Object Detection Materials
1.SPPNet
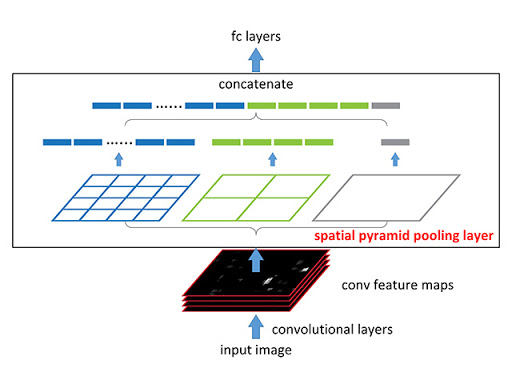
과거에 사용된 CNN 구조들은 Fully Connected Layer에 넣어야 하기 때문에 고정된 이미지 크기의 입력을 필요로 한다. cropping 과정이 들어가면서 이미지 전체를 담지 못하거나, 아니면 warping이 되면서 이미지가 왜곡이 됐다.
2021년 5월 3일
2.Alexnet 논문 읽기
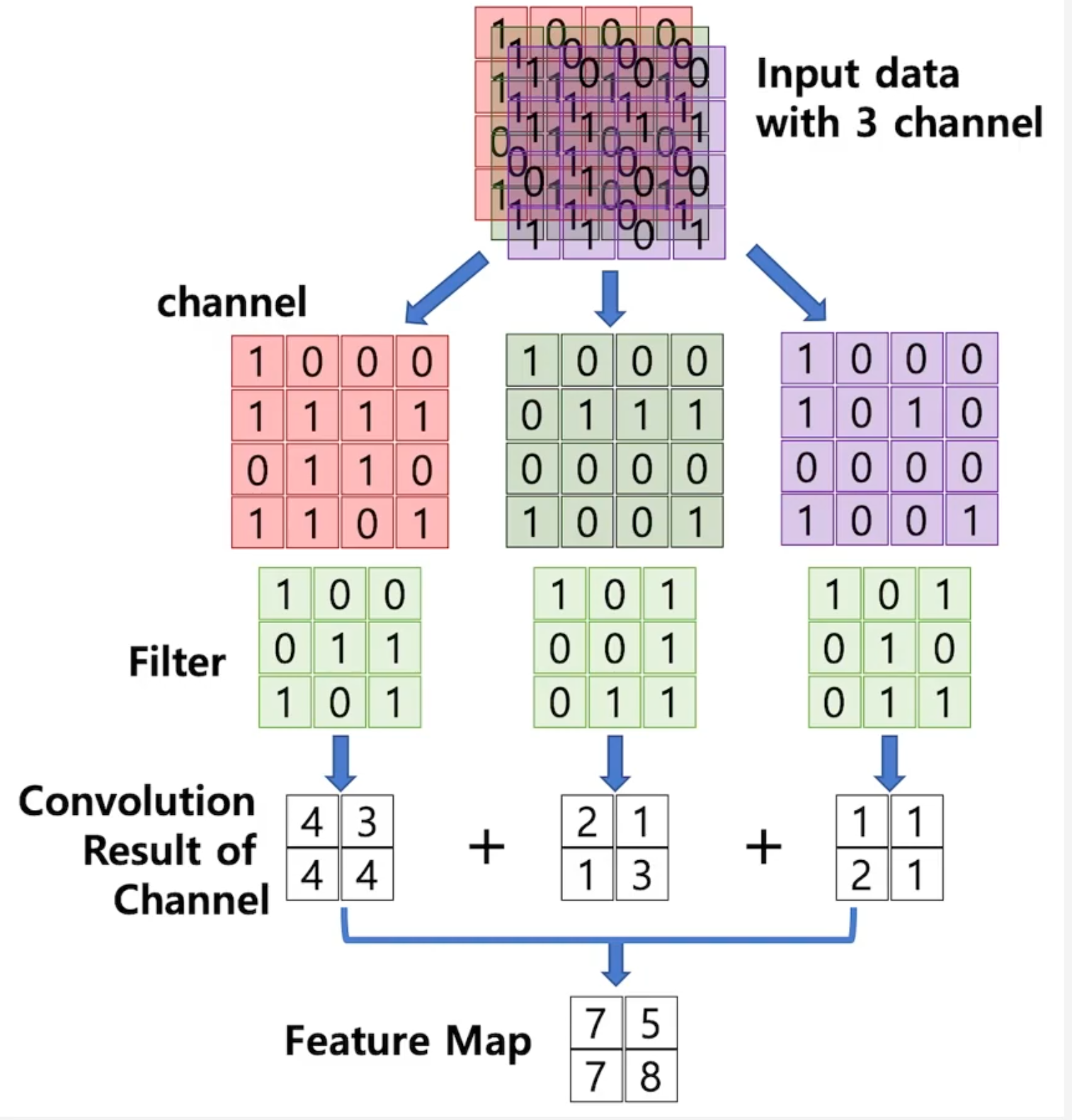
심층 신경망 모델(Deep Convolutional Neural Network)인 Alexnet이 어떻게 기존 CNN의 단점을 보완했을까?
2021년 4월 4일
3.Retinanet Paper Summary & Torch Model Code
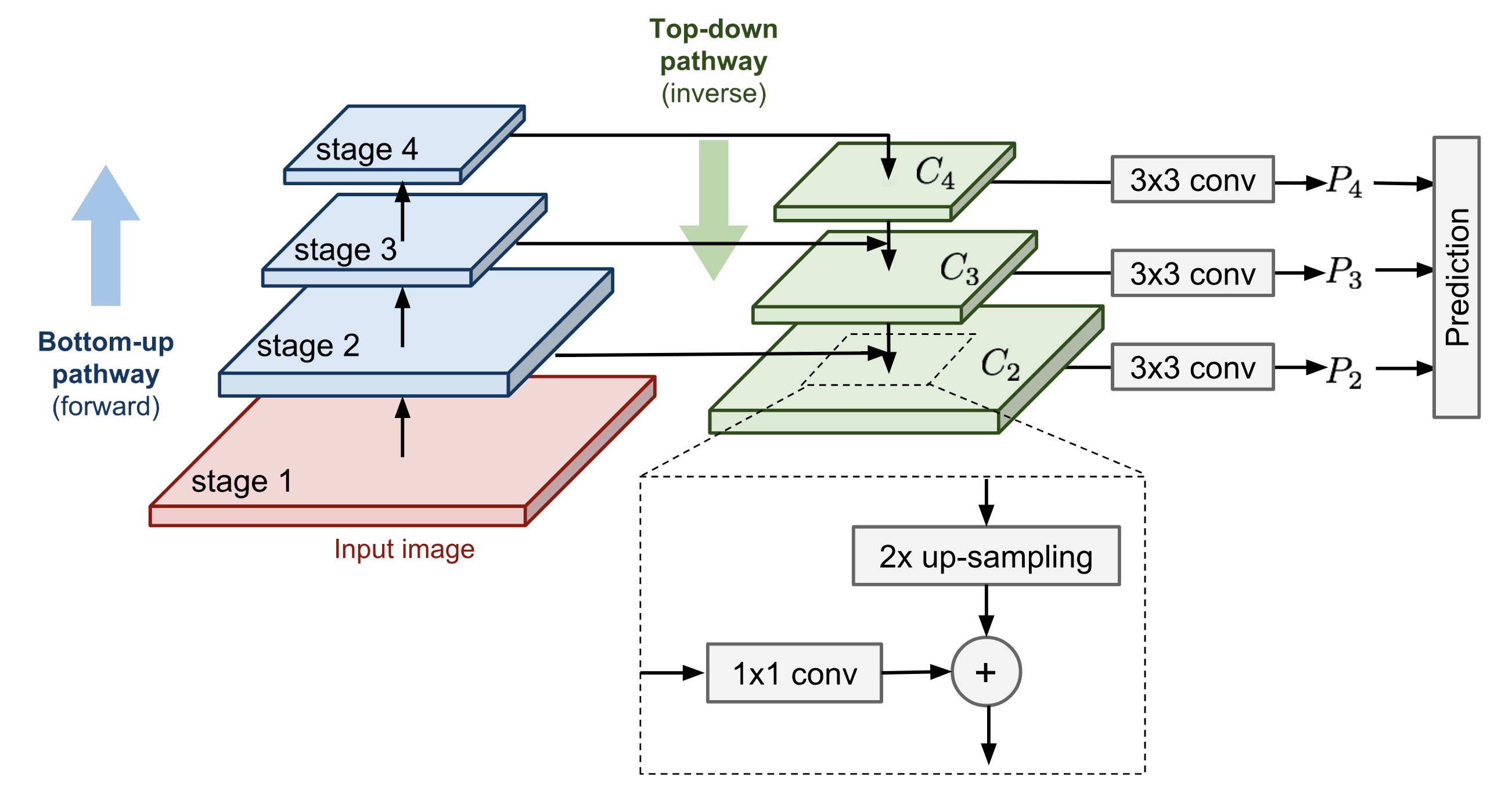
This writing is a summary for the paper Focal Loss for Dense Object Detection.
2021년 3월 28일
4.CRAFT Paper Reading
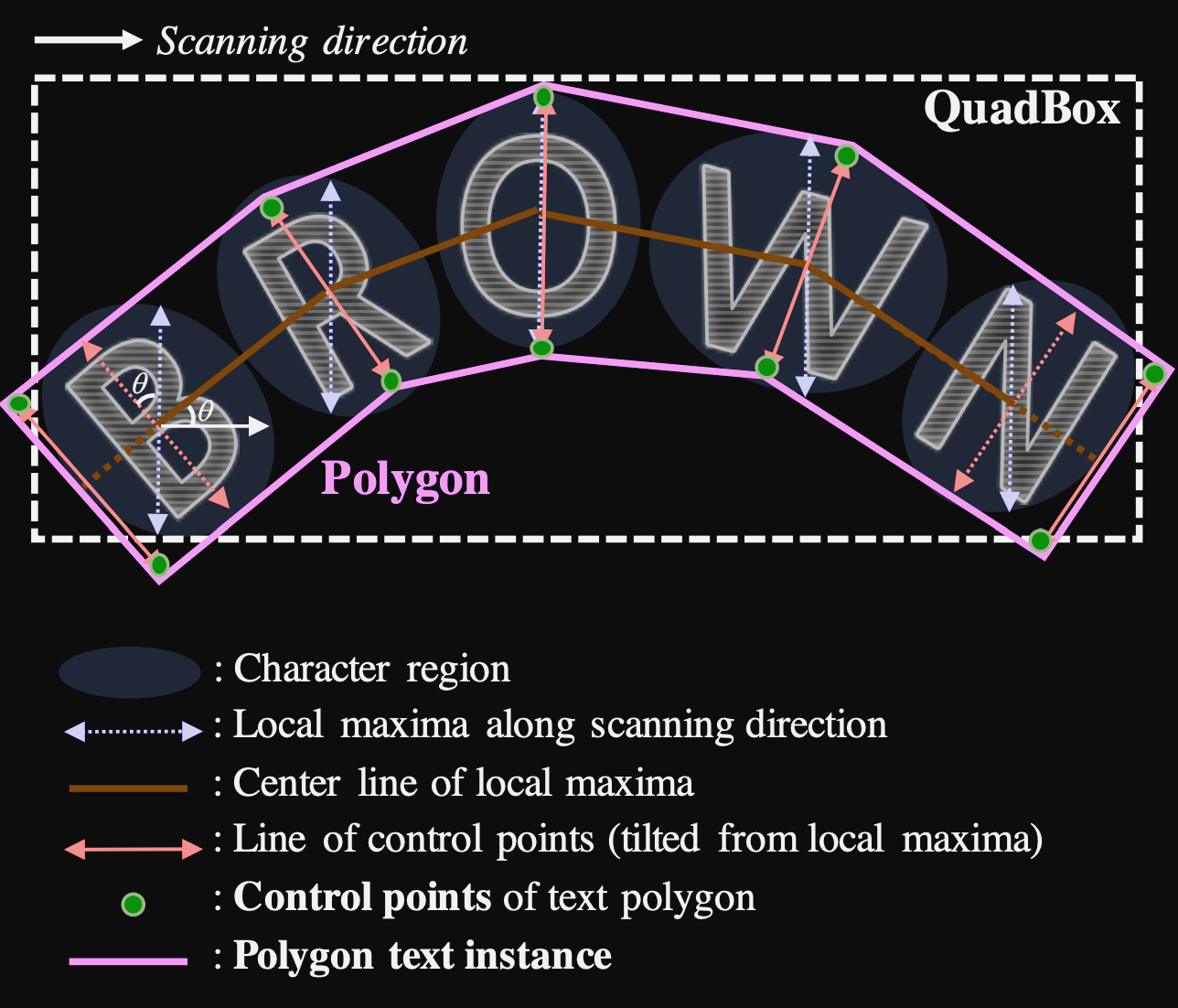
Reading Clova AI's CRAFT Paper
2021년 3월 21일
5.ResNet50 Classification Model Transfer Learning

Transfer Learning with Custom Dataset on Keras ResNet50 Base Model Pretrained on ImageNet Dataset
2021년 5월 18일
6.VGGNet Paper Reading
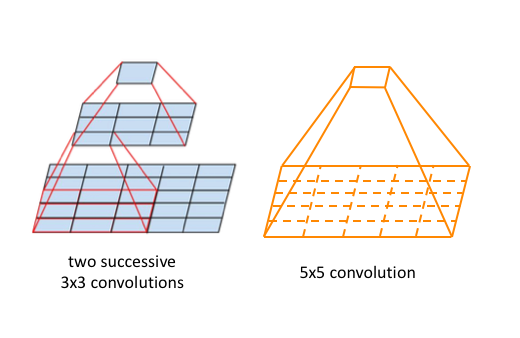
VGGNET은 Layer 개수가 19개이다. CNN 망이 깊고 넓을 수록 성능이 더 좋아지지만, 문제는 학습이 어려워진다.
2021년 5월 11일
7.Going Deeper with Convolutions: GoogleNet, Inception

Inception Module과 GoogleNet
2021년 5월 23일