
대학교 AI 이론 수업 내용 중 K-Fold Cross-Validation 내용 정리해보고자 한다.
배경
실제로는 많은 경우에 한 가지 모델만 가지고 hyper parameter들을 바꿔가면서 하기보다는 여러가지 후보가 될 만한 모델을 선정한다.
모델 선정
여러가지 후보가 될만한 모델을 고려해보고 각각의 모델에 대해 training 시켜본 후 우리의 문제에서 가장 generalization한 문제를 좋게 보여줄만한 모델을 선택하는 과정.
모델 선정을 할 때에는 parameter를 업데이트하는데 사용하는 데이터(train data)를 활용하면 별로 도움이 되지 않음. 그래서 validation set을 사용한다.
| Training set | 모델의 parameter를 업데이트 하는 데 사용 |
|---|---|
| Validation set | 개발 중에 쓰는 데이터(hyper parameter 업데이트 하는 데 사용) |
| Test set | 개발 후에 쓰는 데이터 |
-
Training set과 Validation set
딥러닝 모델은 training set에 대해 어느정도 overfitting이 일어날 수 밖에 없으니까 training set에 대해서 fitting된 모델을 validation set에다가 test해보고 그것으로 hyperparmeter를 업데이트함.
-
Test set
Test data는 딱 한 번만 건드려야 되는 데이터다. 하지만 실제로 여러번 활용 하게 됨. 아주 엄격한 의미에서 test data를 만드는 것은 어려움
ex) 의료인공지능 같은 경우 그러한 과정이 필요한데 신약개발할 때, 제품으로 나오려면 임상실험을 해야 되기 때문.
그래서 대부분 현실적으로는 있는 데이터를 사골 우려 먹듯이 충분히 잘 활용해서 모델을 개발할 수 밖에 없음. 그러한 측면에서 유용하게 쓸 수 있는 방법이 “K-Fold Cross Validation” 이다.
K-Fold Cross Validation

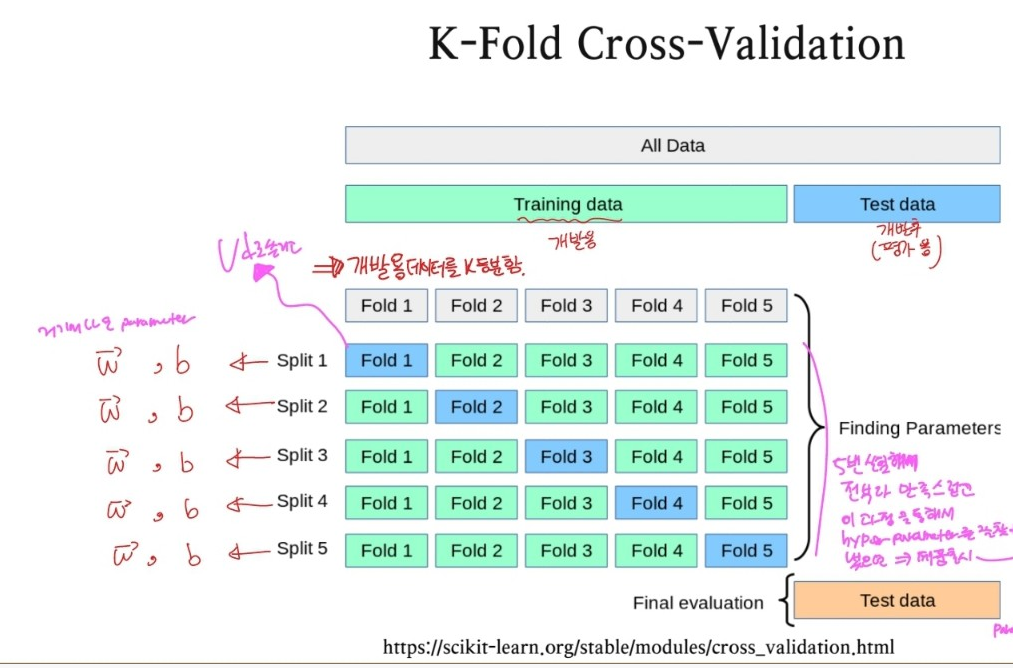
⇒ 그래서 K등분 하여 subset을 한 번씩 추출하여 모든 데이터에 대해 검증해보는 방식을 사용하는 것으로 생각 됨.
-
방법
- original Training data를 overlap 되지 않는 K개의 subset으로 분할(데이터를 K등분 함).
- 모델의 Training과 Validation을 K번 수행함.
- 한 번의 수행과정 : K-1개의 subset들로 학습을 시키고, K-1개를 제외한 나머지 하나의 subset으로 검증과정을 수행하는 것으로 구성됨. ⇒ 이걸 K번 수행한다는 것(subset들을 바꿔가며)
- 마지막으로 Training error rate와 Validation error rate은 K번의 실험의 결과에 대한 평균을 통해 추정함.
-
K-Fold Cross-Validation 결과
-
K번의 실험을 거치면서 K개의 parameter가 나오게 됨
-
K번 실험해서 전부 다 만족스럽고 이 과정을 통해서 hyperparameter를 잘 찾아 냈으면 최종 모델을 선정하여 제품을 출시한다!
- hyperparameter를 잘 찾아낸 거 같으면 Validation set을 안쓰고, 그hyperparameter를 바탕으로 하여 전체 데이터를 학습에 사용하고 새로운 모델을 만들 수 있음.
- K개의 모델을 혼합해서 더 좋은 모델을 만들어 볼 수 있음.
- K개의 parameter을 평균을 내서 쓸수도 있음.
P-stage STS 대회 미션3 코드에서 구현된 kfoldDataloader와 학습 및 평가 코드를 분석해보았을 때, 모델 선정 어떻게 하였는 지에 대한 분석
-
일반학습 : epoch3 (k-fold경우와 비교하기 위해 3으로 설정)
-
K-fold cross validationb : epoch:1, k = 3
-
pytorch-lightning에서 교차 유효성 검사를 사용하는 방법을 찾을 수 없었음.
-
미션 코드의 KfoldDataloader도 커스텀제작한 것으로 보임.
-
게다가 단순히 k번 반복하여 fit(학습) 시킴.
-
따라서 단순히 k번만큼 (eppch = k) 다른 trainset과 다른valid를 사용하여 학습시킨 뒤 dev로 평가하는 게 K-fold 이고
-
train이랑 valid 고정시켜놓고 (처음에 설정한 일정 비율대로) 학습진행 후 dev로 평가한 것들을 평균내는 것이 일반 학습임.
-
공통점은 train데이터를 train과 valid로 나눈다는 점과 평가를 dev로 한다는 점.
느낀점
이번 P-stage STS 대회에서 미션과제로 소개되어 다시 한 번 정리해보았다. 이처럼 실제로 현업에서 제한된 데이터를 가지고 제품을 출시하려 할 때, 굉장히 유용한 기법이라는 생각이 들었다. 대회를 진행하며 이러한 K-Fold Cross-Validation기법을 실제 제품을 출시하기 위해 모델의 generealization 성능을 올린다고 생각하며 모델을 학습시키며 적용해 봐야겠다고 생각했다.
이미지 출처: https://scikit-learn.org/stable/modules/cross_validation.html,
