
최근의 모든 머신 러닝 시스템은 일반적으로 텐서를 기본 데이터 구조로 사용한다.
데이터를 위한 컨테이너라고 생각하면된다.
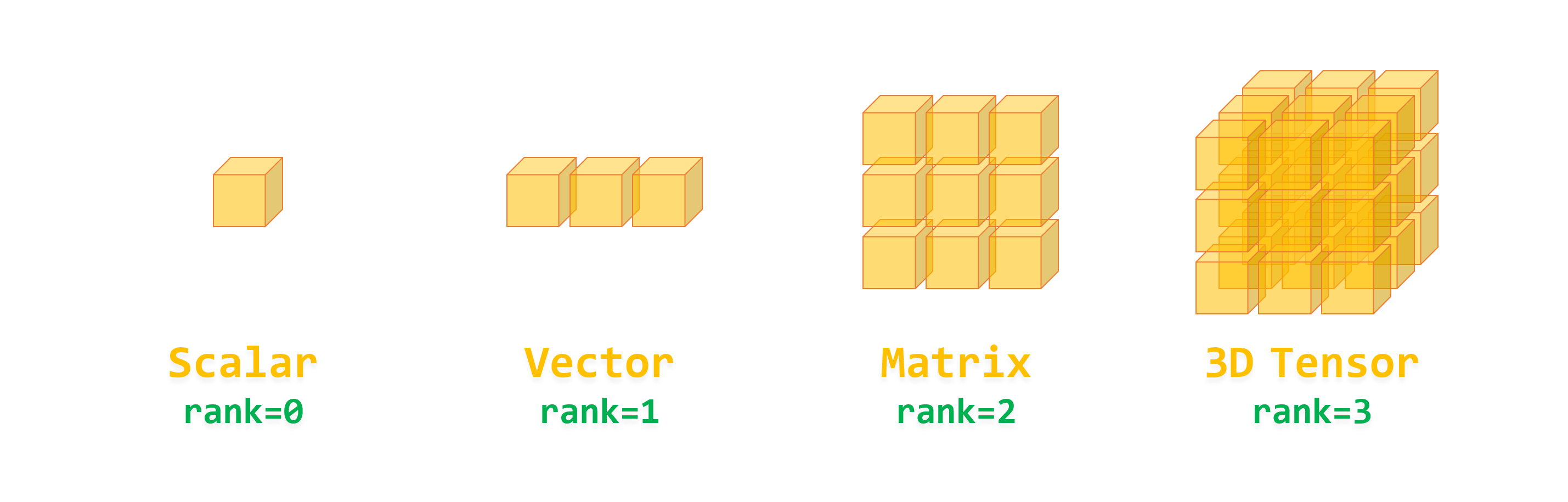
텐서의 특성
- 축의 개수:
랭크라고도 부르며 넘파이 배열에서는ndim을 통해 확인할수있다.
- 크기:
텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타낸 튜플 넘파이 배열에서는shape을 통해 확인할수있다.
- 데이터 타입:
텐서에 포함된 데이터 타입이다.
타입은 float32, unit8, float64 등이 될 수 있으며 문자열은 지원하지 않는다.dtpye속성으로 데이터를 확인할 수 있다.
 출처:https://codetorial.net/tensorflow/basics_of_tensor.html
출처:https://codetorial.net/tensorflow/basics_of_tensor.html
1. 스칼라(0D Tensor)
- 하나의 숫자만을 담고 있는 텐서를 스칼라라고 하며 0차원텐서 라고 한다.
- 스칼라의 축의 개수는 0개이다.
scalar = np.array(10)
print(scalar)
print(scalar.ndim)
print(scalar.shape)10
0
()2. 벡터(1D Tensor)
- 숫자들의 배열을 벡터라고 하며 1차원 텐서라고 한다.
- 벡터의 축의 개수는 1개이다.
vector = np.array([1, 2, 3, 4, 5])
print(vector)
print(vector.ndim)
print(vector.shape)[1 2 3 4 5]
1
(5,)3. 행렬(2D Tensor)
- 벡터들의 배열을 행렬 이라고 하며 2차원 텐서라고 한다.
- 행렬에는 행과 열 2가지의 축이 있다.
matrix = np.array([[1, 2, 3],
[4, 5, 6]])
print(matrix)
print(matrix.ndim)
print(matrix.shape)[[1 2 3]
[4 5 6]]
2
(2, 3)4. 고차원 텐서
- 행렬들을 하나의 새로운 배열을 합치면 숫자로 채워진 직육면체가 되는데 이는 3D Tensor이다.
- 딥러닝에서는 보통 5차원 텐서까지 다루게 된다.
tensor_3D = np.arange(24).reshape(2, 3, 4)
print(tensor_3D)
print(tensor_3D.ndim)
print(tensor_3D.shape)[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
3
(2, 3, 4)Tensor의 Shape
넘파이의 배열에서 shape를 이용하여 텐서의 크기를 알아볼 경우 return값은 다음과 같다
1차원: (열,)
2차원: (행, 열)
3차원: (깊이, 행, 열)
즉, 열의 기준이 되어 차원이 늘어날수록 늘어난 차원의 크기가 열의 앞에 추가된다고 생각하면된다.
머신러닝에서 사용하는 train_data의 shape은 다음과 같다.
1. 벡터 데이터: (samples, features) 2D tensor
집값 예측 문제라고 생각하고 주어진 데이터가 100개의 연식, 동네, 역세권의 유무에 따른 데이터라고 하면 (100, 3)크기의 텐서에 저장될 수 있다.
2. 이미지: (samples, height, width, channels) 4D tensor
채널 우선방식 과 채널 마지막 방식 으로 나뉘지만 보통의 경우 100 장의 28x28의 컬러 이미지라면 (100, 28, 28, 3)크기의 텐서에 저장될 수 있다.
3. 동영상: (samples, frames, height, channels) 5D tnesot
텐서의 조작
- 슬라이싱(slicing)을 이용한다.
import numpy as np
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()print(train_images.shape)(60000, 28, 28)28x 28배열의 사진이 6만장이 들어있는것을 뜻한다.
use_images = train_images[:100, :, :]
print(use_images.shape)(100, 28, 28)일반적으로 딥러닝에서 사용하는 모든 데이터 텐서의 첫번째 축(axis0)은 샘플 축(sample axis)이다. 즉 샘플의 개수를 의미한다. 위의 use_images에서는 100을 가르키고 이는 100장의 샘플 데이터가있다는 뜻이다.
위와 같은 샘플축의 슬라이싱은 모델 수행시 배치 데이터를 나눌때 사용된다.
배치 데이터를 다룰 때는 첫번째 축(axis0)를 배치축(batch axis) 또는 배치차원(batch dimension)이라고 부른다.
# 6만장의 데이터 중에서 위쪽 절반만 사용하고 싶을 경우
use_images = train_images[: , :14 , :]
print(use_images.shape)(60000, 14, 28)