6. 모델 학습(Training Model)
batch_size = 128
epochs = 25
history = model.fit(x_train,
y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = (x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
알고 갈 것
다른건 PyTorch와 같은데,
validation_data = (x_test, y_test)부분을 확인하고 넘어가야한다.
검증 데이터 세트 (x_test, y_test):로
validation_data: 검증 데이터와 레이블로, 각 에포크가 끝날 때마다 검증 성능을 평가한다.
그러니까 각 에포크 마다 학습이 끝나면 그 모델로 바로 테스트 데이터 세트를 예측해서
실제 어떤 값이 나오는지 확인하는 과정이 추가됐다.
보이는 사실
겁나짧다, PyTorch로 구현한 코드보다 3배는 짧다.

학습하는데 총 2분이 걸렸다.
7분이 걸린 PyTorch 모델과 많은 차이가 난다.

학습 로그도 되게 깔끔하고 직관적으로 표현을 잘 해놨다.
Keras를 이용해서 모델을 학습을 하니까 많은 시간이 절약되고 라이브러리가 사용자에게 친절하다.
PyTorch로 구현한 CNN 모델 트레이닝 코드
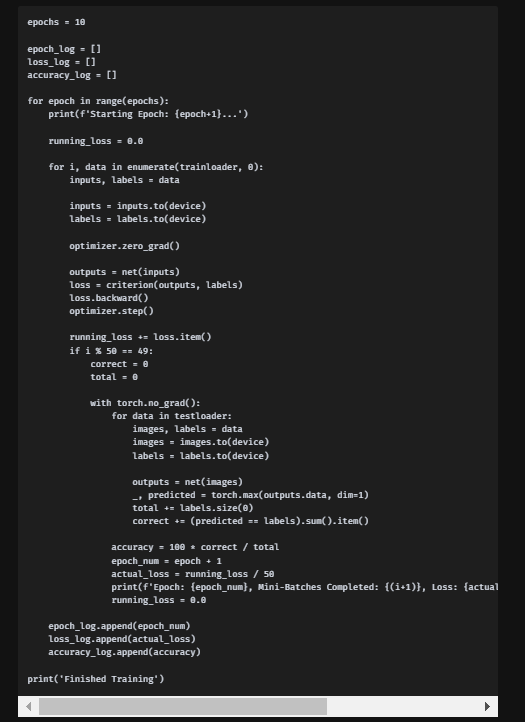
저번에 구현한 코드며 7분이 걸렸다.
이곳의 에포치는 10으로 keras의 25와 2.5배 차이가 나는데
속도는 Keras가 3배 넘게 빠르다
Keras의 모델 정확도는 25회 학습에 95%
PyTorch의 모델 정확도는 10회 학습에 97%
이걸 보니 누가 더 좋고 나쁘다가아니라
해야할 일의 목적에 따라 선택하면 될 것 같다.
정확도가 중요한 프로젝트에서는 PyTorch를
정확도 말고 빠르게 검증해야하는 프로젝트라면 Keras를 사용하는것이 좋아보인다.
7. 로그 차트 확인
손실차트
# 손실 차트를 시각화합니다
import matplotlib.pyplot as plt
# 학습 중 저장된 성능 결과를 가져오기 위해 History 객체를 사용합니다
history_dict = history.history
# 손실 값과 검증 손실 값을 추출합니다
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
# 에포크 수를 가져와서 해당 수만큼의 배열을 생성합니다
epochs = range(1, len(loss_values) + 1)
# 검증 손실과 학습 손실에 대한 라인 차트를 그립니다
line1 = plt.plot(epochs, val_loss_values, label='Validation/Test Loss')
line2 = plt.plot(epochs, loss_values, label='Training Loss')
plt.setp(line1, linewidth=2.0, marker = '+', markersize=10.0) # 첫 번째 라인 설정
plt.setp(line2, linewidth=2.0, marker = '4', markersize=10.0) # 두 번째 라인 설정
plt.xlabel('Epochs') # x축 레이블 설정
plt.ylabel('Loss') # y축 레이블 설정
plt.grid(True) # 그리드 설정
plt.legend() # 범례 설정
plt.show() # 차트 출력
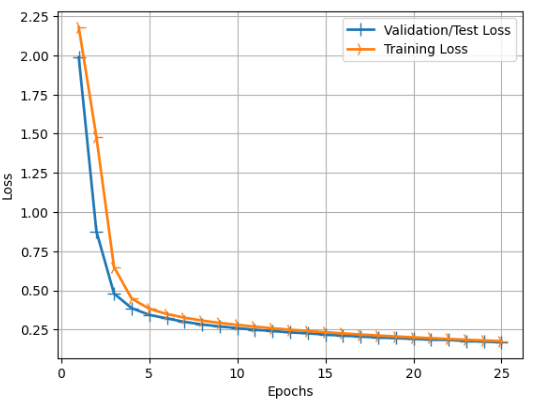
주황색은 학습을 하면서 계산했던 예상 손실(loss)값
파란색은 x_train 학습 한 모델을 테스트 데이터 세트에 바로 예측해서 나온 값이다.
대체로 파란색이더 작은 값을 보이며
이는 학습할때 발생한 손실보다 바로 검증한 로스값이 적다는 뜻이다.
정확도 차트
# 정확도 차트를 시각화합니다
import matplotlib.pyplot as plt
# 학습 중 저장된 성능 결과를 가져오기 위해 History 객체를 사용합니다
history_dict = history.history
# 정확도 값과 검증 정확도 값을 추출합니다
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
epochs = range(1, len(loss_values) + 1)
# 검증 정확도와 학습 정확도에 대한 라인 차트를 그립니다
line1 = plt.plot(epochs, val_acc_values, label='Validation/Test Accuracy')
line2 = plt.plot(epochs, acc_values, label='Training Accuracy')
plt.setp(line1, linewidth=2.0, marker = '+', markersize=10.0) # 첫 번째 라인 설정
plt.setp(line2, linewidth=2.0, marker = '4', markersize=10.0) # 두 번째 라인 설정
plt.xlabel('Epochs') # x축 레이블 설정
plt.ylabel('Accuracy') # y축 레이블 설정
plt.grid(True) # 그리드 설정
plt.legend() # 범례 설정
plt.show() # 차트 출력
손실 차트와 똑같이 파란색 선이 좋은 성능을 내고있다.
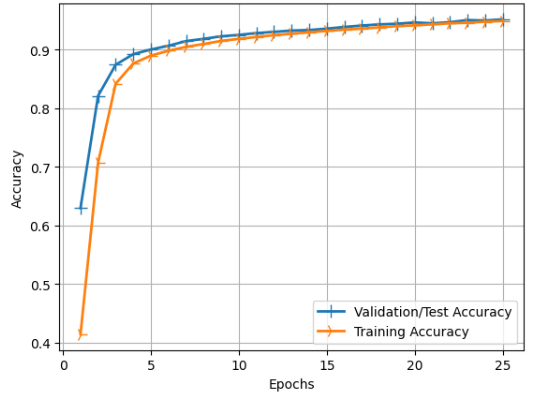
왜 검증치가 더 높게 나왔는가에 대해서는
셔플링으로 인해 학습 모델과 테스트 데이터 세트의 궁합이 잘 맞았다고 보는게 맞는것 같다.
8. 모델 저장 및 로드
저장
model.save("mnist_simple_cnn_10_Epochs.h5")
print("Model Saved")
로드
# We need to import our load_model function
from tensorflow.keras.models import load_model
classifier = load_model('mnist_simple_cnn_10_Epochs.h5')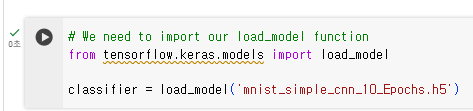
체크 표시 뜨면 이상없이 로드 된 것이다.
9.샘플 테스트 데이터에서 예측 가져오기
그럼 이 모델이 동작을 잘 하는지 테스트 하기전에 테스트 데이터셋에서 샘플을 가져오자.
#x_test = x_test.reshape(10000,28,28,1)
print(x_test.shape)
print("Predicting classes for all 10,000 test images...")
pred = np.argmax(classifier.predict(x_test), axis=-1)
print("Completed.\n")
print(pred)
print(type(pred))
print(len(pred))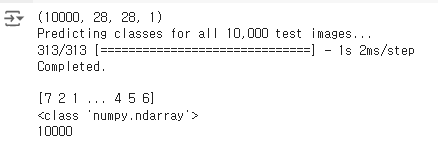
print(x_test.shape)는 테스트 데이터 셋은 1000개의 28x28이니 맞다
10000개를 테스트 했을때
print(pred) 이미지를 보고 예측한 값이다.
생략이 돼있지만
len(pred)로 10000개 인것을 확인 가능하다.
검증
# x_test의 첫 번째 이미지(인덱스 0)를 가져와서 그 형태를 출력합니다
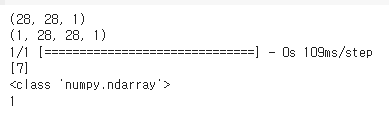
input_im = x_test[0]
print(input_im.shape)
# 첫 번째 축에 4번째 차원을 추가해야 합니다
input_im = input_im.reshape(1, 28, 28, 1)
print(input_im.shape)
# 이제 해당 단일 이미지에 대한 예측을 얻습니다
pred = np.argmax(classifier.predict(input_im), axis=-1)
print(pred)
print(type(pred))
print(len(pred))
x_test의 첫 번째 이미지라 하면

방금 위에서 봤던 7이다.
근데 봤던 7은 이미지 7이 아닌 모델로 예측한 7이다.
그냥 하나만 따로 뽑아서 맞는지 확인하는 과정이다.
x_test[0] 은 7이고
예측결과 7로 예측을 하였으며
길이는 1로
논리적으로 봐도 맞다.
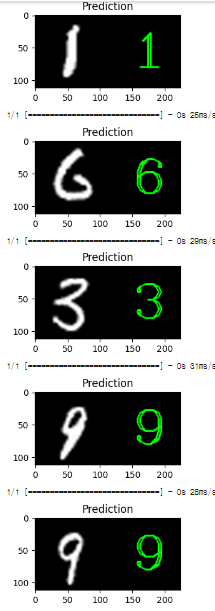
원본 이미지 옆에 예측된 클래스를 표시하는 예제
import cv2
import np
# 데이터를 다시 로드합니다 (이전에 스케일을 조정했기 때문에 다시 로드)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
def draw_test(name, pred, input_im):
'''원본 이미지 옆에 예측된 클래스를 표시하는 함수'''
# 검정색 배경을 만듭니다
BLACK = [0,0,0]
# 예측된 클래스 텍스트를 배치할 공간을 만들기 위해 원본 이미지를 오른쪽으로 확장합니다
expanded_image = cv2.copyMakeBorder(input_im, 0, 0, 0, imageL.shape[0], cv2.BORDER_CONSTANT, value=BLACK)
# 그레이스케일 이미지를 컬러로 변환합니다
expanded_image = cv2.cvtColor(expanded_image, cv2.COLOR_GRAY2BGR)
# 확장된 이미지에 예측된 클래스 텍스트를 넣습니다
cv2.putText(expanded_image, str(pred), (150, 80), cv2.FONT_HERSHEY_COMPLEX_SMALL, 4, (0,255,0), 2)
imshow(name, expanded_image)
for i in range(0, 10):
# 테스트 데이터셋에서 무작위로 이미지를 가져옵니다
rand = np.random.randint(0, len(x_test))
input_im = x_test[rand]
# 텍스트를 넣을 수 있도록 더 큰 크기로 이미지 크기를 조정합니다
imageL = cv2.resize(input_im, None, fx=4, fy=4, interpolation=cv2.INTER_CUBIC)
# 데이터를 reshape하여 네트워크에 입력할 수 있도록 합니다 (forward propagate)
input_im = input_im.reshape(1, 28, 28, 1)
# 예측을 얻습니다. numpy 배열에 저장된 값을 접근하기 위해 [0]을 사용합니다
res = str(np.argmax(classifier.predict(input_im), axis=-1)[0])
# 테스트 데이터 샘플 이미지에 레이블을 붙입니다
draw_test("Prediction", res, np.uint8(imageL))
10 개를 랜덤으로 뽑아 모델로 예측하고 예측한 결과 값을 확장시킨 이미지의 검은 부분에
입력해주는 예제이다.