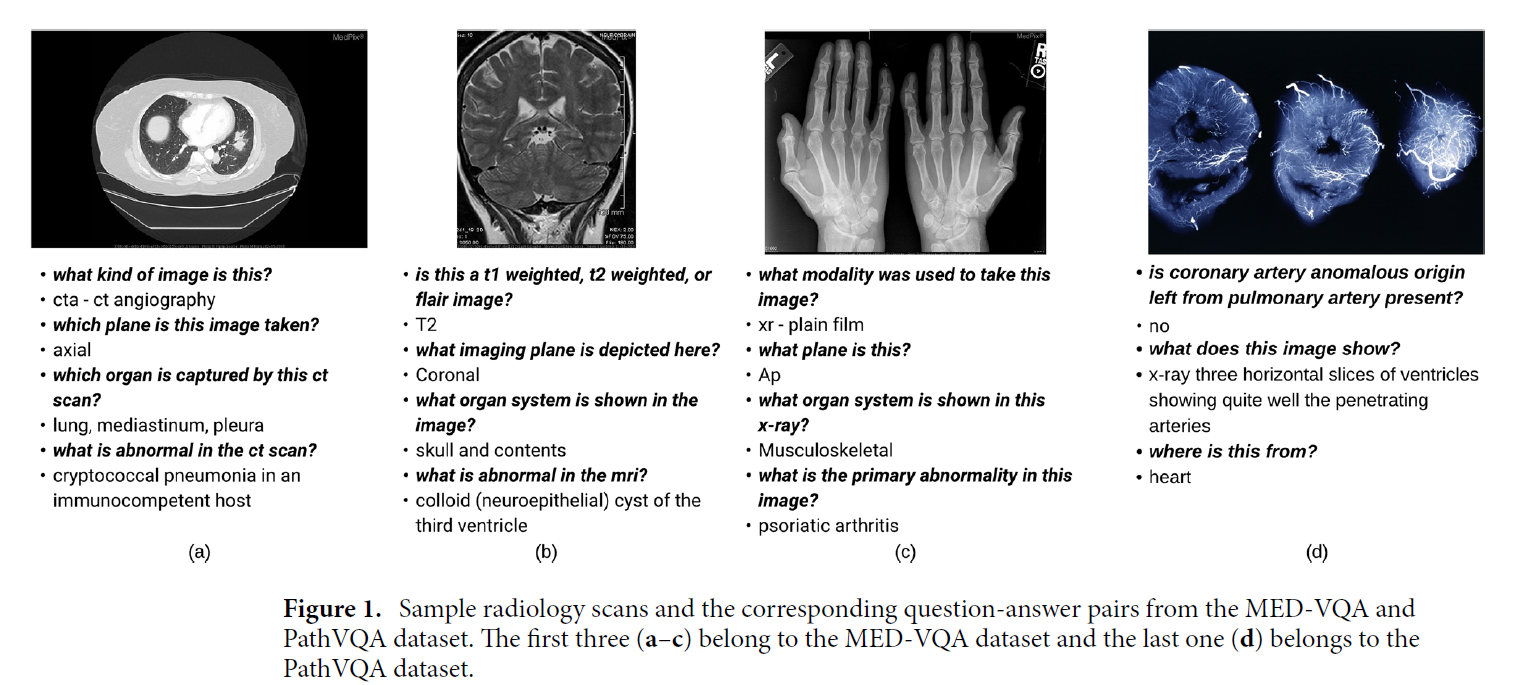
예시
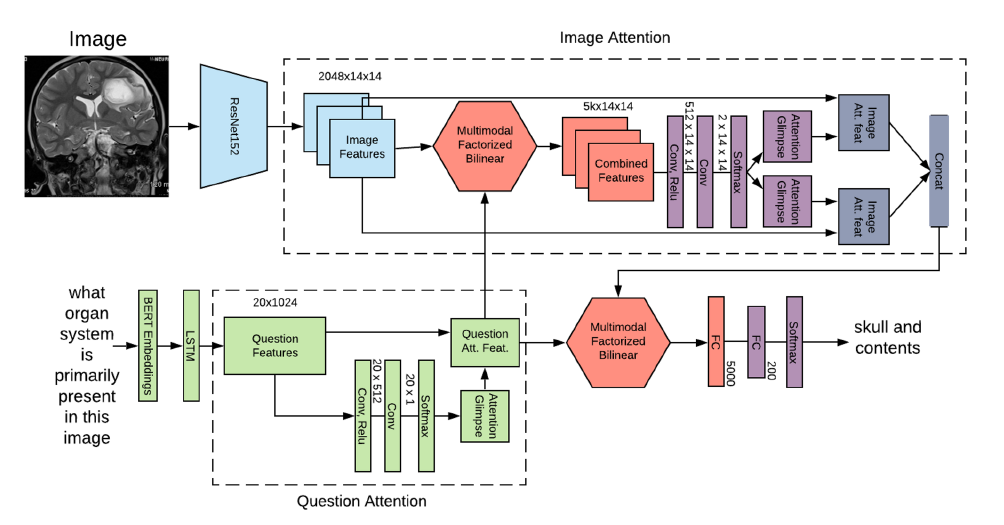
메인 아키텍처
- Image Feature Extractor, Question Feature Extractor, Feature Fusion , Answer Categorization(or Generation) module, 즉 4개의 component를 위주로 봅시다.
참고로, 위의 components와 아래에서 기술할 Related Work의 대부분은 서베이 페이퍼인 Medical VQA : Survey(본 블로그 내 글로 이어집니다)와 상당부분 겹칩니다.
그렇기 때문에 서베이 페이퍼 먼저 훑고 오는 것이 낫고, 같은 이유로 본 글의 Related Work에서는 위의 서베이 페이퍼와 겹치지 않는 내용에 대해서만 간단하게 다루겠습니다.
2. Related works
2.1. Visual Question Answering
현존하는 여러 VQA 접근법들은 크게 attention 매커니즘을 사용하는 방법론과 attention 매커니즘을 사용하지 않는 방법론 2가지로 나눌 수 있습니다.
General Domain VQA
- Image Feature와 Question Feature를 단순히 concat함으로써 Feature fusion을 하는 것이 초기 방법론.
- Attention을 활용해 이미지와 질문 간 관계를 할당하는 식으로 fusion하는 것이 그 이후 방법론.
- 단, 웬만하면 일반적인 이미지를 다루는 large dataset에 학습시키는 모델들이었음.
Medical Dedomain VQA
- 기본적으로 적은 양의 VQA dataset을 이용하게 됨.
- 다만, 많은 양의 연구가 그저 VQA를 classification problem으로만 바라봄.
- 물론, 트랜스포머를 활용한 연구인 Ren, et al(2020)도 있으며, input question을 더 잘 이해하게끔 모델을 구축한 연구인 Vu, et al(2020)도 있었음.
위의 모델들은 좋은 방향을 보여주었으나, medical VQA task를 위해 멀티모달 인풋을 다루는 일반적인 방법론은 아니었기에 다른 모델들과 성능비교가 힘들었으며, VQA 결과에 대한 해석가능성 또한 제공하지는 못했습니다.
MedFuseNet의 저자들은 제공한다.
2.2. VQA components
Image representation learning
- 생략
Medical VQA : Survey 참고
Textual representation learning
- 생략
Medical VQA : Survey 참고
Feature fusion Techniques
Image Features와 Question Features를 어떻게 통합할지에 대한 방법론
- 초기 : element-wise multiplication
- 두 Feature (vector)간 상호작용이 부족했음.
- 중기 : outer product or bilinear product of two vector
- 두 feature vector의 요소들을 전부 고려하고, 관계를 포착하는 좋은 전략임.
- 후기 : 두 벡터 간 상호작용을 최대화하고 연산량을 최소화하는 다양한 방법론들
- Multimodal Compact Bilinear Pooling(MCB)
- Multimodal Low-rank Bilinear Pooling (MLB)
- Multimodal Tucker FUsion (MUTAN)
- Multimodal Factorized Bilinear Pooling(MFB)
- 이름에서 보다시피 연산량이 비교적 낮은 bilinear pooling을 활용함.
MedFuseNet의 저자들도 위 요소들의 장점을 활용해 참신한 multimodal attention model을 제안합니다.
3. MedFuseNet Model
우선, Medical VQA에서 answer 도출을 위해 problem statements먼저 정의한 다음, 아키텍처에 대한 설명으로 넘어갑시다.
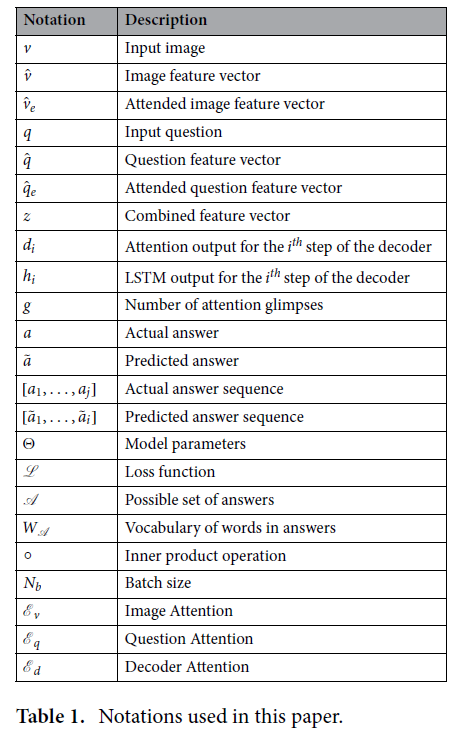
notation은 아래와 같습니다.
3.1. Problem definitions
Definition 1 : Answer Categorization task
VQA에서 정답 분류 task의 목표는 메디컬 이미지 와 이와 관련된 자연어 질문 를 받아, 가능한 answer 집합 으로부터 가장 좋은 answer 를 반환하는 것입니다.
이 때, ground truth answer를 라고 한다면, 위의 목표는 아래와 같은 식으로 기술될 수 있습니다.
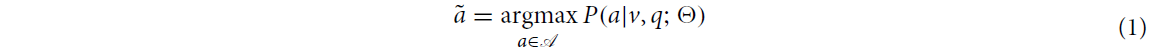
식은 자명하나, 위에서 는 모델의 파라미터이고, 이미지 는 radiology image입니다.
아마 Pathology Image는 병리학 이미지의 특성 상 다소 다른 접근법을 취하기에 명시한 게 아닐까 싶습니다.
Definition 2 : Answer Generation task
VQA에서 정답 생성 task의 목표는 메디컬 이미지 와 이와 관련된 자연어 질문 를 받아, 가능한 word vocabulary의 집합 으로부터 가장 좋은 answer sequence인 를 생성하는 것입니다.
이 때, ground truth answer sequence를 라 한다면, 위의 목표는 아래와 같이 기술될 수 있습니다.
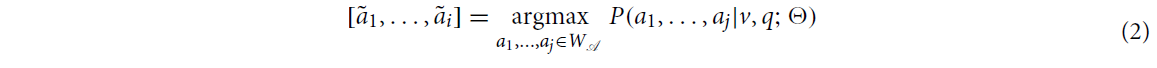
다른 부분은 Answer Categorization task와 동일하나, ground truth answer sequence의 길이는 , predicted answer sequence의 길이는 인 점이 다릅니다.
본 논문에 기술되어있지는 않지만, 후에 Implementation을 진행할 때는 아마 길이가 부족한 answer sequence에 대해 제로패딩을 하지 않을까 싶습니다).
위의 answer categorization task와 answer generation task 모두 아래의 softmax cross-entropy loss function을 목적함수로 사용합니다.
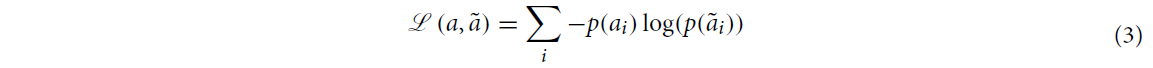
Categorization
: Ground-truth answer의 확률
: predicted answer의 확률
즉,
와 같을 것이고(or smoothed one-hot vector) - 논문 내엔 언급 x
로 기술될 것. - 역시 논문 내엔 언급 x
Generation
Categorization에서는 개의 class들에 대한 categorical cross-entropy를 비교하면 되지만(n-dim vector), Generation에서는 길이의 ground-truth answer sequence와 길이의 predicted answer sequence를 비교하게 됩니다.
(길이 처리 등 세부 사항은 Official-github 내 코드를 참고해야할듯)
3.2. Overview of the MedFuseNet model
MedFuseNet의 과정을 대략적으로 정리하면 아래와 같이 표현할 수 있을 것 같습니다.
-
--> (Image feature Extractor) -->
-
--> (Quesion feature Extractor) -->
-
-->
-
와 을 활용해 예측.
3.3. Components of MedFuseNet model
조금 더 자세히 다루어봅시다.
Image feature extraction
CNN 기반 Image feature Extractor는 정~말 많이 다루어져 왔습니다.
일반적으로 CNN output layer 직전의 penultimate layer를 image feature vector로 활용하곤 합니다.
output layer는 보통 Fully-connected layer.
즉, 위의 penultimate layer는 아마 Convolution layer의 마지막 layer를 뜻합니다.
저자들은 VGGNet-16, DenseNet-121, 그리고 ResNet-152를 image feature extractor로 실험했습니다.
본 논문 내 'Image representation learning'과 'Experiments' section에 ablation study가 존재하긴 합니다만, Medical Image는 다른 이미지에 비해 복잡한 면이 있어 skip connection 과정이 있는 DenseNet-121과 ResNet-152가 더욱 좋은 feature representation을 생성한다고 합니다.
결론적으로 ResNet-152가 성능이 가장 좋아 이를 image feature extractor로 추출했으며, ImageNet dataset에 사전학습된 모델을 사용했다고 합니다.
Question feature extraction
이 또한 "Textual representation learning" section에서 자세히 다루었는데요, 우선 자연어 내 맥락을 표현하기 위해 쓰이는 word embeddings을 다루었습니다.
다만, 예상하다시피 이런 워드임베딩 방법으로는 맥락을 제대로 파악할 수 없습니다.
NLP 분야에서는 단어 레벨의 semantics가 아닌 문장 내 단어 간 Positional semantics를 충분히 포착해야하니까요.
특히나 데이터가 적을수록 더더욱 맥락 파악에 집중해야 합니다.
아무튼, 이런 저런 이유로 인해 BERT와 XLNet같은 SoTA NLP model들은 positinal & word-level semantics를 잘 포착할 수 있게끔 설계되어 더 나은 representation을 뽑아내 ㄹ수 있습니다.
MedFuseNet 또한 question feature extractor로 BERT를 사용합니다 !
역시 "Experiments" section에 XLNet에 대한 결과도 있으며, 두 모델 다 pre-trained version을 사용했습니다.
Feature fusion techniques
Image Feature와 Question Features를 통합하는 가장 간단한 방법은 concatenation입니다. 다만, 이는 단순히 이어붙히는 것이기 때문에 두 feature간 interaction을 고려하지 못합니다.
다른 대표적인 방법은 내적(inner product)과 원소곱(element-wise multiplication)입니다만, 이 또한 두 features간 interaction을 잘 고려하지 못하기 때문에 원시적인 방법으로 여겨집니다.
외적(outer product)이나 bilinear prdocut는 두 feature 벡터의 원소들간 interaction을 잘 포착하는 robust&complete 전략입니다**(강추).
bilinear model을 간략하게 다뤄봅시다.
두 개의 vector를 각각 , 으로 정의했을 때, bilinear model은 아래와같이 정의됩니다.
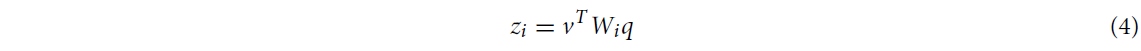
벡터-행렬 연산이므로 는 차원을 가지며, output 는 차원을 갖습니다.
라고 쓰여있긴 하지만, 는 scalar이고, 가 차원이라 보는 게 맞을 것 같습니다.
아무튼, 해당 모델은 전체 parameter로 입니다.
하지만, 만일 로 정의할 경우 projection matrix 는 의 parameter 개수를 가지기 때문에 너무나 많은 연산량을 요구합니다.
그렇기 때문에 최근에는 (위에서 잠깐 언급했던) MCB, MUTAN, MFB 등 다양한 Bilinear Pooling 기법을 도입해 이런 문제를 다루는 추세입니다.
주로 outer product projection matrix 를 분해하는 방법으로 Bilinear Pooling 과정을 단순화하는데요, 이 중 MFB는 실행시키기도 쉽고 좋은 convergence rate을 가지기 때문에 MedFuseNet또한 MFB를 택했습니다.
이를 단순히 사용하는 것을 넘어서 MedFuseNet은 local minima로 수렴하는 문제를 피하기 위해 MFB module의 output에 power noramlization & L-2 normalization을 적용했씁니다.
근데 이 normalization들은 original MFB에서도 사용하는 것들이라 MedFuseNet만의 방법은 아니긴 합니다.
Attention mechanisms
전형적인 VQA 모델은 이미지와 질문으로부터 feature vector를 추출하고, 이를 위에서 기술한 fusion technique을 사용해 fuse한 다음, fused vector로 부터 answer를 예측합니다.
하지만, input image에 밀접하게 관련된 question은 구체적이고 많은 image의 맥락을 필요로 합니다.
단순하게 fusion해서는 question이 충분히 image에 대한 정보를 소화하지 못합니다.
그렇기 때문에 MedFuseNet의 저자들도 이런 관점에서 가장 잘 작동하는 Attention기법을 도입합니다.
더욱 자세히는, Image-Attention과 Image Question Co-Attention을 도입해 question에 답하는 것과 관련있는 Image의 맥락을 포착하고자 했습니다.
아래에서는 이 2가지 종류의 Attention에 대해 다룹니다.
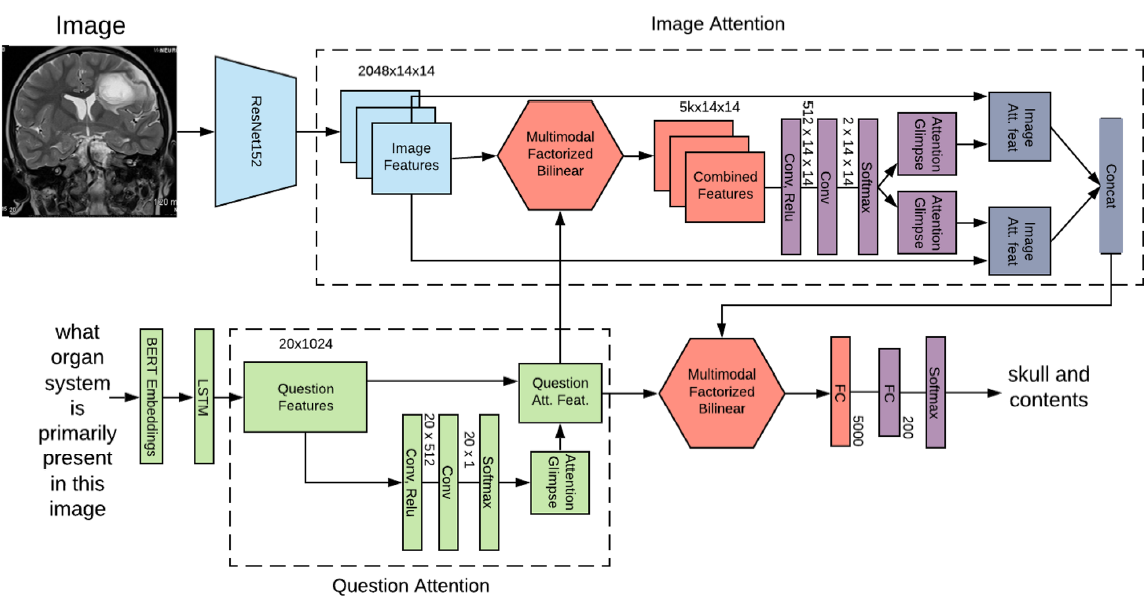
- Question attention 매커니즘을 이용해 attended question features 를 얻습니다(Question의 key factor)를 더욱 강조(?)).
- 이렇게 얻은 attended question features와 image features를 MFB로 결합해 Image attention 매커니즘을 행해줍니다.
- 이렇게 얻은 attended image features를 MFB 알고리즘을 이용해 attended question features와 다시 결합한 다음, answer classification module을 구축해줍니다.
Image Attention
Image Attention은 기본적으로 MedFuseNet의 attention을 (input question을 기반으로) 이미지의 가장 관련있는 부분으로 확장하는 것을 목표로 합니다.
이는 두 멀티모달 input 사이의 상관관계를 구축해주기 때문에 더 빠르게 수렴하는 것을 도와줍니다.
- image features 와 question features 를 fusion technique을 이용해 결합합니다(아래 알고리즘의 line 21).
- 이렇게 결합한 feature vector로부터 attention maps을 연산합니다(lines 22-23).
- input image features 에 attention glimpses를 overlay해 **attended image features vector 를 얻습니다.
대강 흐름만 보고 후에 pseudo-code를 보고 이해하는 것을 추천드립니다.
또한 위에서 말하는 question features 는 (아마) 아래의 Co-attention을 통해 얻은 일 것이기에 뒷부분을 보고 나서야 이해할 수 있습니다.
Image-Question Co-Attention
Image attention 매커니즘은 이미지의 중요한 부분에 초점을 맞춥니다만, 이는 question 전체를 고려합니다.
반면, co-attention mechanism은 question의 중요한 part는 image attention을 강화하는데 쓰일 수 있는 question에 대해서만 연산될 수 있다는 직관을 이용합니다*.
A co-attention mechanism exploits the intuition that the key parts of the question can be solely computed for the question which can further be used to enhance the image attention
Fig.3에 나와있는 과정을 정리하면 아래와 같습니다.
- Question attention mechanism 를 이용해 **attended question feature vector 를 연산합니다.
- 그 후 이 를 image attention mechanism의 input으로 활용합니다(대신, lines 8-18 in Algorithm 1).
조금 괴상?한 과정처럼 보이는데, 보통 VQA에서 Image 정보를 제대로 소화하기 힘들기 때문에 Image Attention을 상당히 강조한 아키텍처로 보입니다. 겸사겸사 Question features도 중요한 부분만 포착해 representaiton을 뽑아내구요.
Introduction에서 다루었던 Issue & Challenge를 모두 반영한 모델이기 때문에 이에 대해
3.4. MedFuseNet model for medical VQA tasks(알고리즘)
위에서 잠깐 언급했던 것처럼 MedFuseNet은 모델 복잡도를 줄이고 답변 예측 성능을 높히는 방향으로 학습합니다.
3개의 메인 컴포넌트는 (a) pre-trained ResNet-152 for image feature extraction, (b) pre-trained BERT for question feature extraction (c) MFB for feature fusion 이구요.
또한, attention 테크닉을 활용해 모델이 image와 question의 가장 관련있는 부분만 보도록 유도하고, 이로부터 예측을 행합니다.

이쁘게 잘 쓰여 있습니다. 논문에 적혀있지 않은 특이사항만 정리해봅시다.
-
line 7 : linear 7에서 MFB를 으로 정한다.
-
lines 15-16 : image feature 와 question features 는 각각 의 길이를 가지기 때문에 FCN을 통해 차원으로 맞춰줍니다.
-
line 17 : 의 내적을 통해 vector 를 만든다고 하는데, **상식적으로도 그렇고 기호()적으로도 그렇고 내적이 아니라 원소곱(element-wise multiplication or Hadamard product)로 보는 게 맞는 것 같습니다.
- 이는 MFB의 original paper 내 figure & body를 봐도 알 수 있습니다.
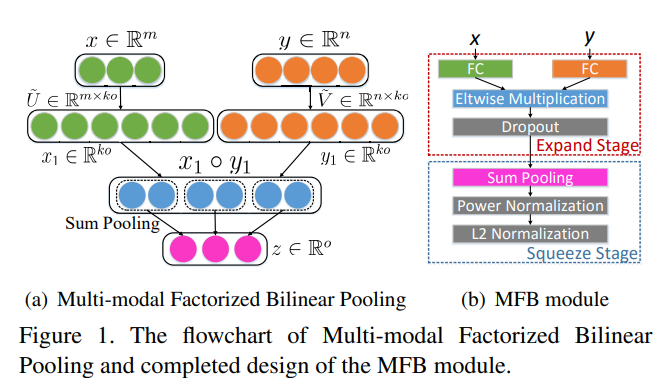
- (왼쪽에 그림, 오른쪽의 Eltwise Multiplication)
- 근데 아카이브도 아니고 정식 투고 저널 페이퍼인데 inner product랑 Hadamard product랑 헷갈리는게 말이 되나싶긴 합니다.
- 이는 MFB의 original paper 내 figure & body를 봐도 알 수 있습니다.
-
lines 15-17 : 는 입니다. 즉, lines 15-17에서는 차원을 확대하고,
-
lines 18-19 : Pooling과 Normalization을 거치면서 차원을 축소한다고 보면 될 것 같습니다.
-
line 18 : 아마 두 번의 MFB 모두 의 window size를 사용하는 것 같습니다.
-
line 21 : 는 attention glimpses(엿보기)의 개수입니다(2).
-
lines 21-24 : 위 과정에서 얻은 차원의 joint features를 로 점점 낮춰 2개의 Attention map(아마 image features 와 동일한 scale)을 얻습니다.
-
lines 25-29 : 이렇게 얻은 softmax-attention map을 lines 25-29에서 image features 와 곱해주는데, 여기서 또한 element-wise multiplication으로 보는 게 맞을 것 같습니다.
-
lien 31 : 최종적으로 이렇게 Attention weight를 부여한 attended image feature vector 2개를 더해 를 반환하게 됩니다.
-
참고로, Question features는 , Image features는 입니다.
-
1024와 2048을 5000(혹은 15000) vector로 바꿔서 element-wise multiplication이 나오는 것은 알겠는데, 어떻게 20차원과 14x14=256차원이 처리되는지, 그리고 왜 결과가 5000x14x14가 나오는 지는 코드를 뜯어봐야 알 수 있을듯합니다.
결론적으로,
- pre-trained ResNet과 BERT를 사용하기 때문에 더 나은 general features를 뽑아낼 수 있다.
- MFB로 인해 연산량을 많이 낮추었고, 두 모달리티 간 fusion information을 잘 보존할 수 있었다.
- 연산량 parameter를 낮추었기 때문에 데이터가 적은 MED-VQA dataset에서의 과적합을 방지할 수 있었다.
- attention & co-attention은 기존의 attention을 input에 중요한 부분에 할당되게끔 최소화했습니다.
- 모델이 판단을 내리기 위해 고려할 차원(space)가 줄었다고 할 수 있습니다.
Answer categorization
위에 알고리즘대로 진행되며, 최종적으로 line 7에서 얻은 joint vector 를 활용해 classification loss, update 등을 진행합니다.
Answer Generation
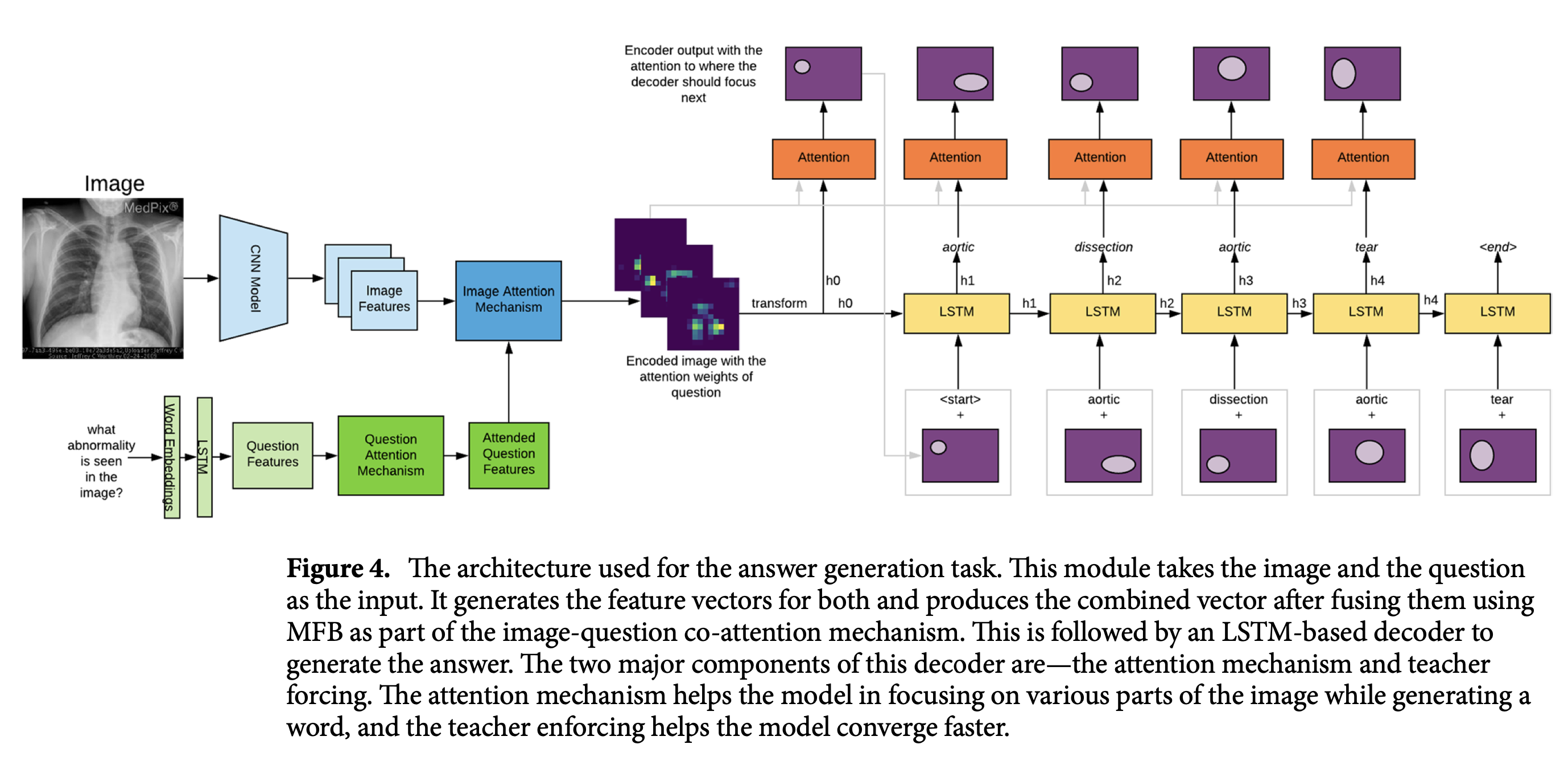
- Teacher Forcing : sequence generation 자체가 어렵지만, Medical 분야에서는 데이터도 적기때문에 수렴하기 어려울 수 있다. 이를 보완하기 위해 Teacher Forcing을 적용해주는 편이 좋다(학습할 때 target token을 매 time step마다 제공함 - 단, 손실만 계산하고).
- 애초에 Scheduled Sampling이 좋을 수 있음.
- Co-Attention mechanism: 기본적인 Encoder-Decoder Attention
- Beam Search : model이 soft-max의 결과 중 가장 큰 확률을 보이는 token만 추적하는 게 아닌, 여러 후보를 가지고 가는 것.
우선, 위 그림에서 볼 수 있다시피 attended image features 는 Decoder의 hiden state에 먼저 주어진다.
그 후, decoder의 번째 step에서, attention mechanism의 output 를 ground truth **와 concat해, LSTM cell로 들어갑니다.
그 결과 를 얻게 됩니다.
 0
0
4. Experiments
여러가지 실험을 진행했답니다.
Datasets for answer categorization task
MED-VQA(2019)

- 4200 medical images / 각 이미지에 대응되는 (보통 여러 개의) questions
- Three categories
- Modality - 3825 triplet(image-question-answer) / 36 classes
- Medical image의 modality
- Plane - 3825 triplet / 16 classes
- medical image가 어떤 평면에서 왔는지
- Organ - 3825 triplet / 10 unique organ systems
- 어떤 장기기관의 medical image인지.
- Modality - 3825 triplet(image-question-answer) / 36 classes
- question의 평균 길이는 8(maximum :13)
PathVQA
- pass
Datasets for answer generation task
- pass
Dataset preprocessing
- medical image는 으로 resizing
- pre-trained model들이 224x224 이미지를 input으로 많이들 받으신다.
- Question은 NLTK를 활용해 토큰화하고, dataset의 voca에 따라 정수인코딩을 수행합니다.
- (아마) Answer Classification에는 100개 가량의 단어밖에 안 쓰입니다.
- 패딩도 적당히.
VQA baseline models for comparision
- VIS + LSTM
- Deeper LSTM + Norm. CNN
- Stacked Awttention Networks(SAN)
- Hierarchical Co-attention (HICAt)
- Bilinear Attention Networks (BAN)
참고로, Answer Generation에 적합한 베이스 모델은 없다고 합니다.
Evaluation metrics
Dataset과 모델들은 대강 위에서 1다루었고, 전체적인 성능을 평가하기 위해서 training, validation, testing splits을 모두 합친 후 5-fold cross-validation을 진행했다고 합니다.
Answer categorization task
저자들이 진행한 평가 메트릭은 아래와 같습니다.
1. Accuracy
2. AUC (in ROC curve - Receiver Operator Characteristics)
3. AUC (in PRC curve - Precision-Recall Curve)
Answer generation task
- pass
Implementation datails
Answer Categorization
-
Image feature Extractor : Keras의 pre-trained model들.
-
Question feature Extractor : Embedding-as-a-Service (from pre-trained BERT and XLNet models)
-
question : 20 tokens으로 패딩
-
combined feature vector : MFB,MUTAN에는 5000, MCB에는 16000
-
optimizer = ADAM()
-
batch size : 32
-
epochs : 100
-
metrics : Sckit-Learn
-
fusion baseline code : MCB, VQA PyTorch, OpenVQA github repo 참조.
Answer Generation
- Decoder part : Image-Captioning-Pytorch와 거의 동일.
- LSTM step 개수 : 1024(???)
- optimizer : ADAM(
- epochs : 30
- batch size : 32
- metrics : BLEU-score in NLTK Module
e.t.c.
- three baseline code : SAN-VQA 참고
- HiCat baseline code : HiCAt 참고
- BAN code : ban-vqa 참고
- 해당 모델은 FasterRCNN feautres를 참고하는데, 이는 FasterRCNN-Visual Genome을 참고하였음.
MedFuseNet : https:// github.com/ dhruv sharm a15/ MEDVQA.
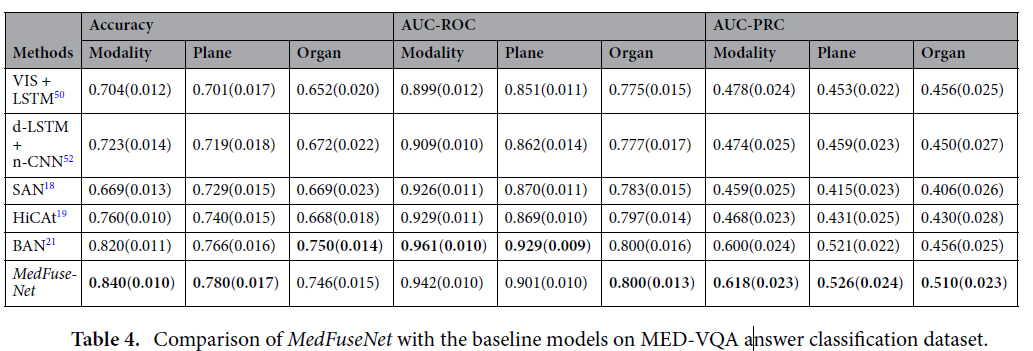
Experimental results(Quantative)
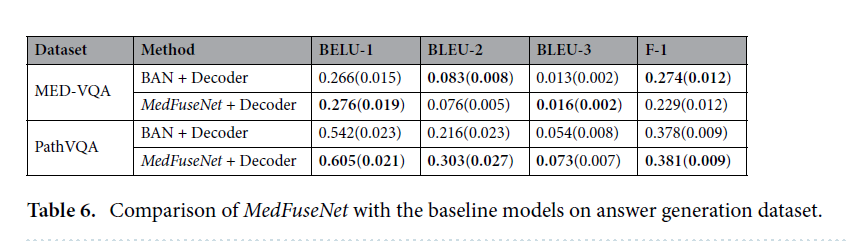
Answer classification dataset
Answer generation dataset
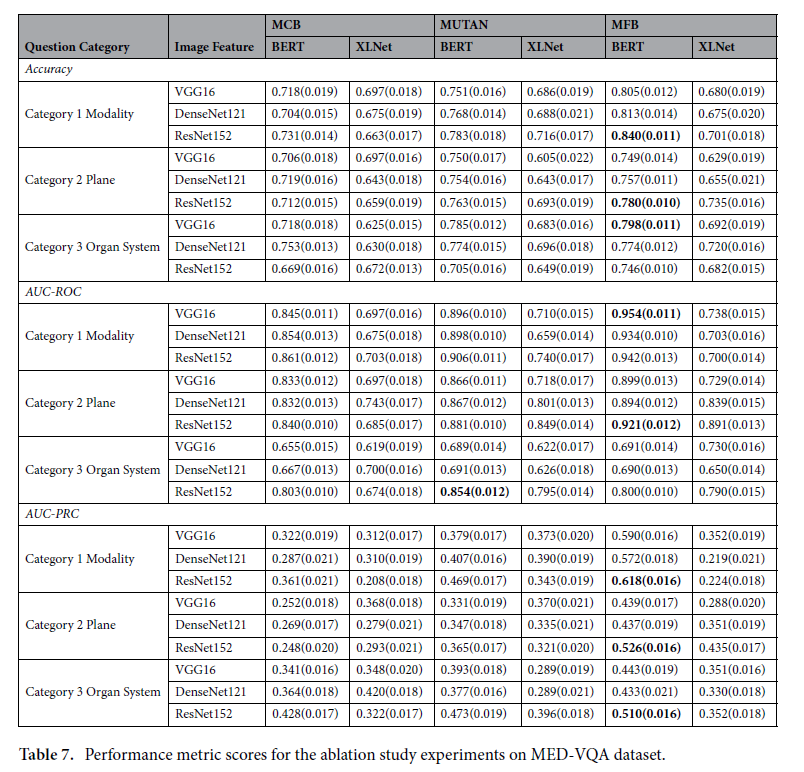
Ablation study
Attention Visualization(Qualitative)
Image Attention
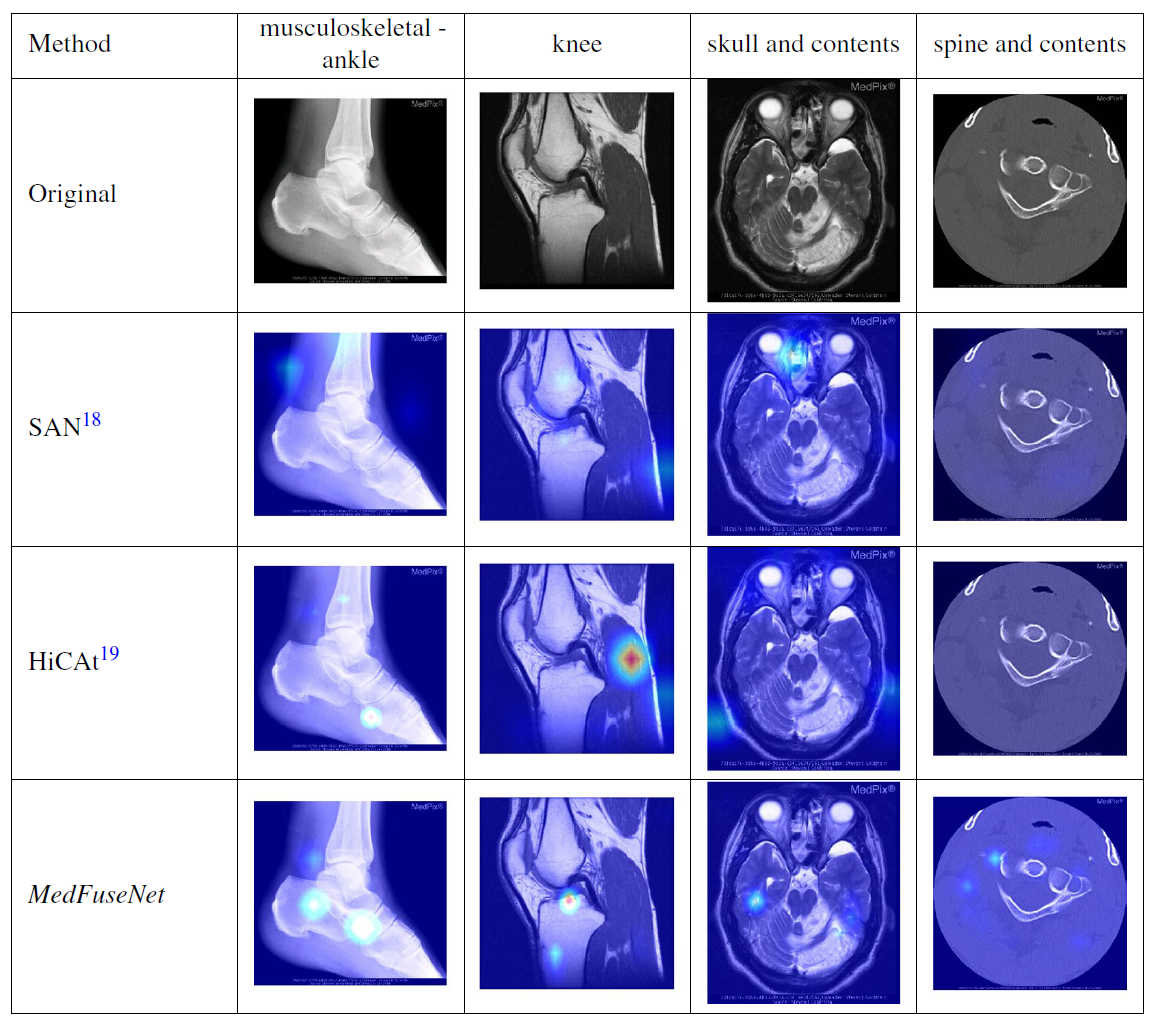
대략 critical point를 잘 찾아낸다고 하였으나, 판단할 수 있는 지식이 나에겐 없으므로 패스하도록 하겠습니다.
다만, 본문 내에 Attention map을 제공하는 것은 판단 과정에 충분한 정당성을 부여한다고 기술되어 있으나, 여전히 Attention map만으로 설명을 제공하는 것은 부족한 상황이긴 합니다.
Co-Attention
그 외에도, 아래 그림은 Image와 question을 겹쳐, MedFuseNet의 co-attention schema를 분석한 그림입니다.
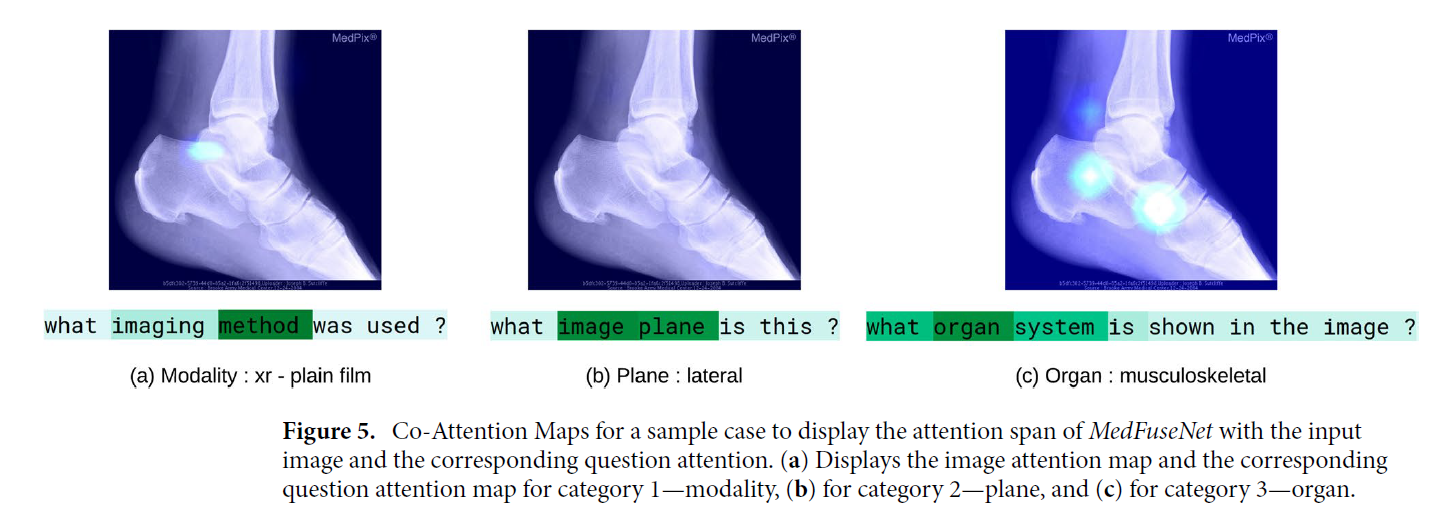
그런데 사실 Medical VQA에서 question이라 해봐야 method, system, plane, organ과 같이, 사실상 '1개의 단어'만 봐도 풀 수 있는 질문들이 많기 때문에, 의미가 조금 퇴색되긴 한다.
하지만, organ이냐 plane이냐에 따라서는 narrow-attention을 취하는지, wide-attention을 취하는지는 분명 다르기 때문에 이에 대해서는 고려해볼만 하다.
Answer Generation-related attention
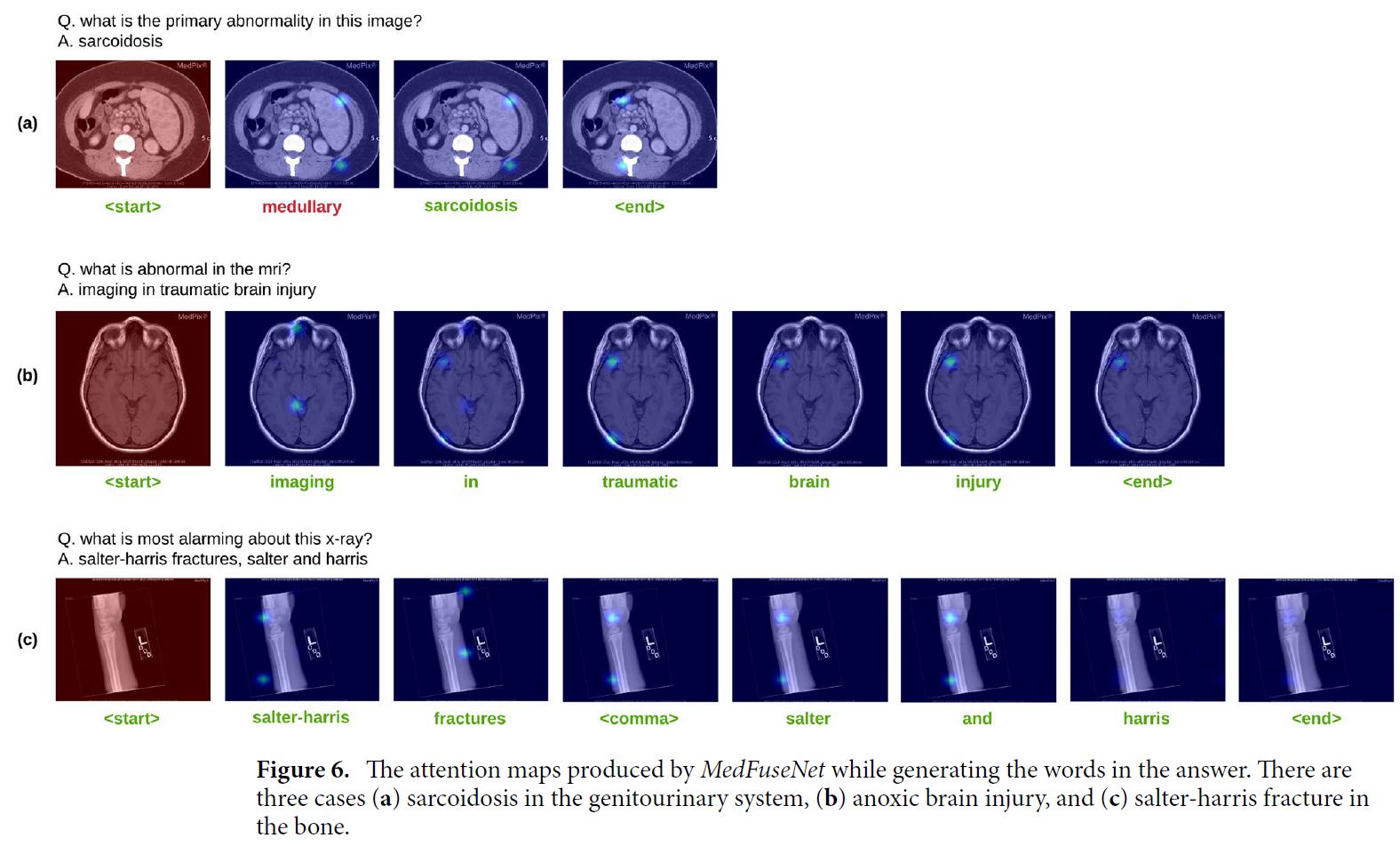
위의 사진은 answer sequence를 생성할 때 얻어진 attention maps을 시각화합니다.
각 time step에서의 attention map은 다음 step에도 feeding됩니다.
- (a) : genitourinary organ system 내 sarcoidosis를 예측하는 그림.
- MedFuseNet은 단어 "medullary"를 생성하는데, 이는 그림 내에 위치한 영역과 관련된 부위라고 합니다(수두근).
- (b) : 뇌 손상에 관련된 질문과 이미지입니다.
- 잘 찾는다고 합니다.
- (c) : 골절인데, 주로 뼈 사이 이음새에서 발생하는 골절이라고 합니다.
- comma(",")를 이해하는 것도 좋지만, 각 word에 따라서 각기 다른 구역을 attending하는 것을 볼 수 있다.
- 이로 인해 모델이 골절의 특별한 종류를 구분하고, localize할 수 있는 능력이 있는 걸 볼 수 있습니다.
Conclusion
Code에서 신경써야 할 것.
- Image Feature와 Question Features가 MFB로 결합되는 부분 차원 체크.
- origianl MFB paper에서는 일 때 를 권장했다. 라면 으로 줄어드는 게 맞지만, 본 MedFuseNet은 임에도 불구하고 (Fig.3)에는 output vector가 으로 나와있다.
- 그러려면, 애초에 FCN으로 two features를 15000차원으로 사영시켜야 Pooling 이후에 output이 5000이 나온다. 이 부분 차원 체크하기.
