
GAN에 대해서 알아봤는데 DCGAN은 뭘까
GAN, DCGAN
요약부터 먼저 말하자면
-
GAN은 생성자와 판별자를 포함하는 기본 구조로, 다양한 데이터 생성을 위한 일반적인 프레임워크
-
DCGAN은 GAN의 확장판으로, 컨볼루션 신경망을 사용하여 특히 이미지 생성 및 변환에 강력한 성능을 발휘
이 두 가지 모델 모두 생성적 적대 신경망의 개념을 바탕으로 하지만, DCGAN은 이미지와 같은 고차원 데이터를 처리하는 데 최적화된 아키텍처를 제공
GAN
GAN은 두 개의 신경망(네트워크)
생성자(Generator), 판별자(Discriminator)로 구성됐다.
생성자는 가짜 데이터를 생성하는데 능하고,
판별자는 그 데이터가 진짜인지 가짜인지 구분한다.
DCGAN (Deep Convolutional Generative Adversarial Network)
DCGAN은 GAN의 한 종류로, 생성자와 판별자 모두 컨볼루션 신경망(CNN)을 사용하여 설계되었다.
CNN은 이미지와 같은 고차원 데이터를 처리하는 데 매우 효율적이기 때문에 DCGAN은 특히 이미지 생성 및 변환에 효과적이다.
DCGAN 의 구성도 생성자와 판별자 두 가지 이지만,
전통적인 GAN과 달리, DCGAN의 생성자는 스트라이드 컨볼루션 및 배치 정규화를 사용하여 업샘플링을 수행하고,
판별자는 스트라이드 컨볼루션 및 배치 정규화를 사용하여 다운샘플링을 수행합니다.
Keras 실습
1. Setup & load and prepare the dataset
# To generate GIFs
!pip install imageio
!pip install git+https://github.com/tensorflow/docs
import tensorflow as tf
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display기본적으로 라이브러리를 다운로드하고 호출해준다.
2. Load and prepare the dataset
# Download MNIST
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
# Reshape and Normalize
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
# Set Batch and Buffer Size
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)버퍼사이즈 60000,
버퍼사이즈는 데이터셋을 섞기(셔플) 위한 버퍼 크기이며, 크기가 클 수록 데이터셋이 더 무작위로 분포 되어 모델의 학습 성능이 향상될 수 있지만, 너무 크면 메모리를 많이 사용한다.
배치사이즈 256
배치사이즈는 훈련할때 사용할 배치의 크기로, 모델이 한 번에 처리하는 데이터의 양을 의미한다.
클수록 훈련속도가 빠르며 학습이 더 안정적일수 있지만, 메모리 사용량이 많아진다.
작다면 훈련시간이 길고, 모델이 더 자주 업데이트되므로 훈련이 불안정해질수 있다.
예시 비교
- BUFFER_SIZE 1000, BATCH_SIZE 32:
데이터셋이 덜 섞여 있을 가능성이 있으며, 배치 크기가 작아 메모리 사용은 적지만 훈련 시간이 길어질 수 있습니다.
- BUFFER_SIZE 60000, BATCH_SIZE 256:
데이터셋이 잘 섞여 있어 모델이 더 잘 학습할 수 있습니다. 배치 크기가 적당하여 메모리 사용과 훈련 시간의 균형이 맞을 수 있습니다.
- BUFFER_SIZE 60000, BATCH_SIZE 1024:
데이터셋이 잘 섞여 있으나, 배치 크기가 너무 커서 메모리 사용이 많아질 수 있습니다. 훈련 속도는 빨라질 수 있지만, 메모리 제한에 부딪힐 수 있습니다.
3. Define our Generator Model
모델 아키텍쳐:
생성자 모델은 입력 노이즈 벡터(100 차원)를 받아 점진적으로 업샘플링하여 28x28 크기의 이미지를 생성
각 레이어는 BatchNormalization과 LeakyReLU를 통해 학습을 안정화하고 비선형성을 추가

여기에 해당하는 부분으로
DCGAN의 전형적인 구조로, 노이즈 벡터를 입력받아 점진적으로 고해상도 이미지를 생성
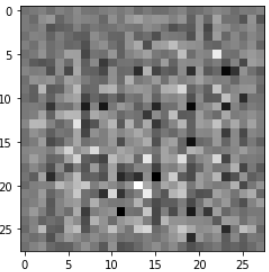
결과를 봤을때는 뭔지도 모를정도로 매우 좋지않다.
4. Define our Discriminator Model
모델 아키텍처:
판별자 모델은 Conv2D 레이어를 통해 입력 이미지의 특징을 추출하고, LeakyReLU 활성화 함수와 Dropout을 사용하여 학습의 안정성을 높인다.
Flatten 레이어를 통해 2D 이미지를 1D 벡터로 변환하고, Dense 레이어를 통해 단일 출력 노드를 사용하여 이진 분류를 수행
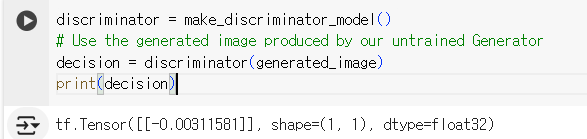
출력된 값 -0.00311581은 생성자가 생성한 이미지가 가짜임을 판별자가 인식했음을 나타낸다.
0에 가까울수록 가짜일 확률이 높다.
이 값은 생성자가 아직 훈련되지 않은 상태이므로, 생성된 이미지가 현실적이지 않음을 의미
손실 및 정규화 처리
loss, 정규화, checkpoints를 정의하고
학습을 진행한다.
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16학습은 에포크 50,
노이즈 벡터 100차원의 랜덤 벡터
한번에 생성할 이미지 예제의 수 16
학습을 하고 이미지를 저장.
학습 과정들을 전부 저장해서, GIF로 만들어서 출력
50의 에포크 동안, 16개의 이미지를 생성했고, 점점 개선되는 모습을 확인할 수 있다.

PyTorch 실습
PyTorch도 Keras와 비슷하다
모델 정의:
-
Discriminator 모델:
이미지를 입력으로 받아 진짜인지 가짜인지 판별하는 모델
여러 층의 Fully Connected Layer로 구성
최종 출력은 이진 분류를 위한 단일 노드 -
Generator 모델:
랜덤 노이즈 벡터를 입력으로 받아 이미지를 생성하는 모델
입력 노이즈 벡터의 크기는 100이며, 최종 출력은 28x28 크기의 이미지
손실 함수 및 최적화 설정:
손실 함수는 Binary Cross Entropy Loss를 사용
최적화 기법으로는 Adam Optimizer를 사용
학습률은 매우 낮게 설정(0.0001)
결과
50 에폭 후의 결과를 보면, 생성된 이미지가 상당히 잘 만들어졌음을 알 수 있다.

하지만 이미지에 약간의 노이즈가 존재하는데, 이는
Convolutional Layer를 사용하지 않았기 때문일 수 있다.
