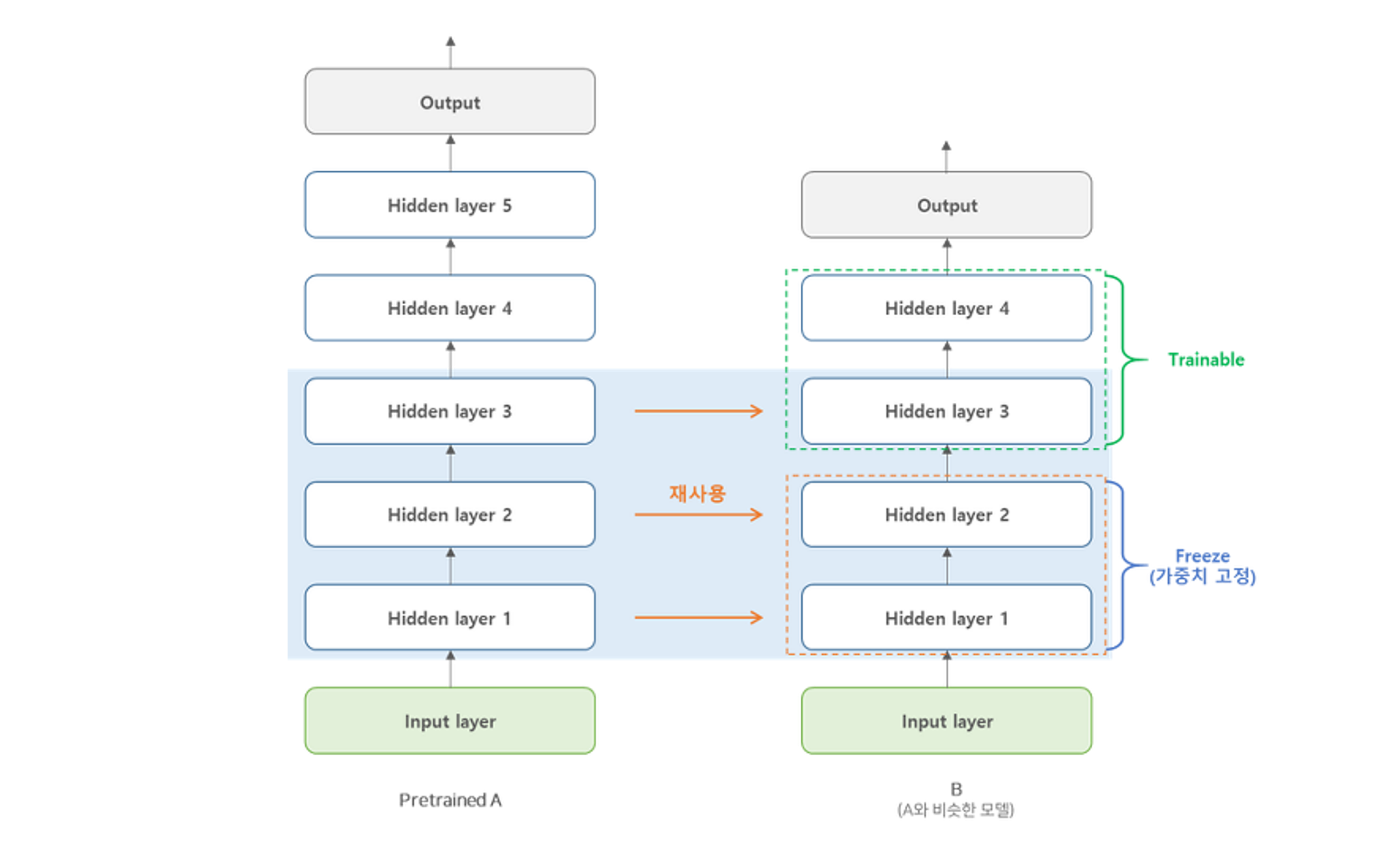
개념 이해하기
지금까지는 CNN을 이용해 모델을 처음부터 만들고 모든 parameter를 학습시켰다. 하지만 이렇게 혼자서만 모델을 구현하고 학습을 시키는 것은 여러 단점이 있을 텐데, 엄청난 수의 데이터셋을 구하기 어렵고 설령 구하더라도 학습시키는 데 매우 오랜 시간이 소요될 것이다. 하지만 다른 사람이 만든 모델을 그대로 가져다 쓰려고 하면 내가 달성하고자 하는 목표를 정확하게 구현한 모델을 찾기 어려울 것이다.
전이 학습(transfer learning)은 특정 분야에서 학습된 신경망의 일부 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경망의 학습에 이용하는 것을 의미하며, 사전에 훈련된 모델의 일부를 가져온 후 그 아래에 원하는 출력값을 갖는 신경망을 추가하는 방식으로 구현될 수 있다.
이 책에서는 ImageNet 데이터베이스의 수백만 개 이상의 이미지를 천 개 이상의 클래스로 분류하도록 훈련된 Inception V3 모델을 사용하여, 저번 글에서 다루었던 사람과 말 분류 문제에 적용할 것이다.
import urllib
import tensorflow as tf
weights_url = "https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5"
weights_file = "inception_v3.h5"
# weights_url에서 파일을 가져와 weights_file이라는 이름으로 저장
urllib.request.urlretrieve(weights_url, weights_file)
# Inception V3 신경망 모델 생성
pre_trained_model = tf.keras.applications.inception_v3.InceptionV3(input_shape=(150, 150, 3),
include_top=False,
weights=None)
# 생성된 모델에 가져온 가중치 부여
pre_trained_model.load_weights(weights_file)
# 모델 정보 출력
pre_trained_model.summary()Inception V3 모델의 구조는 내 노트북으로는 도저히 학습시키지 못할 것 같은 느낌이 들 만큼 굉장히 복잡하게 되어 있는데, 이 모델의 많은 층 중에서 이 책에서는 출력 크기가 로 작은 mixed7 층에서 신경망을 잘라서 가져온다.


공부한 내용을 토대로 설명을 추가한 예제 코드는 다음과 같다.
import urllib
import tensorflow as tf
# 데이터셋 가져오기
training_dir = "ch3/ch3_training"
validation_dir = "ch3/ch3_validation"
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
validation_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
training_dir,
# Inception V3 입력 크기 150*150
target_size=(150, 150),
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
# Inception V3 입력 크기 150*150
target_size=(150, 150),
class_mode='binary'
)
# weights_url에서 파일을 가져와 weights_file이라는 이름으로 저장
weights_url = "https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5"
weights_file = "inception_v3.h5"
urllib.request.urlretrieve(weights_url, weights_file)
# Inception V3 신경망 모델 생성
pre_trained_model = tf.keras.applications.inception_v3.InceptionV3(input_shape=(150, 150, 3),
include_top=False,
weights=None)
# 생성된 모델에 가져온 가중치 부여
pre_trained_model.load_weights(weights_file)
# 가져온 신경망의 parameter가 훈련되지 않도록 동결
for layer in pre_trained_model.layers:
layer.trainable = False
# mixed7 층의 마지막 출력을 가리키는 변수 생성
last_layer = pre_trained_model.get_layer('mixed7')
last_output = last_layer.output
# 출력 펼치기
x = tf.keras.layers.Flatten()(last_output)
# Dense 층 추가
x = tf.keras.layers.Dense(1024, activation='relu')(x)
# 이진 분류를 위해 시그모이드 함수를 사용한 출력층 생성
x = tf.keras.layers.Dense(1, activation='sigmoid')(x)
# 모델 생성
model = tf.keras.Model(pre_trained_model.input, x)
# 훈련 방법 설정
model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.0001),
loss='binary_crossentropy',
metrics=['acc'])
# 훈련 시작
model.fit(train_generator, epochs=40, validation_data=validation_generator)사람과 말의 이미지로 이루어진 데이터셋을 가져오는 방법은 전과 동일하나, Inception V3의 입력 크기가 이므로 이 크기로 가져와야 한다.
한편, 이 부분에서 신경망에 층을 추가하는 새로운 방식이 소개되었는데 이에 대해 잠깐 살펴보자.
지금까지는
Sequential클래스의 생성자에 layer의 배열을 전달하여 신경망을 생성하였지만 이번에는 각 층을 함수로 생각하여A신경망을 추가하는 작업을x = A(x)의 형태로 표현하였다. 최종적으로 입력과 출력을Model객체에 전달하여 신경망을 생성하는 것을 Keras에서는 함수형 API라고 한다.
# mixed7 층의 마지막 출력을 가리키는 변수 생성
last_layer = pre_trained_model.get_layer('mixed7')
last_output = last_layer.output
x = tf.keras.layers.Flatten()(last_output)
x = tf.keras.layers.Dense(1024, activation='relu')(x)
x = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(pre_trained_model.input, x)그렇다면 이 신경망을 Sequential 클래스를 이용한 기존의 방식으로 나타낼 수 있을까? 결국 Inception V3 모델도 여러 층으로 이루어져 있기 때문에 while 이나 리스트 슬라이싱을 적당히 사용한다면 층들의 배열로 바꿀 수 있을 것 같다. 하지만, 이는 불가능하다. Inception V3 구조는 사실 층이 일자로 쌓인 것이 아니기 때문이다.
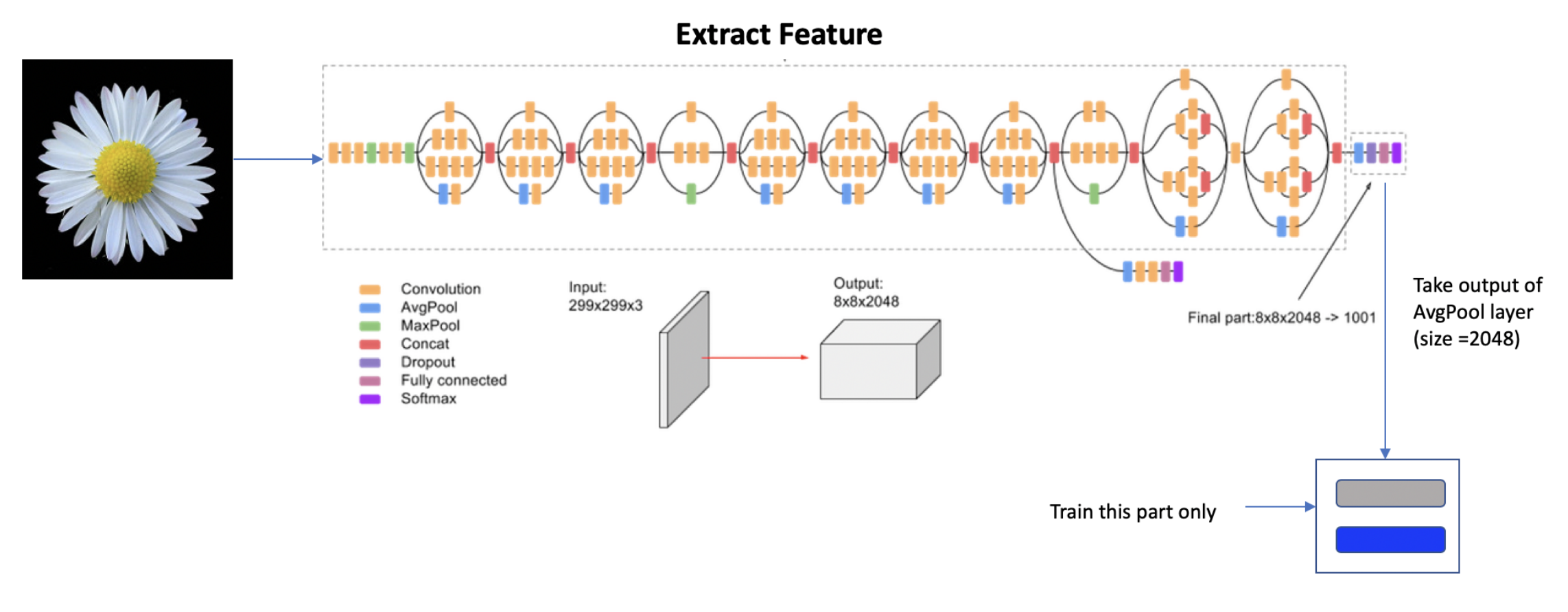
위 사진이 Inception V3의 구조인데, 하나의 층이 다른 하나의 층과 연결되는 부분도 있지만 하나의 층이 여러 개의 층과 연결되는 부분도 존재한다. 그러나 Sequential 클래스에서는 이러한 부분을 구현할 수 없다. 따라서, 함수형 API를 사용한다면 하나의 층을 통과한 출력이 여러 층의 입력이 되는 경우(x가 신경망 A, B, ... 를 통과하는 경우)는 y1 = A(x), y2 = B(x), ... 의 형태로 구현하고, 여러 층의 출력이 하나의 입력으로 합쳐지는 경우(x1, x2, ... 가 신경망 A를 통과하는 경우) y = A(x1, x2, ...) 의 형태로 구현할 수 있어 이러한 구조를 나타내는 데 적합할 것이다.
이렇게 Inception V3를 일부 가져온 신경망에서 사람과 말의 데이터를 훈련한 결과, 검증 정확도가 약 99.6%로 매우 높아진 것을 알 수 있다.

책에서 이어지는 내용은 가위바위보 데이터셋을 이용하여 이진 분류가 아닌 다중 분류를 하는 것인데, 다중 분류에 대한 내용은 패션 MNIST 데이터셋에서 다루어 보기도 했고 출력층의 뉴런 개수가 분류하고자 하는 대상의 종류의 수가 되는 것, ImageDataGenerator 를 생성하고 flow_from_directory() 메소드를 사용할 때 class_mode 를 categorical 로 설정하는 것, 손실 함수로 binary_crossentropy 가 아닌 categorical_crossentropy 혹은 sparse_categorical_crossentropy 를 사용한다는 것 이외에는 큰 차이가 없으므로 생략하려 한다. 대신 조만간 카메라를 통해 사용자의 손 동작을 인식해서 가위바위보 필승 로봇을 만들어 보고 싶은 생각이 있어서, 나중에 토이 프로젝트의 주제로 남겨 보려 한다...!
3장의 마지막은 과대적합을 피하는 다른 방법 중 하나를 언급한다.
드롭아웃 규제(dropout regularization)는 훈련하는 동안 일부 뉴런을 무작위로 무시함으로써, 그 뉴런이 다른 층의 뉴런에 미치는 영향을 일시적으로 막는 기법으로 어떤 데이터에 의해 일부 뉴런이 과도하게 특화될 가능성을 줄여주는 기능을 한다.
드롭아웃은 Keras에서 Dropout 층을 추가하는 것으로 간단히 구현될 수 있는데, 2장의 패션 MNIST 분류기에서 Dense 층 이후에 20%의 뉴런을 무시하는 드롭아웃을 적용하는 코드를 작성하였는데, 달라진 부분은 2장에서 테스트 데이터로 사용했던 부분을 검증 데이터로 사용하는 것과 신경망에 몇 개의 Dense 층을 추가하고 드롭아웃을 적용한 것이다.
import tensorflow as tf
data = tf.keras.datasets.fashion_mnist
# 가져온 데이터셋에서 일부(60,000개)는 훈련에 사용, 일부(10,000개)는 검증에 사용
(training_images, training_labels), (validation_images, validation_labels) = data.load_data()
training_images = training_images / 255.0
validation_images = validation_images / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
# tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
# tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
# tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, validation_data=(validation_images, validation_labels), epochs=30)드롭아웃을 적용하지 않은 결과는 아래와 같이 훈련 정확도가 약 94.7%, 검증 정확도가 약 88.6%로 과대적합의 징후가 나타났다.

모델 내 각주를 해제해 드롭아웃을 적용한 결과는 아래와 같이 훈련 정확도가 약 91.2%, 검증 정확도가 약 88.9%로 훈련 정확도가 낮아지며 검증 정확도와 비슷한 수치를 기록했기 때문에, 과대적합을 방지하는 효과가 있었다고 볼 수 있다.

삽질 후기
오늘의 삽질 후기는 내용과 관련된 것은 아니고, 그 전부터 거슬리던 Keras가 인식되지 않는 문제(놀랍게도 막상 실행하면 정상적으로 실행된다)를 해결해 보고 싶었는데, 구글링해 보니 가장 많이 나오는 방법은 tensorflow.keras 부분은 tensorflow.python.keras 로 바꾸는 것이었다. 그런데 이렇게 하니 Keras의 하위 모듈이 여전히 인식되지 않는 문제가 있어서 결국은 import 문에 keras 를 사용하지 않고 코드에 tf.keras 를 사용하기로 하였다. 빨간 줄이 뜨지는 않지만 코드가 너무 길어져서 보기가 힘든 것 같은데 언젠가는 이 문제가 고쳐졌으면 좋겠다! 코드가 예쁘게 보였으면 하는 나에게는 이건 너무 큰 고통이야... 코드가 너무 길어지면 일단은 그냥 새로 변수를 선언해서 쓰는 수밖에 없겠지?

