[NAVER Boostcamp AI Tech 5기] STS 대회 개인 회고

프로젝트에서 내가 진행한 것들.
-
학습 목표
- NLP 기초 대회 강의 및 미션을 잘 이해하여 데이터 분석 및 모델링을 잘 수행하여 팀에 기여하는 것.
-
학습목표를 달성하기 위해 시도한 것
- 프로젝트 대회에 대한 기본 배경을 충분히 익히고 진행하기 위해, NLP 기초 대회 강의를 학습하고, 미션을 수행하며 사전학습 모델 및 hugging face 사용 등, 헷갈리거나 모르는 내용에 대해 조사하고, 코드들을 변경해가며, 출력 결과를 확인하고 주석을 달아가는 방식으로 코드를 분석하며 대회에 사용될 코드들을 익힘.
- class imbalance 해결 (Weighted MSE Loss Function, Embedding vector dropout)
- 모델 성능을 높이기 위해 Multi Loss 코드 구현하여 실험 및 분석 진행
-
내가 해본 시도중 실패한 경험
- class imbalance 해결 (Weighted MSE Loss Function, Embedding vector dropout)
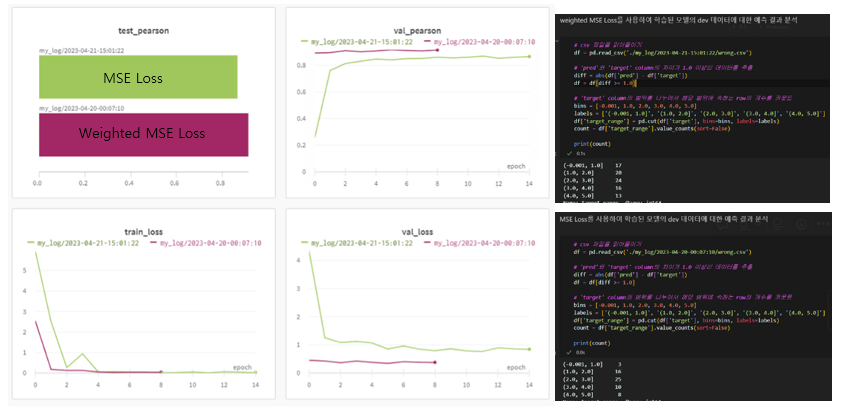
- class imbalance 해결 (Weighted MSE Loss Function, Embedding vector dropout)
-
실패의 과정에서 얻은 교훈
- Weighted MSE Loss Function를 실험하며 단순히 한 번에 실험에 대해서 좋지 않은 결과를 보았는데 Neural Network라는 것은 원래 실험마다 결과가 조금씩 달라지기 때문에 단순히 한 번의 결과만으로 가설이 참이다 아니다를 판단하기는 어렵다는 것을 알게되어 다음 프로젝트에서 이를 유념하고 실험 과정에 그러한 부분에 대해 신경을 더욱 써야겠다고 생각했다.
- Embedding vector에 dropout을 적용하여 데이터 불균형을 개선하는 것을 시도하며 시간 내에 끝까지 구현을 해내지 못하였을 때, 네트워크 혹은 네트워크의 출력을 통해 무언가를 만들어내거나 조정하려면 네트워크의 구조와 입출력에 대한 이해가 반드시 필요하다는 점을 다시 한 번 느끼게 되었다.
-
협업 과정에서 잘된 점
- 팀원 들간에 소통이 잘 이루어졌다고 느꼈다. 전달사항 혹은 질문이 있으면 슬랙을 통해 바로 공유를 하거나, zoom에서 실시간으로 질문을 하였고, 팀원들 모두 빠른 시간 내에 잘 답변을 주고 소통하여 원활하게 협업이 이루어졌다고 생각되었다.
- 팀 템플릿이 잘 작성되어 새로운 기능을 구현하고 그것을 다른 팀원들이 사용하는 과정이 원활하게 잘 이루어졌다고 생각했다.
-
내가 기여한 내용
-
Loss function에 대해 조사하여 Correlation Loss, MSE Loss, 각각을 실험하였고, 단독으로 사용하였을 때, 결과가 잘 나오지 않아, 두 Loss의 장점을 모두 챙길 수 있는 Multi Loss 방법을 시도해보게 되어 MSE와 Correlation Loss를 포함하여 실험을 진행 후 어떤 조합이 가장 성능이 좋았는 지를 실험하였다. 실험에서 가장 높은 점수를 기록한 Multi Loss 조합을 사용하여 대회 진행 제출 테스트에서 팀 내 최고 점수인 9.164를 기록하여 기존 팀 최고 점수를 더 높임으로써 팀에 기여할 수 있었다.

-
상세 실험 내용
-
Correlation Loss Function을 구현하였고, 모든 세팅을 갖게 설정하고 Correlation Loss Function을 사용했을 때와, MSE Loss를 사용했을 때의 결과를 Wandb tool을 이용하여 비교하였다.
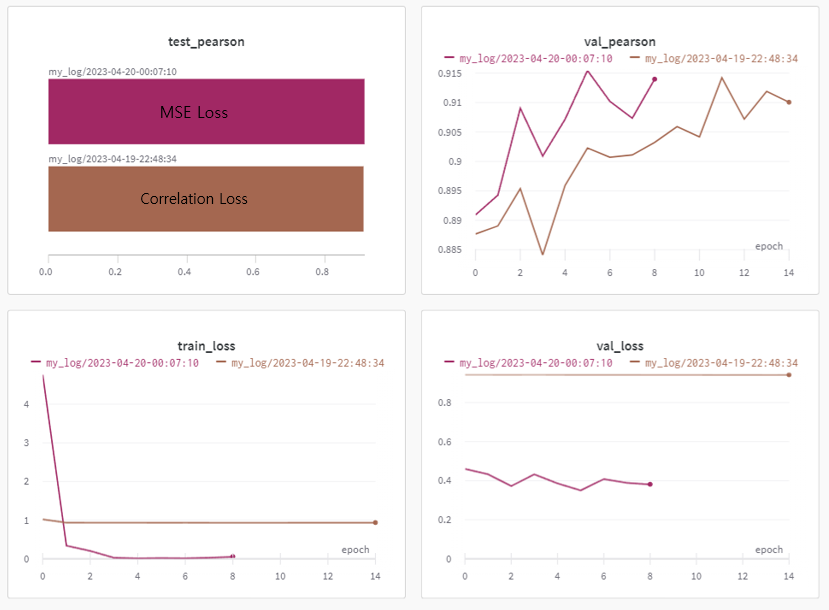
-
Validation loss 및 validation pearson 모두 MSE Loss보다 좋지 않은 성능을 보였지만, MSE Loss를 사용할 때 지속적으로 확인되었던 train loss와 validation loss와의 gap이 완화된 것을 확인할 수 있었고, 이러한 결과를 통해 MSE의 장점과 Correaltion Loss의 장점을 모두 고려하기 위해 두 loss를 함께 최적화하고자 multi loss를 시도하였다.
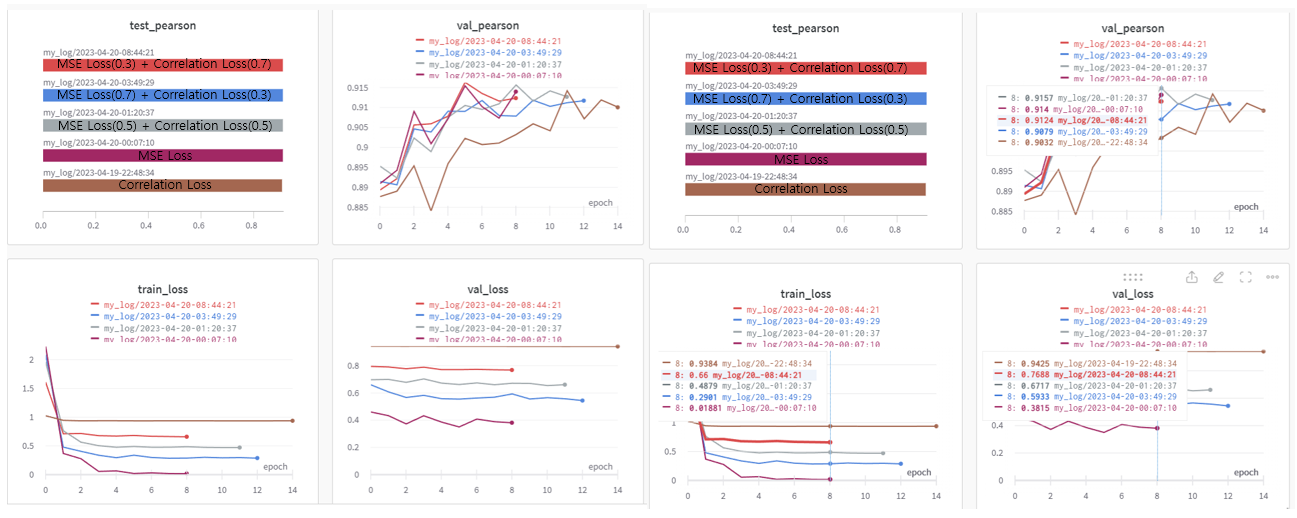
- 모든 학습 과정 중 MSE(0.3) + Correlation(0.7) 조합의 Loss function을 사용한 case가 Val_Pearson 0.9162을 기록하며 가장 높은 Val_Pearson을 보여주었고, 그 다음으로 MSE Loss를 사용했을 때의 경우 Val_Pearson 0.915 점수를 기록하며 두 번째로 높은 수치를 기록하였다. 또한 val_loss 수치로 비교하였을 때, 마지막 epoch을 기준으로 MSE의 val_loss가 더 낮은 0.3815로 “MSE(0.3) + Correlation(0.7) Loss function” 의 val_loss인 0.7688보다 낮은 수치를 기록하였지만, train_loss와의 격차가 0.36이상 차이를 보였다. 이는 “MSE(0.3) + Correlation(0.7) Loss function”의 train_loss와 val_loss의 차이인 0.1088보다 3배 가량 높은 수치인 것을 고려하였을 때, “MSE(0.3) + Correlation(0.7) Loss function”을 사용하였을 때, 더 나은 일반화 성능을 보인다고 판단하였다.
-
-
-
마주한 한계
- 위 과정에서 예상보다 많은 시간이 소요되어 팀원 모두 각자 End-to-End로 진행해보기로 결정한 1주차에 다른 팀원들 보다 진행 속도가 더뎌서 팀원들에게 진행 방향에 대해 도움이 될만한 실험 결과를 많이 제공해 주지 못하였다. 하지만 흔들리지 않고 학습을 이어나갔으며 팀원들이 K-Fold Cross Validation 기법에 대해 여러 질문들을 주었을 때, 미션 코드 중 K-Fold Cross Validation 부분을 공부했던 것을 바탕으로 해당 내용을 정리하여 노션에 공유하고 피어세션 시간에 팀원들에게 간략히 발표하며 공유하여 팀원들에게 도움을 주기 위해 노력했다. (https://velog.io/@smuhyeon/K-Fold-Cross-Validation-정리)
- 위 과정에서 예상보다 많은 시간이 소요되어 팀원 모두 각자 End-to-End로 진행해보기로 결정한 1주차에 다른 팀원들 보다 진행 속도가 더뎌서 팀원들에게 진행 방향에 대해 도움이 될만한 실험 결과를 많이 제공해 주지 못하였다. 하지만 흔들리지 않고 학습을 이어나갔으며 팀원들이 K-Fold Cross Validation 기법에 대해 여러 질문들을 주었을 때, 미션 코드 중 K-Fold Cross Validation 부분을 공부했던 것을 바탕으로 해당 내용을 정리하여 노션에 공유하고 피어세션 시간에 팀원들에게 간략히 발표하며 공유하여 팀원들에게 도움을 주기 위해 노력했다. (https://velog.io/@smuhyeon/K-Fold-Cross-Validation-정리)
프로젝트를 진행하며 느낀 점들
- 아쉬웠던 점
- 데이터 분석을 조금 더 진행해 보지 못한 점.
- 정의한 가설에 대해 충분히 많은 실험을 진행하여, 더욱 신빙성있는 결과를 만드는 시도를 하지 못했던 것.
- 출력 임베딩 차원에 대해 drop out을 적용하여 데이터 증강을 시도하였으나 코드를 끝까지 구현해 내지 못한 점.
- git 사용이 익숙지 않아 git과 관련한 작업을 할 떄 시간이 더 많이 들어간 점.
- 강의 내용과 실습을 충분히 이해한 뒤, 프로젝트를 진행하고자 했기 때문에, 가설을 정의하고 실험을 하는 단계까지 가는 것에 시간이 많이 소요된 점.
- 한계/교훈을 바탕으로 다음 프로젝트에서 시도해보고 싶은 점
- 마스터님께서 조언해주신 것처럼 실험을 할 때 단순히 한 번만 실험해보고 비교하는 것이 아닌, 실험 횟수를 정의하고, 실험결과에 대해 평균값, 혹은 중앙값을 취하여 조금 더 신뢰할 수 있는 가설 검증을 진행해보는 것.
- 다음 프로젝트에서 데이터 분석 task를 맡게 된다면, 이번 보다 더욱 여러 데이터 분석 기법들을 활용하여 데이터를 분석해보고 이를 통해 모델의 성능을 개선하는 경험까지 해보는 것.
- 동료들 통해서 배운 것.
- git 사용에 대해 이미 익숙한 팀원들이 있었다. github 특강을 통해 git 사용에 대해 학습하였지만 실제로 적용하는 데 있어서 어려움들이 있었고, 팀 Repository clone 및 브랜치 생성 등에 대해 팀원 들에게 헷갈리는 부분들에 대해 도움을 받았으며, 빨리 Git을 사용하는 것에 익숙해져서 그 만큼 시간을 확보해 더 많은 기여를 할 수 있도록 해야겠다는 것을 느꼈다.
