ImageNet Classification with Deep Convolutional Neural Networks
Background
- CNN은 1993년에 만들어졌다(…) Zip Code(postal code) Detection OCR 프로젝트를 1993년에 진행했음. 사람이 쓴 손글씨를 CNN으로 인식을 시키는 게 목적이었으며, Mnist 데이터셋이 만들어짐.
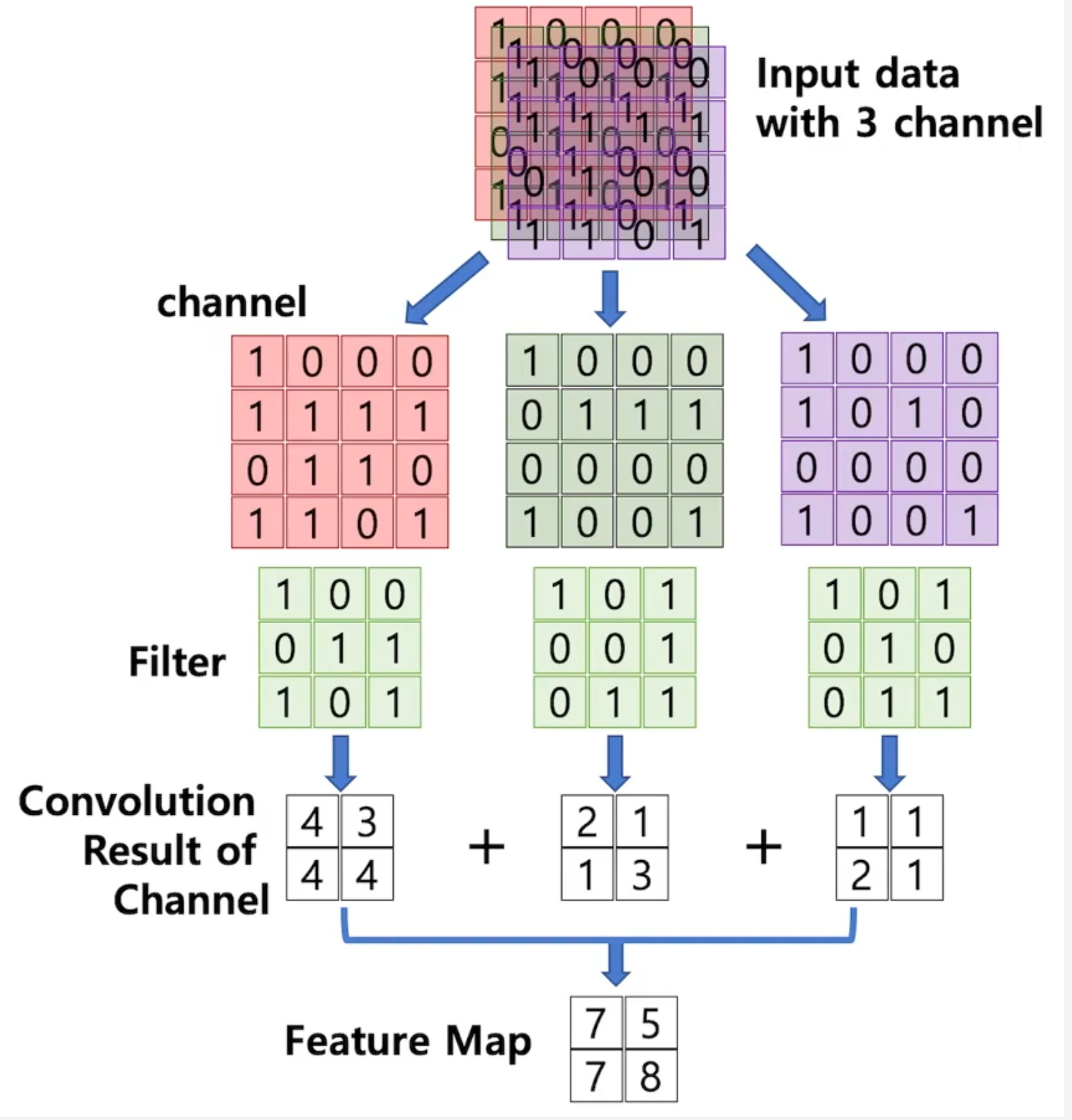
- 하지만 Lenet(CNN)이 이후에는 성과를 내지 못했음. Zip Code 인식은 좋았지만, 고해상도 이미지에 대한 성능이 떨어졌음. 고해상도 이미지 classification을 위해서는 깊은 신경망 모델이 필요했음. 근데 CNN은 깊은 신경망 모델에서 성능이 떨어지는 현상이 발생.
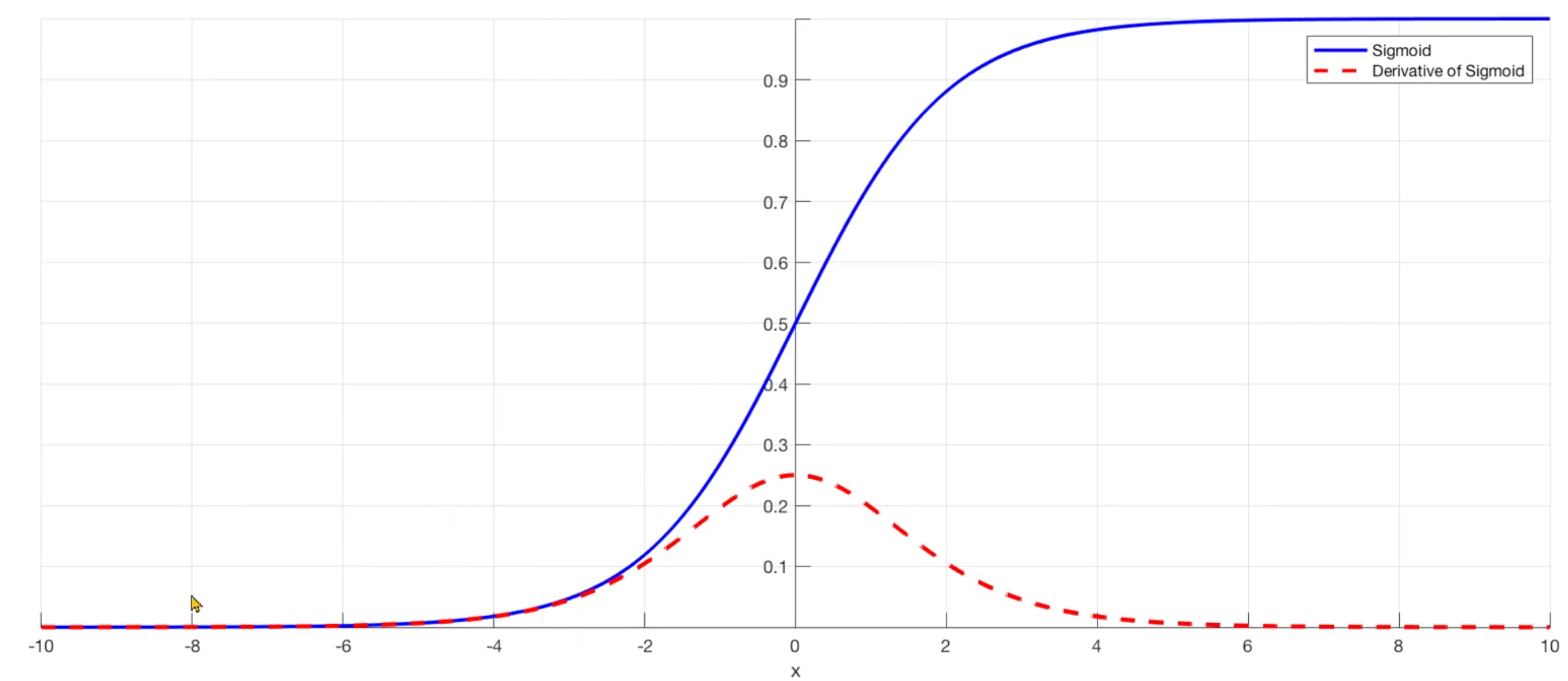
- 기존 CNN에서 발생하는 Vanishing Gradient 문 제: Sigmoid 함수(파란색)과 도함수(빨간색). Chain Rule & Backpropagation에 의해서 업데이트할 양인 미분값이 0에 수렴한다는 것을 볼 수 있다. network가 깊어지면 깊어질 수록 어차피 0에 수렴을 한다는 것. 즉 업데이트가 거의 없다는 것.
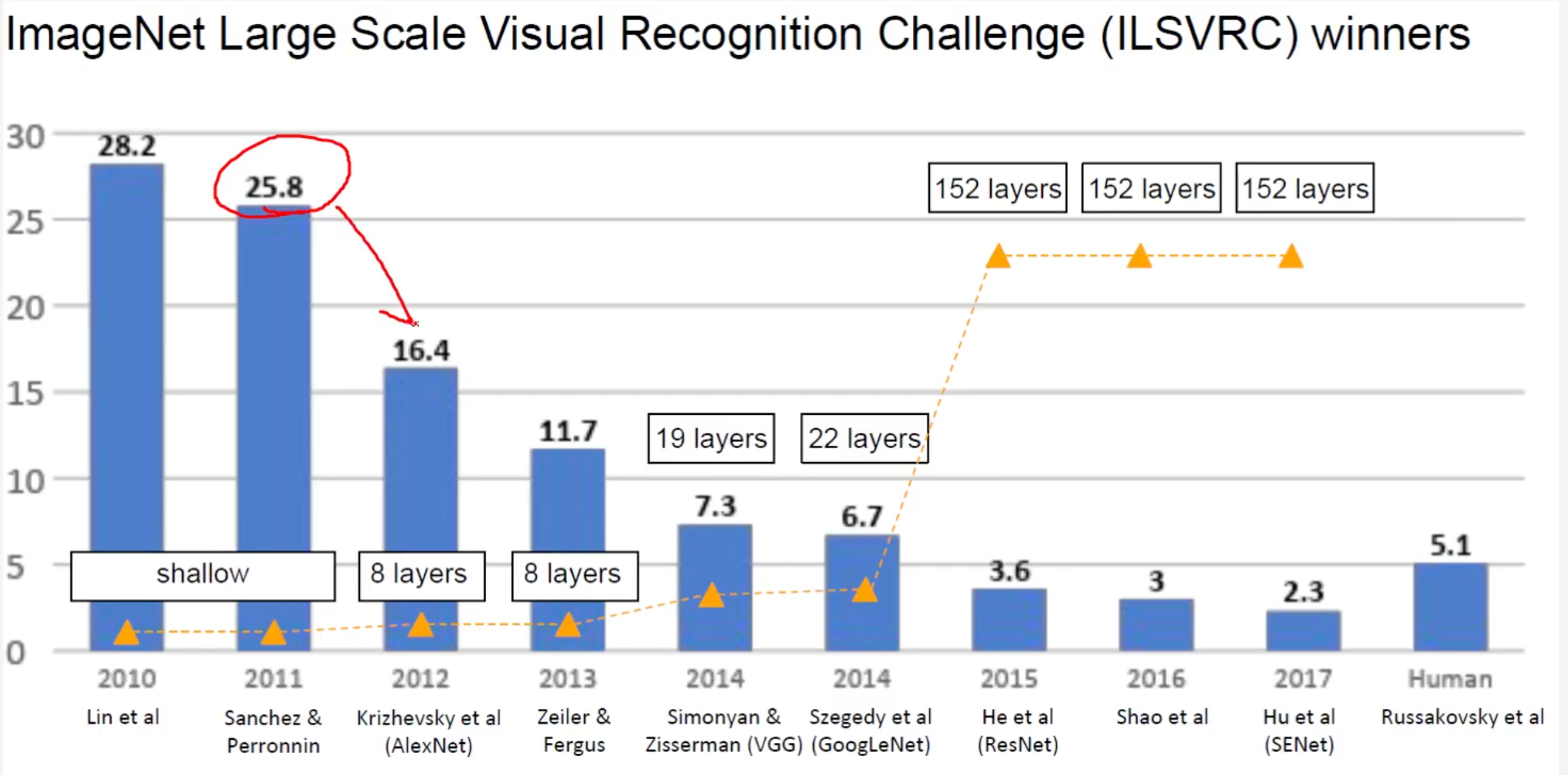
- 큰 성능향상을 이루어낸 Alexnet. 2위 모델과는 10% 이상의 압도적인 성능으로 1위 달성. GPU를 사용함. 기존 머신러닝 기법(SVM 등)에서 탈피를 한 것이 차이점이었음. 성능 좋은 일반화를 위해서는 더 큰 데이터셋을 학습시켜야 더 좋은 성능을 내는 모델을 만들 필요가 있었음. Alexnet은 심층 신경망 모델을 사용함. Vanishing Gradient 문제와 과적합을 해결하기 위해서 층을 깊게 쌓는다는 의미. 과적합을 방지하기 위해서 Dropout을 시킴.
- Alexnet 심층 신경망 모델(Deep Convolutional Neural Network)
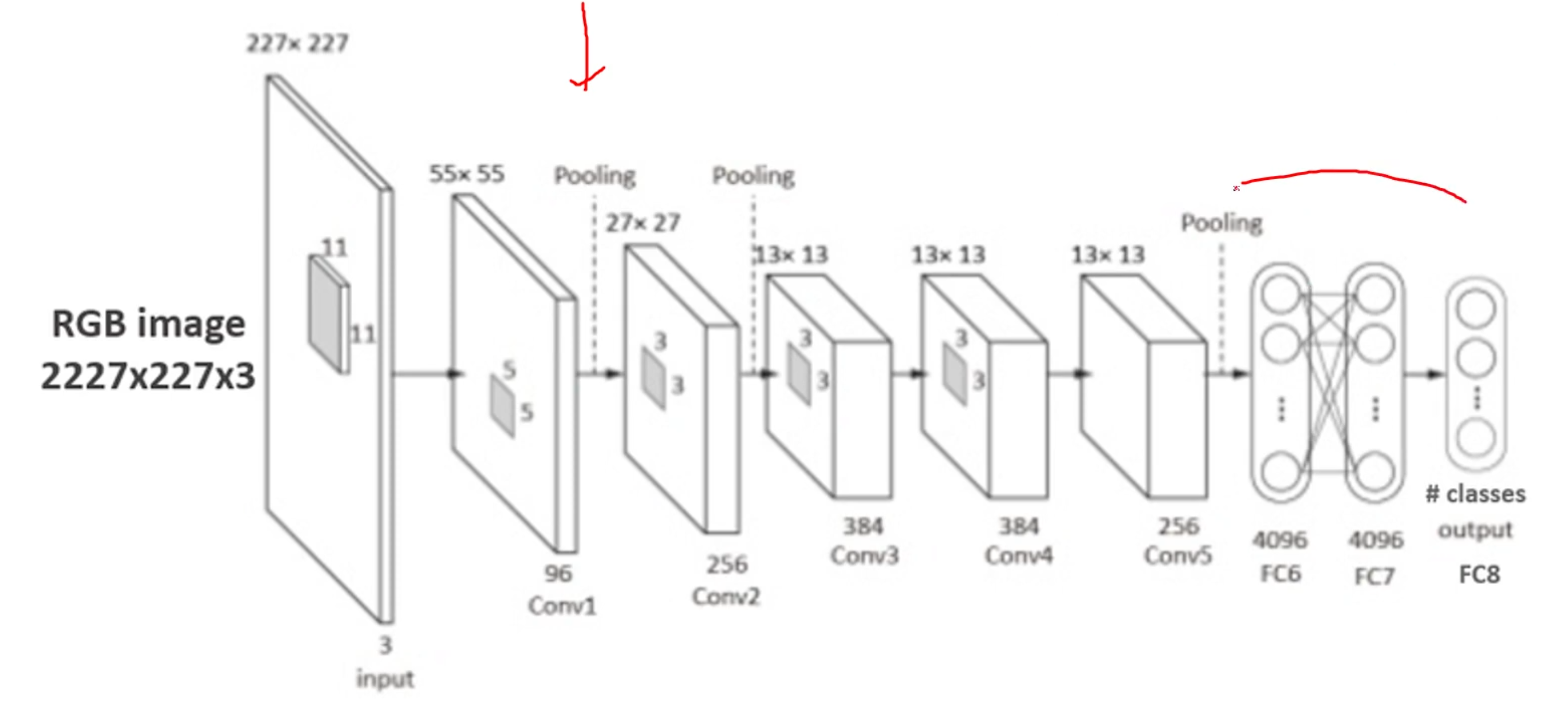
-
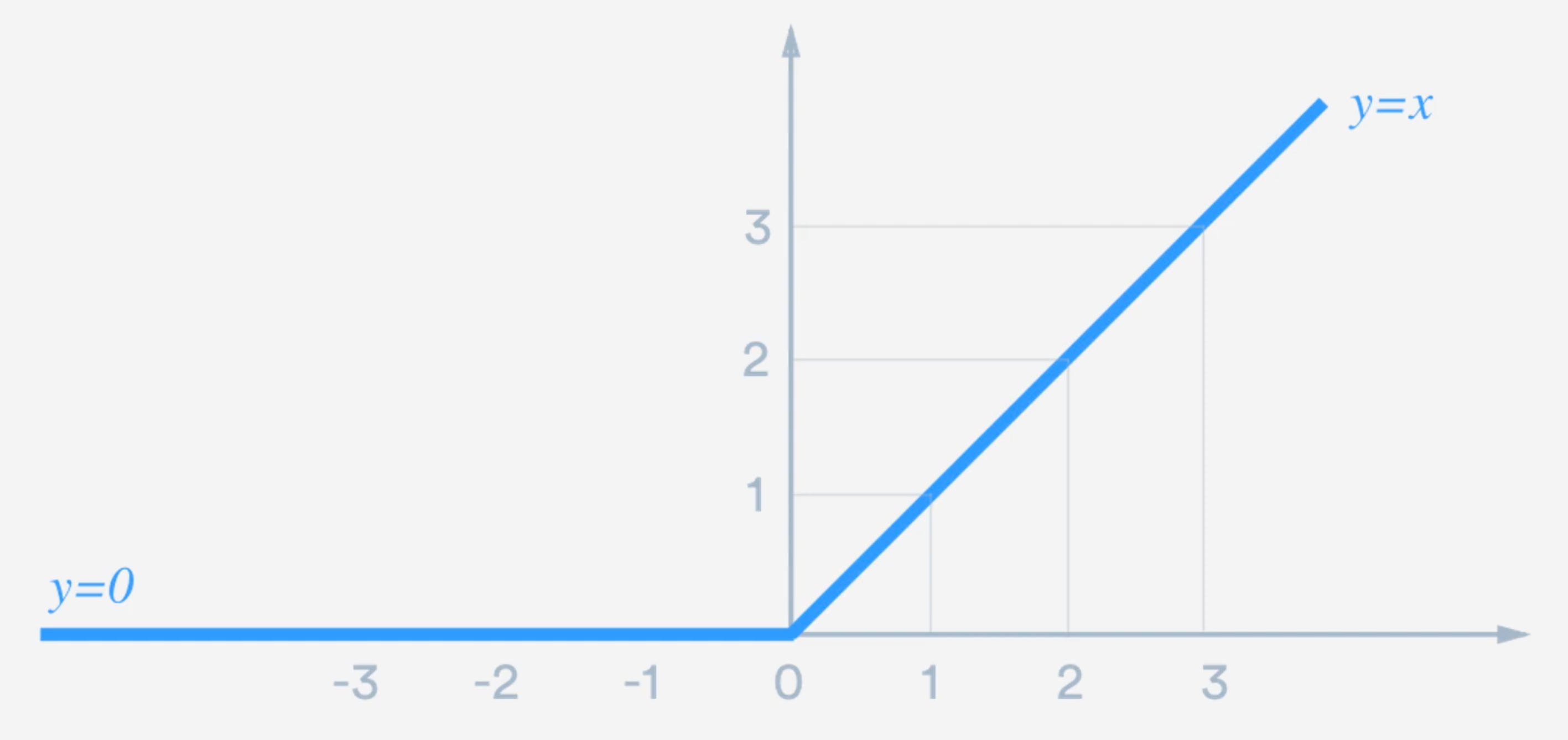
ReLU Activation Function
학습속도가 빠름: 미분값(gradient)가 0 또는 1. 그러므로 학습속도가 개선이 됨.
Non-saturation 활성함수: 미분값이 0에 수렴하게끔되는 함수. x 값이 크면 클 수록 더 큰 Gradient를 줌. 따라서 Vanishing Gradient 문제를 어느 정도 해소. 그러나 x 값이 0보다 작으면 0을 return하는 문제는 아직도 남아 있음.
-
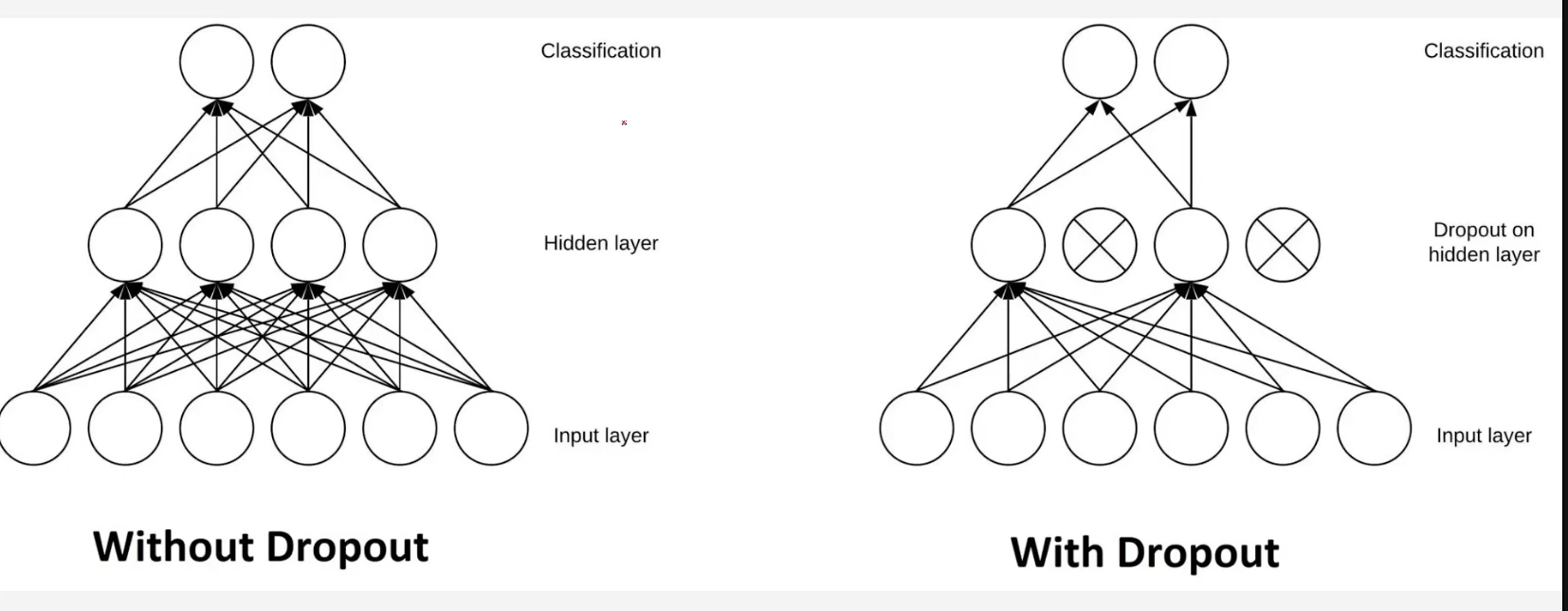
Dropout Layer로 과대적합 방지.
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xReferences

break, compose, display