Keras를 이용해서 정규화가 있고 없고의 학습데이터 결과를 확인했다.
이번에는 PyTorch로 학습하여 확인한다.
1. 사전 준비(라이브러리, 함수 정의, 데이터셋)
라이브러리
import torch
import PIL
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import torch.nn as nn
print("GPU available: {}".format(torch.cuda.is_available()))
device = 'cuda' #'cpu' if no GPU available
정규화
# PyTorch 텐서로 변환하고 값을 -1과 +1 사이로 정규화합니다.
transform = transforms.Compose([
transforms.ToTensor(), # 데이터를 PyTorch 텐서로 변환
transforms.Normalize((0.5, ), (0.5, )) # 평균 0.5와 표준편차 0.5를 사용하여 정규화
])
정규화는 학습속도와 안정성을 늘리기 위한 작업이다.
데이터셋 다운로드
trainset = torchvision.datasets.FashionMNIST(root='./data', train=True,
download=True, transform=transform)
testset = torchvision.datasets.FashionMNIST(root='./data', train=False,
download=True, transform=transform)train 데이터셋이랑 test 데이터 셋을 다운로드해준다.
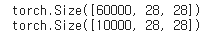
# 훈련 데이터와 테스트 데이터를 위한 데이터 로더 준비
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32,
shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=32,
shuffle=False, num_workers=2)
# 클래스 이름을 포함한 리스트 생성
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress',
'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot')
# 훈련 데이터로 60,000개의 이미지 샘플과 테스트 데이터로 10,000개의 이미지 샘플을 사용
# 각 이미지는 28 x 28 픽셀로 구성되어 있으며, 그레이스케일 이미지이기 때문에 3차원은 없습니다.
print(trainset.data.shape)
print(testset.data.shape)
데이터는 60000, 10000개씩 28x28 크기의 그레이스케일 이미지
시각화

import matplotlib.pyplot as plt
import numpy as np
# 이미지를 표시하는 함수
def imshow(img):
img = img / 2 + 0.5 # 정규화 해제
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0))) # 이미지 배열의 축을 변환하여 표시
plt.show()
# 일부 랜덤 훈련 이미지 가져오기
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 이미지 표시
imshow(torchvision.utils.make_grid(images))
# 레이블 출력
print(' '.join('%5s' % classes[labels[j]] for j in range(8)))

2. 정규화 없이 간단한 CNN 구축 및 Training
모델 정의
import torch.nn as nn
import torch.nn.functional as F
# 신경망 클래스 정의
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 첫 번째 컨볼루션 층: 입력 채널 1, 출력 채널 32, 커널 크기 3x3
self.conv1 = nn.Conv2d(1, 32, 3)
# 두 번째 컨볼루션 층: 입력 채널 32, 출력 채널 64, 커널 크기 3x3
self.conv2 = nn.Conv2d(32, 64, 3)
# 최대 풀링 층: 커널 크기 2x2
self.pool = nn.MaxPool2d(2, 2)
# 첫 번째 완전 연결 층: 입력 크기 64 * 12 * 12, 출력 크기 128
self.fc1 = nn.Linear(64 * 12 * 12, 128)
# 두 번째 완전 연결 층: 입력 크기 128, 출력 크기 10 (클래스 개수)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 첫 번째 컨볼루션 층과 ReLU 활성화 함수 적용
x = F.relu(self.conv1(x))
# 두 번째 컨볼루션 층과 ReLU 활성화 함수, 최대 풀링 층 적용
x = self.pool(F.relu(self.conv2(x)))
# 특성 맵을 일렬로 펼침 (Flatten)
x = x.view(-1, 64 * 12 * 12)
# 첫 번째 완전 연결 층과 ReLU 활성화 함수 적용
x = F.relu(self.fc1(x))
# 두 번째 완전 연결 층 적용 (출력)
x = self.fc2(x)
return x
# 신경망 인스턴스 생성 및 장치로 이동 (GPU 또는 CPU)
net = Net()
net.to(device)
손실 및 최적화 기능 정의
손실 함수는 모델의 예측과 실제 값 사이의 차이를 측정하고
옵티마이저는 이 손실을 줄이기 위해 모델의 매개변수를 조정
# 옵티마이저 함수 불러오기
import torch.optim as optim
# 교차 엔트로피 손실 함수를 손실 함수로 사용
criterion = nn.CrossEntropyLoss()
# 경사 하강법 알고리즘 또는 옵티마이저 설정
# 학습률 0.001로 설정된 확률적 경사 하강법(SGD)을 사용
# 모멘텀(momentum)을 0.9로 설정
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
3. Training Model
# 훈련 데이터셋을 여러 번 반복 (각 반복은 에폭(epoch)이라고 함)
epochs = 15
# 로그를 저장할 빈 배열 생성
epoch_log = []
loss_log = []
accuracy_log = []
# 지정된 에폭 수 만큼 반복
for epoch in range(epochs):
print(f'Starting Epoch: {epoch+1}...')
# 각 미니 배치 후 손실을 누적하여 저장
running_loss = 0.0
# trainloader 이터레이터를 통해 반복
# 각 사이클은 미니 배치
for i, data in enumerate(trainloader, 0):
# 입력과 레이블 가져오기; data는 [inputs, labels] 리스트
inputs, labels = data
# 데이터를 GPU로 이동
inputs = inputs.to(device)
labels = labels.to(device)
# 학습 전 기울기 초기화 (0으로 설정)
optimizer.zero_grad()
# 순전파 -> 역전파 + 최적화
outputs = net(inputs) # 순전파
loss = criterion(outputs, labels) # 손실 계산 (예측 결과와 실제 값의 차이)
loss.backward() # 역전파를 통해 모든 노드의 새로운 기울기 계산
optimizer.step() # 기울기/가중치 업데이트
# 학습 통계 출력 - 에폭/반복/손실/정확도
running_loss += loss.item()
if i % 100 == 99: # 100 미니 배치마다 손실 출력
correct = 0 # 올바른 예측 개수를 저장할 변수 초기화
total = 0 # 반복된 레이블의 총 개수를 저장할 변수 초기화
# 검증 과정에서는 기울기가 필요 없으므로
# no_grad로 감싸서 메모리 절약
with torch.no_grad():
# testloader 이터레이터를 통해 반복
for data in testloader:
images, labels = data
# 데이터를 GPU로 이동
images = images.to(device)
labels = labels.to(device)
# 테스트 데이터 배치를 모델에 통과시키기 (순전파)
outputs = net(images)
# 최대값에서 예측값 가져오기
_, predicted = torch.max(outputs.data, 1)
# 총 레이블 개수를 total 변수에 계속 추가
total += labels.size(0)
# 올바르게 예측된 개수를 correct 변수에 계속 추가
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
epoch_num = epoch + 1
actual_loss = running_loss / 100
print(f'Epoch: {epoch_num}, Mini-Batches Completed: {(i+1)}, Loss: {actual_loss:.3f}, Test Accuracy = {accuracy:.3f}%')
running_loss = 0.0
# 각 에폭 후 학습 통계 저장
epoch_log.append(epoch_num)
loss_log.append(actual_loss)
accuracy_log.append(accuracy)
print('Finished Training')
100개 마다 손실 출력하고 에포크는 총 15회 진행
정확도 확인
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
# Move our data to GPU
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Accuracy of the network on the 10000 test images: {accuracy:.4}%')정확도가 Keras에 비해 소폭 높다

트레이닝 중 결과 시각화
fig, ax1 = plt.subplots()
plt.title("Accuracy & Loss vs Epoch Mini-Batches")
plt.xticks(rotation=45)
ax2 = ax1.twinx()
ax1.plot(epoch_log, loss_log, 'g-')
ax2.plot(epoch_log, accuracy_log, 'b-')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss', color='g')
ax2.set_ylabel('Test Accuracy', color='b')
plt.show()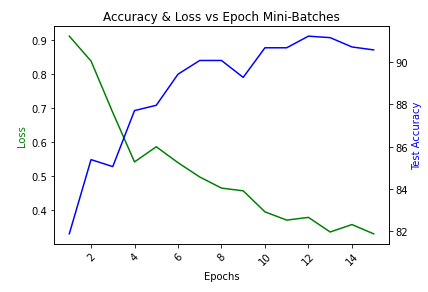
가중치(모델) 저장
PATH = './fashion_mnist_cnn_net.pth'
torch.save(net.state_dict(), PATH)
감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w