[논문리뷰+아이디어] A mathematical model of the COVID-19 pandemic dynamics with dependent variable infection rate Application to South Korea
본 글은 아이디어를 얻기 위한 메모 글로, 참고하기엔 좋지 않습니다.
원 글 작성일: 2020-10-10
A mathematical model of the COVID-19 pandemic dynamics with dependent variable infection rate Application to South Korea
특징 : 38장의 꽤나 많은 분량
한국의 데이터,매개변수에 대한 연구라는 점.
나름 최신(7월 달)의 연구라는 것.
Abstract
- new SEIR-type model에 관한 연구(코로나의 동역학과 잠정적인 통제를 위해).
- It has a compartmental structure and a differential inclusion for a variable infection rate (감염률 변수를 위해 구획구조와, 미분포함?)
- 이 연구의 novelty(진기함)은 크게 3가지이다(three-fold)
-
polulations is separated into those who fully follow the directives and those who only partially comply with the directives or are necessarily mobile (disease control directives-질병 관리 지침(거리두기, 마스크, 집에 머무르기) 등 에 규합하게.
- 이는, 어쩔 수 없이 움직여야 하는(부분적으로 지침을 따르는) 집단과, 완전히 지침을 따르는 집단 2개로 나누었다(현실 세계에서도, 고통받는 사람(자영업자) 제대로 이행을 안하는 사람(교회 등)으로 나뉘기 때문에 –> 모델에 고려하면 재미있긴할 듯.
- 의의: 감염병 통제와 완화에 따른 전반적인 효과를 평가할 수 있게 해줌.
-
Model은 infenction rate(감염률)이 안 알려져 있으며, 계속해서 어떻게 변하는지 추적하는 모델이다(virus mutations, saturations effect등 때문에 변하므로)
- differential inclusion을 통해서
-
to some of the system coefficients, ran-domness를 부여함으로써 이러한 parameters들에 대한 model의 민감도를 조사하고, 이러한 model simulations에 대해 신뢰의 한계구간을 제공한다.
여기서는 두 접촉군이 전염성이 있다고 가정하는데, latent-infectious인데 왜 전염성을 ?? 또한 , H는 단지 증상이 심하여 입원 된 부분만 체크.
즉, 한국에서는 맞지 않음, 어차피 I는 무조건 잘 격리 된다고 보면 됨.
잠복기의 의미가 두개가 있음. 여기선 아마 exposed -> latent로 봄.
변수 추정
The model parameters were found by minimizing the deviation(편차) of the model prediction from the reported data세타
결론
현 남한의 동역학 상황을 정확히 포착하며, 이는 미래 예측에 대한 신뢰를 줄 것.
Introduciton
여러 정책의 결정 판단 근거를 위해서 연구들을 많이 했다.
다만, 이 연구에서는
-
새로운 θ : ∈ [0,1] 매개변수를(이는, R0값으로 하는 연구와 동시에 수행될 수 없을 듯) 도입했는데, 시간에 따라 변하며 이는 보건당국의 코로나 완화,억제 정책을 준수하는 정도를 측정한다.
또한, 출처 [5] : The asymptomatic spread of covid-19에 나와있는 모델의 parameter를 사용했다.
[5] : 무증상 감염 (확산에 큰 영 향을 끼치는) 집단에 대한 고찰. -
infectiveness or the contact parameter인 β를(역시, R0와 다르게) 고정된 상수가 아닌, 종속변수(규정된 함수)중 하나로 간주하며
contact probability와 관련되어 있기에 이는 제한된 범위를 가지고, 그 때문에 differential inclusion을 통해서 기술된다. 이렇게 한 이유는, 바이러스의 전염,감염성 등은 pandemic이 지남에 따라 다르기 때문(변이,시민의식 변화 등)
-복잡하지만, 정확하게 만들 것.
※ Differential inclusion : 상 미분방정식 개념의 일반화
https://en.wikipedia.org/wiki/Differential_inclusion -
일부 모델 parameter에 대해 randomness를 도입했다.
이는 특정 변수에 대한 모델의 민감성을 이해하게끔 할 것이다(simulations의 신뢰구간 등을 제공하면서). 만약 모델이 특정 parameter가 조금만 변해도, 결과(solution)에 큰 변화를 가져올 정도로 민감하다면 정확한 parameter값을 얻는 것은 더 중요하다. 그렇게까지 민감하지 않다면, approximate value로도 충분하다.
아무튼 , 기존 연구는 MERS로 연구를 했으나, 굉장히 좋지 않은 결과를 산출했는데 이는 보건당국이 한 조치를 주민들이 얼마나 준수를 하는가에 따라서 달라졌기 때문이라고 생각한다.
그런 연유로 지침을 잘 따르는 사람들(거리두기, 마스크착용, 잦은 손 세정 등)과 그 외의 사람을 구별하기로 하였다(이는, 기존 모델에 P집단만 도입한 후, 정부의 특정 효과를 데이터로부터 추산하면 되지 않나?, 역시 P집단을 추가하든가 이 방법을 하든가 둘 중 하나만 하면 충분할 듯)
어찌 되었건 지침을 잘 준수하는 사람들 / 준수하지 않거나, 일부만 준수하거나, 부득이하게 아픈 사람들과 접촉을 해야하는(Health care, 택배업 종사자 등)
이런 것들을 하기 위해서 위에 서술된 변수 θ를 도입한 것이고, Exposed 집단과 Infected집단을 아래 2개의 Sub집단으로 나뉘게 한 것이다.
결론 : 한국에 모델을 적용시켰을 때, 한국이 성공적으로 전염병을 통제하는데에는 73일간 theta 변수가 0.995로 유지되었기 때문이다.
두번째 새로운 아이디어는, contagion or contact parameter인 β의 변화이다.
현재 parameter β는 보통 다른 연구에서는 time-dependent 하지만 given and in this way, 계절의 변동성 뿐만 아니라 지침 및 정책의 변화 또한 연관을 주었다.
바이러스 변이가 있는게 관찰되었으며, simple SEIR 모델에서는, saturation phenomenon이 있음(감염성 감소) 관찰되었다(군집 면역과 무관하게) – 레퍼런스 참고.
그렇기에 β를 간단한 시간 의존적인 함수 대신에 잘 안알려진 system으로 여기면서 contacts parameter(beta)의 본질적인 변화를 신경썼다(정책에 의한 변화와 독립적이게)
이는 pandemic의 진화를 더 자연스럽게 포착할 수 있을 것이다.
따라서, 우리는 감염자 수가 늘면 parameter β가 증가하게끔, 또는 회복자 수가 늘어감에 따라 β가 (선형적으로) 감소하게끔 하는 differential inclousion-여기서는, 그저 main model에 추가로 베타에 관한 미분방정식을 추가한 것 뿐인듯-을 추가하였다.
이 선형성은 ad-hoc assumptions(반박을 위한 반박? 오직 문제 해결을 위한 가설)
이며 어떤 미래에 그러한 선형성의 포함으로 이어지는, 조금 더 적절한 underlying assumptions을 탐구하는데 상당한 관심일 수도 있다그냥 어려워서 대충 가정 했다는 뜻.
방향 : corona가 종식이 되지 않는 방향이 되게끔 매개변수를 설정하되, 그래도 최대한 간단하게(데이터 추출이 편하게끔) 설정하자.
이를 위해서 어떠한 randomness를 도입을 한다던가 하는건 분명히 좋은 선택(신천지 등의 trigger반영을 위해서?) – 과거 데이터와 연동되게끔. 이게 올바르게 작동하려면 역시 networked 이론과 같이해야하는데…
또한 이 randomness는 정부의 정책과도 연관이 있긴 해야한다.
모델 변수에 randomness를 부여하는건, 확률 변수에 관해 solutions을 measuarability하는 문제를 더 발생시킨다. section 3에서 다루며, 참고하도록 하자.
we used some of the published data to ‘train’ the model by using an optimization routine in MATLAB which finds the model parameters that provides the best L1 fit.
We present our simulated model predictions together with the data one part of which was used in optimization and the remaining part was gathered after the optimized parameters were determined
또한, 데이터의 어느 부분은 optimization을 위해 사용했고, 그 data와 함께 시뮬 결과를 제시했다. 데이터의 나머지 부분은 optimization을 통해 결정된 parameter가 확정 된 이후의 모아진 데이터이다.
결론은 잘 나왔다.
추신 : 이전 데이터에서는 R의 Opti함수를 이용하여, 여기서는 matlab으로 하였다, python에서도 없을 리가 없으므로 참고—
아무튼, 이러한 도입 이후 모델은 7개의 비선형 ode의 결합시스템과, virus infectivity에 대한 differential inclusion으로 구성된다.
모델에 대한 고유한 solution은 section 3에서 결정되며 (이게 필요한가?)
section 4에서는 randomness의 도입과, 확률변수의 measureablity에 관한 고찰이 있다.
5장에서는 2가지 평형 상태의 stability 인 Disease-free equalibrium과 endemic equllibrium이 나와있으며, 6장에서느 모델의 수치 시뮬레이션에 사용한 방법을 설명한다.
- matlab의 여러 함수들,(최소제곱법 등을 나타내는 l1 norm을 나타내는 선형 회귀법 등을 이용해서 제약이 있는 다변수 함수의 최소를 구하는 최적화..)
섹션 7에서는, 한국의 covid-19 역학 시뮬레이션 결과를 보고한다
섹션 7.2에는 한국의 정책의 효과와, 그 정책을 어떻게 parameter theta에 연결 짓는지가 나와있다
섹션 8은, 민감도 분석을 하는 일반적인 방법.
섹션 9에서는 풀어야 할 과제와 미래 연구에 대한 제시.
Model
- Compartment를 Subpopulation으로 나눔.
- rate of infections에서 감염률도 고려함(사회 행동, 기후, 돌변연이 등)
- 각 인구들은 continuous dependent variables를 정당화, 즉, ODE의 사용을 할 수 있을정도로 크다고 가정함. ( 무슨 상관인지 이러한 Collective model을 쓰려면 어느정도 각 구획별로 인구가 커야한다.)
※ Continuous dependent variable model - 여러가지 지정학적 분포(GEOGRAPHICAL distribution과, 인구밀도는 기간과 문화 등에 따라 다름 등)들을 고려하려면 편미분방정식으로 기술해야 하고, 이는 복잡하기 때문에 간단히 ODE로 나타내겠다.
따져야할 변수, 사회적 거리두기 단계, 이동 통제, 자발/강제적 격리,
또한, Exposed 집단을 2개의 subpopulation으로 나누되, Infected 모델은 나눌 필요가 없다고 생각한다.
Efc : 노출됐고, 무증상이지만 타인에게 감염시킬 수 있으며 지침 등을 잘 따르는
또한, 5~14일 이내 증상을 수반할 것이지만 검사받지 않고, 서류화 되지 않은. (실질적인 집단
이 연구에서는 추가로 H(t) : 증상이 심한, 입원 한 환자들까지 추가함.(버리자, 사망률은 크게 고려 할 부분이 아닐 뿐더러 한국은 격리가 잘 되어있다.
Randomness in system parameters
model의 parameter에 대한 dependence에 관한 이해는 중요하다 .그를 위해 얼마나 parameter가 변하는지, 또 그에 따라서 model 예측에 얼만큼 영향을 주는지를 이해하는 것은 중요하다.
즉, 만약 parameter의 작은 변화가 model에도 큰 영향을 끼친다면 이는 더 정확한 parameter를 구하기 위해서 노력을 해야한다. 이는 model이 unstable하거나 process그 자체가 unstable할 수도 있으며, 그 상황에서 예측에 대한 시도는 분명히 쓸모가 없을 수도 있다. RANDOMness를 부여하려면, 애초에 모델 자체가 안정적으로 수렴해야 한다.
다만, 이 연구에서 randomness 부여는 굉장히 어렵기 때문에, 이는 나만의 방법을 찾아보도록 하자.
COVID-19 IN South Korea
여러 parameter들은 MATLAB의 l1 optimization routine을 사용했다. worldmeter의 7일 평균 확진, 사망의 이동추세선들 뿐만 아니라 총 확진자, 총 사망자 에 관한 데이터와 예측 모델과의 비교를 하였음.
이는 단지 model이 과거의 data를 사용하였기 때문에, virus behavior, population behavir, policy, or the environment의 변화에 따른 결과는 예측하지 못한다, 다만 미래에 대한 예측은 합당해보이며, 현재 data로는 해낼 수 없는 몇몇 details을 제공한다.
7.1 Baseline simulations
정부의 정책에 대한 변화를 나타낼 parameter θ를 다음과 같이 도입하였다.

(8일 째 정책 시행)
또한, 이러한 value는 optimization subroutine (in MATLAb?)
을 이용하여 추산되었다.
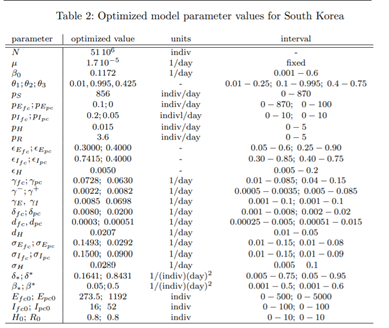
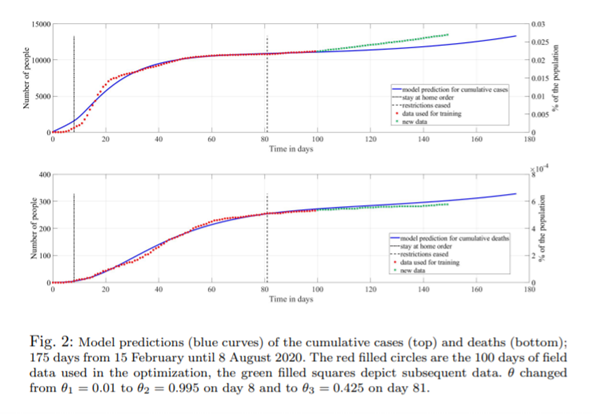
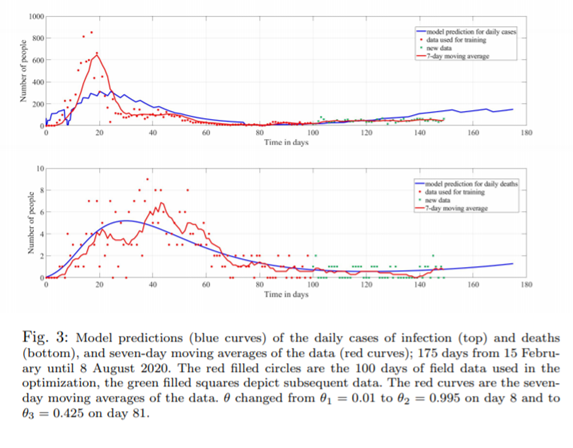
Conclusion
To gain further insight into the model predictions, we studied the equilibrium points of the system. Instead of finding a basic reproduction number RC , we used the system Jacobian due to the complexity of the model. Using this Jacobian, we found that the disease-free equilibrium (DFE) is asymptotically stable when θ = 0.995 and becomes unstable about θ ∗ = 0.58747; and since we used θ = 0.425 from day 81 onward, it was found that an endemic equilibrium (EE) appeared and was stable and attracting. Therefore, as long as θ < θ∗ the model predicts that the disease will linger for a very long time, but, we note that the disease-related EE numbers are very small
- R0값을 찾는 것 대신 여기서는 평형상태 이론을 이용했다.
데이터는, 월드미터에서 웹 크롤링을 이용하던가, 아니면 kaggle의 잘 정리된 데이터를 이용하자.
Novel coronavirus 2019-nCoV: early estimation of epidemiological parameters and epidemic predictions Version 2. Updated 27 Jan 2020
푸아송 분포
최적화 함수
신용도 95%의 검정
MLE, 몬테 카를로 시뮬레이션.
Assumptions of model
-daily time increments(매 날짜의 증분)을 Poisson-Distribution이라고 가정.
- 인간-인간 간의 감염만 고려했으며 (동물성 감염 원인이 된 중국의 시장)의 폐쇄 이후만(following the closure of the market) 고려
- 시장 폐쇄 이후는 동물성 감염이 존재하지 않았다고 가정함.
- 잠복기는 4일이라고 고려했으며(SARS와 동일), 일련의 연구에 따르면 4.4days라고 추정됨) – 최신 연구 찾아보면 됨. or article.
aggregate Model(집합모델) fitting
-Fitting은 ODE system을 1일 평균 신규 확진자를 나타내는 걸로 여김으로써,
또한 관측된 신규확진자는 이 평균 신규확진자 근처에서 Poisson-distribute를 가정함으로써 실행되었다.
- 또한, Model과 data가 주어진 상황에서, parameter inferene는 maximum likelihood estiomation using Nelder_mead optimization(최대 우도 추정법 --- 4주차 공부필요+
- R statistical language에서 optim() function을 이용하였다.
code : https://github.com/chrism0dwk/wuhan/tree/v0.2
- parameter의 불 확실성은 parametric bootstrap을 이용해 탐구되었다.
ex) 10000개의 Monte Carlo simulations from the model(ODE and Poisson nosie)이
MLE estimates of the parameters를 사용해 생성되었다.
각 시뮬레이션 된 dateset들은 그 다음 re-fitted 되었다(joint sampling distribution of the parameters – 공동 표본 분포를 만들게끔)
또한 95%의 신용도 검정을 수행하게끔.
ODE system은 이 표본분포를 통해 실행되며, 예측된 평균 전염병 궤도 주변, 95%의 신뢰 구간을 만들며 실행된다.
Epidemiological parameter estimates
