
Why VGG
‘large scale image recognition’의 accuracy와 ‘network depth’의 상관관계를 알고싶어서?
- 네트워크 depth 키우기
- 3 × 3 Conv 필터 고정적으로 사용하기
- (1번과 중첩) 16~19 weight layers 사용하기

Introduction Part
레이어의 깊이, 모든 레이어에 3×3 Conv 필터를 동일하게 적용

Q1. 왜 3×3 필터를 고정적으로 사용했을까?
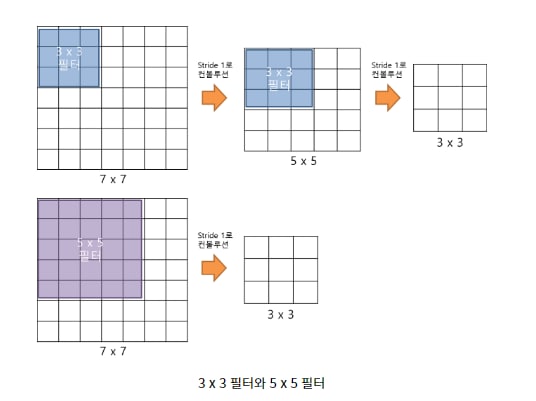
- 3 × 3 필터로 2번 Convolution 하는 것과 5 × 5 필터로 1번 Convolution 하는 것은 동일한 사이즈의 Feature Map을 나타냄.
- 채널 수를 C라고 가정했을 때, VGGNet에서 3 × 3 필터를 사용한 이유는, 3 × 3 필터 3개를 쌓았을 경우에 총 27×C^2개의 가중치 파라미터를 갖고, 7 × 7 의 필터를 사용할 경우에 49×C^2의 가중치 파라미터 개수를 갖는다. 즉 연산량을 줄일 수 있다.
- 1개의 큰 필터 레이어를 거치는 것보다, 3개의 작은 필터를 거치면서 ‘비선형성’을 증가시킬 수 있다.
Architecture part
-
Input Image Size는 224 × 224로 고정한다.
- Input Image에 대한 전처리과정은 RGB mean Value를 빼주는 것만을 적용한다.
- RGB mean Value : 이미지 상의 pixel들이 가자고 있는 R,G,B 각각의 평균값
- Input Image에 대한 전처리과정은 RGB mean Value를 빼주는 것만을 적용한다.
-
Conv Layer
- 3 × 3 Conv Filter를 사용한다.(3×3이 left,right,up,down 4가지 방향을 고려할 수 잇는 최소한의 receptive field이기 때문에)
- 1 × 1 Conv Filter를 사용한다. (비선형성 증가를 위해 + 연산량 감소(?))
- 왜 1 × 1 Conv Filter를 중간에 넣어주면 비선형성이 증가할까? 참고 자료 → 모델을 깊게 구성하는 과정에서 기존보다 많은 수의 비선형성 활성화 함수(ex. ReLU)를 사용하게 되기 때문에.
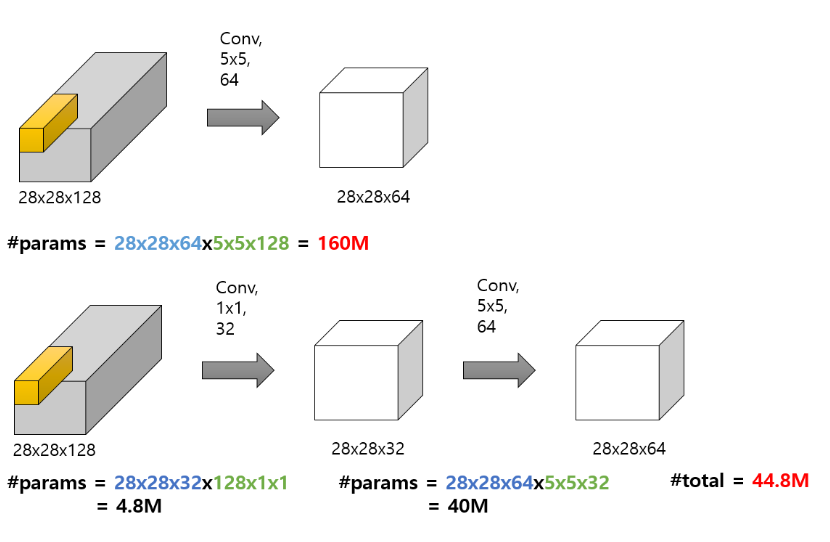
- 왜 1 × 1 Conv Filter를 중간에 넣어주면 비선형성이 증가할까? 참고 자료 → 모델을 깊게 구성하는 과정에서 기존보다 많은 수의 비선형성 활성화 함수(ex. ReLU)를 사용하게 되기 때문에.
- Conv Filter는 stride가 1이고, 연산 시 padding이 적용됨
- Pooling Layer
- Max Pooling은 Conv Layer 다음에 적용되고 총 5개의 Max Pooling Layer로 구성된다.
- Pooling 연산은 2×2, stride 2로 구성된다.
- FC(Fully-Connected) layer
- 4096,4096,1000 channel로 이루어져있다.
- 모든 hidden layer에는 ReLU 활성화 함수가 적용된다.
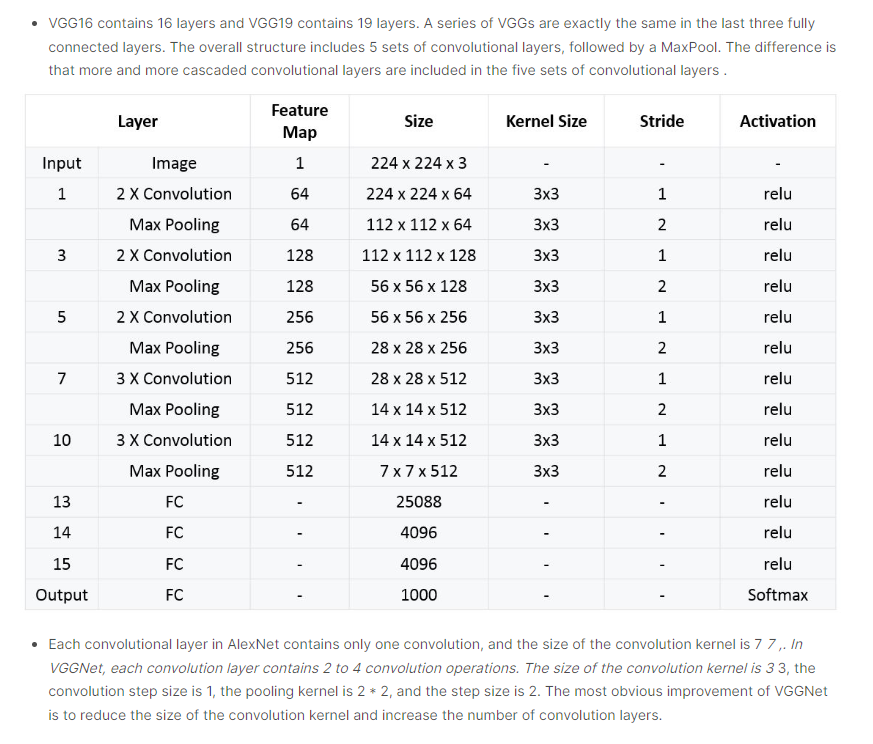
Configuration Part
“해당 파트에서는 layer depth에 따라 VGG 모델을 조금씩 변형시켜 연구를 진행했다고 언급하고 있다. 모델명은 A~E까지 있으며, 각 11~19 Weight layers를 이루고 있다.”
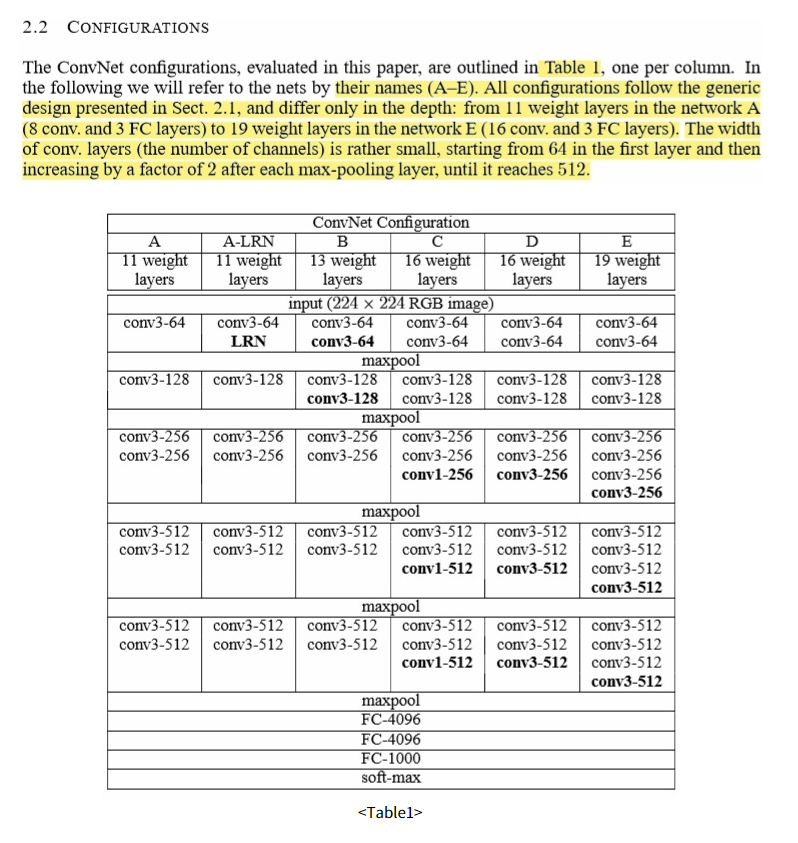
“모델의 depth가 증가하더라도 증가 계수에 비해 parameter개수가 크게 증가하지 않는다는 특징을 갖고 있다.”


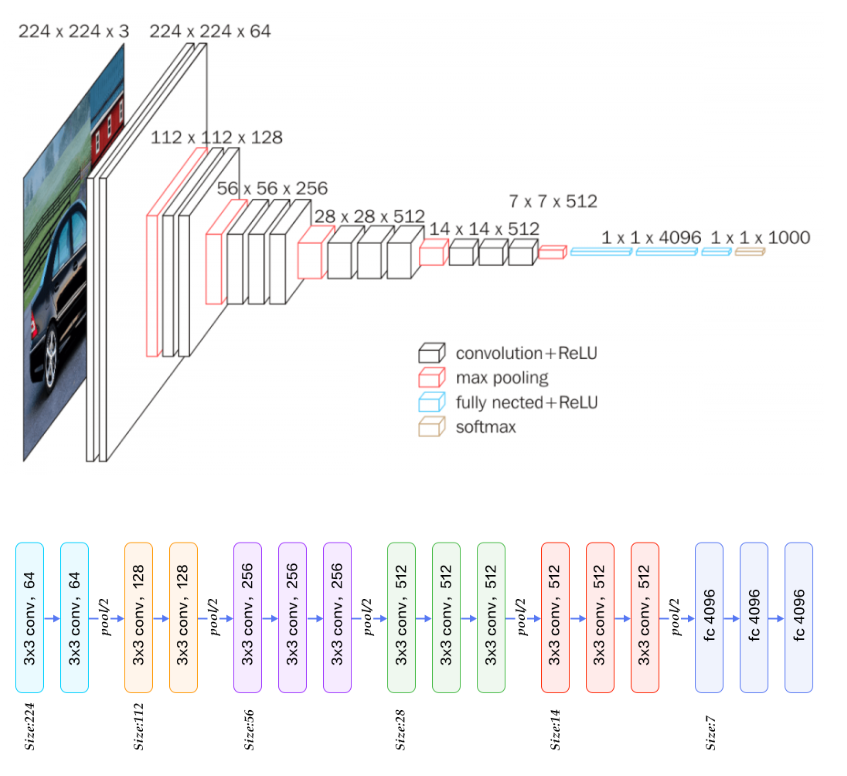
“Discussion Part의 내용을 Architecture Part에서 다뤘기 때문에 넘어가도록 하겠습니다.”
Training Part
“AlexNet보다 더 깊고, 파라미터도 살짝 더 많지만 더 적은 epoch을 기록했다고 언급되어 있음”
why?
- implicit regularisation
- 3×3 필터 3개 < 7×7 필터 1개
- pre-initialisation of certain layers
- VGG A모델의 처음 4개의 Conv Layers 와 마지막 3개의 Fully connected layer의 가중치 값들로 다음 B,C,D,E 모델들을 구성할 때 사용함.
- 가중치 초기값 설정은 모델 학습을 용이하게 도와줌.

Training Image Size
VGG 모델의 Input Size에 맞게 Input Image 사이즈 조절해줌


-
Single-scale Training
- S를 256 또는 384로 고정시켜서 사용하는 방법
- 384를 사용할 때는 256으로 줄여서 학습시킨 VGG모델의 가중치값들을 기반으로 다시 학습시킴.(단 384 구간에서는 lr 줄임)
-
Multi-scale Training
- 256~512 중 S를 random하게 설정해줌.
- 일종의 data agumentation 방법이고, ‘scale jittering’이라고 함
Test Part
Test Input size의 경우도 Training과 마찬가지로 조절해줌.

- Training image를 rescaling 할 때, 기준값이 S였다면, Test image를 rescaling할 때 기준이 되는 값을 Q라고 함.
- S == Q 일 필요는 없는데, Training image에서 설정한 S값과 다른 Q를 적용하면 성능이 좋아진다고 함.
Testing 할 때 구조와 Training 할 때 구조가 약간 다름.
→ 오버피팅을 막기 위해

-
Test에서는 Training에서 사용되던 첫 번째, FC layer를 7×7로 변경하고, 나머지 2개의 FC layer를 1×1로 변경하였음. 이를 통해, uncropped 이미지에 적용할 수 있다고 함.(?)
어떻게?
이 부분 이해 X
softmax 들어가기 직전에 result(output)은 input image size에 따라서 달라질 수 있음.

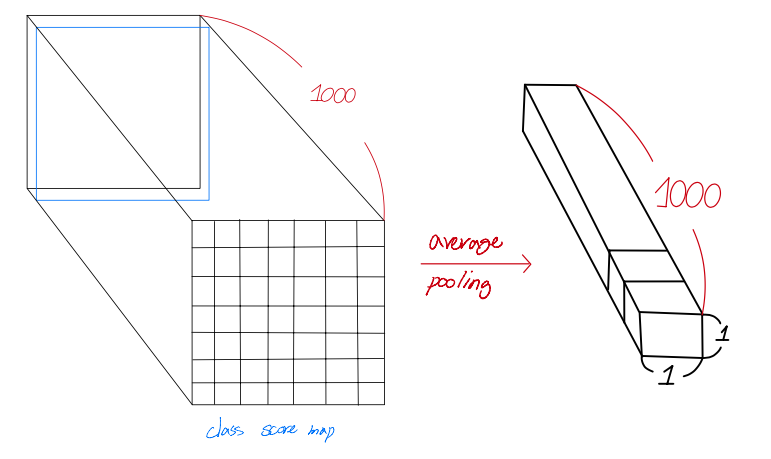
- 1×1이 아닌, 7×7의 feature map을 가질 수도 있음.
- spartially averaged(sum-pooled)으로 pooling 작업을 해 줌.
#pytorch
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))#keras
pooling: Optional pooling mode for feature extraction
when `include_top` is `False`.
- `None` means that the output of the model will be
the 4D tensor output of the
last convolutional block.
- `avg` means that global average pooling
will be applied to the output of the
last convolutional block, and thus
the output of the model will be a 2D tensor.
- `max` means that global max pooling will
be applied.
if pooling == 'avg':
x = layers.GlobalAveragePooling2D()(x)
elif pooling == 'max':
x = layers.GlobalMaxPooling2D()(x)Code 및 참고자료 출처
Very Deep Convolutional Networks for Large-Scale Image Recognition
models/vgg.py at master · tensorflow/models
vision/vgg.py at baa592b215804927e28638f6a7f3318cbc411d49 · pytorch/vision
VGGNet-16 Architecture: A Complete Guide
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
본 포스팅은 개인 공부용으로 논문 외에 위 블로그 및 자료를 참고하였습니다.
