5. 데이터 로더 생성
데이터 로더는 지정된 배치 크기(여기서는 128)를 사용하여
훈련 중에 데이터를 가져오는 함수이다.
나누는 이유는 모든 데이터를 한 번에 네트워크에 입력할 수 없기 때문이다.
훈련 및 테스트 로더 준비
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=128, # 배치 크기를 128로 설정합니다.
shuffle=True, # 데이터를 섞어서 로드합니다.
num_workers=0) # 데이터 로딩에 사용할 CPU 코어 수를 0으로 설정합니다.
testloader = torch.utils.data.DataLoader(testset,
batch_size=128, # 배치 크기를 128로 설정합니다.
shuffle=False, # 데이터를 섞지 않고 로드합니다.
num_workers=0) # 데이터 로딩에 사용할 CPU 코어 수를 0으로 설정합니다.- 데이터 시퀀스 편향 방지
일부 데이터셋에 각 클래스가 순서대로 정렬되있는 경우 = 같은 숫자가 여러개 있다.
단일 클래스만 포함된 배치를 로드하는 것을 방지하기 위해
Shuffle = true로 설정했다.
- CPU 사용
num_workers는 사용하려는 CPU 코어의 수를 지정하는걸로
CUDA를 사용할 것이기 때문에 0으로 설정했다.
Iter 및 Next()를 로드 배치에 사용
for는 순서대로 출력하는 반면, iter와 next 를 사용하면
각 요소를 직접 하나씩 가져올 수 있다.
하는 이유는 처리속도가 빨라진다.
# trainloader 객체의 이터레이터를 반환합니다
dataiter = iter(trainloader)
# 이터레이터에서 첫 번째 배치의 데이터를 가져옵니다
images, labels = next(dataiter)
print(images.shape)
print(labels.shape)
결과
- torch.Size([128, 1, 28, 28])
128개의 이미지
각 이미지는 1개의 채널(흑백 이미지)
높이 28 픽셀
너비 28 픽셀
- torch.Size([128])
레이블 텐서의 크기를 나타내며,
각 배치에는 128개의 레이블이 있고, 각 레이블은 단일 값(숫자 클래스) 이다.
해석
-
이미지 텐서(images)
배치 크기: 128 (한 번에 128개의 이미지를 처리)
채널 수: 1 (흑백 이미지)
이미지 크기: 28x28 픽셀 -
레이블 텐서(labels)
배치 크기: 128 (각 이미지에 해당하는 128개의 레이블)
images[0].shapeimages[0]~images[127] 로 128개 구성돼있고
1차원 흑백 이미지에 28x28 이라는것을 확인했다.
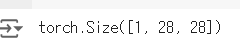
PyTorch는 자체 이미지 시각화 도구를 제공
import matplotlib.pyplot as plt
import numpy as np
# 이미지를 표시하는 함수
def imshow(img):
img = img / 2 + 0.5 # 정규화를 해제합니다
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()이미지 텐서를 받아서 정규화를 해제한 후, matplotlib을 사용하여 이미지를 표시하는 함수
2.
# 일부 랜덤한 훈련 이미지를 가져옵니다
dataiter = iter(trainloader)
images, labels = next(dataiter)trainloader에서 이터레이터를 생성하고, next를 사용하여 랜덤한 배치의 이미지와 레이블을 가져온다.
3.
# 이미지를 표시합니다
imshow(torchvision.utils.make_grid(images))torchvision.utils.make_grid를 사용하여 여러 이미지를 그리드 형식으로 배치한 후, imshow 함수를 사용하여 이미지를 표시

4.
# 레이블을 출력합니다
print(' '.join('%1s' % labels[j].numpy() for j in range(128)))
배치에 포함된 128개의 레이블을 출력합니다. 각 레이블은 0에서 9 사이의 숫자로, 각 이미지에 해당하는 숫자 클래스이다.
1 2 5 5 1 2 6 3 9 1 3 8 8 8 6 4 3 1 8 1 2 5 7 1 1 2 9 3 3 8 9 7 3 0 1 9 3 8 3 1 0 0 1 7 2 7 4 3 0 0 4 4 9 8 7 3 7 6 3 2 0 1 9 2 5 6 5 3 2 2 8 3 0 0 7 6 9 2 7 8 0 1 1 1 7 1 0 4 3 0 0 9 7 9 4 1 0 2 1 0 7 7 0 2 6 4 1 7 6 3 1 9 5 4 9 7 7 0 2 9 0 4 6 3 0 1 4 5여기서 이해하고 넘어가야할것은
labels은 꼬리표로
images, labels = next(dataiter) 이작업에서
images에는 이미지 데이터가,
labels에는 각 이미지에 해당하는 꼬리표가 담겼다는 것이다.
6. 모델 만들기
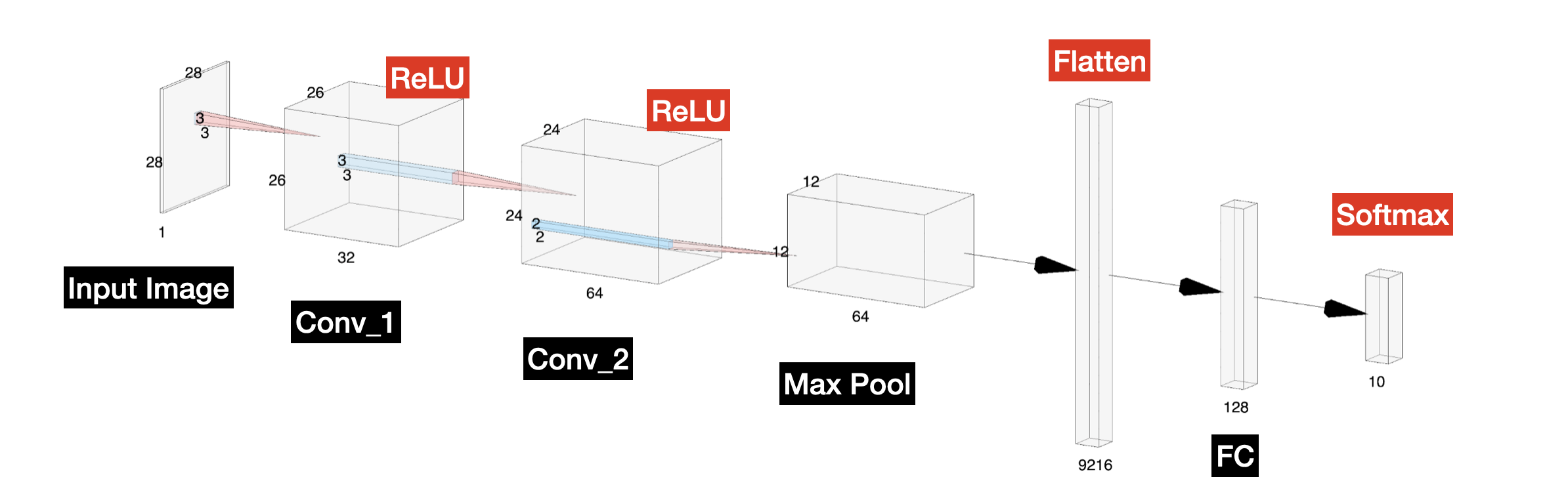
해당 CNN 만들것인데,
하나하나 확인
이론
1. Input Image > Conv_1
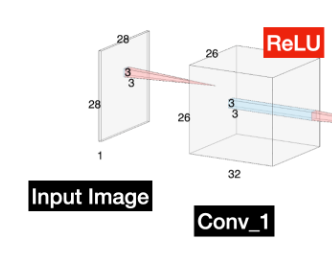
A. 입력 이미지: (1, 28, 28)
흑백 이미지로, 채널 수는 1이고, 크기는 28x28
B. 첫 번째 합성곱 레이어: Conv1
입력 크기: (1, 28, 28)
출력 크기: (32, 26, 26)
32개의 3x3 필터를 사용하고, 스트라이드 1과 패딩 0을 적용하여
C. ReLU 활성화 함수: Conv1 후
출력 크기: (32, 26, 26)
비선형성을 추가
2. Conv_1 > Conv_2

입력 크기: (32, 26, 26)
출력 크기: (64, 24, 24)
커널 크기: 3x3
스트라이드: 1
3. Conv_2 > Max Pool

입력 크기: (64, 24, 24)
출력 크기: (64, 12, 12)
커널 크기: 2x2
스트라이드: 2
Max Pool을 적용했기때문에 크기가 2배줄어듬,
처리량은 1/4됨
3. Max Pool > Platten

입력(64,12,12)
2차원 이미지 데이터를 1차원 벡터로 변환
출력(9216)
4. Platten > FC1
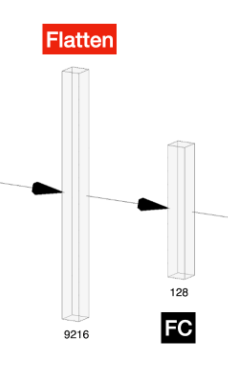
입력 크기: (9216)
처리: 9216개의 입력을 받아 128개의 노드에 연결
출력 크기: (128)
5. FC1 > FC2(Output)
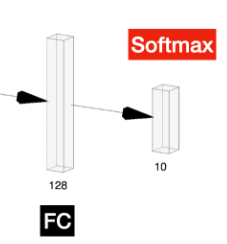
입력 크기: (128)
처리: 128개의 입력을 받아 10개의 출력 노드(클래스)로 연결
출력 크기: (10)
활성화 함수: Softmax에는 10개의 확률값을 가지고
10개의 확률값을 다 더하면 1이 나온다.
코드
하나하나 풀어서 봤으니 이제 이것을 코드로 PyTorch를 이용해 코드로 구현해보자
import torch.nn as nn
import torch.nn.functional as F
# 모델을 Python 클래스로 생성
class Net(nn.Module):
def __init__(self):
# super는 nn.Module의 서브클래스로, 모든 메서드를 상속받습니다
super(Net, self).__init__()
# 레이어 객체를 정의합니다
# 첫 번째 CNN 레이어, 32개의 3x3 크기 필터, stride 1, padding 0
self.conv1 = nn.Conv2d(1, 32, 3)
# 두 번째 CNN 레이어, 64개의 3x3 크기 필터, stride 1, padding 0
self.conv2 = nn.Conv2d(32, 64, 3)
# Max Pool 레이어, 2x2 커널, stride 2
self.pool = nn.MaxPool2d(2, 2)
# 첫 번째 완전 연결 레이어 (Linear), Max Pool의 출력을 받아서
# 12 x 12 x 64 크기의 출력을 128개의 노드에 연결합니다
self.fc1 = nn.Linear(64 * 12 * 12, 128)
# 두 번째 완전 연결 레이어, 128개의 노드를 10개의 출력 노드(클래스)로 연결합니다
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 여기에서 순방향 전파 순서를 정의합니다
# 순서는 Conv1 - Relu - Conv2 - Relu - Max Pool - Flatten - FC1 - FC2 입니다
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 12 * 12) # Flatten
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 모델 인스턴스를 생성하고 CUDA 디바이스로 이동시킵니다 (메모리와 연산을)
net = Net()
net.to(device)
흐름은 아래와 같다
Conv1 - Relu - Conv2 - Relu - Max Pool - Flatten - FC1 - FC2
컨볼루션 연산은 Conv2d을 사용하고
MaxPool은 MaxPool2d을 사용한다
평탄화 한후 노드로 연결해주는 것은 Linear
저 코드를 실행해서 결과를 출력해보자

이어서 출력 결과를 해석해보면
- (Conv1):
입력 이미지의 채널 수가 1인 흑백 이미지(Input Image)에 대해 32개의 3x3 필터를 적용
- (Conv2):
Conv1의 출력을 입력으로 받아 64개의 3x3 필터를 적용합니다.
- (MaxPool2d):
Conv2의 출력을 받아 2x2 풀링 커널을 사용하여 공간 크기를 절반으로 줄입니다.
- (FC1):
MaxPool2d의 출력을 평탄화하여 9216개의 입력 노드를 128개의 출력 노드로 변환합니다.
- (FC2) = [Softmax]:
FC1의 출력을 받아 128개의 입력 노드를 10개의 출력 노드로 변환합니다. 최종 출력은 10개의 클래스 확률입니다.
이렇게 하나의 간단한 CNN를 PyTorch를 이용해 빌드해봤다.
코드가 굉장히 복잡해 보이지만 주석을 제거해보면 의외로 간결하다.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 12 * 12, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 12 * 12)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
net = Net()
net.to(device)