[논문정리+아이디어] The Asymptomatic spread of COVID-19
본 글은 아이디어 메모 용으로 사용한 글이기 때문에 참고하기엔 적절하지 않을 수 있습니다 (__)
원 글 작성일 : 2020-9-15
Abstract
Asymptomatic cases(무증상, 확진자)의 경우 보통 발견도 되지 않고, 격리도 당하지 않기 때문에 실질적으로 전염병 확산에 큰 영향을 끼치나, 보고서에는 반영되지 않는 경우가 많다. 반면에, herd immunity(집단 면역)에는 기여하기 때문에 corona의 멸종에는 도움이 될 것이다.
기존 연구에서 사용하는 data
- 확진자, 심각성, 회복,사망자, (병원, clinic에 보고된, 다만 이는 passively collected된 data기 때문에 현실과는 동 떨어져있을 수도 있다.)
물론 이러한 data들은 여러 공식적인, 사적인 플랫폼에 분배되면서 어느정도 covid-19의 심각성 등에 대한 정보를 얻을 수는 있으나, 분명히 앞에 놓인 믿을만한 예측모델은 막을 것이다.
Introduction
현재, hospitalization(입원?)을 필요로 하는 심각한 증상을 보이는 연령대는 0.1%(5살이하)부터 27.3%(80살 이상)까지 다양하다.
즉, 이러한 hospitalization parameter는 그 나라의 인구 구조에 의존(dependent)한다.
다만, Hospitalization variable을 추가해야 할까? 어차피 한국은 Infected = Hospitality일 정도로 격리가 잘 되어있다. 어떤 숨은 A집단을 고려할 때 이와 같은 HOSPITALITY에 대한 정보를 활용만 하고, COMPARTMENT는 빼도록 하자.
그저, Total death를 고려하는 데 쓰이는 parameter에만 인구의 구조를 추가하면 되지 않을까 싶다.
예를 들면, 아프리카의 경우 연령대가 낮기 때문에 실질적으로 입원할 정도의 심각한 증상을 보이는 인원은 4%뿐인데, 이 경우 약한 증상이나 무증상으로 covid-19가 지나갈 수 있기 때문에, 실질적으로 병원 등에 보고가 안 되었을 수도 있다.
물론 선별진료실과 외래진료실에도 많은 인원이 관측 되겠지만, 분명히 많은 부분은 detected된 상태로 존재할 것이다. 어떤 의료에 대한 접근도 없고.
그렇기에, 어느 정도 hospitalization parameter를 model에 도입을 했다고 볼 수 있다.
어찌 되었든, 보고서는 조금 왜곡 된 부분이 있을 수도 있다는 것.
random samples of the Populations을 테스트 함에 따라, 어느 하나는 infection과 아마도 immunity의 널리 퍼지는 정도를 결정할 수 있을 것이다. (Germany의 Gangelt의 지방자치제에서 실현됨 – 논문 존재 , 해당 논문의 refenrence(9)참고)
아무튼, in[11], 어느정도 중간 결과가 주어졌는데, 이는 TOTAL SAMPLE인 1000명중 약 500명이 테스트되었으며, 거의 14%의 면역자가 기록되었고 2명이 그 기간동안 사망됐다고 보고되었다. 사망률은 0.37%이고, 이는 존홉대에서 나온 1.98의 MORTALITY RATE와 꽤 차이가 난다. 현재 Gangelt의 사망률은 0.06%이다. 이 Gangelt의 낮은 사망률은 Gangelt내의 연구가 모든 감염된 사람(심지어, 무증상과 약한 증상의 사람들을 포함한) 경우를 고려했다고 보여진다.
그러므로, 연구는 이전의 생각보다 치사율이 낮다는 것을 제안한다.
다시 말하면, severe symptoms에 있는 사람들만 test하는 것은, 전염병에 확산에 왜곡된 영향을 끼칠 것이고, 특히 사망률에는 더욱 그렇다.
[11]의 저자들은 회복 후엔 체내 감염이 없기 때문에 집단 면역이 가능하며, 대충 6~18개월 간은 면역이 있따라고 추정이 되어있다. (60~70퍼센트가 면역이라면 전염병은 끝난다)
[4],[6]의 연구에 따르면, 대부분의 감염은 무증상이거나, 약간의 증상만을 보이며 (양성확진자의)50%가 무증상이다. (아이슬란드의 무려 10%가 검사를 받은 결과이다)
아이슬란드의 치사율은 0.41%이고 증상이나 합병증이 없는 사람들 사이에서 바이러스의 빈도가 감소하거나, 안정적인데 이는 면역의 만연함(집단면역)이 증가된 경우라고 볼 수 있다.
[2]에서는 영국 저널에서 무증상 감염의 중요성을 나타냈으며, 중국내 신규 확진자 166명 중 130명이나 뭊으상 감염이라고 밝혀져 있다. 또한 [1]에서도 담요테스팅(전면테스트인듯)Italy의 고립된 마을에 테스트를 했는데,(약 3천명의 인구) 이 때 10일 안에 90%의 유증상자가 감소했고, 이는 분명히 증상이든 무증상이든 고립시킨 것 때문이라고 볼 수 있다.
Model
아프리카의 경우 젊은 층이 많기 때문에, 유럽이나 미국 등에 비해 분명 무증상(or 약한 증상)을 보이는 인원의 비중이 더 많을 것이다. 이는 장기적인 COVID-19의 동역학과 그 결과 사망자 규모, 경제적인 부담 등에 핵심적인 영향을 끼칠 것이다.
고려해야 할 부분 : 유증상자의 격리정책은 정확히 기대하는 결과를 보이지 않을 것이며, 무증상자의 감염 확산은 집단 면역에 따른 기대하지 않은 확진자 수의 감소에 영향을 끼칠 것이다. 또한 여러 연구를 찾아서 대한민국의 인구구조와, 무증상감염 정도 등을 찾아야 한다.
[10]과도 같은 모델이지만, 이에 개입정책에 따른 compartments도 도입하였다.
여기서, SEIR+A+H 모델인데, 역시 E->I는 잠복기간의 역수이고,
'A-무증상, 약한 증상의 감염자'로 넘어간다(I는, medical attention이 필요).
이 심각한 증상을 보이는 I집단에서, 추가적으로 입원이 필요한 집단은 H로 이동한다(아마, 고령화 된 나라에서 더 가중치를 줘야 할 것)
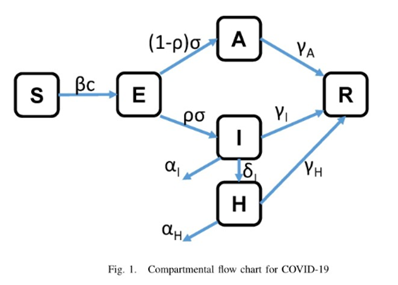
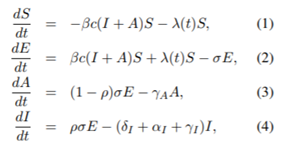
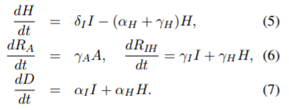
- point : E->A와 E->I의 매개변수 관계.
각각의 compartment는 각 인구의 percentage를 나타냄
β : 접촉 시 감염 확률
c : 한 사람당 접촉하는 사람 수
- 즉, 둘의 곱(βc) 은 한 사람이, 하루에 감염 시키는 사람의 수이다.
λ ∶ 시간에 따른 함수, 또한 (해외 유입에 따른 확진자로써, 초반에만 역할을 한다.
복잡하긴한데, 어느정도 고려를 해줘야 할 듯 하다.
여기선, parameter ρ가 주 된 관심거리이며, 무증상 확진자와 유증상 확진자를 가르는 parameter라고 볼 수 있다.
(6),(7)는 시스템에서 분리될 수 있으며, 그렇게 하는게 이론적 분석이나 컴퓨터 시뮬레이션을 하는게 용이하다. total number of case를 나타내기 편하기 때문에 저러한 Ra, Rih, D 변수를 사용하는게 편리하긴 하다.
즉, 총 누적 유증상 확진자는 I+H+RIH+D이고, 모든 확진자는
A+I+H+R+D이다(RA+RIH)
여기서 제일 중요한 변수는 단연 βc 이며(저자들 마음대로 찾아서 결정한듯 + R0값에 대한 연구는 많긴 함), 여러가지 정부의 개입조치에 관한 부분은 값 βc에 끼치는 영향을 통해 모델화(마찬가지로, 정부의 개입조치를 R0값으로 환산했다고 볼 수 있다. 이는 differential inclusion을 통해 더 정확하게 나타낼 수 있다.
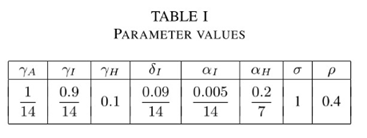
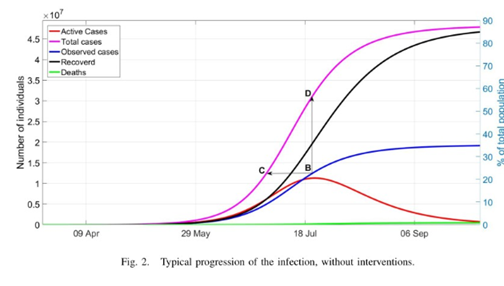
이 그래프는 βc = 0.17로 가정했으며, 이 때
기초 재생산지수(ℛ0)값은 다음과 같이 표현된다.
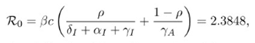
한 사람이 보통 평균 14일동안 전염을 시킨다라는 의미.
이는 단지 그냥 I이동매개변수의의 역수와 A이동량의 역수를 시킨 것 뿐.
또한, [7]과[12]와 같은,연구에서 역시 이 R0값은 2와 3 사이라고 추정되어 있다.
많은 모델 연구들에서와 같이 이러한 Variable들은 역시 관측할 수 없고 그저 observation operator와 같은 함수만 관측 가능하다.
이 연구에서는 , observable variables은 그저 daily recruitment(신규 확진자, 특히 A,I중 I로만 가는)이며 I,H,RIH,D 에 관한 부분만 관측 가능하다.
또한 , 신규 확진율에 관한 데이터는 Oscillate한 경우가 많다( many random factors, 예를 들어 보고가 하루 늦게, 또는 하루 일 찍 된다던가)
그렇기 때문에 누적 신규 확진자 비율(ρσE, into I compartment)의 분포를 고려하는 게 더 적절하다. 또는 7일 평균 추세선을 고려하거나.
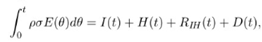
관측 가능 variable을 이용해서, 매개변수 중 하나를 결정할 수도 있을 것 같다.
- 그냥 적분이 CUMULATIVE를 계산하는데 쓰인다정도
다시 말하면, 누적 분포는 정확히 symptomatic cases의 총 수와 같다.
매일 보고되는 confirmed cases와 거의 유사하다(동일하게 취급, 실제로 같진 않겠지만).
이러한 관측할 수 있는 부분은, 여러 경로로 수집한 data를 이용해 거기에 맞게 끔 모델을 적절히 조절할 수 있다.
이런, 관측 가능한 variable말고 진정한 총 누적 분포는 A+I+H+R+T이며 총 신규 확진은 σE의 적분에 해당.
또한, 진정한 총 확진자와, 관찰된 총 확진자의 차이는 역시 parameter ρ에 의해 결정됨.
또한, 표시할 때 y축의 눈금이 왼쪽,오른쪽 쌍으로 표현 됨을 확인하자.(visualization)
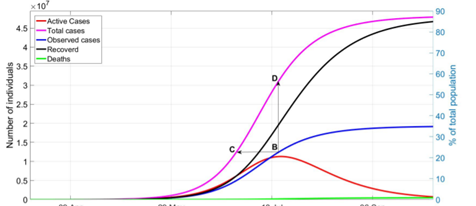
그래프에서, 총 신규 확진자(Active Cases : red lines)-A+I+H가 peak를 찍었을 때, 실질적으로 관측된 confirmed cases가 겨우 인구의 22%지만, 총 확진자(예측)은 55%에 해당한다. 그 순간 Recovered(전염병에 면역인) 부분은 36%에 해당하며 이는 신규 확진을 막는 역할을 한다. 이때 S집단은 약 42%로 계산하기 쉬우나(회복이 36%, 관측된 확진자가 22%이므로), 이 때 기초 재생산비율값은 2.3848(R0)과 X 0.42를하면 약 1이기 때문이다.
이 부근은, 앞에 정의된 R0값의 이해와 함께 이해해야 할 부분이다.
물론, 위의 그래프는 당연히 정확한 예측값이 아니며(parameter가 안 알려져 있기 때문), 무증상 compartment의 역할 정도만 확인 할 뿐이고(어느 예측이든), 어떤 연구는 이 size를 추산하는데 노력을 기울여야한다.
한 가지 방법은, 항체에 관해 실험함으로써 already existing immunity에 대해 실험하는 것이다. [11] 참고(단 이는 나라마다 분명히 다른 결과를 가질 것이기에)
Modeling in South Africa
deterministic differential equations이기 때문이 numbers가 클 때만 실질적으로 정확한 전염병 확산을 반영할 수 있다. 그렇기에 중간부터 예측 진행(150의 confirmed, 300의 무증상확진자(예측,가정)).
또한, 해외 유입자에 관한 정보는 분명히 강력한 lockdown 정책 이전의 폭발전인 증가를 설명할 수 있을 것이다(이게 아니라면 기초 재생산지수는 예측치를 훨씬 넘는다).
lockdown 이전에는, 변수()를 0.2, 즉 기초재생산지수(R0)=2.8로 가정하니까 데이터와 잘 맞았다.
역시, 이 예측 SECTION을 보면 확실히 기본모델과는 다르다(퍼센테이지 자체에서)
이는 실제 데이터와 비교하면서, 어느정도 맞춰줘야 한다고 본다.
어떤 개입 정책이 실행되고 난 후의 변수(𝛃c) 값을 0.07로 나타내면, 차례로 R0값은 1이 되며(신규 확진자가 상수로 나올 것) 이는 실제 데이터와도 비슷하다.
그 이후는 지수적 증가가 확연히 보인다.
이는 아무리 거리두기 정책이 진행돼도, 날이 갈수록 사람과 오토바이의 교통이 증가한다(지치니까-lockdown patigue). 이 점도 변수에 진행해야 한다, 다만 data를 사용할 수 있을까?
또한, 어떤 모델링에 있어서 설명가능하지 않은 인공지능은 그렇게 사용하고 싶지 않기 때문에, 수학적 모델을 정교하게, 납득 가능하게 만들든지 아니면 머신러닝에 결과에 대한 판단 근거를 설명할 수 있는 장치를 부여하고 싶다.
또한 규제 정책의 변화가 분명히 parameter에 영향을 끼쳤을 것이고, 뭐 이런 저런 변화가 있지만 이러한 부분들을 세세하게 원일 규명하기는 힘들고, 그저 lockdown efficiency가 변하는 그 부분을 morum mutation(behavior change)로 그냥 명명하도록 하자.
아무튼 이 linear한 부분에서 증가율이 exponent하게 급격하게 늘어난 이 시점에는, 분명히 무증상 확진자가 어느정도 큰 역할을 했다라고 생각한다.
한국에서, 감염자와 접촉한 E는 어느정도 역학 조사를 통해서 자가격리를 권하지만, 이 역시 모두 통제를 할 수는 없다.
아무튼 이 이후는 여러가지 문제로 인해 예측하기 힘들지만, P값을 0.2와 0.4로 비교해보면 신규 확진(유증상) 자와 확인 된 총 신규 확진자(유증상)은 꽤나 달라진다.
p값이 낮아지면, 당연히 유증상(관측되는)인구가 적을 것이다,반면에 총 확진자수와 사망자, 면역(회복)자는 당연하게도 안 달라진다.
이러한 무증상 관측자들은 어느정도 수준으로 억제가 되어야, 보건 당국이 잘 대처를 할 수 있을 것이다. 연구의 말미에는 어떤 정책이나, 여러가지 보완점이나 방향을 제시해주면 좋을 듯 하다.
여기선, 정책의 영향을 R0값의 설정정도로 표현하였는데, 나는 조금 더 구체화 해보도록(By differential inclusion (왜냐면, R0값의 경우는 무언가 직관성이 떨어지니까, 다만 R0에 대한 연구가 흔하기 때문에 이를 이용해서 P로가는 parameter를 결정하도록)
(또한, 장기적인 예측은 분명히 집단면역(Herd immunity)도 중요하니 판단을 하도록 하자.)
알려진 방법은 거의 유일하게 항체에 대한 실험밖에 없다(무증상 감염자 비율을 알아내는 방법).
이 연구도 수준 높은 연구는 아닌 이유가, 어떤 p parameter의 정확한 추정을 실행하지 않았다(어렵지만).
기존 연구들(모델링 뿐만 아니고, R0값 등을 알아낸 생명과학적 연구)들을 참고하여, 이대로 진행했을 때와 추가 숨어있는 변수를 추가했을 때랑의 차이를 포커싱하도록 하자.
