7. 손실 함수 및 최적화 정의
PyTorch를 사용하여 신경망 모델의 최적화(학습) 설정을 하는 예제
이 예제를 수행하기 전에 신경망 모델 net은
이미 정의되어 있어야 한다.
- optimizer 함수 선언
import torch.optim as optimPyTorch의 최적화 도구(optimizers)를 가져온다.
이는 모델 학습 시 가중치를 조정하는 알고리즘을 포함하고 있다.
- 교차 엔트로피 손실(Cross Entropy Loss)를 손실 함수로 사용
criterion = nn.CrossEntropyLoss()모델의 예측 값과 실제 값 간의 차이를 계산하여 손실을 구하는데 사용한다.
- 확률적 경사 하강법(Stochastic Gradient Descent, SGD)을 사용하여 모델의 가중치를 업데이트
# 경사 하강법 알고리즘 또는 Optimizer를 설정합니다
# 학습률(learning rate)을 0.001로 설정한 Stochastic Gradient Descent (SGD)를 사용합니다
# 모멘텀(momentum)을 0.9로 설정합니다
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)A. lr=0.001은 학습률(learning rate)을 설정
학습률은 가중치를 업데이트할 때 얼마나 크게
조정할지를 결정하는 인자
B. momentum=0.9은 모멘텀(momentum)을 설정
모멘텀은 경사 하강법의 수렴 속도를 높이고
진동을 줄이는 데 도움을 준다.
8. 모델 트레이닝(Training Time!)
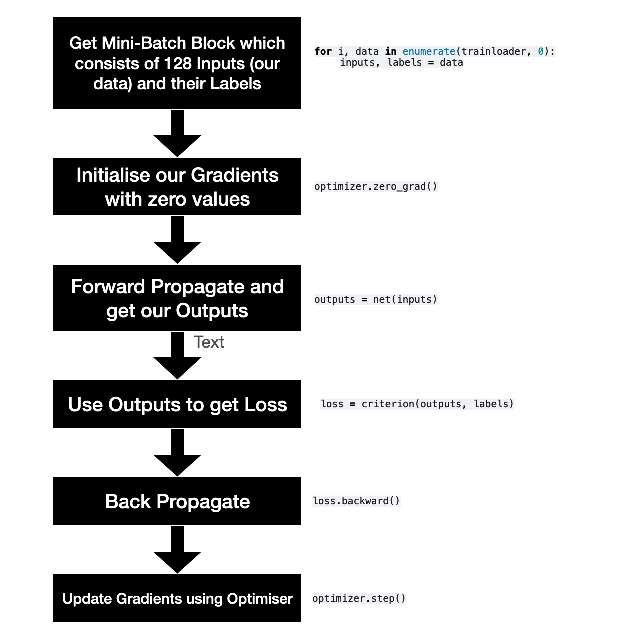
이 흐름도는 신경망 모델 학습의 기본적인 단계를 시각적으로 설명하고,
각 단계가 어떻게 코드로 구현되는지 보여준다.
그럼 또 하나씩 해석해보자.
모델 학습 흐름
- Mini-Batch 가져오기
for i, data in enumerate(trainloader, 0):
inputs, labels = data습 데이터셋에서 미니 배치 블록(128개의 입력 데이터와 해당 레이블)을 가져온다.
- 그래디언트 초기화
optimizer.zero_grad()학습 전에 그래디언트를 0으로 초기화
- 순전파 (Forward Propagation)
outputs = net(inputs)모델에 입력 데이터를 전달하여 출력값을 얻는다.
- 손실 계산
loss = criterion(outputs, labels)출력값을 사용하여 손실을 계산
손실 함수는 모델 예측과 실제 값 간의 차이를 정량화한다.
- 역전파 (Back Propagation):
loss.backward()손실을 기반으로 그래디언트를 계산하여 가중치의 변화량을 얻는다.
- 최적화기를 사용하여 그래디언트 업데이트
optimizer.step()최적화기를 사용하여 모델의 가중치를 업데이트
코드
# 학습 데이터셋을 여러 번 반복하여 학습합니다 (각 반복을 epoch라고 합니다)
# 실제로는 50을 많이쓴다.
epochs = 10
# 로그를 저장할 빈 배열을 만듭니다
epoch_log = []
loss_log = []
accuracy_log = []
# 지정된 횟수만큼 에포크를 반복합니다
for epoch in range(epochs):
print(f'에포크 시작: {epoch+1}...')
# 각 미니 배치 후 손실을 누적하여 running_loss에 추가합니다
running_loss = 0.0
# trainloader 이터레이터를 통해 반복합니다
# 각 사이클은 하나의 미니 배치입니다
for i, data in enumerate(trainloader, 0):
# 입력 데이터를 가져옵니다; data는 [입력, 레이블]의 리스트입니다
inputs, labels = data
# 데이터를 GPU로 이동합니다
inputs = inputs.to(device)
labels = labels.to(device)
# 훈련 전에 그래디언트를 0으로 초기화합니다
# 새로 시작하기 위해 필요합니다
optimizer.zero_grad()
# 순전파 -> 역전파 + 최적화
outputs = net(inputs) # 순전파
loss = criterion(outputs, labels) # 손실 계산 (결과와 예측 간의 차이를 정량화)
loss.backward() # 역전파를 통해 모든 노드의 새로운 그래디언트 계산
optimizer.step() # 그래디언트/가중치 업데이트
# 훈련 통계 출력 - 에포크/반복/손실/정확도
running_loss += loss.item()
if i % 50 == 49: # 50개 미니 배치마다 손실 출력
correct = 0 # 올바른 예측 개수를 저장할 변수를 초기화
total = 0 # 반복된 레이블 수를 저장할 변수를 초기화
# 검증을 위해 그래디언트가 필요 없으므로
# 메모리를 절약하기 위해 no_grad로 래핑
with torch.no_grad():
# testloader 이터레이터를 통해 반복합니다
for data in testloader:
images, labels = data
# 데이터를 GPU로 이동합니다
images = images.to(device)
labels = labels.to(device)
# 테스트 데이터 배치를 모델을 통해 순전파
outputs = net(images)
# 예측된 출력 텐서의 최대값에서 예측값을 가져옵니다
# dim = 1은 축소할 차원의 수를 지정합니다
_, predicted = torch.max(outputs.data, dim=1)
# total 변수에 레이블의 크기 또는 길이를 계속 더합니다
total += labels.size(0)
# 올바르게 예측된 예측 개수를 계속 합산합니다
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
epoch_num = epoch + 1
actual_loss = running_loss / 50
print(f'에포크: {epoch_num}, 완료된 미니 배치 수: {(i+1)}, 손실: {actual_loss:.3f}, 테스트 정확도 = {accuracy:.3f}%')
running_loss = 0.0
# 각 에포크 후 학습 통계를 저장합니다
epoch_log.append(epoch_num)
loss_log.append(actual_loss)
accuracy_log.append(accuracy)
print('훈련 완료')
학습데이터셋으로 학습하고 그 모델로 테스트 데이터셋을 테스트하는것으로
손실은 줄이면서 정확도를 높이는게 목적이다.
결과를 보면서 이해하자.
에포크 시작: 1...
에포크: 1, 완료된 미니 배치 수: 50, 손실: 2.273, 테스트 정확도 = 36.470%
에포크: 1, 완료된 미니 배치 수: 100, 손실: 2.137, 테스트 정확도 = 57.730%
에포크: 1, 완료된 미니 배치 수: 150, 손실: 1.720, 테스트 정확도 = 78.230%
에포크: 1, 완료된 미니 배치 수: 200, 손실: 0.934, 테스트 정확도 = 83.510%
에포크: 1, 완료된 미니 배치 수: 250, 손실: 0.556, 테스트 정확도 = 85.610%
에포크: 1, 완료된 미니 배치 수: 300, 손실: 0.464, 테스트 정확도 = 86.940%
에포크: 1, 완료된 미니 배치 수: 350, 손실: 0.441, 테스트 정확도 = 89.000%
에포크: 1, 완료된 미니 배치 수: 400, 손실: 0.402, 테스트 정확도 = 89.120%
에포크: 1, 완료된 미니 배치 수: 450, 손실: 0.390, 테스트 정확도 = 88.420%
에포크 시작: 2...
에포크: 2, 완료된 미니 배치 수: 50, 손실: 0.361, 테스트 정확도 = 90.650%
에포크: 2, 완료된 미니 배치 수: 100, 손실: 0.353, 테스트 정확도 = 89.270%
에포크: 2, 완료된 미니 배치 수: 150, 손실: 0.373, 테스트 정확도 = 89.920%
에포크: 2, 완료된 미니 배치 수: 200, 손실: 0.327, 테스트 정확도 = 91.150%
에포크: 2, 완료된 미니 배치 수: 250, 손실: 0.319, 테스트 정확도 = 90.010%
에포크: 2, 완료된 미니 배치 수: 300, 손실: 0.314, 테스트 정확도 = 90.980%
에포크: 2, 완료된 미니 배치 수: 350, 손실: 0.304, 테스트 정확도 = 91.600%
에포크: 2, 완료된 미니 배치 수: 400, 손실: 0.319, 테스트 정확도 = 91.260%
에포크: 2, 완료된 미니 배치 수: 450, 손실: 0.287, 테스트 정확도 = 90.830%
... (3~8 생략)
에포크 시작: 9...
에포크: 9, 완료된 미니 배치 수: 50, 손실: 0.094, 테스트 정확도 = 97.540%
에포크: 9, 완료된 미니 배치 수: 100, 손실: 0.091, 테스트 정확도 = 97.340%
에포크: 9, 완료된 미니 배치 수: 150, 손실: 0.097, 테스트 정확도 = 97.370%
에포크: 9, 완료된 미니 배치 수: 200, 손실: 0.085, 테스트 정확도 = 97.360%
에포크: 9, 완료된 미니 배치 수: 250, 손실: 0.080, 테스트 정확도 = 97.550%
에포크: 9, 완료된 미니 배치 수: 300, 손실: 0.091, 테스트 정확도 = 97.250%
에포크: 9, 완료된 미니 배치 수: 350, 손실: 0.084, 테스트 정확도 = 97.470%
에포크: 9, 완료된 미니 배치 수: 400, 손실: 0.087, 테스트 정확도 = 97.590%
에포크: 9, 완료된 미니 배치 수: 450, 손실: 0.078, 테스트 정확도 = 97.670%
에포크 시작: 10...
에포크: 10, 완료된 미니 배치 수: 50, 손실: 0.076, 테스트 정확도 = 97.470%
에포크: 10, 완료된 미니 배치 수: 100, 손실: 0.075, 테스트 정확도 = 97.640%
에포크: 10, 완료된 미니 배치 수: 150, 손실: 0.073, 테스트 정확도 = 97.380%
에포크: 10, 완료된 미니 배치 수: 200, 손실: 0.083, 테스트 정확도 = 97.690%
에포크: 10, 완료된 미니 배치 수: 250, 손실: 0.077, 테스트 정확도 = 97.710%
에포크: 10, 완료된 미니 배치 수: 300, 손실: 0.073, 테스트 정확도 = 97.740%
에포크: 10, 완료된 미니 배치 수: 350, 손실: 0.068, 테스트 정확도 = 97.590%
에포크: 10, 완료된 미니 배치 수: 400, 손실: 0.073, 테스트 정확도 = 97.820%
에포크: 10, 완료된 미니 배치 수: 450, 손실: 0.087, 테스트 정확도 = 97.580%
훈련 완료학습에는 6분 정도 소요됐다.
에포크 6부터는 97퍼센트에 머물고있고,
그 이상 잘 올리가지 않는다
이유는 간단하게도 학습 수 부족이다.
주석을 제거하고 보면 의외로 또 간결하다.
epochs = 10
epoch_log = []
loss_log = []
accuracy_log = []
for epoch in range(epochs):
print(f'Starting Epoch: {epoch+1}...')
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 50 == 49:
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
epoch_num = epoch + 1
actual_loss = running_loss / 50
print(f'Epoch: {epoch_num}, Mini-Batches Completed: {(i+1)}, Loss: {actual_loss:.3f}, Test Accuracy = {accuracy:.3f}%')
running_loss = 0.0
epoch_log.append(epoch_num)
loss_log.append(actual_loss)
accuracy_log.append(accuracy)
print('Finished Training')
9. 모델 저장하기.
PATH = './mnist_cnn_net.pth'
torch.save(net.state_dict(), PATH)torch.save() 함수를 사용하여 모델을 저장
net.state_dict()는 사전 형식으로 모델 가중치를 저장
가중치 파일과 모델 구조만 있으면 네트워크를 재생성 할 수 있고
원하는 방식으로 사용 가능하다.
이제 저걸 다운로드 하면 10회 학습했던 모델을 사용할수있다.
모델 불러오기
아래의 코드로 모델을 불러올 수 있다.
# 모델 인스턴스를 생성하고 CUDA 장치로 이동합니다 (메모리와 연산을 CUDA로 이동)
net = Net()
net.to(device)
# 지정된 경로에서 가중치를 로드합니다
net.load_state_dict(torch.load(PATH))새로운 net(모델)을 생성(초기화)하고,
초기화 한 net을 CUDA 장치로 옮긴다.
device는 GPU가 가능하면 CUDA이고,
그렇지 않다면 CPU가 들어가게된다.

코드를 실행시키면 CUDA 안에 빈 모델을 넣은다음
그 빈 모델안에 10회 학습한 모델을 넣었다는 것에대한
결과를 받았다.
불러온 모델 테스트 하기 전 작업
새로 불러온 모델로 testset 데이터셋을 분석하기 전에
기존에 있던 testset을 불러오자
내 모델로 예측한 결과가 맞는지 비교 대상군이 필요하니까
# 하나의 미니 배치 로드
dataiter = iter(testloader)
images, labels = next(dataiter)
# torchvision의 utils.make_grid()를 사용하여 이미지 표시
imshow(torchvision.utils.make_grid(images))
print('정답: ', ''.join('%1s' % labels[j].numpy() for j in range(128))) 
정답: 72104149590690159734966540740131347271211742351244635560419578937464307029173297762784736136931417696054992194873974449254767905예측 시작
## 하나의 미니 배치를 순전파하고 예측된 출력을 얻습니다
# Python 함수 iter를 사용하여 train_loader 객체에 대한 이터레이터를 반환합니다
test_iter = iter(testloader)
# next를 사용하여 이터레이터에서 첫 번째 배치 데이터를 가져옵니다
images, labels = next(test_iter)
# 데이터를 GPU로 이동합니다
images = images.to(device)
labels = labels.to(device)
# 모델을 사용하여 순전파를 수행합니다
outputs = net(images)
# torch.max를 사용하여 클래스 예측을 얻습니다
_, predicted = torch.max(outputs, 1)
# 128개의 예측값을 출력합니다
print('예측값: ', ''.join('%1s' % predicted[j].cpu().numpy() for j in range(128)))예측값: 72104149590690159734966540740131347271211742351244635560419578937464307029173297762784736136931417696054992194873979449254767905

두개의 출력을 비교했을때 현재는 완벽하게 예측해냈다.
그런데 예측하는 양이 엄청나게 많아진다면
아마도 예측이 틀리는 경우가 발생할 것이다.
나의 모델의 정확도는 98 퍼센트 정도이니까
정확도 계산 예제
correct = 0
total = 0
with torch.no_grad(): # 그래디언트를 계산하지 않음 (메모리 절약을 위해)
for data in testloader:
images, labels = data
# 데이터를 GPU로 이동합니다
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'10000개의 테스트 이미지에 대한 네트워크의 정확도: {accuracy:.3}%')
모델의 정확도를 계산하는 예제이다.
(predicted == labels).sum().item()이 부분이 예측을 하는 부분으로
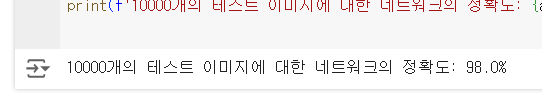
98 퍼센트가 나온것으로 보아 출력의 신뢰도가 높다고 볼 수 있다.
