1. Keras 모델 및 데이터 로드
사용하기 쉽게 다운로드 하기 위해,
저번에 Keras로 MNIST를 학습해 만든 모델을 구글 드라이브에 올렸다.
모델 로드
10회의 에포크를 가진 CNN 모델이 다운로드 됐다.

해당 파일을 모델로 로드
from tensorflow.keras.models import load_model
model = load_model('mnist_simple_cnn_10_Epochs.h5')MNIST 데이터셋 로드
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()두 종류를 다운로드 했는데
train 셋과 test 셋이다.
x_train 에는 학습할 이미지가 담겨있고,
y_train 에는 학습할 이미지의 라벨값이 담겨있다.
이어서 test 데이터셋은 train 데이터셋으로 학습한 모델을 가지고
예측을 하기위한 검증/ 테스트 데이터 셋이다.
2. 잘못 분류한 이미지 보기
예측
import numpy as np
# Keras 가 필요한 정보로 reshape
print(x_test.shape)
x_test = x_test.reshape(10000,28,28,1)
print(x_test.shape)
# test 데이터 셋의 10000개의 이미지를 예측
print("Predicting classes for all 10,000 test images...")
pred = np.argmax(model.predict(x_test), axis=-1)
print("Completed.\n")
Keras를 위해 차원이 하나 추가된 모습과,
10000개의 테스트 데이터셋을 예측했다.
잘못된 예측시 저장
import cv2
import numpy as np
# numpy를 사용하여 잘못된 분류가 발생했을 때 1의 값을 저장하는 배열을 만듭니다
result = np.absolute(y_test - pred)
misclassified_indices = np.nonzero(result > 0)
# 오분류의 지수를 표시
print(f"Indices of misclassifed data are: \n{misclassified_indices}")
print(len(misclassified_indices[0]))result 부분에서 y_test - pred를 하는데,
pred는 x_test(이미지) 를 예측하고, 라벨과 같이
숫자 데이터 값으로 저장된 값이고,
y_test는 애초에 테스트 데이터셋의 데이터 라벨값이다.
그렇다면 데이터 라벨값은 정확한 값이고,
pred는 예측한 값이며 잘못된 예측값이 있을 수 있다.
올바르게 예측을 했다면 아래 result의 값은 0이 돼야 한다.
result = np.absolute(y_test - pred)
result가 0이 아닐때, 절대값을 씌워 하나의 경우로 오분류를 걸러내준다.
misclassified_indices = np.nonzero(result > 0)
np.nonzero 는 조건이 True인 인덱스를 반환한다.
즉 오분류된 이미지의 인덱스를 반환
여기서의 인덱스는 틀린 데이터가 몇번째인지를 나타낸다.

1~10000 인덱스의 이미지를 예측해서
총 506개의 예측이 틀렸다.
95% 정도의 신뢰도를 가진 모델이라는 뜻이다(검증 신뢰도 = 97%)
모델이 잘못 분류된 이미지 시각화
이미지 출력 함수
import cv2
import numpy as np
from matplotlib import pyplot as plt
def imshow(title="", image = None, size = 6):
if image.any():
w, h = image.shape[0], image.shape[1]
aspect_ratio = w/h
plt.figure(figsize=(size * aspect_ratio,size))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(title)
plt.show()
else:
print("Image not found")이미지 시각화
import cv2
import numpy as np
# 데이터 다시 로드 (이전에 리스케일했으므로)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
def draw_test(name, pred, input_im):
'''예측된 클래스를 원본 이미지 옆에 배치하는 함수'''
# 검정색 배경 생성
BLACK = [0,0,0]
# 원본 이미지를 오른쪽으로 확장하여 예측된 클래스 텍스트를 배치할 공간 생성
expanded_image = cv2.copyMakeBorder(input_im, 0, 0, 0, imageL.shape[0] ,cv2.BORDER_CONSTANT, value=BLACK)
# 그레이스케일 이미지를 컬러로 변환
expanded_image = cv2.cvtColor(expanded_image, cv2.COLOR_GRAY2BGR)
# 확장된 이미지에 예측된 클래스 텍스트 배치
cv2.putText(expanded_image, str(pred), (150, 80), cv2.FONT_HERSHEY_COMPLEX_SMALL, 4, (0,255,0), 2)
imshow(name, expanded_image)
for i in range(0, 10):
# 테스트 데이터셋에서 무작위 이미지 가져오기
input_im = x_test[misclassified_indices[0][i]]
# 텍스트를 배치하고 더 큰 디스플레이를 위해 이미지를 크게 리사이즈
imageL = cv2.resize(input_im, None, fx=4, fy=4, interpolation=cv2.INTER_CUBIC)
# 데이터를 재형성하여 네트워크에 입력 (전방 전파)할 수 있도록 함
input_im = input_im.reshape(1, 28, 28, 1)
# 예측값 가져오기, numpy 배열에 값이 배열로 저장되므로 [0]을 사용하여 값에 접근
res = str(np.argmax(model.predict(input_im), axis=-1)[0])
# 테스트 데이터 샘플 이미지에 레이블 배치
draw_test("Misclassified Prediction", res, np.uint8(imageL))
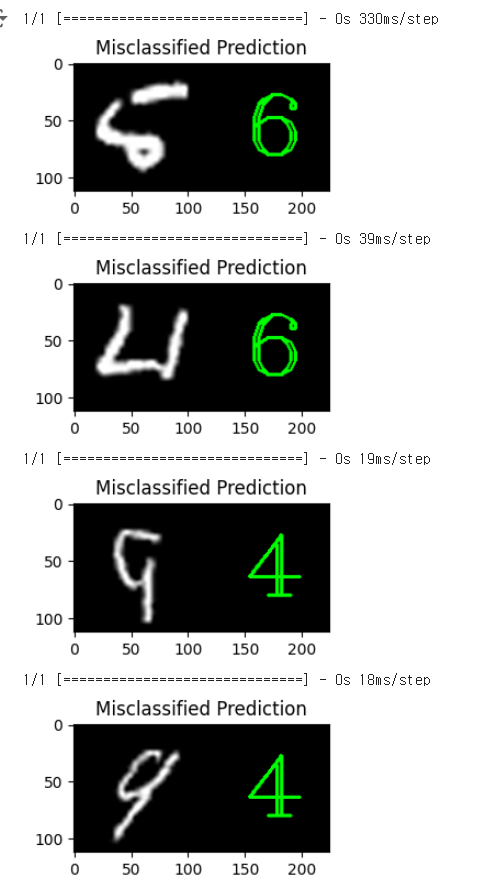
draw_test는 이미지를 늘려서 텍스트를 배치하는 함수이고,
test 데이터셋에서 10개의 데이터를 가져왔다.
임의의 10개는 아래와 같이 표현했는데,
misclassified_indices는 아래와 같은 구조를 갖는다.
(array([...]),)
misclassified_indices[0][i]는
잘못 분류된 이미지의 인덱스 배열[0] 의 i번째 요소를 의미한다.
다른 방식으로 표현
5x5 격자 형태의 플롯을 만들어, 잘못 분류된 이미지들을 시각화하고, 각 이미지에 대해 모델의 예측값과 실제 레이블을 함께 표시

import matplotlib.pyplot as plt
import numpy as np
# 그리드의 행과 열 설정
L = 5
W = 5
# 5x5 서브플롯 생성
fig, axes = plt.subplots(L, W, figsize=(12, 12))
axes = axes.ravel() # 다차원 배열을 1차원으로 평탄화
for i in np.arange(0, L * W):
# 오분류된 이미지의 인덱스 가져오기
input_im = x_test[misclassified_indices[0][i]]
ind = misclassified_indices[0][i]
# 모델의 예측값 가져오기
predicted_class = str(np.argmax(model.predict(input_im.reshape(1, 28, 28, 1)), axis=-1)[0])
# 이미지를 그리드에 그리기
axes[i].imshow(input_im.reshape(28, 28), cmap='gray_r')
# 타이틀에 예측값과 실제 레이블 표시
axes[i].set_title(f"Prediction Class = {predicted_class}\n Original Class = {y_test[ind]}")
# 축 숨기기
axes[i].axis('off')
# 서브플롯 간 간격 조정
plt.subplots_adjust(wspace=0.5)
plt.show()
Confusion Matrix 생성
Confusion Matrix를 생성하기 위해서는
진짜 라벨(y_test)과 예측 라벨이 필요하다
from sklearn.metrics import confusion_matrix
import numpy as np
x_test = x_test.reshape(10000,28,28,1)
#모델 예측
y_pred = np.argmax(model.predict(x_test), axis=-1)
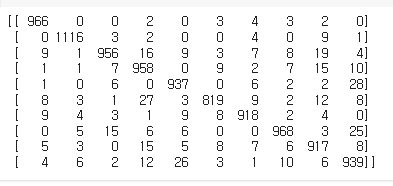
print(confusion_matrix(y_test, y_pred))테스트 데이터에 대한 예측값(확률)을 반환하여
y_pred에 담고 y_test와 함께 출력
해석

저번에 말했듯 대각선은 예측이 잘 된것이고,
나머지 값들은 예측이 틀렸다는 뜻인데,
동그라미 친 부분들은 특히 많이 틀린 부분들이다
Confusion Matrix 시각화

import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import itertools
def plot_confusion_matrix(cm, target_names, title='Confusion matrix', cmap=None, normalize=True):
accuracy = np.trace(cm) / np.sum(cm).astype('float')
misclass = 1 - accuracy
if cmap is None:
cmap = plt.get_cmap('Blues')
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
if target_names is not None:
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 1.5 if normalize else cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
if normalize:
plt.text(j, i, "{:0.4f}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
else:
plt.text(j, i, "{:,}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label\naccuracy={:0.4f}; misclass={:0.4f}'.format(accuracy, misclass))
plt.show()
# 클래스 이름 리스트 생성
target_names = list(range(0, 10))
# 혼동 행렬 생성
conf_mat = confusion_matrix(y_test, y_pred)
# 혼동 행렬 시각화
plot_confusion_matrix(conf_mat, target_names)클래스당 정확도
같은 모델로 10번의 테스트를 해봤을때 각각의 정확도를 확인

class_accuracy = 100 * conf_mat.diagonal() / conf_mat.sum(1)
for (i,ca) in enumerate(class_accuracy):
print(f'Accuracy for {i} : {ca:.3f}%')4. 분류 보고서 생성
classification_report 함수를 사용해 수치 확인
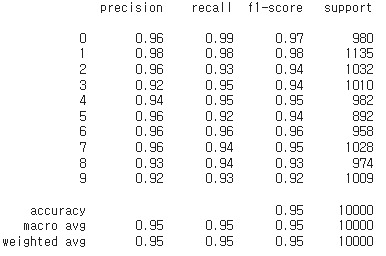
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))왼쪽에 0~9는 테스트데이터셋의 숫자

Precision (정밀도): 모델이 특정 클래스로 예측한 샘플 중 실제로 해당 클래스인 비율.
Recall (재현율): 실제 클래스 중에서 모델이 올바르게 예측한 비율.
F1-Score: 정밀도와 재현율의 조화 평균
Support (지원): 각 클래스의 실제 샘플 수
마지막 3 줄은 각 값의 평균이다.
정밀도, 재현율 둘다 0.9가 넘어가서 높은 정확도를 가진 모델이라는 것을 확인할 수 있고,
둘의 관계값인 F1-Score도 0.9가 넘는것으로 보인다.
4.1 Recall 리뷰
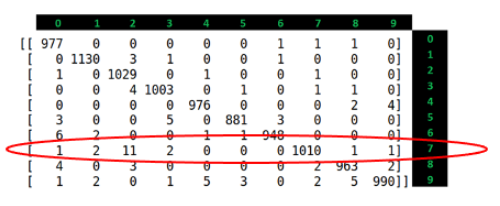
TP(참 긍정, True Positive) = 1010
FN(거짓 부정, False Negative) = 18
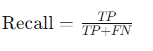
Recall 을 계산하면 약 98.24%가 나온다.
4.2 Precision 리뷰

숫자 7의 정밀도
TP(참 긍정, True Positive) = 1010
FP(거짓 긍정, False Positive) = 7
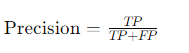
precision을 계산하면 약 99.31%가 나온다
4.3 Recall & Precision의 관계
Recall이 높은 경우:
대부분의 실제 긍정 샘플을 올바르게 인식하지만, 거짓 긍정(FP)이 많을 수 있다.
Precision이 높은 경우
모델이 긍정으로 예측한 샘플 대부분이 실제 긍정이지만, 실제 긍정을 놓칠 가능성(FN)이 있다.
해석
높은 Recall이, 낮은 Precision:
대부분의 긍정 예제가 올바르게 인식되지만, 다른 클래스가 잘못 긍정으로 예측될 가능성이 높음.
낮은 Recall이, 높은 Precision:
모델이 많은 긍정 예제를 놓치지만, 예측된 긍정 예제는 대부분 정확함.
결론
모델의 성능을 더 개선하려면 전체적인 Confuse Matrix를 분석하여 각 클래스(0~9 숫자)에 대한 FP와 FN을 줄이는 방법을 고려해야한다.