
개념 이해하기
이번 장은 내용이 길다고 생각해서 두 개의 게시물로 나누게 되었는데, 목차와 분량을 보니 사실 이번 장의 내용이 긴 게 아니라 저번 장의 내용이 짧았던 것 같다는 생각이 들기 시작했다.
저번에는 패션 MNIST 데이터셋에 CNN을 적용하여 학습 효과를 높여 보았는데, 이번에는 학습을 위해 정형화된 데이터셋이 아니라 우리가 접하는 실제 이미지에 조금 가까운 데이터셋을 다루어 볼 예정이다. 또한, 실행 시마다 우리가 데이터를 훈련시키는 것이 아니라 다른 누군가가 이미 많은 데이터를 이용하여 훈련시켜 둔 모델의 일부를 가져오는 전이 학습에 대해서도 다루어 볼 예정이다.
먼저 여기에서 컴퓨터로 합성된 다양한 말과 사람 사진이 담겨 있는 데이터셋을 가져온다. 패션 MNIST 데이터셋을 다룰 때에는 이미지마다 그 이미지가 무엇인지를 나타내는 레이블이 있었지만, 이번에는 폴더 이름이 그 레이블이 된다.


압축을 풀면 horses 폴더와 humans 폴더가 있는데, 여기에 다양한 자세의 말과 사람 이미지가 담겨 있다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 이미지 경로
training_dir = "ch3_training"
# 전체 이미지를 1/255로 스케일 조정
train_datagen = ImageDataGenerator(rescale=1/255)
# 훈련 이미지를 300*300 크기로 다시 조정하고, 레이블을 부여한 배치 데이터 생성
train_generator = train_datagen.flow_from_directory(
training_dir,
target_size=(300, 300),
# 사람과 말을 구분하는 이진 분류이므로 binary 사용
class_mode='binary'
)
# 레이블 확인
print(train_generator.class_indices)위 코드를 이용하여, 경로에 있는 이미지 파일을 가져와 레이블을 부여할 수 있다. 지금은 ImageDataGenerator 객체에 rescale 속성만 적용했지만, 다양한 속성을 지정하여 원본 이미지를 조금씩 변형시켜 훈련에 사용될 데이터를 증식(augmentation)시킬 수 있다. train_datagen_flow_from_directory() 메소드를 사용하면 지정한 경로에서 ImageDataGenerator 에 명시한 설정을 바탕으로 데이터를 생성하는데, 훈련 이미지가 들어 있는 경로 이름을 사전 순으로 나열한 순서가 레이블이 된다. 이때 분류하고자 하는 대상이 2개를 초과하는 경우 class_mode=categorical 로 지정하여야 한다. 여기에서는 horses 와 humans 이렇게 2개의 폴더가 있으므로, horse 는 0의 레이블을 갖고 humans 는 1의 레이블을 갖는다. train_generator 객체의 class_indices 변수로 이를 확인할 수 있다.

본격적으로 신경망을 구축하고 훈련을 시작하는 부분은 다음과 같다.
# 신경망 구축
model = tf.keras.models.Sequential([
# 입력값은 300*300 크기의 RGB 이미지
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.ConV2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.ConV2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.ConV2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.ConV2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
# 분류 대상이 2개이므로 하나의 뉴런만 사용
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 훈련 방법 설정
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=0.001),
metrics='accuracy')
# 훈련 시작
model.fit(train_generator, epochs=15)모델을 훈련할 때 2장에서처럼 model.fit() 메소드에 training_images 와 training_labels 를 직접 사용하지 않고 앞에서 생성한 train_generator 객체를 사용한 것을 볼 수 있다.
위의 예제 코드를 실행한 결과와 모델의 정보는 아래와 같다.
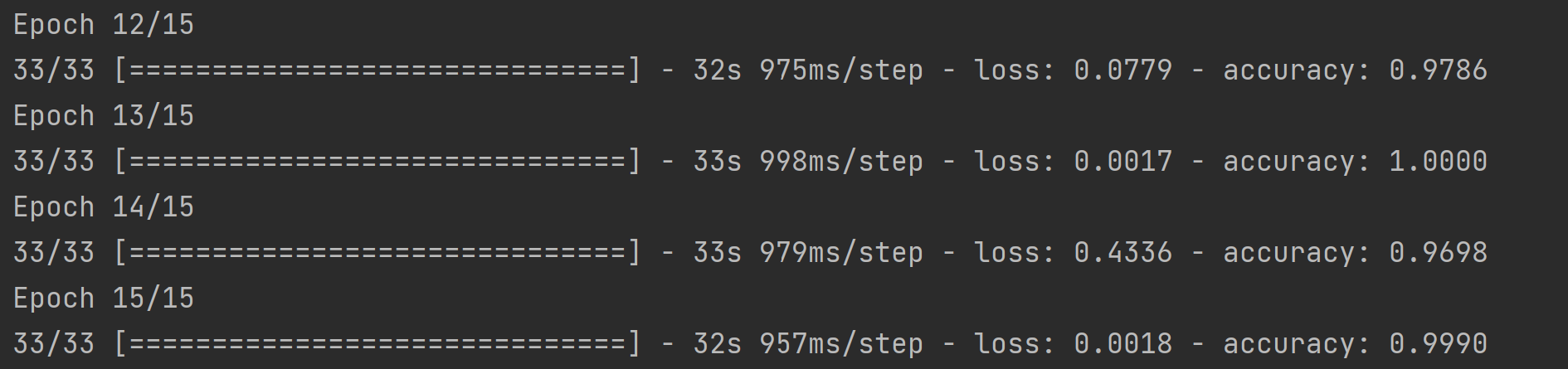
패션 MNIST 데이터셋을 다룰 때보다 입력 이미지의 크기가 많이 커졌기 때문에, 층을 통과하면서 이미지의 특징이 강조된 작은 이미지를 많이 만들기 위해 합성곱 층과 풀링 층을 많이 사용한 것을 볼 수 있고 이에 따라 학습해야 하는 parameter의 수가 이전에 비해 매우 많아졌으며 학습 시간이 오래 걸렸다. model.summary() 메소드를 이용해 확인하면 합성곱 층과 풀링 층을 모두 통과한 특성(feature)의 크기는 이 된다.
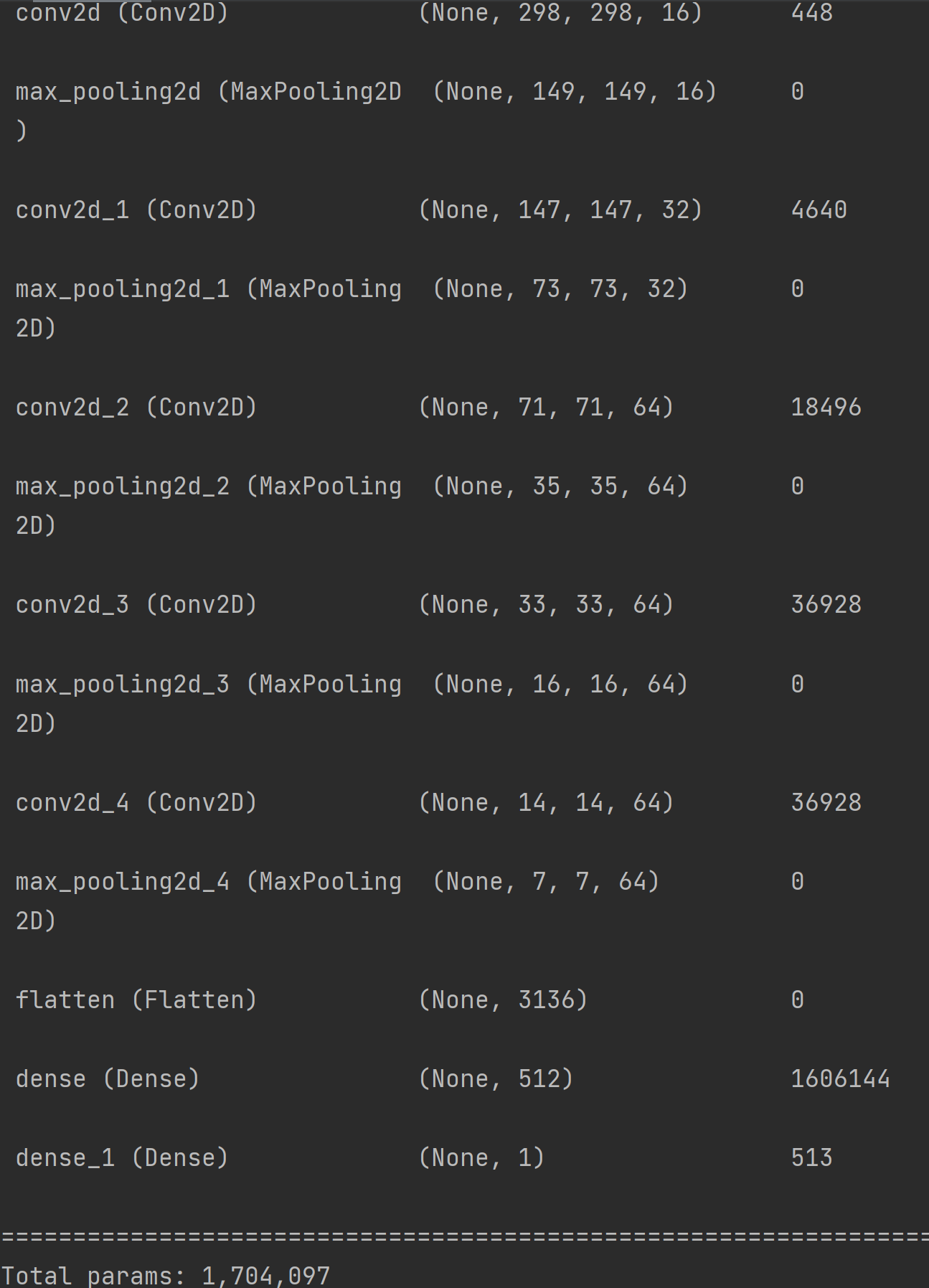
model.compile() 메소드의 optimizer 설정으로 RMSprop을 사용하며 learning_rate 를 지정하였는데, 이는 '학습률'이라는 값이다.
컴퓨터에서 학습은 모델의 예측값과 정답 값을 바탕으로 모델의 parameter를 조정하는 과정인데, 이를 수학적인 관점에서 보면 오차 함수가 최소가 되는 지점을 찾는 과정으로 예상한 지점에서 도출한 오차 함수의 기울기(gradient)를 바탕으로 예측 지점을 옮기는 과정이라고 볼 수 있다. 이때, 기울기 벡터에 곱해지는 상수를 학습률(learning rate)라고 하는데 이 값이 너무 작으면 아래 사진의 왼쪽 경우처럼 최솟값에 수렴하는 시간이 오래 걸리거나 실제로는 최솟값이 아닌 극솟값(local minima)에 수렴하는 문제가 발생할 수 있고, 너무 클 경우 최솟값이 되는 지점을 지나쳐 버리는 문제가 발생할 수 있다.
한편 앞의 코드를 실행한 결과 훈련 정확도가 약 99.9%로 매우 높은 수치가 나왔는데, 이는 훈련이 잘 되었다는 의미이기도 하지만 모델이 과대적합(overfitting)되었을 가능성도 있다. 이를 확인하기 위해 이전에는 테스트 데이터셋을 사용하였지만, 훈련이 끝났을 때뿐만 아니라 훈련 도중에도 과연 학습이 잘 되고 있는 것인지 확인해 볼 필요가 있다.
검증 데이터셋(validation dataset)은 모델을 훈련하는 동안 본 적 없는 데이터에서 모델의 성능을 확인하기 위해 사용되는 것으로, 훈련이 모두 끝난 뒤 모델의 성능을 평가하기 위해 사용하는 테스트 데이터셋과는 차이가 있다.
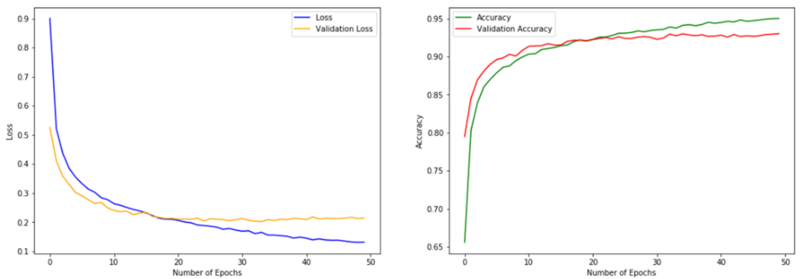
매 epoch마다 학습이 진행됨과 동시에 검증 데이터셋을 이용하여 손실과 정확도를 확인하면 위와 같은 그래프를 얻을 수 있는데, 이를 토대로 학습이 진행되는 중에도 과대적합이 일어나는지 등을 확인하고 학습에 영향을 미치는 hyperparameter를 수정하는 등의 조치를 취할 수 있다. 모든 epoch가 끝나면, 테스트 데이터셋을 통해 학습이 종료된 모델의 성능을 평가한다.
training_dir = "ch3/ch3_training"
validation_dir = "ch3/ch3_validation"
# 전체 이미지를 1/255로 스케일 조정
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
# 훈련 및 검증 이미지를 300*300 크기로 다시 조정하고, 레이블을 부여한 배치 데이터 생성
train_generator = train_datagen.flow_from_directory(
training_dir,
target_size=(300, 300),
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(300, 300),
class_mode='binary'
)
# 신경망 구축, model.compile() 메소드 호출
# model.fit() 메소드에 검증 데이터셋 사용
model.fit(train_generator, epochs=15, validation_data=validation_generator)실행 결과, 15번의 epoch 이후에 훈련 정확도는 거의 100%를 달성하였지만 검증 정확도는 약 85.1%로 모델이 과대적합되었다는 것을 알 수 있다.

이번에는 여기에서 3장의 테스트용 이미지를 가져와서 matplotlib 라이브러리를 이용하여 출력하고 모델에 넣어 결과를 눈으로 확인해 보자.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from keras.preprocessing import image
# 테스트 이미지 가져오기
sample_images = ['ch3/ch3_test/hh_image_{}.jpg'.format(i) for i in range(1, 4)]
for fn in sample_images:
# matplotlib을 이용하여 이미지 출력
plt.imshow(mpimg.imread(fn))
plt.show()
# Keras에 이미지를 300*300 크기로 불러오기
img = tf.keras.utils.load_img(fn, target_size=(300, 300))
# 이미지를 2D 배열로 변환
x = tf.keras.utils.img_to_array(img)
print("2D 배열 shape : ", x.shape)
# 모델의 input_shape가 (300, 300, 3)이므로 이 모양으로 변환
x = np.expand_dims(x, axis=0)
print("3D 배열 shape : ", x.shape)
classes = model.predict(x)
print("모델 출력 : ", classes[0][0])
if (classes[0][0] > 0.5):
print(fn + "는 사람입니다.")
else:
print(fn + "는 말입니다.")이번에도 2차원 배열의 이미지를 가져와서, 3차원 배열을 입력으로 받는 모델에 넣기 위해 np.expand_dims() 함수를 사용하였다. 이 함수의 기능은 np.reshape() 와 근본적으로 같지만, 고차원 배열에서의 dimension을 정확히 알지 못해도 사용이 가능하다.

아래 사진은 테스트 이미지 3장에 대한 모델의 예측 결과를 나타낸 것인데, 두 번째 사진의 경우 사람임에도 불구하고 말로 잘못 예측한 것을 알 수 있다. 이는 테스트 데이터셋에 몸의 일부만 나온 사람의 사진이 없어, 이러한 유형에 대해서 학습이 잘 되지 않았기 때문이라고 볼 수 있다. 두 번째 사진에 나온 분이 이걸 알면 슬퍼하시겠지...?
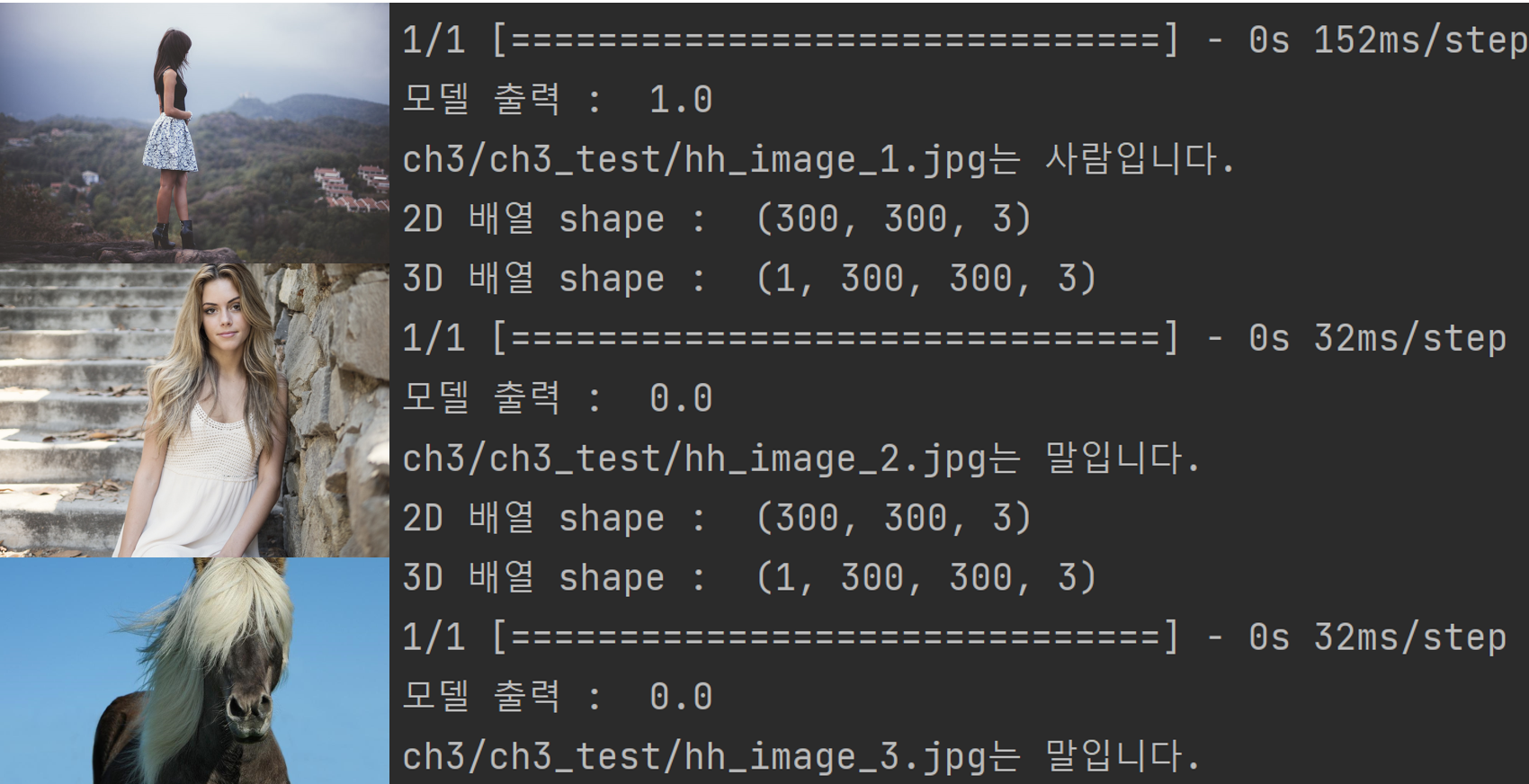
훈련 데이터에 없는 유형의 데이터가 주어졌을 때 모델이 잘못된 예측을 하는 문제를 해결하기 위해서는 훈련 데이터셋에 더 다양한 상황에서의 사람과 말 사진을 추가할 수도 있지만, 이 방법이 가능하지 않다면 기존의 데이터셋에 약간의 변형을 가해서 데이터셋을 늘릴 수도 있다. Tensorflow에서는 이미지 증식(image augmentation)이라는 기능을 통해 이미지를 로드할 때 회전, 이동, 기울임, 확대, 반전 등의 변형을 적용할 수 있다.
이를 구현하는 방법은 크게 두 가지가 있는데, ImageDataGenerator 클래스를 이용하는 방법과 Keras의 이미지 전처리 층을 이용하는 방법이 있으며, Keras의 전처리 층은 자동으로 훈련 데이터셋에만 적용되고 모델 검증이나 예측에는 사용되지 않는다.
train_datagen = ImageDataGenerator(
rescale=1/255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
# 이동하거나 기울인 후에 누락된 픽셀을 근처 픽셀로 채우기
fill_mode='nearest'
)model = tf.keras.models.Sequential([
# 이미지 전처리 층
tf.keras.layers.Rescaling(1./255, input_shape=(300, 300, 3)),
tf.keras.layers.RandomRotation(0.11, fill_mode='nearest'),
tf.keras.layers.RandomTranslation(0.2, 0.2, fill_mode='nearest'),
tf.keras.layers.RandomZoom(0.2, fill_mode='nearest'),
tf.keras.layers.RandomFlip('horizontal'),
# 나머지 CNN 층과 Dense 층
])이미지 증식을 마치고 같은 신경망에 학습시킨 결과, 이미지 전처리로 인해 훈련 시간이 더 늘어났고 훈련 정확도가 조금 더 낮아진 것을 알 수 있다. 이는 epoch마다 동일한 훈련 데이터셋이 조금씩 변형되기 때문에 과대적합이 덜 일어났기 때문이라고 분석할 수 있다. 위에서 말이라고 잘못 분류한 사람의 사진도 올바르게 분류한 것을 알 수 있다.


삽질 후기
책에서는 이미지 증식을 하면 훈련 정확도가 조금 낮아지지만 검증 정확도가 올라간다고 하였다. 그런데 나는 이미지 증식을 하니 검증 정확도도 떨어지는 것 같았다...! 위에 업로드한 사진 기준 이미지 증식을 하지 않은 경우 검증 정확도는 85.1%였지만, 이미지 증식을 한 경우 검증 정확도는 79.3%가 나온 데다가 검증 시 손실 함수의 값은 2.40에서 1.24로 감소해서 혼란스러웠다. 그런데 심지어 테스트 이미지를 넣었을 때는 더 정확해져서 무슨 마법이 일어난 건지 궁금했다!
조금의 생각과 구글링 결과 여기에서 비슷한 답을 찾았는데, 이미지 증식을 훈련 데이터에만 적용했기 때문에 검증 데이터는 변하지 않는 상황인데 epoch 때마다 훈련 데이터셋이 달라지니까 parameter도 계속 조금씩 바뀌어서 같은 데이터셋 검증할 때 정확도가 계속 달라지는 것 같다는 생각이 들었다. 그러고 보니 이미지 증식을 적용한 위의 사진에서도 14번째 epoch에서는 85.1%의 검증 정확도를 기록하기도 했으니까!
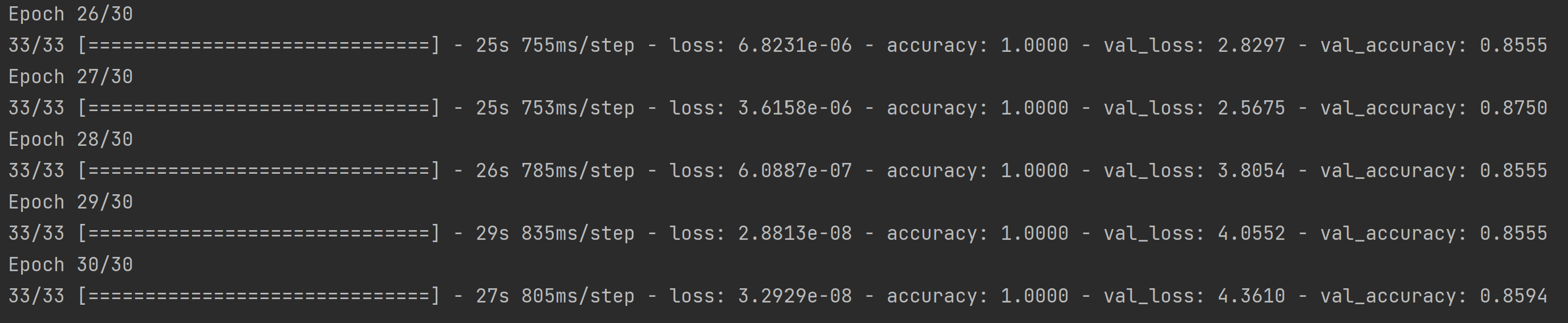
그렇다면, 만약 epoch이 15회가 아니라 더 많았다면 결국은 이미지 증식을 한 쪽이 검증 정확도도 높아질 수도 있을 것 같다는 생각으로 epoch을 30회로 늘린 채 이미지 증식을 하지 않은 경우와 한 결과를 비교해 보기로 했다!
먼저 이미지 증식을 하지 않은 결과는 다음과 같다.
다음으로 이미지 증식을 한 결과는 다음과 같다.
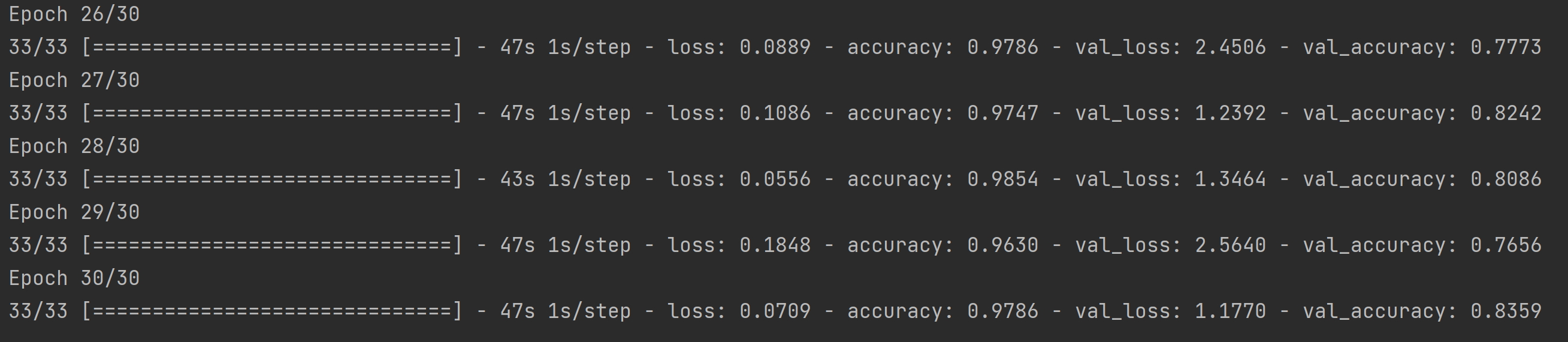
아까보다는 차이가 줄어들었지만, 여전히 이미지 증식 이후에도 검증 정확도가 더 낮은 것을 볼 수 있다.

그러던 중 검증 데이터를 뜯어보니, 이 폴더에 있는 사람의 이미지는 모두 전신이 골고루 나와 있는 것을 알 수 있었다. 그렇다면, 이미지 증식을 통해 신체의 일부만 나오는 데이터들이 훈련 데이터에 포함되면서 전신 이미지만 있는 검증 데이터에서의 정확도가 상대적으로 떨어진 것으로 해석할 수 있을 것 같다! 마치 수학 1만 공부한 사람이랑 수능 전 범위를 공부한 사람이랑 수학 1 시험 점수를 겨루는 느낌...? 그래서 위의 테스트 이미지의 2번 사진과 같은 데이터들을 검증 데이터셋에 포함시킨다면 당연히 이미지 증식을 통해 훈련시킨 모델이 훨씬 좋은 성능을 보여줄 것으로 기대된다!
