Paper: https://arxiv.org/pdf/2111.10056.pdf

0. Abstract
저자들은 Medical VQA와 관련한 내용을 크게 세 가지로 나눠서 다룹니다.
- Open medical VQA dataset(source, quantity, feature)
- Approaches in medical VQA
- Challaenges and Future research directions
1. Introduction
- Medical VQA는 일반적으로 임상적인 의사 결정을 보조하고, 환자의 참여를 증진하는 것을 목표로 합니다.
- 다른 Medical AI는 질병과 데이터, organ types 등을 미리 정의하고 진행하지만, VQA는 일반적으로 free-form questions을 이해해 믿을만한, 그리고 유저 친화적인 답변을 반환해야 합니다.
최근 연구에 따르면 medical VQA는 몇 개의 업무를 할당받았다고 합니다.
- 의사가 의뢰하면 CT나 MRI를 해석하는 '방사선 전문의'(radiologist)
- 실제 평균적인 방사선사들은 CT나 MRI를 3~4초 안에 해석해야 하낟고 합니다.
- 이런 이미지 연구 외에도 환자나 의사로부터 하루에 수십 건의 전화를 받기 때문에, 굉장히 비효율적입니다.
- 그렇기에 Medical VQA는 어느 정도 의사의 요청에 따른 답변을 반환함으로써 훨씬 더 효율적인 workflow를 챙길 수 있습니다.
-
조직 검사를 시행해 다른 의사들이 의사결정을 내리는 데 도움을 주는 병리학자(pathologist)
이런 전문적인 역할(professional role)도 할 수 있지만, 단지 knowledgeable assistant로서 의사의 판단에 보조를 해주어 오진을 줄이는 역할을 할 수 있습니다(second opinion 제시).
필자는 오히려 이 assitant의 역할이 (현재는)더 옳다고 생각합니다.
완전한 Medical VQA System이 구축된다면 의료 업계의 전방위에서 활동할 수 있겠지만, 당연히 먼 얘기입니다.
Medical VQA는 (정책적인 부분은 고사하더라도) 기술적으로 구현하기 굉장히 까다로운데, 일반적으로 이유는 아래와 같습니다.
- large-scale medical VQA dataset을 구축하기가 힘들다.
- 비용도 비싸고, 전문의의 전문지식도 필요로 한다.
- 이미지로부터 Question&Answering pair를 생성할 수가 없습니다.
- 이미지를 바탕으로 질문에 답변하는 것(QA)은 specific design을 필요로 합니다.
- VQA뿐만 아니라, Medical Image 내에서는 병변(lesion)이 너무나도 미세하기 때문에, 매우 세밀한 스케일(fine-grained scale)에 집중해야 합니다.
- 그렇기에 관심 영역을 정확하게 포착할 수 있는 segmentation 테크닉도 필요로 합니다.
- Question이 매우 전문적이기 때문에 일반적인 언어 데이터베이스가 아닌, medical knowledge base에 학습될 필요가 있습니다.
2. Datasets and performance metrics
2.1. Datasets
(저자들이 알기로는), 지금까지 7개의 public-available medical VQA dataset이 있다고 합니다.
- VQA-MED-2018
- VQA-RAD
- VQA-MED-2019
- RadVisDial
- PathVQA
- VQA-MED-2020
- SLAKE
시간순입니다.
아래는 각 데이터셋의 특징을 다룬 테이블과 예시 샘플입니다.
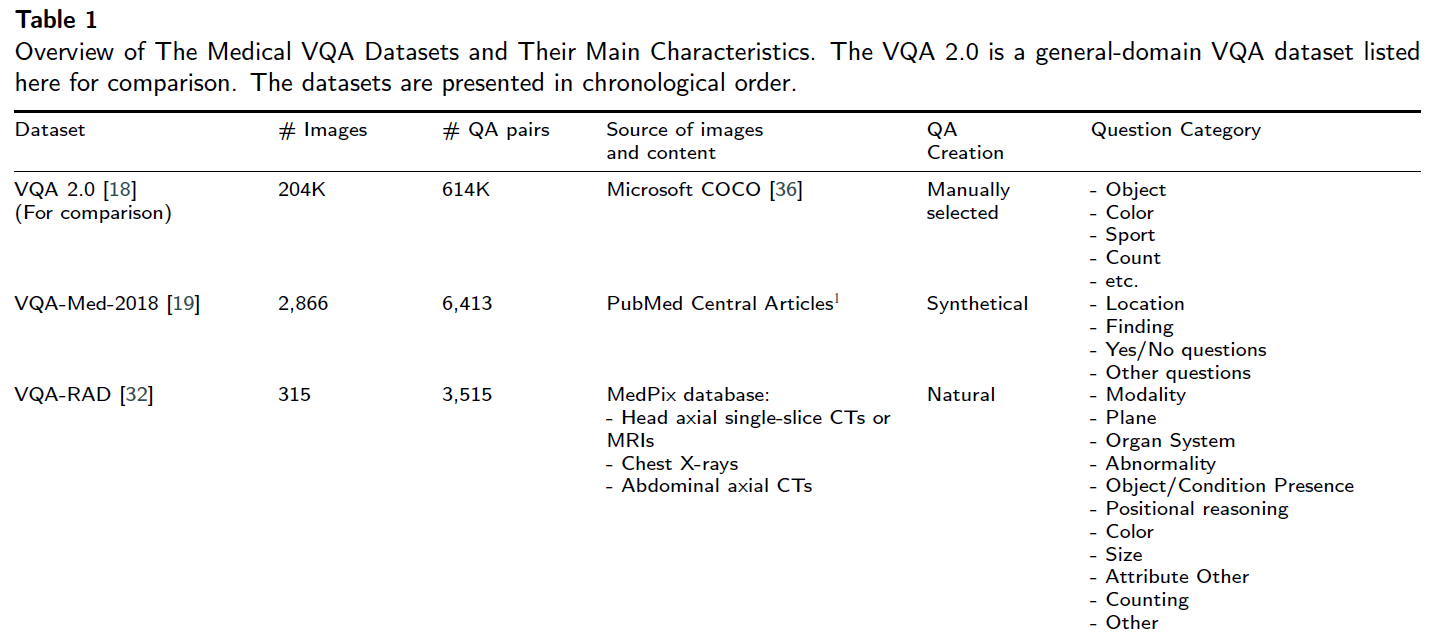
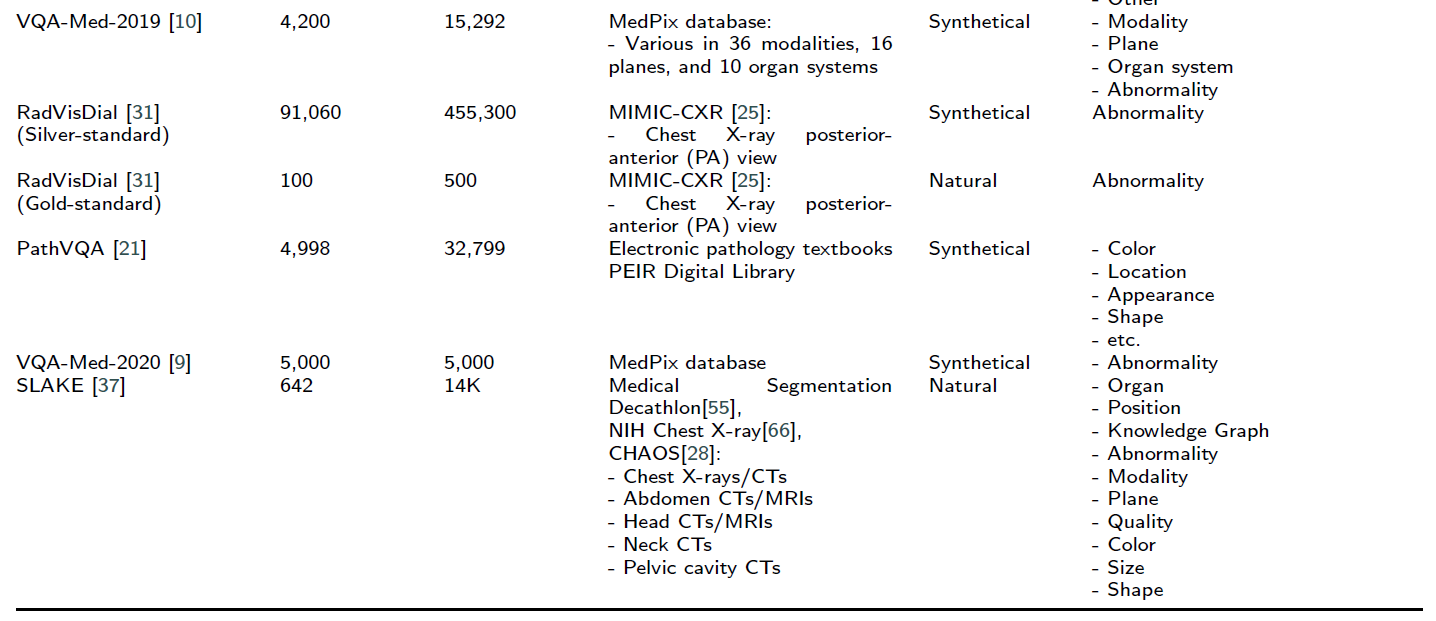
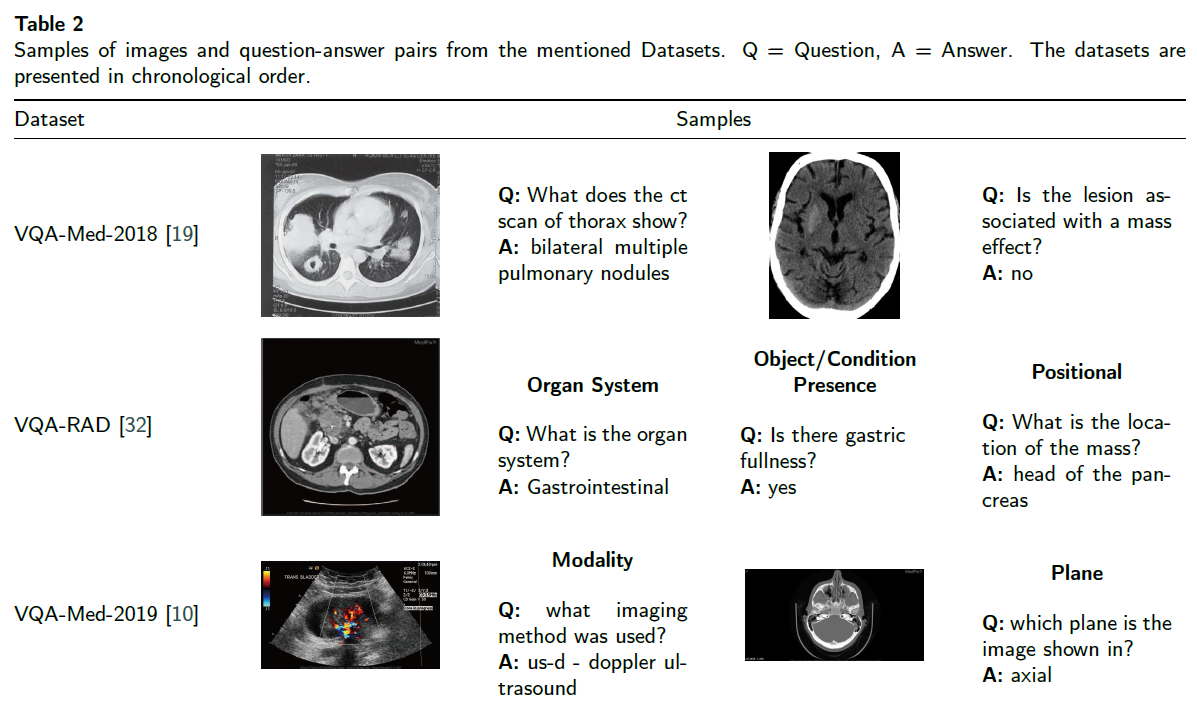
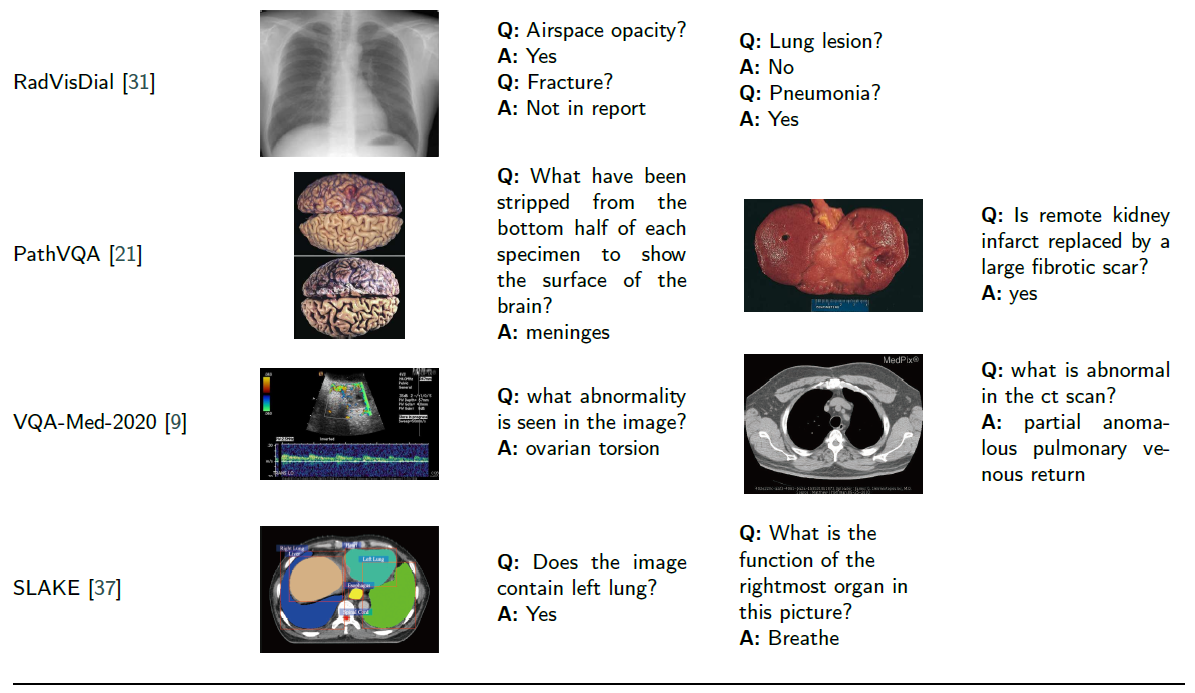
조금 더 자세히 다뤄봅시다.
2.1.1. VQA-Med-2018
VQA-Med-2018은 처음으로 공개된 데이터셋입니다.
Question-Answering pairs(QA pairs)는 반자동적인 방식으로 생성됐다고 합니다.
데이터셋 구축 방법은 아래와 같습니다.
- Rule-based Question Generation(QG) system을 이용해 가능한 QA pairs를 생성합니다.
- 문장 단순화, answer phrase 인식, 질문 생성, 후보 문장 서열화 등을 이용합니다.
- 두 명의 전문가(one expert in clinical medicine)이 생성된 모든 QA pair를 점검합니다.
한 명은 의미적으로 옳은지, 그리고 다른 한 명은 임상적인 관련성이 타당한지 점검했다고 합니다.
2.1.2. VQA-RAD
VQA-RAD는 2018년에 제안된 radiology-specific dataset입니다.
해당 이미지셋은 head, chest(흉부), abdomen(복부) sample을 골고루 포함합니다.
현실의 임상 상황에 가까운 question을 얻기 위해 전문의들에게 free-form & template structure에 대한 question을 받고, 검증 과정을 거쳤습니다.
answer types은 closed-ended, open-ended 두 종류 모두 포함합니다.
데이터셋의 양 자체는 적지만, 해당 데이터셋은 AI radiologist로서 어떤 식으로 답변을 해야하는 지에 대한 필수적인 정보들은 충분히 보장해싿고 합니다.
2.1.3. VQA-Med-2019
2.1.1.에서 다룬 VQA-Med의 후속버전입니다.
ImageCLEF 2019 challenge에서 주어졌습니다.
2.1.2.의 VQA-RAD에서 영감을 받아 추가적인 4개의 질문 카테고리를 다루었습니다.
- modality
- plane
- organ(이미지 내 장기 기관 예측)
- abnormality
위의 3개(modality, plane, organ)은 일종의 classification tasks로 볼 수 있고, 나머지 하나(abnormality)는 answer generation task로 볼 수 있습니다.
아래는 일부 예시입니다.


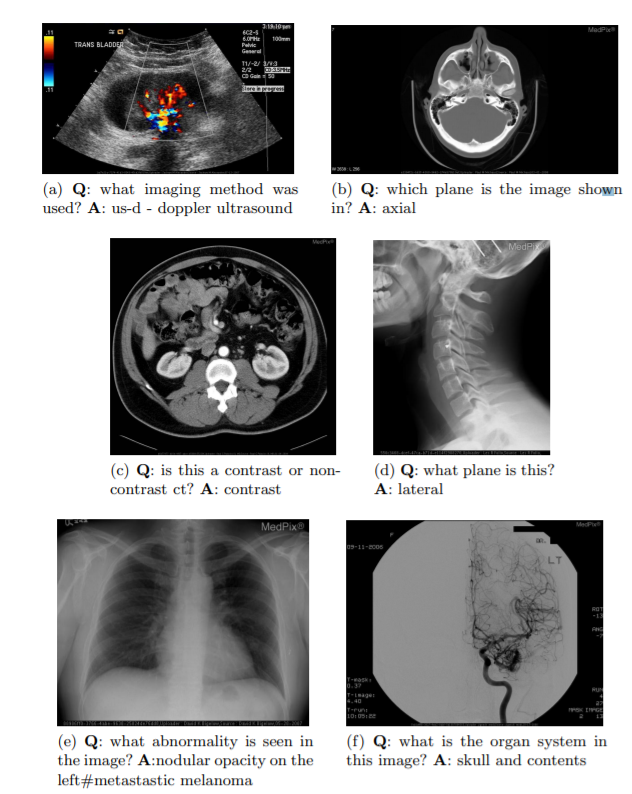
출처 : [VQA-Med: Overview of the Medical Visual Question Answering Task at ImageCLEF 2019](http://ceur-ws.org/Vol-2380/paper_272.pdf
2.1.4. RadVisDial
RadVisDial은 최초로 공개된 방사선학(radiology)에서의 visual dialog dataset입니다.
visual dialog는 일반적인 VQA보다 실용적이고, 복잡한 다수의 QA pairs로 구성되어 있습니다.
이미지는 MIMIC-CXR에서 골랐으며, MIMIC-CXR는 각 이미지에 대해 14개의 Label(13개는 이상현상, 1개는 이상소견 없음)을 갖는 주석이 포함된, weel-structured relevant report를 제공합니다.
RadVisDial dataset은 아래 두개의 데이터셋으로 구성됩니다.
- silver-standard dataset
- 각 이미지와 관련 있는 plain text reports를 사용해 dialogue를 (합성적으로) 생성
- 각 dialogue는 5개의 질문을 포함(13개 중 임의로 샘플링)
- 이에 대응하는 답변은 source data로부터 자동적으로 추출됨.
- 답변은 yes, no, maybe, not mentioned 4가지만 가능
- gold-standard dataset
- Dialogue를 두 명의 방사선 전문의의 대화로부터 수집
- 적당한 annotation 가이드라인을 따름
- 100개의 이미지만 glod-standard 방식으로 라벨링됨
RadVisDial dataset은 실제 의학 분야에서의 대화를 최대한 보장하려 했으며, 환자의 병력또한 도입해 더 좋은 정확도를 도출하는 데 도움을 주었습니다.
2.1.5. PathVQA
PathVQA는 이름에서 알 수 있다시피 병리학(pathlogy)을 위한 VQA 데이터셋입니다.
뭐 이런 저런 과정을 통해 데이터셋을 구축했을 거고, Question은 아래와 같은 카테고리로 나눌 수 있습니다.
- what, where, when, whose, how, how much/how many, yes/no
전체 질문들 중 50.2%는 open-ended question입니다.
yes/no questions은 8,145개가 yes, 8,189가 no입니다.
해당 데이터셋은 American Board of Pathology(ABP)의 병리학 자격증 시험을 따르게끔 설계되었기 때문에 어느 정도 AI Pathologist를 검증할 수 있는 데이터셋이기도 합니다.
2.1.6. VQA-Med-2020
세번째버전.
330개의 abnormality 문제가 최소 10번 이상씩 포함되어 있는 데이터 셋입니다.
본 데이터 셋에서는 VQG(Visual Question Generation) task가 의학 도메인에 최초로 도입됐습니다.
VQG는 image와 관련된 question을 생성하는 태스크입니다.
1001개의 방사선 이미지와 2400개의 관련 Question으로 구성.
2.1.7. SLAKE
SLAKE는 semantic label과 structural medical knowledge base를 모두 제공하는 종합적인 데이터셋입니다.
이미지 : open soursce dataset에서 추출
라벨 : 숙련된 의사가 제공
semantic label은 Segmentation mask와 bounding boxes를 제공합니다.
medical knowledge base는 knowledge graph(지식 그래프) 형태로 주어집니다.
특히, 지식그래프는 <심장, 기능, 혈액 순환을 돕는다> 처럼 triplet 형식을 갖습니다.
지식 그래프를 도입했기에 장기기간의 기능, 예방 대책 등 외부 지식 기반 question도 허용합니다(다룰 수 있습니다).
3. Performance Metrics
VQA는 Vision과 Language가 통합된 Multi-modal이기 때문에 **성능 평가 척도 또한 Classification / Language 두 가지로 나눌 수 있습니다.
- Classification-based metrics
- accuracy & F1 score
- answer를 일종의 분류 문제로 여겨 accuracy, precision, recall 등을 계산
- 위에서 다룬 7개의 Dataset 또한 모두 classification-based metrics을 사용함
- Language Metrics
- Translation, Image captioning과 같은 일반적인 sentence evaluation과 동일
- VQA-Med(2018-2020), PathVQA가 language metrics을 포함함
- 특히, 두 문장 간 유사성을 판단하는 BLEU SCORE를 사용
- 뿐만 아니라 각 TASK에 맞는 Word-based Semantic Similarity, Concept-based Semantic Similarity 등을 도입하기도 했음(VQA-Med-2018).
위에서 예상할 수 있다시피, Medical VQA는 General VQA와 꽤나 다른 특징을 보여줍니다.
가령 task를 방사선학(radiology)이나 병리학(pathology)쪽으로만 제한한다든지,
modality(t1-t2weighted, ultrasound, etc)나 organ까지 제한한다든지..
또한 Medical VQA에서는 질문들 자체가 하나의 객체나 속성에 대해서 주로 물어보는데, 일반적인 VQA와 비교하면 질문들 카테고리도 굉장히 작을 뿐만 아니라 데이터의 양적인 측면에서도 매우 적은 것을 알 수 있습니다.
4. Method
일반적인 도메인에서는 LSTM Q+I가 거의 베이스라인으로 사용됩니다.
이는 joint embedding approach라 할 수도 있습니다.
이미지랑 질문을 임베딩해 같이 사용하니까요.
아래 그림에서 나타나있는 것과 같이, 이 frameworks는 4가지 요소로 구성됩니다.
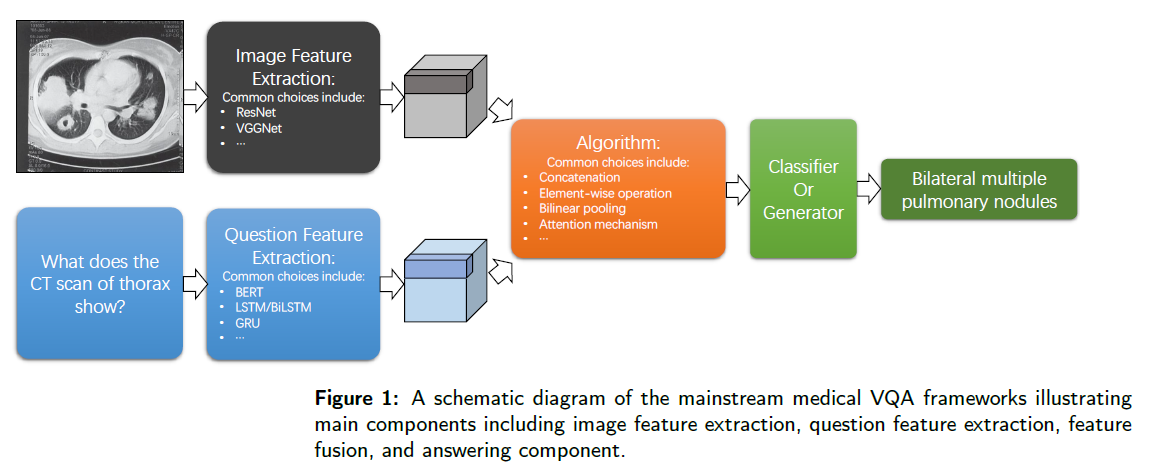
- Image Encoder
- CNN Backbones; e.g. VGG, Resnet
- Question Encoder
- Language encoding models; e.g. LSTM, BERT
- Feature Fusing Algorithm
- Answering Component
- Close-ended Question : Neural net classificer
- Open-ended Question : Recurrent neural net language generator
완전 Original LSTM Q+I에서는 Question, Image를 각각 인코딩해서 얻은 question features와 Image features를 단순히 element-wise multiplication을 통해 융합(fuse)했습니다.
다만, 그 후에 연구자들은 혁신적인 fusing algorithm을 개발하고, 인기 있는 attention mechanism을 시스템에 도입해 성능을 상당히 진전시켰습니다.
저자들은 Medical VQA task에 쓰인 접근법들의 특징을 다루기 위해 VQA-Med challenge에 대한 25개의 연구와 투고된 conference/journal paper 5개를 리뷰합니다.
특히 위에서 소개한 4개의 Components를 중심으로 다룹니다.
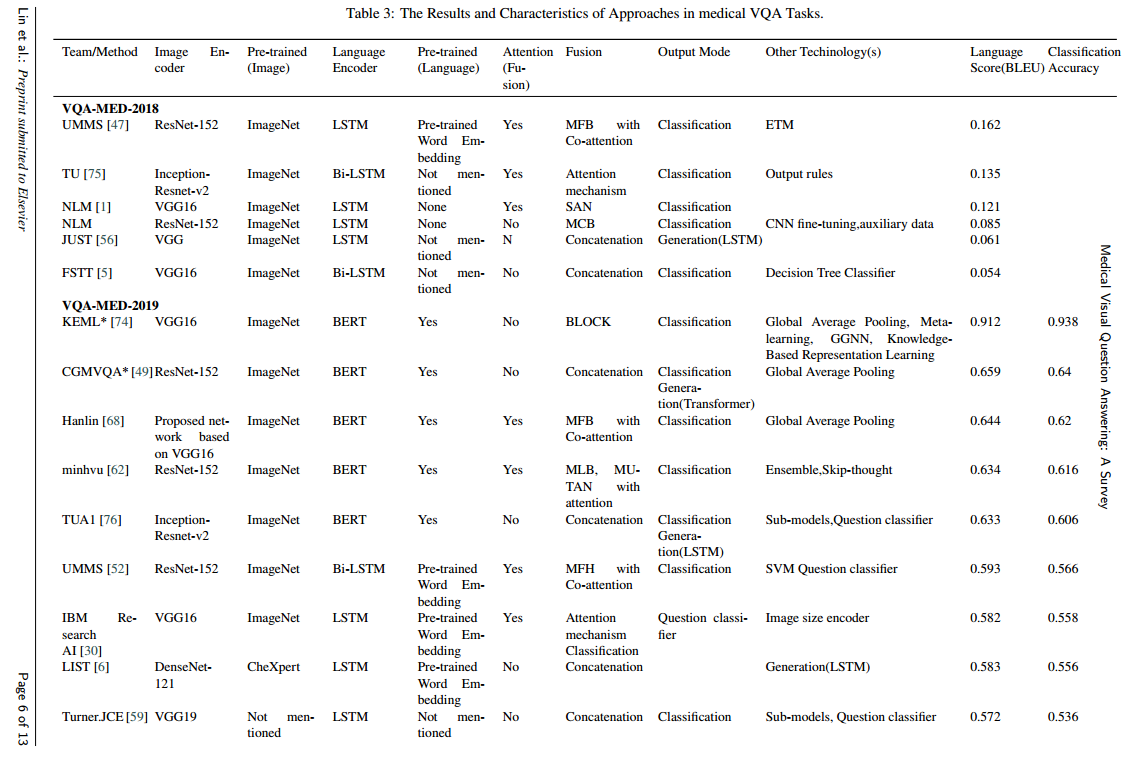
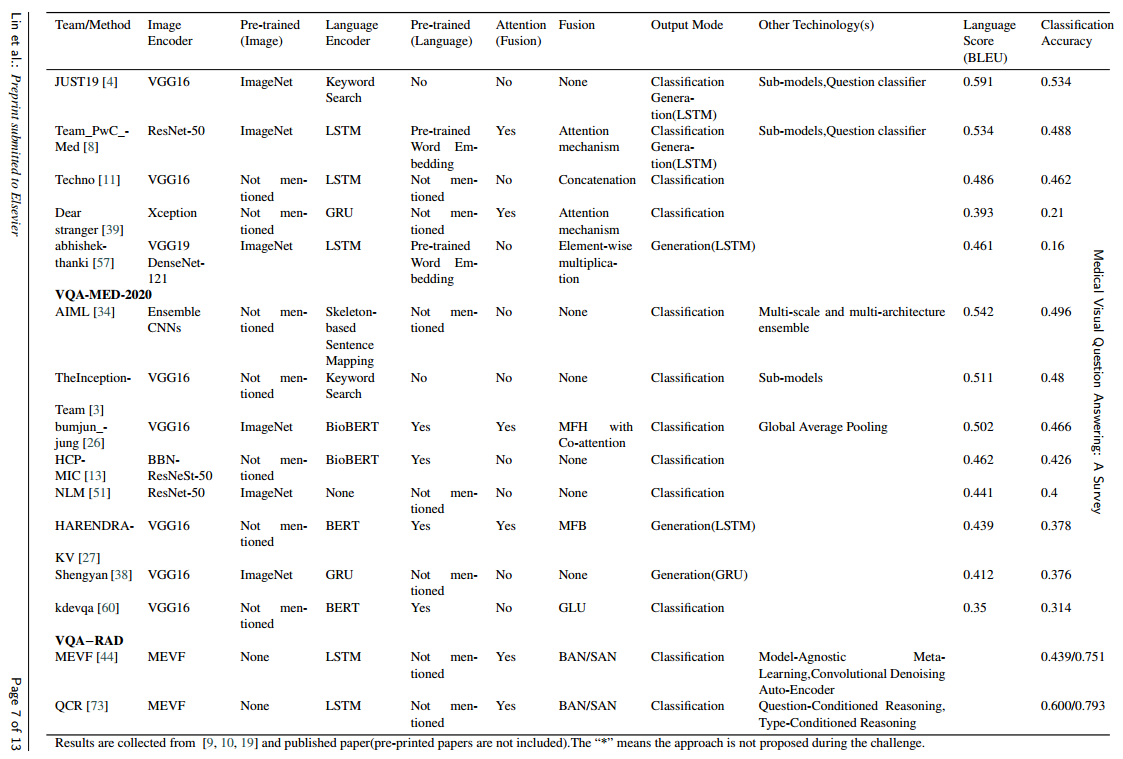
4.1. Image Encoder
Public Challenges에서는 VGG Net이 가장 인기 있는 이미지 인코더였습니다.
특히, 30개 중 19개의 팀이 ImageNet-Pretrained-Model을 사용했습니다만은, 알다시피 Medical VQA에서 쓰이는 이미지와 ImageNet의 이미지는 많이 다릅니다.
하지만, 데이터가 적고 라벨이 적어서 Medical Dataset에 사전학습시키기 어려울 때는, 합리적이지 못하지만 그래도 적당히 동작시키는 방법이긴 합니다.
다른 방법은 public pre-trained model을 사용하거나, meta-learning을 사용하는 것입니다.
LIST team은 CheXpert dataset에 사전학습시킨 이미지 인코더를 활용했습니다.
Nauyen et al은 메타러닝의 일종인 MAML(Model-Agnostic Meta-Learning)과 CDAE(Convolution Denoising Auto-Encoder)를 활용해 Image Encoder의 초기 가중치(initial Weight)를 부여함으로써 데이터 부족의 한계를 극복했습니다(전이 학습의 일종).
Nauyen et al이 제안한 방법을 Mixture of Enhanced Visual Features(MEVF)라고 합니다.
메타러닝에 대해서는 본 블로그 내에서도 간략하게 다루었었습니다.
Few-Shot Learning
사실 엄밀히 따지고 보면 VQA task에 대해서 Image (Classification)dataset만을 이용해 사전학습 시키는 것은 조금 맞지 않을 수도 있는데, Medical 분야에서는 answer types 자체가 적기 때문에 사실상 Image Classification Label을 다루는 것처럼 여길 수 있고, 그렇기에 Image Encoder를 사전학습 시키는 방법은 어느 정도 검증 가능하고, 장래의 과제라 할 수 있습니다.
일반적인 VQA는 가능한 answer의 개수, 즉 candidate answer의 개수가 수천개에 달하기 때문에 Image Classification과는 꽤나 동 떨어져 있을수도..?
이미지 인코더의 다른 특징은 (적어도 저자들이 리뷰한 연구들 중에는) 바로 CNN classification 모델이라는 것입니다.
때로 Image Encoder를 위한 Backbone으로 R-CNN, Faster R-CNN같은 Detection Model을 사용하기도 합니다.
Classification을 위한 CNN계열과 Detection을 위한 R-CNN계열은 애초에 Feature를 추출하는 방식이 완전히 다르기 때문에(Top-down <-> Bottom up) task에 맞게 적절히 사용될 필요가 있습니다.
Detection-based Image Encoder를 사용하지 못하는 이유는 알다시피 의학 분야는 애초에 robust pre-trained model과 large-scale detection dataset이 아예 없다고 봐도 되기 때문.
그렇기 때문에 Medical VQA task에서만큼은, General VQA에서 현재 꽤나 인기 있는 detection-based methods를 사용하기 힘든 단점이 존재합니다.
4.2. Language Encoder
본 논문에서 리뷰되는 language encoder는 LSTM, Bi-LSTM, BERT, BioBERT인데요, VQA-MED-2019 챌린지에서는 상위 5개의 팀이 모두 BERT를 사용했다고 합니다.
BERT와 BioBERT를 LSTM/Bi-LSTM보다 점차 많이 사용하는 것은 아래의 그림에서도 볼 수 있습니다.
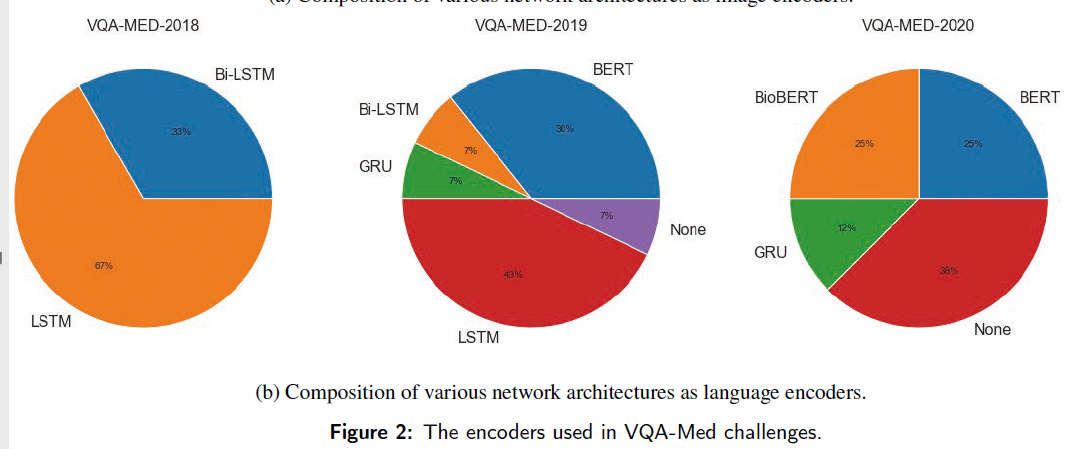
이는 medical domain과 general domain의 corpus 차이에도 불구하고 Transformer:pre-trained model이 성능 상 우수하다는 것을 보여줍니다.
더군다나 LSTM/Bi-LSTM을 사용한 팀들은 또한 pre-trained word embedding을 사용하는 팀이 많았습니다.
모두가 알다시피 데이터 양이 적은 downstream task에서는 pre-training이 중요하다는 것을 알 수 있습니다.
특히나 세 팀은 question을 딥러닝 모델로 처리하지 않고 keyword or template matching을 사용해 처리했습니다.
이는 keywords나 templates을 이용해도 question을 쉽게 불려할 수 있기 때문입니다.
그러니, medical VQA처럼 적은 양의 question category만을 가지고 있다면 light language encoder가 실용적인 선택일 수도 있습니다.
4.3. Fusion Algorithm
fusion stage에서는 추출된 visual feature와 language fecture를 통합해 둘 사이의 hidden relationship을 모델링합니다.
일반적으로는 attention 매커니즘과 pooling 모듈이 많이 쓰입니다.
Attention mechanism
Attention mechanism은 vision과 language tasks에서 널리 쓰이고 있습니다.
Medical VQA approaches에서는 30개의 팀 중 13개의 팀이 fusion stage에서 attention을 채택했습니다.
Stacked Attention Networks(SAN)이 전형적인 어텐션 알고리즘의 예시입니다.
SAN은 question feature를 Query로 사용해 이미지 영역과 관련된 answer의 순위를 결정합니다.
레이어가 많기 때문에 image를 여러 번 반복해 쿼리할 수 있으며, incursive attention mechanism은 많은 데이터 셋에서 종종 베이스라인으로 쓰입니다.
SAN외에도 Hierarchical Qusetion-Image Co-Attention(HieCoAtt), the Bilinear Attention Networks(BAN) 등과 같은 여러 어텐션 방법이 있습니다.
눈 여겨 볼 점은, 가장 인기있는 Multi-head Attention 방법인 Transformer와 Modular Co-Attention network(MCAN)등은 Medical VQA에 적용되지 않았다는 점입니다.
성능을 뽑기 힘든(보통 트랜스포머는 large-scale dataset에 적합하므로) 문제가 있다고 볼 수도, 혹은 성능을 더 개선할 여지가 있다고 볼 수도 있습니다.
Multi-modal pooling
Multi-modal pooling은 visual&language features를 혼합하는데 쓰이는 테크닉입니다.
가장 기본적인 방법으로는 concatenation, sum element-wise product가 있습니다.
저자들이 리뷰했던 페이퍼들도 direct concatenation이 가장 널리 쓰인 fusion method였습니다. 만은, 성능은 평균에 지나지 않았습니다.
input vector가 고차원이기 때문에 외적(outer product)는 연산량이 너무 많기 때문에, 저자들은 더 효율적인 pooling method를 도입했습니다.
Multi-modal Compact Bilinear (MCB) pooling 또한 pooling을 위해 사용하는 전형적인 방법입니다.
MCB pooling은 image&text features를 고차원 벡터로 임베딩 시키고, Fourier space에서 convolution 곱셈을 행합니다.
attention 또한 pooling module에 쓰일 수 있습니다.
Multi-modal Factorized High-Order(MFH) pooling, Multi-modal Factorized Bilinear(MFB) pooling과 같은 연구들도 일종의 multi-modal pooling familty입니다.
pooling with attention method를 사용한 팀은 두번째로 많았으며(5/30)
VQA-Med-2018과 2019에서 우승한 팀이 이런 어텐션 솔루션을 사용했씁니다.
4.4. Answering Component
저자들이 리뷰한 30개의 방법 중에, 21개의 방법이 classification을 통한 output mode, 5개의 방법이 generation을 통한 output mode를 채택했습니다.
몇 개의 방법은 classification과 generation을 둘다 채택하는 switching strategy 전략을 사용했습니다.
무엇을 선택할 지는 ground-truth answers의 길이 분포를 반영하는 경향이 있습니다.
대답이 짧다면 classification으로도 충분할 것이고, 대답이 길어야 한다면 아무래도 generation 기반 output을 사용해야겠죠.
Moreover, the classification mode will facilitate the learning difficulties under a restricted number of data.
4.5. Other Strategies
Sub-task strategy
Sub-task strategy는 전반적인 태스크를 여러 개의 sub-tasks로 나누고, 이를 branch model로 연결하는 것입니다.
이 경우 추가적인 taks classification module을 구축해 각 question cateogry나 image modality의 종류에 대응하는 잘 작동하는 모델을 선택하게 됩니다.
Question이 4개의 Category로 구성된 VQA-Med-2019에서도, 1개의 Category(2개의 종류)로 구성된 VQA-Med-2020에서도, 총 8개의 팀이 이 방법을 사용했습니다.
이런 방법을 사용하는 이유는 question의 카테고리가 매우 적고, 잘 나뉘어 있기 때문에(distinct) 쉽게 나눌 수 있기 때문입니다.
모델을 여러개 구축함으로써 single model보다는 효율성이 좋으나, 때로는 sub-task classification을 잘못해 각 태스크에 모델을 잘못 할당할 경우 문제가 생길 수 있습니다.
뿐만 아니라, question category가 꽤나 다르다면 다른 태스크에는 일반화될 수도 없을 것이구요.
Global Average Pooling
다른 테크닉 중에 많이 쓰이는 것은 GAP(Global Average Pooling)입니다.
GAP는 (일반적으로 마지막에 많이 쓰이는) Fully connected layer를 대체하기 위해 feature maps의 average를 사용하는 방법입니다(30팀중 4팀 사용).
연산량도 엄청나게 줄여주지만, 보다 나은 image representation을 뽑는다고 알려져있기도 합니다.
E.T.C
- Embedding-based Topic Model
- Question-Conditioned Reasoning
- Image Size encoder
5. Challenge and Future Works
5.1. Question Diversity
VQA-RAD Dataset에서의 questions은 아래와 같다.
- modality
- plane
- organ
- abnormality
- object/condition presence
- positional reasoning,
- color, size, attribute other, counting, other
하지만, VQA-Med-2019와 PathVQA에서는 VQA-RAD에 비해 다양성이 떨어지며, RadVisDial과 VQA-Med-2020에서는 카테고리가 anormality presence로만 제한된다.
종양의 위치나 종양의 사이즈같은 건 물어보지 않는다.
이를 개선하기 위해서는 아래와 같은 방향들을 취할 필요가 있다.
- 데이터 소스를 늘린다.
- QA pair를 합성(생성)할 때 거의 image caption과 medical report에서 발췌한다.
- 단, 이는 특정한 토픽에만 제한되기 때문에, text book같은 다양한 데이터 소스로부터 corpus를 다룰 필요가 있다.
- VQA-RAD와 같은 이미 구축된 데이터를 다시 활용할 필요가 있다.
- VQA는 일반적으로 question과 image content가 관련이 있어야만 한다.
- 가끔 임상 환경에서는 이미지와 대화가 약간 어긋날 경우가 있으므로.
- 결론적으로, 다양한 question category를 갖는 데이터셋으로 학습해야 더 나은 일반화 성능을 보여, 실제 임상 환경에서도 활용할 수 있을 것이다.
5.2. Integrating the Extra Medical Information
Medical VQA에서 또다른 문제점은 추가적인 정보를 인퍼런스 과정에 통합하는 것이다.
예를 들어, Kovaleva et al은 환자의 병력을 통합할 경우 anwering questions task에서도 더 나은 성능이 도출될 수 있음을 보여줬습니다.
5.2.1. EHR
EHR(Electronic Health Record)는 환자의 병력, 진단명, 복용약, 치료 계획 등을 포함합니다.
Medical AI 분야에서는 이러한 EHR가 더 나은 예측을 하는 데 도움이 되어 왔습니다.
VQA에서도 이러한 EHR를 활용할 필요가 있으며, 그 때가 된다면 이를 위해 Numerical Features들도 다룰 수 있게끔 VQA Model을 약간 수정해야 할 것입니다.
뭐 근데 아직 컴퓨터 비전과 EHR를 통합한 연구는 거의 없는 듯 합니다.
EHR이 numerical feature기 때문에 input으로 이를 사용하게 되는데, 기존에 visual features와 language features 외에도 numerical feature도 통합해야 합니다.
애초에 numerical feature를 encoding하는 component도 추가해야겠네요..
5.2.2. Multiple Images
의학 분야에서는, 특히 방사선학에서, 일반적으로 연구들은 single image가 아니라 multiple image를 기반으로 행해집니다.
이미지들은 각각 다른 plane을 지닐 수도 있고, 아니면 sequential한 이미지들일 수도 있습니다.
실제로 MIMIC-CXR 연구에서도 postero-anterior view와 lateral view 2장을 활용해 연구를 진행했었는데, RadVisDial dataset에서는 그냥 postero-anterior view만 탑재했으며, 이에 따라 VQA Model의 input 또한 단순히 single image만을 받았습니다.
5.3. Interpretability and Reliability
해석가능성(Interpretability)는 딥러닝의 고질적인 문제입니다.
애초에 VQA든 Medical-VQA든 99%는 딥러닝을 기반으로 하기 때문에 마찬가지로 해석가능성 문제(Blackbox)가 존재하겠죠.
다만, Medical 분야에서의 해석가능성은 다른 분야보다 수십배는 중요합니다.
건강이 걸려 있으니까요.
General domain의 VQA 연구자들은 이런 문제를 꽤나 다뤄왔으며, 모델의 추론 능력을 평가하기 위한 여러 방향을 제안했습니다.
5.3.1. Unimodal Bias of VQA Models
VQA Models에서 Unimodal Bias는 VQA 모델이 Multi-modal(이미지, 텍스트, ...) 임에도 불구하고 하나의 modality에서 나온 통계 규칙에만 의존해 답변을 내놓는 편향입니다.
- 특히, language input에 편향됐다면 이를 language prior라고 합니다.
이런 편향을 줄이기 위해 VQA-CP dataset, GVQA, RUBi, Adversarial game(VQA <-> only language model) 등 여러 방법들이 제안됐습니다.
주로 language prior에 집중하는 이유는 question도 language, 그리고 answer도 language이기 때문에 question<->answer 간 통계적 규칙이 더 두드러질 가능성이 높기 때문인듯합니다.
Medical 분야는 데이터가 일반적인 분야보다 더욱 적기 때문에 이런 unimodal bias를 피할 수 있는 방안들이 많이 연구되어야 합니다.
5.3.2. External Knowledge
일반적인 VQA 분야에서는 어른 수준의 기초 상식이 있어야 인지/추론을 뒷받침할 수 있습니다(사진과 question만 본다고 무조건 맞출 수 있는 것은 아님).
이런 부분을 다루기 위해 사용할 수 있는 접근법은 structured knowledge base를 VQA dataset에 추가하는 것입니다.
Wang et al은 외부 지식기반 추론을 제공하는 Ahab 방법론을 제안했고, 이를 평가하는 프로토콜도 제공했습니다.
뿐만 아니라 이게 왜 중요한지에 대해서 지지해주는 FVQA dataset도 제안했습니다.
외부기반 지식을 필요로하는 question으로만 구성된 OK-VQA dataset도 있습니다.
문제는, medical VQA에서는 어른 수준의 기초 상식보다 훨씬 더 높은 수준의 지식을 요구한다는 것입니다.
이후에는 Medical VQA에서 이런 전문가-기반-기초상식을 갖추기 위한 추가적인 approach를 취해야 할지에 대한 연구가 행해질 필요가 있습니다.
5.3.3. Evidence Verification
Attention mechanism에서 attention map을 이용해 answer와 연결된 image regions을 시각화할 수 있습니다.
이 attention map과 인간으 ㅣattention map을 비교하면 어느 정도 연구자들은 VQA method가 질문에 답을 하기 위해 올바른 방식으로 이미지를 추론하는지 알 수 있습니다.
의학 분야에서도 당연히 답에 대한 근거는 너무나도 필요하지만, 전문적인 사람들만 이에 대한 평가와 검증이 가능한 단점이 있습니다.
일반적인 도메인에서는 이런 human visual attention을 포함한 VQA-HAT Dataset이 있으며, 이런 판단 검증을 Image evidence 외에도 textual evidence까지 확장하기 위한 데이터셋인 VQA-X도 있습니다.
text-based question-answer pairs를 다루기 위해서 Wang et al은 올바른 text 단서에 bounding box를 부여하는 dataset인 EST-VQA를 제안하기도 했습니다.
eye-tracking data를 제공하는 IQVA dataset도 있습니다.
아무튼, inference ability를 평가하기 위해 다양한 모델, 데이터셋, 방법론들이 연구될 필요가 있습니다 !
왜 판단을 내렸는 지는 알아야 하니까요!
