이번 내용은 각 네트워크들이 무엇을 해결하기 위해 개발됐는지를 확인하면서 넘어가자.
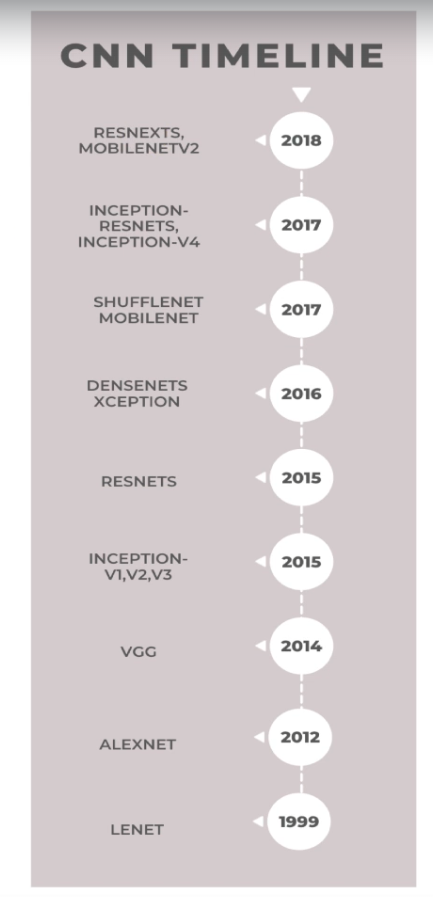
CNN(Convolutional Neural Networks)의 발전에 대한 타임라인
2018년 이후로는 주로 ResNet(Residual Networks)와 관련된 내용이 많으며, ResNet이 여전히 이미지 분류에서 세계적인 성능을 보이고 있기 때문
- LeNet: 초기의 클래식한 CNN 아키텍처.
- AlexNet: LeNet 이후 등장한 주요 네트워크.
- VGGNet: 2014년에 등장해 큰 반향을 일으킴.
- Inception: 더 복잡한 구조를 가지며, ResNet과 함께 현대적인 CNN의 기초를 다짐.
- DenseNet, ShuffleNet, MobileNet: 효율적인 모델로 모바일 장치에서의 활용에 중점을 둠.
- Inception-ResNet, EfficientNet: 더 발전된 네트워크 구조.
최근에는 Vision Transformers가 등장해 CNN 연구를 새롭게 발전시키고 있으며, 이는 2020년 말부터 2021년 초 사이에 큰 주목을 받았다고 한다.
1995 & LeNet
1995 LeCun 개발
LeNet 개발 이유

미국 우체국에서 손으로 쓴 글씨를 자동으로 읽는데, 정확한 글을 읽기 위해 나타난 방법이다.
LeNet의 아키텍처
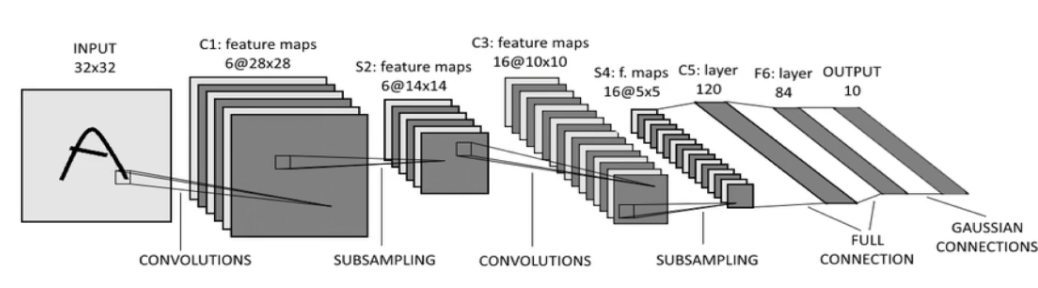
6개의 특징 맵(feature map) 필터 크기는 5x5
2번의 맥스 풀링(max pooling)
fully connected
등 여태 배웠던 기본적인 CNN과 다른 모습을 알 수 있다.
LeNet의 실제 데모
숫자가 이동하며 인식되는 방식이다.
1995년에 나온 기술인데 흥미롭다.


2012 & AlexNet
고급 CNN이며 최초의 CNN이 등장하고 나서 15~17년 뒤에서야 나왔다.
오랜시간이 걸린이유는 GPU 연산 능력이 부족했기 때문
AlexNet 아키텍처
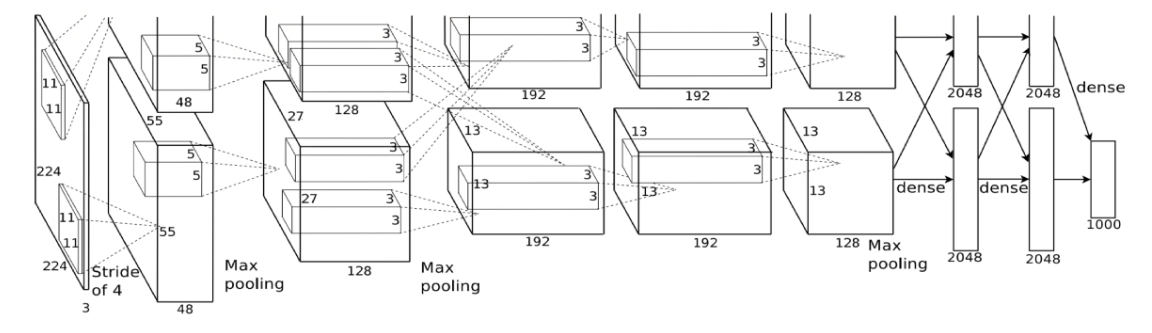
AlexNet의 아키텍처는 8개의 레이어로 구성
처음 5개는 컨볼루션 레이어이고
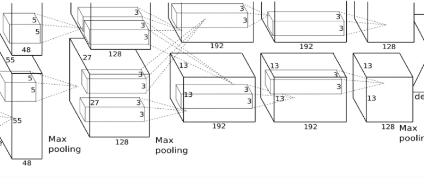
마지막 3개는 완전 연결된 레이어(FC)이다.

2014 & VGGNet
저번에 좀더 많은 레이어로 돼있는 VGGNet 16을 다운로드해서 테스트 데이터 셋을 예측했었는데, 그 모델이다.
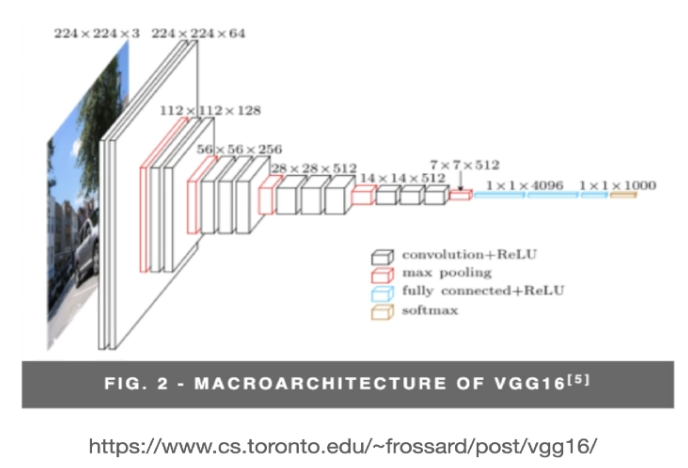
아키텍처

VGGNet은 16~18개의 컨볼루션 레이어와 3개의 완전 연결된 레이어로 구성되어 있다.
VGGNet-19는 16개의 컨볼루션 레이어와 3개
아키텍처 다이어그램
2014년에 발표된 VGGNet 논문에서 발췌한 아키텍처 다이어그램
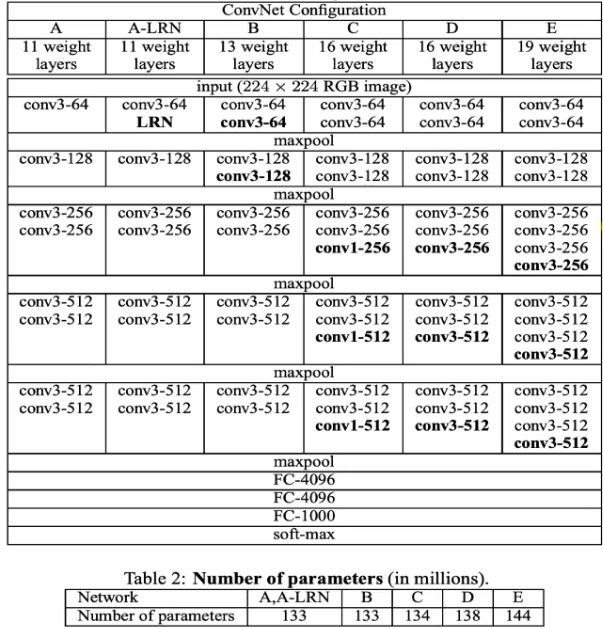
VGGNet-19는 144백만 개의 파라미터를 가지고 있다.
Number of parameters E
좋은 결과를 제공하지만, 훈련 시간이 매우 오래걸리고,
모델 크기도 크기 때문에 임베디드 시스템에서는 사용하기 어렵다.
ResNet
기존에 사용했던 클래식한 CNN

클래식한 CNN 아키텍처는 여러 층과 맥스 풀링 레이어
그리고 마지막에 완전 연결된 레이어로 구성된 직렬적인 구조
여태 배웠던 내용이다.
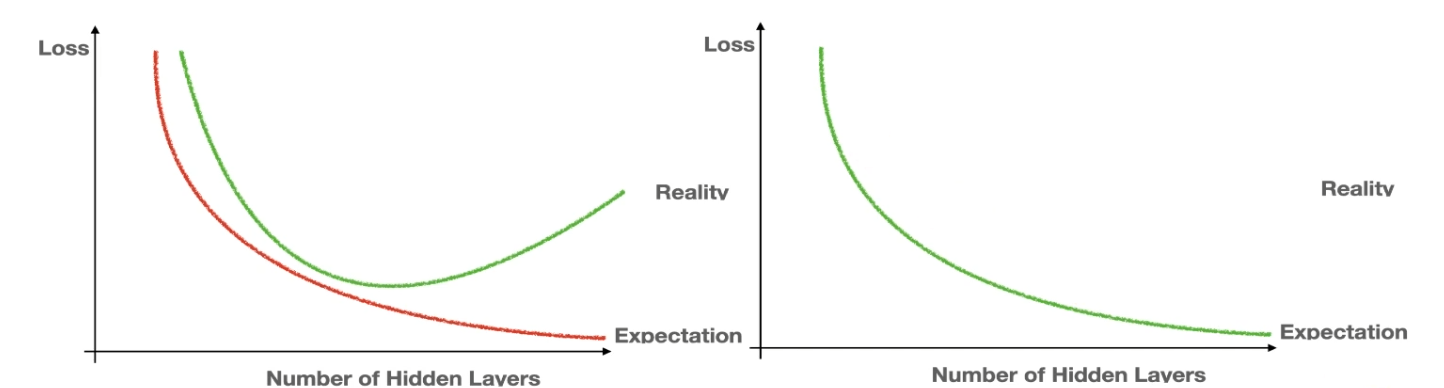
이런 구조에서 발생할 수 있는 문제로는 층의 수가 많아질수록 성능이 저하되는 문제가 발생할 수 있다.
과적합(overfitting)과 일반화(generalization)
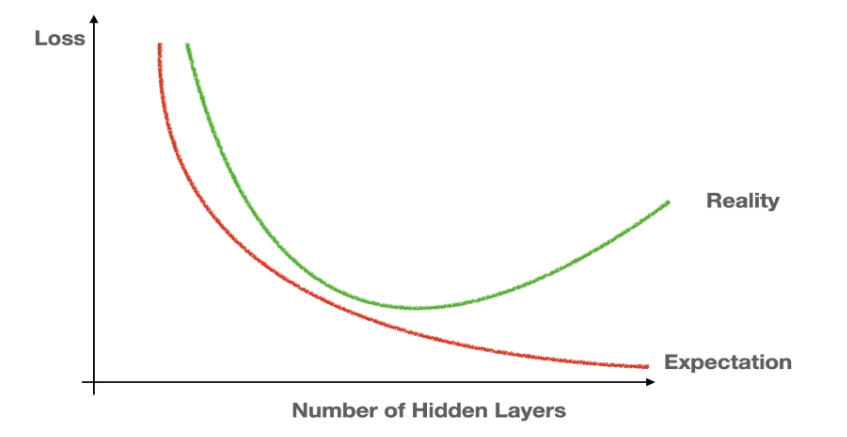
층이 많아질수록 > 훈련을 필요이상 계속하면
깊은 CNN에서는 많은 층이 있고, 각 층에서 기울기를 계산하기 위해 곱셈이 필요하다.
층이 많아지면 곱셈이 많아지며, 기울기가 너무 크면 폭발하고, 너무 작으면 소멸하게 되는데,
이 문제를 해결하기 위해 ResNet이 나오게 됐다.
기존 기울기 소멸 문제 해결 방식
기본 CNN의 직렬적인 연산 구조에 더해,

첫 번째 층으로 들어가는 입력을 두 번째 컨볼루션 레이어로 직접 연결

이렇게 하면 두 번째 컨볼루션 레이어는 이전 층의 출력뿐만 아니라 첫 번째 층의 입력도 함께 받게 된다.
이 구조는 기울기 소멸 문제를 해결
첫 번째 층의 출력 값이 너무 작아지면 사라질 수 있지만, 첫 번째 층의 입력이 두 번째 층으로 직접 전달되므로 기울기가 소멸하지 않게 된다.

ResNet은 이러한 레이어를 여러 개 쌓아 매우 깊은 특징을 학습할 수 있게하는것을 목표로 개발된것
수학적 관점
어떻게 기울기 소실 문제를 해결하는 수학적 원리
전형적인 CNN의 구조는 선형 연산의 연속이다.


단락 연결(short-circuit) O
아래는 출력이 가중치 W와 입력 a의 곱에 바이어스 B를 더한 부분으로,
기본적인 선형 연산이다.
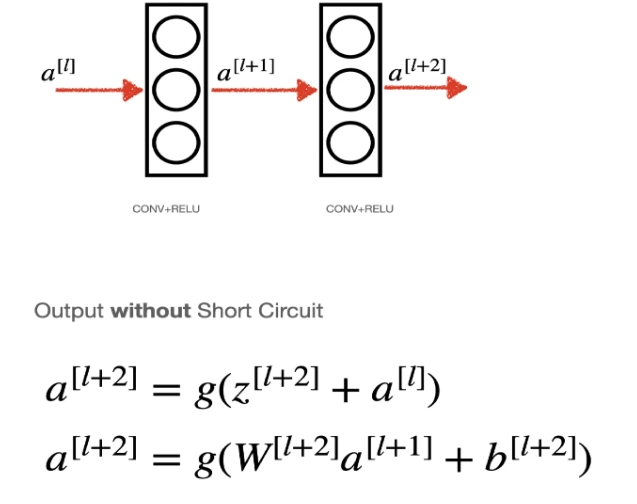
단락 연결(short-circuit) X

여기서 봐야할 부분은 Zl+2의 출력은 이전 층의 출력과 초기 입력값을 합한것
이 구조는 만약
𝑊 또는 바이어스가 0에 가까운 작은 값이라도 출력이 0이 되지 않도록 해준다.
MobileNetV1 & V2
모바일 장치 및 임베디드 디바이스에서 매우 유용한 네트워크인
MobileNet에 대해 알아보자.
위의 ResNet은 성능 중심이였다면, MobileNet은 효율 중심
이 네트워크는 주로 휴대폰과 임베디드 디바이스에서 효율적이고 가벼운 CNN으로 설계되었다.
전통적인 CNN은 매우 깊고 많은 파라미터를 가지며, 그 크기 때문에 모바일 장치에서는 비실용적일 수 있다.
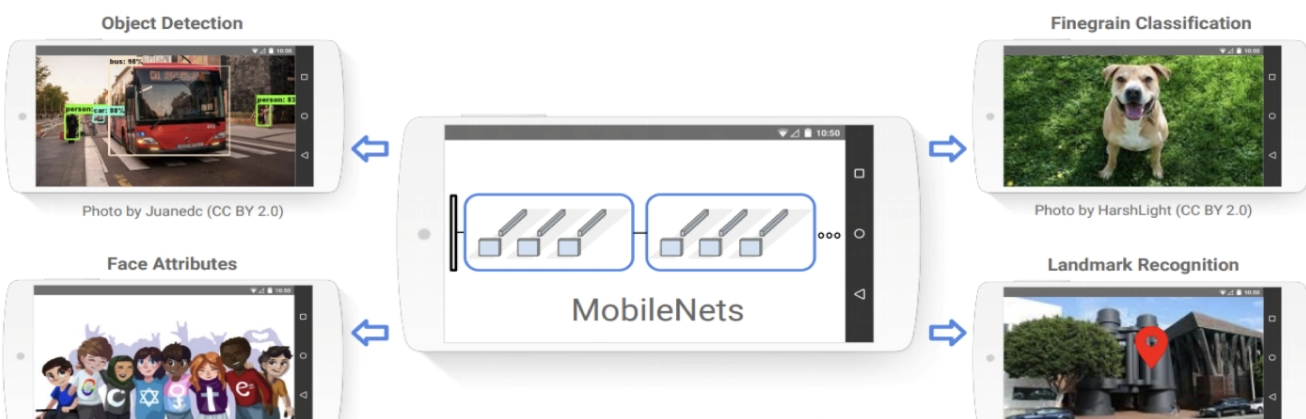
주로 객체 탐지, 얼굴 속성 인식, 세밀한 분류, 랜드마크 인식 등의 용도로 사용
CNN이 임베디드 디바이스에서 제대로 작동하려면 효율적이어야 한다.
MobileNet은 두 가지 주요 기술을 사용하여 성능을 높였다.
1. 깊이별 분리 합성곱(depthwise separable convolutions)
깊이별 분리 합성곱은 전통적인 합성곱 연산을 분리하여 연산량을 줄이는 방법


예를 들어, 일반적인 합성곱에서는 5x5x3 커널을 사용하지만, 깊이별 분리 합성곱에서는 각 채널별로 별도의 필터를 사용하여 연산량을 크게 줄일 수 있다.
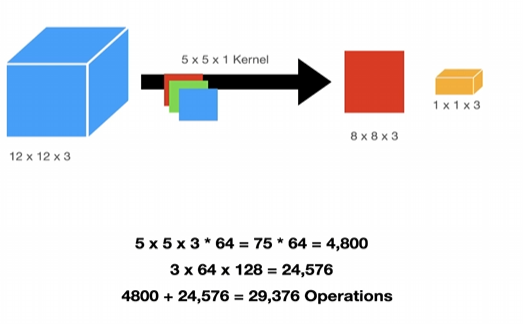
614,400 > 29,376 엄청나게 차이난다.
2. 이미지 크기와 네트워크 폭을 조절하는 두 가지 하이퍼파라미터
1. Width Multiplier (폭 조절자):
이 하이퍼파라미터는 각 레이어에서 모델을 얇게 만들고, 필터의 수를 줄임으로써 모델의 복잡성 감소
2. Resolution Multiplier (해상도 조절자):
입력 이미지의 크기를 줄이고, 따라서 모든 후속 레이어의 내부 표현을 줄인다.
이는 연산량을 감소시키고, 모델을 더 가볍게 만들기 위함
비교
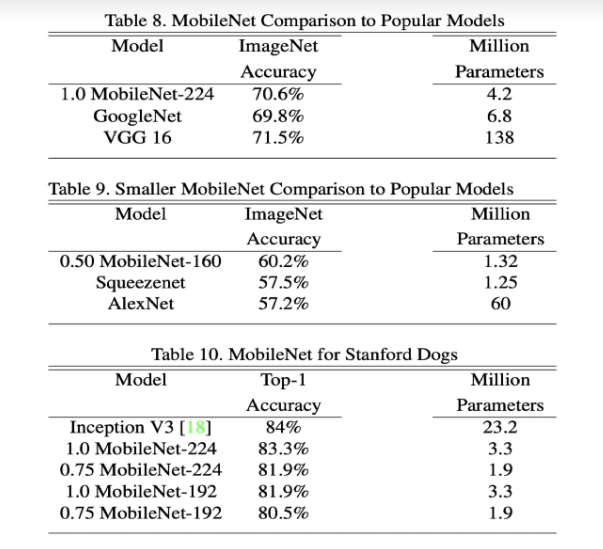
224 픽셀의 이미지 크기로 70.6%의 이미지넷 정확도를 달성
이는 VGGNet의 71.5%와 비교할 때 매우 높은 수치
또한 MobileNet은 4.2백만 파라미터만 사용하며, 이는 VGGNet의 128백만 파라미터에 비해 훨씬 적다.
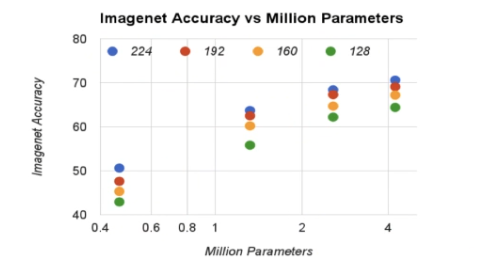
InceptionV3
이 네트워크가 해결한 문제는 무엇일까
CNN에서는 필터 크기, 스트라이드, 패딩, 완전 연결된 레이어의 크기 등 많은 파라미터 조정이 필요
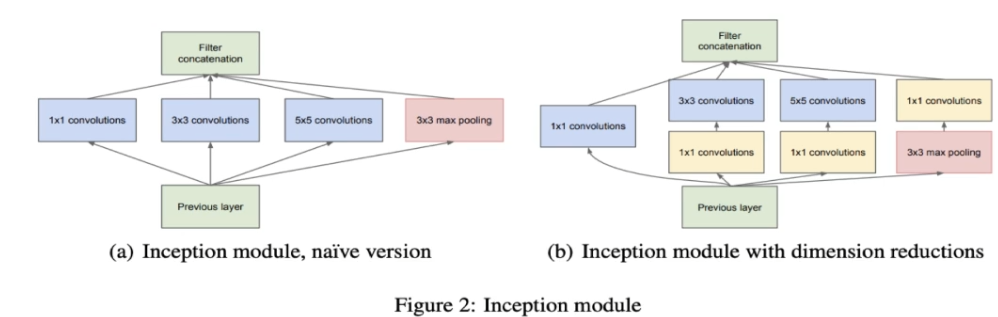
Inception은 이 중 첫 번째 문제, 즉 필터 크기 문제를 해결하려고 했다.
필터 크기를 3x3, 5x5, 7x7 등으로 설정할 수 있지만, 어떤 크기를 선택해야 할지 모르는 경우가 많았고,
Inception은 이를 해결하기 위해 여러 필터 크기를 동시에 사용하는 접근 방식을 제안했다.
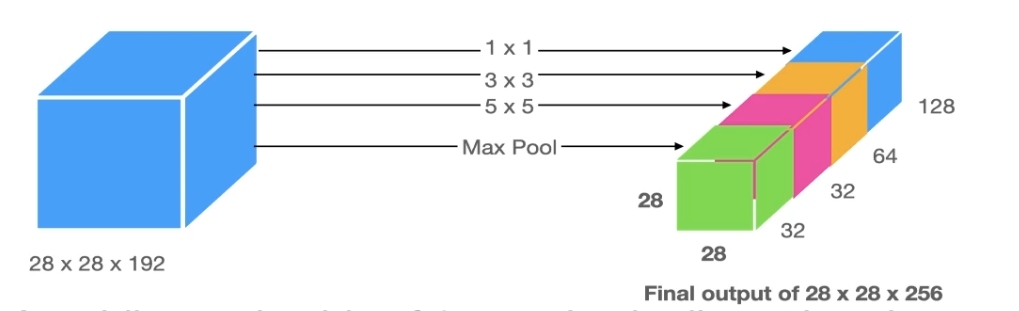
Inception Network 문제 - 계산
Inception 모듈은 입력 이미지에 여러 필터를 동시에 적용하여 여러 크기의 특징 맵을 생성합니다.
그러나 이 방식은 매우 많은 계산을 필요로 하며, 계산 비용이 매우 높아져,

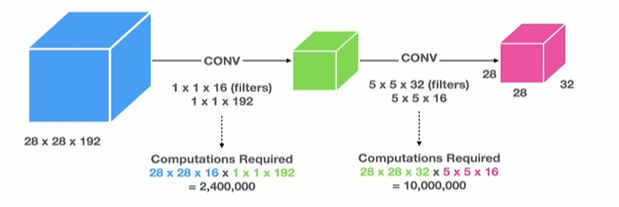
이를 해결하기 위해 1x1 합성곱을 사용하는 방식을 채택해 계산 비용을 줄였다.
1x1 Conv(합성곱)
입력 채널을 줄여 계산량을 감소
기본적인 합성곱에서는 120백만 개의 연산이 필요하지만, 1x1 합성곱을 사용하면 2.4백만 개의 연산으로 줄일 수
Inception Block

1. 여러 크기의 필터를 적용하여 특징 맵을 생성
2. 생성된 특징 맵을 1x1 합성곱을 사용하여 축소
3. 축소된 특징 맵을 다시 결합하여 최종 출력 특징 맵을 생성
Inception 네트워크 디자인
Inception 네트워크 디자인은 여러 개의 Inception 블록으로 구성된다.
이 블록들은 네트워크의 깊이를 증가시키며, 네트워크의 성능을 향상
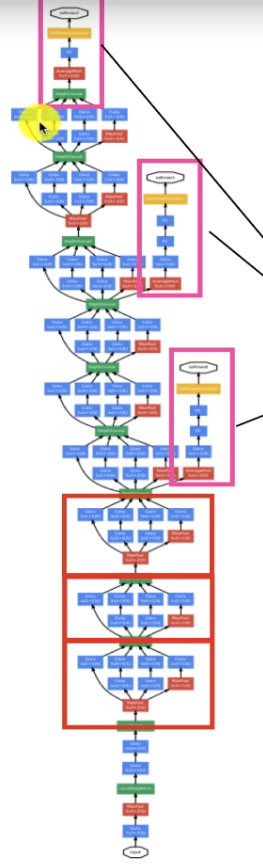
Inception 네트워크에는 또한 정규화 효과를 부여하는 측면 가지(side branch)가 포함되어 있고 분홍색 박스가 side branch 이다.
SqueezeNet
임베디드 장치와 모바일 장치를 위한 고효율, 저파라미터 CNN
SqueezeNet은 MobileNet과 유사하게 매우 높은 정확도를 유지하면서도 작은 크기를 자랑하는 CNN
Fire Module
Fire 모듈은 SqueezeNet의 핵심 구성 요소로, 'squeeze'와 'expand' 블록을 포함한다.
Fire Module - Squeeze and Expand Layers
여기서 'squeeze'는 1x1 컨볼루션을 사용하여 차원을 축소하고, 'expand'는 이를 다시 확장하여 큰 필터를 사용한 것과 유사한 출력을 생성
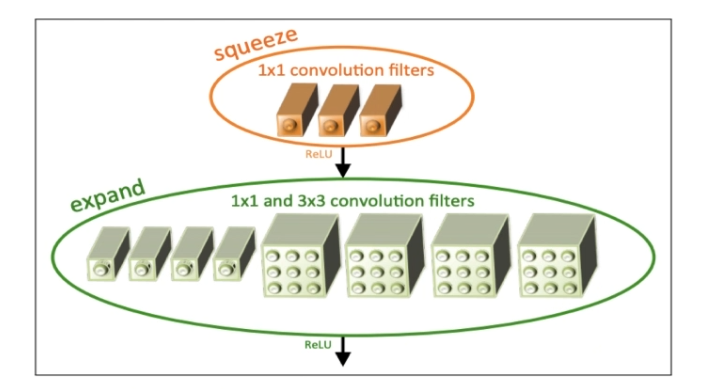
Fire Module - SqueezeNet's Squeeze and Expand Layers

성능
SqueezeNet의 성능을 살펴보면, SqueezeNet은 AlexNet보다 더 작은 모델 크기와 비슷한 정확도를 달성했다.
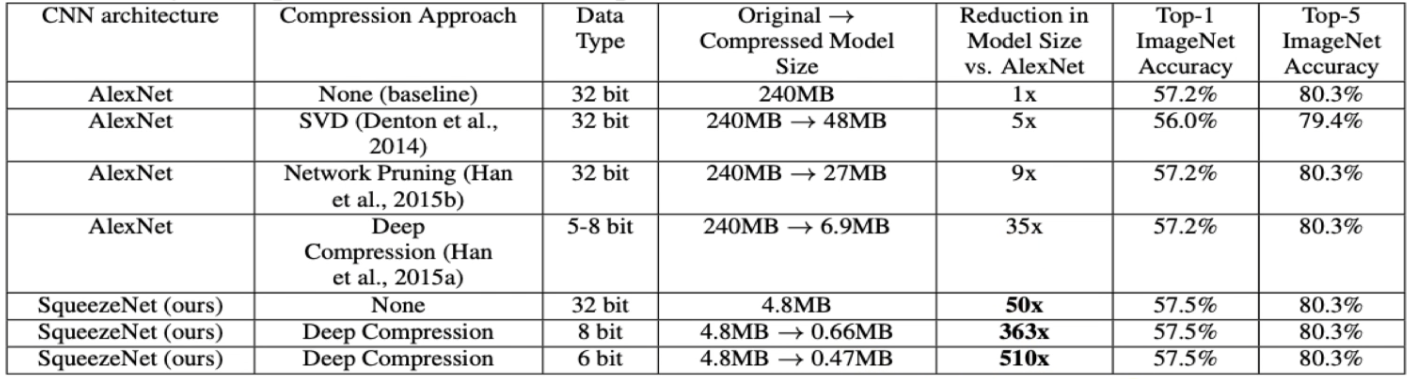
ImageNet에서 SqueezeNet은 57.5%의 정확도를 달성
AlexNet의 57.2%와 비슷하다.
그러나 모델 크기는 훨씬 작아서, 데이터 압축을 통해 모델 크기를 0.47MB로 줄일 수 있다.
이는 매우 작은 크기로, 높은 성능을 유지하면서도 매우 효율적인 모델을 제공한 것이다.
EfficientNet
EfficientNet은 Google의 AutoML과 모델 스케일링 기술을 통해 정확도와 효율성을 개선한 모델
CNN은 일반적으로 고정된 리소스 비용으로 설계되고 나서 스케일업되는데, 이는 최적의 방법이 아니고,
효율성을 극대화하기 위해 레이어 수, 필터 수와 같은 요소가 정확도에 어떻게 영향을 미치는지 알아내야한다.
EfficientNet은 CNN의 각 차원을 균일하게 스케일링하여 최적의 아키텍처를 찾는 방법을 제안한다.
Grid Search
EfficientNet은 네트워크 설계에서 최적의 파라미터를 찾기 위해 그리드 탐색을 사용

네 가지 제약 조건(채널 수, 필터 수, 레이어 수, 입력 해상도)을 고정한 상태에서 최적의 파라미터를 찾는다.
아키텍쳐
EfficientNet은 CNN 아키텍처를 최적화하는 원칙을 따르지만, 기본 네트워크에 크게 의존

EfficientNet 성능
EfficientNet은 B0부터 B7까지 다양한 버전이 있으며, 각각의 버전은 다양한 성능을 보여준다.

예를 들어, EfficientNet-B7은 약 60백만 파라미터로 84% 이상의 정확도를 달성
이는 이전의 많은 네트워크보다 더 나은 성능을 보여준다.
DenseNet
DenseNet은 ResNet과 비슷하지만 더 나은 성능을 제공한다.
DenseNet은 ResNet과 마찬가지로 기울기 소실 문제를 해결
기울기 소실 문제는 네트워크가 매우 커지면 작은 기울기가 네트워크를 따라 전파되면서 0이 되어버리는 문제인데,
DenseNet은 각 층이 두 개 이상의 이전 층에서 정보를 받는 집합적 지식을 도입하여 이 문제를 해결했다.
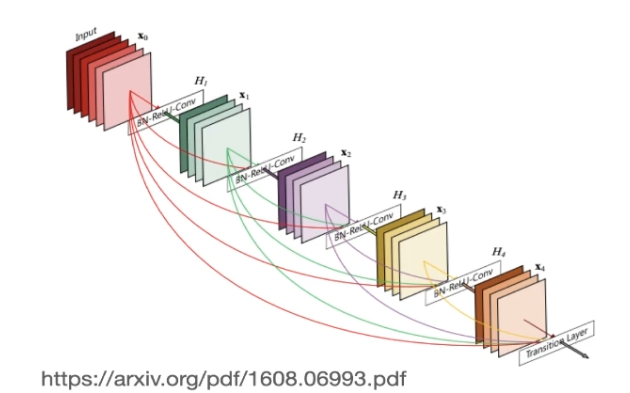
클래식한 컨볼루션 아키텍쳐

ResNet 컨볼루션 아키텍쳐

DensNet 아키텍쳐
DenseNet의 주요 특징은 여러 연결을 통해 각 층이 이전 층의 출력을 받는다는 것
각 층은 이전 층의 출력과 더불어 모든 이전 층의 출력을 받고, 이는 성장률(K)로 제어된다.

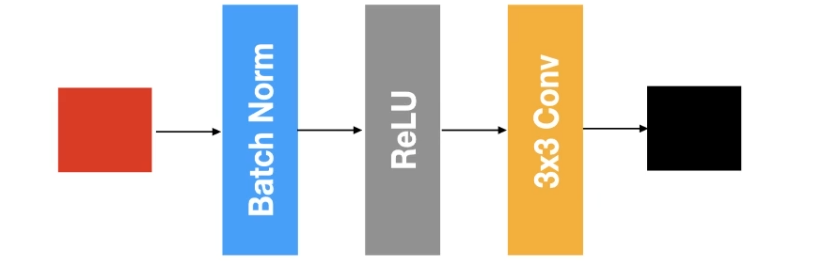
DensNet Component, 기본 DenseNet 구성 레이어
기본 구성 요소로는 프리 액티베이션 배치 정규화와 3x3 필터를 사용하는 합성곱 레이어
DensNet Component, 전이층이 있는 다중 조밀 블록

DensNet Component
DenseNet 성능
ImageNet 데이터셋에서 오류율이 매우 낮다.
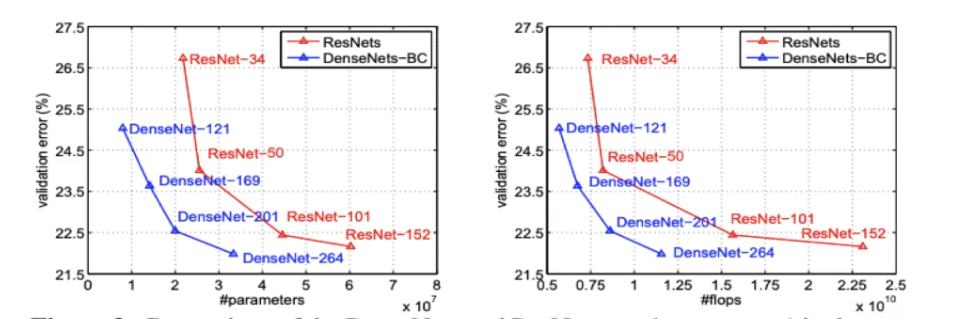
ResNet과 비교해보면, DenseNet은 적은 파라미터로 더 낮은 오류율을 달성했고, 계산량(Flops)도 더 적다.
ImageNet
이미지넷은 컴퓨터 비전 커뮤니티에서 매우 중요한 데이터셋이다.
그 이유는 가장 큰 레이블된 이미지 데이터셋이기 때문
현재 이미지넷 웹사이트에 가면 전체 데이터셋이 1400만 개의 이미지로 구성되어 있으며, 계속해서 증가중이다.

장점 : 크기
1500만 개의 이미지로 구성되어 있으며, 다른 데이터셋에 비해 매우 크다.

WordNet
이미지넷의 또 다른 장점은 의미론적 매핑과 온톨로지 구조를 가지고 있다는 것
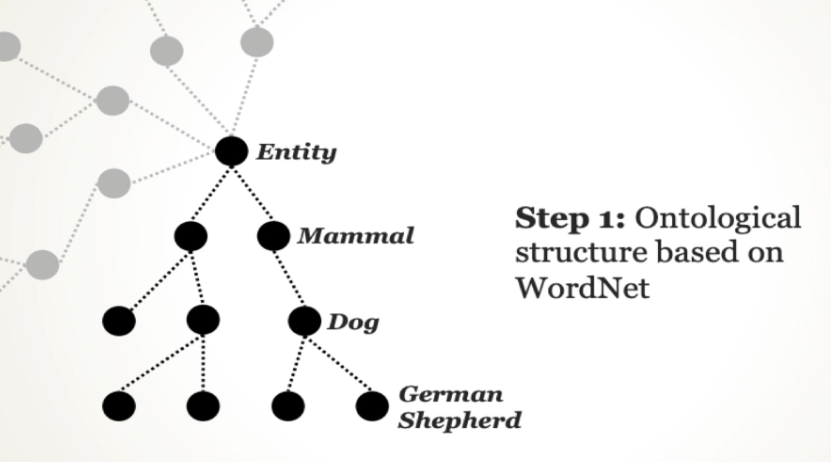

이를 통해 이미지와 단어 간의 관계를 기반으로 한 인간 수준의 이해를 가능하게 한다.

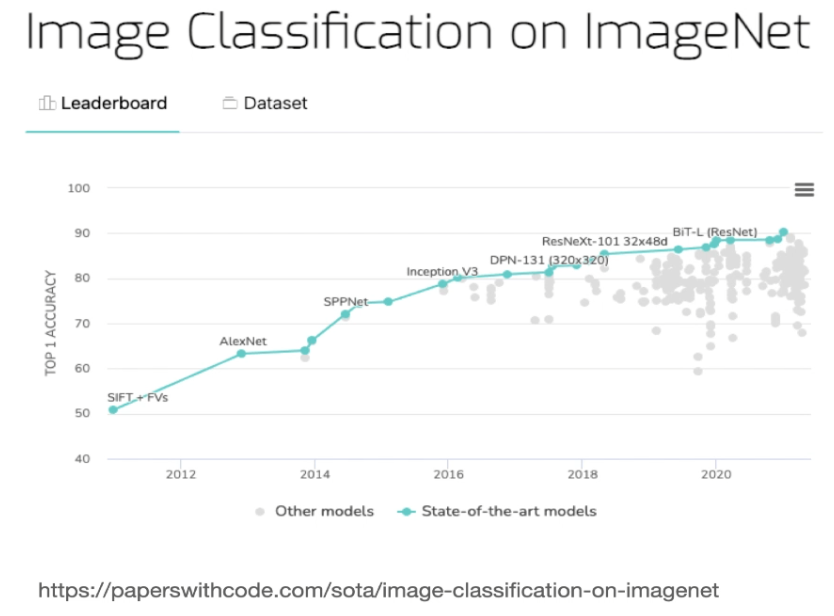
이미지넷은 CNN 모델을 훈련하고 벤치마킹하는 데 자주 사용
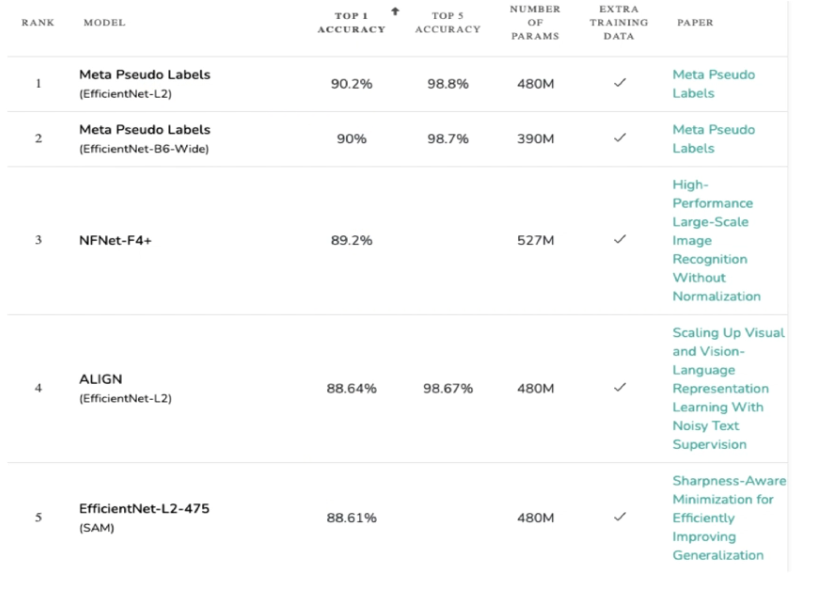
2021년 말 기준으로, EfficientNet-L2가 90.2%의 정확도로 최고의 성능을 보이고 있다.