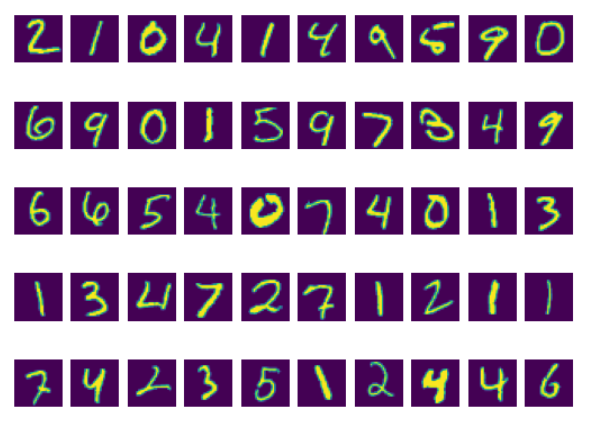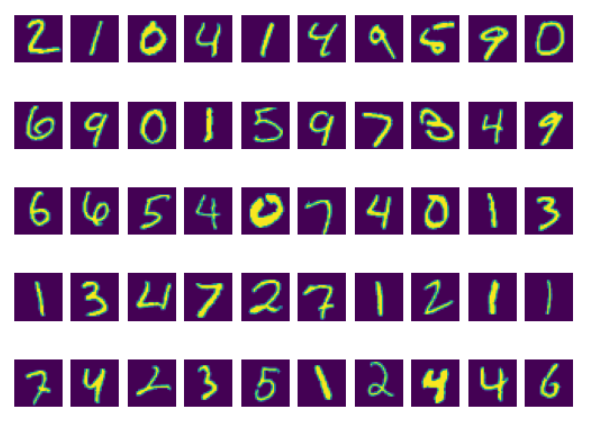1. PyTorch 라이브러리 및 함수 가져오기
# PyTorch를 임포트합니다.
import torch
# torchvision을 사용하여 데이터셋과 유용한 이미지 변환들을 가져옵니다.
import torchvision
import torchvision.transforms as transforms
# PyTorch의 최적화 라이브러리와 nn을 임포트합니다.
# nn은 네트워크 그래프를 위한 기본 구성 블록으로 사용됩니다.
import torch.optim as optim
import torch.nn as nn
# CUDA가 사용 가능한지 확인합니다.
print("CUDA available: {}".format(torch.cuda.is_available()))라이브러리를 가져오고
CUDA가 사용한지 확인한다.
CUDA는 NVIDIA의 GPU에서 동작하는 병렬 컴퓨팅 플랫폼 및 API 모델이며
PyTorch와 같은 딥러닝 프레임워크에서 GPU를 활용하여 연산을 가속화 해준다.

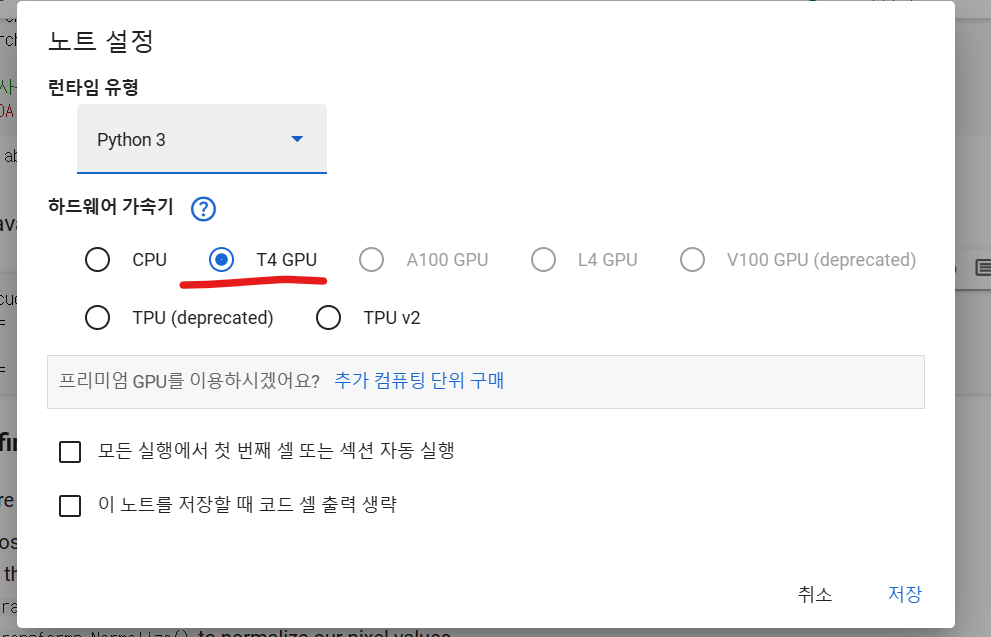
false로 뜬다면 CPU로 동작하고 있는것으로
노트 설정에서 T4 GPU를 클릭해준다.
CPU에서 변경하게 될시 다시 시작해줘야 한다.
device 정의
GPU가 사용가능하면 device가 cuda로 저장하고
아니라면 cpu를 사용한다라는 정의해준다.
if torch.cuda.is_available():
device = 'cuda'
else:
device = 'cpu' 2. Transformation Pipeline
# 이미지 데이터를 PyTorch 텐서로 변환하고 -1과 +1 사이로 정규화합니다
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))
])-
transforms.ToTensor()
PIL 이미지나 NumPy ndarray를 PyTorch 텐서로 변환텐서로 변환되면 이미지의 픽셀 값 범위가 0에서 255에서 0.0에서 1.0 사이로 자동 조정된다.
-
transforms.Normalize((0.5,), (0.5,))
데이터를 정규화하여 평균(mean)이 0.5이고 표준편차(standard deviation)가 0.5인 데이터로 조정한다는 뜻이며,
결과적으로 데이터의 범위를 -1에서 +1로 조정하는 효과를 갖고 있다.
0.5를 사용하는 이유
이미지 데이터의 픽셀 값 범위가 -1에서 1로 조정되어
신경망이 다루기에 더 적합한 형태로 데이터가 변환된다.
3. torchvision 라이브러리를 사용하여 MNIST 데이터셋을 로드
PyTorch의 torchvision 라이브러리를 사용해서 MNIST 데이터셋을 로드한다.
(MNIST 데이터셋은 손으로 쓴 숫자 이미지들로 구성됐다)
# 훈련 데이터를 로드하고 로딩 시 사용할 변환을 지정합니다
trainset = torchvision.datasets.MNIST('mnist',
train=True, # 트레이닝 데이터셋 가져옴
download=True, # false 일시 하드웨어에서 가져옴
transform=transform) # 2번에서 정의한 transform이다.
# 테스트 데이터를 로드하고 로딩 시 사용할 변환을 지정합니다
testset = torchvision.datasets.MNIST('mnist',
train=False,
download=True,
transform=transform)인자를 다르게 설정한 MNIST 데이터셋 trainset, testset 두개를 가져온다.
4. 훈련 데이터 샘플 검토하기
우리의 훈련 데이터와 테스트 데이터셋의 차원을 살펴보자.
# 훈련 데이터에는 60,000개의 이미지 샘플이 있고, 테스트 데이터에는 10,000개가 있습니다.
# 각 이미지는 28 x 28 픽셀이며, 그레이스케일 이미지이므로 이미지의 3차원은 없습니다.
print(trainset.data.shape)
print(testset.data.shape)MNIST 데이터셋 내의 훈련 및 테스트 이미지의 차원을 출력하여
데이터셋의 구조를 이해하기 위함이다.

여기서 다시 trainset과 testset의 차이점을 확인하자
무엇을 위한 trainset, testset인가
trainset(훈련 데이터셋)
인자로 train = True로
모델학습에 사용될 이미지 샘플을 포함하는 훈련을 위한 데이터셋을 가져왔고
testset은 train = false로 모델을 평가하는데 사용되는 이미지 샘플을 포함하는 테스트 데이터셋인것이다.
그것이 각각 60000개, 10000개가 있는것이고 28x28 크기의 흑백 이미지이며,
60000개의 이미지로 학습한 후 나온 모델을 가지고
10000개의 이미지를 테스트 하는것이 각 데이터셋의 목적이다.
이미지 확인
# 데이터 세트의 첫번째 값
print(trainset.data[0].shape)
print(trainset.data[0])위 코드를 사용해서 첫번째 이미지의 데이터를 불러와보자
trainset의 데이터는 총 60000개가 있어서
trainset.data[0]~trainset.data[59999] 로 구성돼있다.
이중에 첫번째 이미지인 trainset.data[0] 에대해서 알아보는것인데,
그것의 shape는 흑백이미지에 28x28 이므로
(28, 28) 출력될 것이다.
torch.Size([28, 28])
tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 18,
18, 18, 126, 136, 175, 26, 166, 255, 247, 127, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 30, 36, 94, 154, 170, 253,
253, 253, 253, 253, 225, 172, 253, 242, 195, 64, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 49, 238, 253, 253, 253, 253, 253,
253, 253, 253, 251, 93, 82, 82, 56, 39, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 18, 219, 253, 253, 253, 253, 253,
198, 182, 247, 241, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 80, 156, 107, 253, 253, 205,
11, 0, 43, 154, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 14, 1, 154, 253, 90,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 139, 253, 190,
2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 11, 190, 253,
70, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 35, 241,
225, 160, 108, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 81,
240, 253, 253, 119, 25, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
45, 186, 253, 253, 150, 27, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 16, 93, 252, 253, 187, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 249, 253, 249, 64, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
46, 130, 183, 253, 253, 207, 2, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 39, 148,
229, 253, 253, 253, 250, 182, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 114, 221, 253,
253, 253, 253, 201, 78, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 23, 66, 213, 253, 253, 253,
253, 198, 81, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 18, 171, 219, 253, 253, 253, 253, 195,
80, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 55, 172, 226, 253, 253, 253, 253, 244, 133, 11,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 136, 253, 253, 253, 212, 135, 132, 16, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=torch.uint8)대충 검은 배경에 흰 무언가가 흩뿌려져있는 느낌의 이미지로 상상된다.
근데 아까 transform 정의를 하면서 데이터가
-1 ~ 1 로 정규화될줄 알았는데 그렇지 않은 모습을 확인할수있다.
OpenCV를 사용해서 해당 이미지를 출력
출력을 하기위해서는 tensor를 numpy 배열로 변환해야 한다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
# imshow 정의
def imgshow(title="", image = None, size = 6):
w, h = image.shape[0], image.shape[1]
aspect_ratio = w/h
plt.figure(figsize=(size * aspect_ratio,size))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(title)
plt.show()
# 이미지를 숫자 배열로 변환
image = trainset.data[0].numpy()
imgshow("MNIST Sample", image)numpy배열로 변환하는 코드는 아래 한줄이다.
image = trainset.data[0].numpy()아까 상상했던 이미지와 비슷하다
print(trainset.data[0])

같은 방식으로 50개 이미지 출력
이미지를 numpy 배열화 시켜줘야 하는데, 그 숫자가 50개와 같이 많다면
import matplotlib.pyplot as plt
# MNIST 훈련 데이터 세트에서 첫 번째 이미지 50개를 시각화합니다.
figure = plt.figure()
num_of_images = 50 # 표시할 이미지 수
for index in range(1, num_of_images + 1):
plt.subplot(5, 10, index) # 5행 10열의 서브플롯 생성
plt.axis('off') # 축 표시 제거
plt.imshow(trainset.data[index], cmap='gray_r') # 이미지를 그레이스케일로 표시
보기 좋게 그레이스케일을 했다.

그레이 스케일을 하지 않은 훈련데이터셋이다.
trainset 상위 50개 데이터

testset 상위 50개 데이터